
摘要:
分析了我国城乡居民收入差距现状及其对社会发展的影响,探讨了城乡收入差距的深层原因,并就这一问题的解决提出若干政策性建议。
关键词:
城乡居民; 收入差距; 二元结构
一.城乡居民收入差距扩大的现状
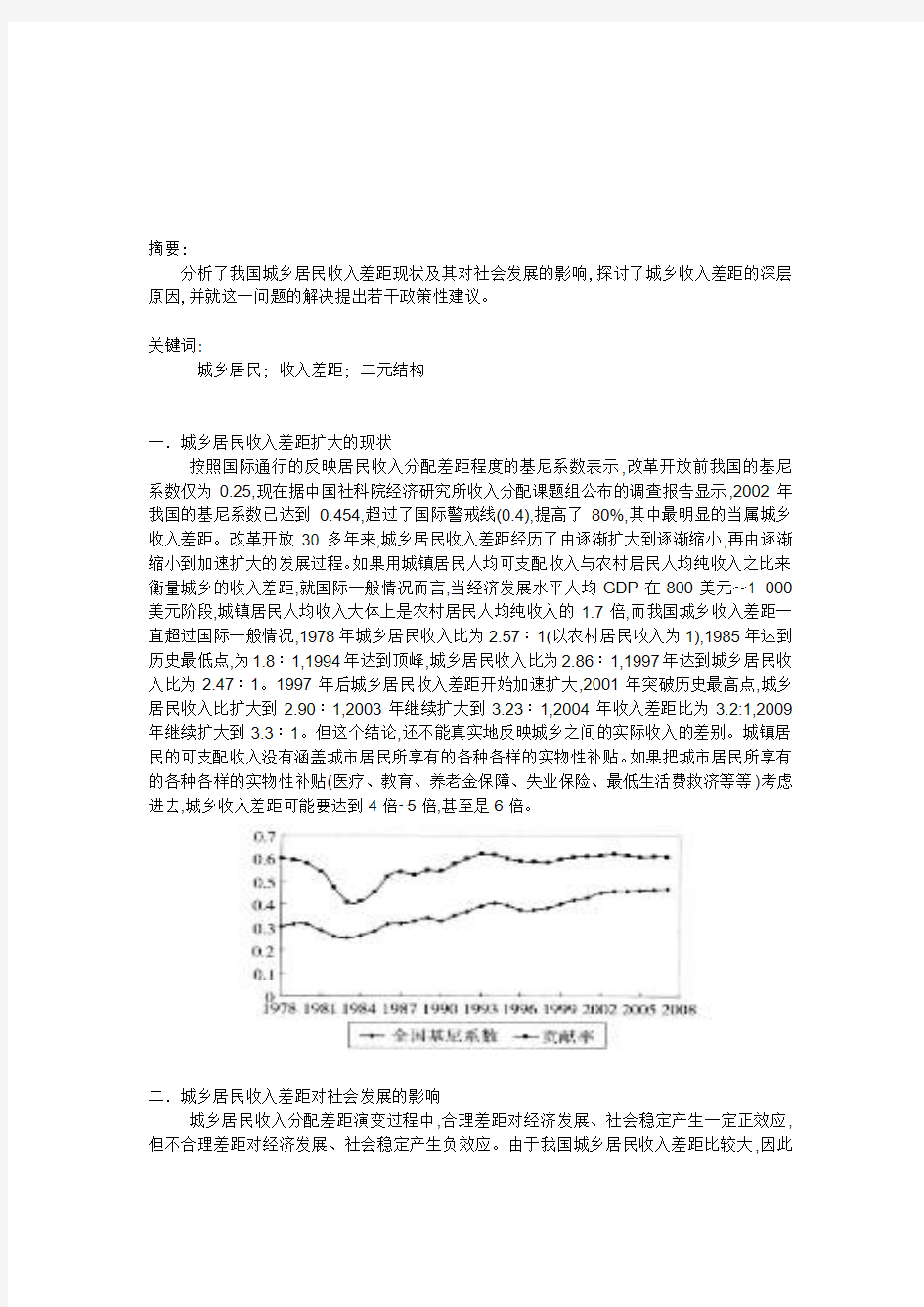
按照国际通行的反映居民收入分配差距程度的基尼系数表示,改革开放前我国的基尼系数仅为0.25,现在据中国社科院经济研究所收入分配课题组公布的调查报告显示,2002年我国的基尼系数已达到0.454,超过了国际警戒线(0.4),提高了80%,其中最明显的当属城乡收入差距。改革开放30多年来,城乡居民收入差距经历了由逐渐扩大到逐渐缩小,再由逐渐缩小到加速扩大的发展过程。如果用城镇居民人均可支配收入与农村居民人均纯收入之比来衡量城乡的收入差距,就国际一般情况而言,当经济发展水平人均GDP在800美元~1 000美元阶段,城镇居民人均收入大体上是农村居民人均纯收入的1.7倍,而我国城乡收入差距一直超过国际一般情况,1978年城乡居民收入比为2.57∶1(以农村居民收入为1),1985年达到历史最低点,为1.8∶1,1994年达到顶峰,城乡居民收入比为2.86∶1,1997年达到城乡居民收入比为2.47∶1。1997年后城乡居民收入差距开始加速扩大,2001年突破历史最高点,城乡居民收入比扩大到2.90∶1,2003年继续扩大到3.23∶1,2004年收入差距比为3.2:1,2009年继续扩大到3.3∶1。但这个结论,还不能真实地反映城乡之间的实际收入的差别。城镇居民的可支配收入没有涵盖城市居民所享有的各种各样的实物性补贴。如果把城市居民所享有的各种各样的实物性补贴(医疗、教育、养老金保障、失业保险、最低生活费救济等等)考虑进去,城乡收入差距可能要达到4倍~5倍,甚至是6倍。
二.城乡居民收入差距对社会发展的影响
城乡居民收入分配差距演变过程中,合理差距对经济发展、社会稳定产生一定正效应,但不合理差距对经济发展、社会稳定产生负效应。由于我国城乡居民收入差距比较大,因此
当前城乡收入差距的负效应占主导地位。
1正面影响
(1)一定时期内能使我国经济在生产力发展方面有长足进步,比如改革开放后打“破大锅饭”及实行按劳分配的原则,确实把我国的现代化进程提前了(在汽车等方面)。
(2)推动农业发展。当城乡居民收入差距调节到工业化所需要的一个理想差距程度时,企业会在农村用较低的价格获得工业发展所需要的劳动力而促进工业化进程,而留在农村的劳动力能享受更多农业资源最大限度利用现有的生产手段,优化资源配置,推动农业增长。
(3)使农村居民向城市聚集,提高了农村居民的素质。城乡收入存在适度差距,会对农村居民产生吸引力。一方面,会使农村人口向城市转移,变成市民,这使他们的文化素质、劳动技能得到提高,比如农村居民通过努力,以升学、学习劳动技能等方式到城市定居;另一方面,农村居民到城市打工,在自己原有知识结构的基础上,在一定条件下接受城市先进的思想观念和生产技术,提高了素质。
2负面影响
(1)不利于社会的稳定,从而影响改革发展的进程。经济发展需要一个稳定的社会环境,但是如果没有农村的稳定也就不会有整个社会的稳定。我国农村人口占总人口数的70%,是社会人口的重要组成部分。农民作为劳动群众,也是我们的政权基础,城乡居民收入分配是否合理,会直接影响社会成员心态的平和程度、社会关系的协调程度和社会形势的稳定程度。在贫富悬殊的社会中,收入分配对社会稳定的影响较多表现为社会秩序的混乱。这个问题在转型社会中尤为突出。贫困阶层不断扩大并日益边缘化,必然引发社会成员对社会的不满情绪,继而带来一系列的社会问题,使社会秩序混乱无序,从而造成社会形势的动荡不安,致使经济发展可能止步。
(2)城乡居民收入差距过大导致农村居民购买力过低,难以激活农村广大消费市场,可导致农村边际消费倾向持续走低,而这又影响了投资乘数作用的发挥,难以起到促进经济发展的作用,从而影响我国经济全面发展。
(3)城乡居民收入分配差距扩大会导致农村教育投入不足和人力资本水平低下,直接导致了农村教育投入不足,农村居民人力资本水平难以提高,这也决定了农村居民收入水平的提高缺乏真正的支撑。为提高农村居民收入水平,最关键的还是要不断提高农村居民的受教育程度。十年树木,百年树人”,唯有加强人力资本投资才能真正提高农村居民的收入水平。
三.城乡居民收入差距形成的原因
1收入的不平衡
行业垄断带着计划经济深深的烙印,虽然在一定期间可明显提升此行业与国外企业在市场上的竞争力,但其长期存在,必然导致行业间及城乡居民收入的差距。因行业垄断由中央政府的主管部门实施,所以能够创造出完全排斥竞争的效果,如电力、电信、金融等自然垄断的行业,以及一些因行政体制原因产生的制度性垄断行业,由于机会不均条件下的垄断和特权,在这些行业从业的人员几乎都成为社会的高收入者。由于行业垄断,破坏了市场经济条件下“利益均衡规律”,弱化甚至排斥了市场的调节功能,使垄断行业与非垄断的行业出现了收入上的差距。再有是一些人将权力作为一种资本参与收入分配,贪污腐败,导致收入分配的严重变形。这些权力资本的使用不当已经成为影响城乡居民收入的重要因素。
2城乡户籍制度的影响
城乡户籍制度是城乡分割体制的基础,它是传统计划经济体制下的产物,符合当时对城市倾斜发展和城乡社会稳定的需要,但是随着市场经济体制的不断深入,它已成为影响社会协调发展和城乡居民收入差距的因素,具体表现在农民劳动力转移不顺畅、农民工子女上学(中小学)难等问题。
3市场运作不规范
在市场机制尚未完全健全的前提下,保证市场运作规范的重要条件是法制建设的先行。当前,由于我国法制不健全或执法不严,致使非法非正常收入大量存在;而且由于市场运作不规范,城乡间信息的不对称,在这样一种背景下出现的农业产业布局不科学,也导致了城乡居民收入差距的扩大。
4社会保障体制不健全
社会保障的功能在于它通过社会保险、社会福利、社会救济等方面的运作,缩小居民间收入差距,减少社会不稳定因素。然而,目前社会保障面太窄,只有城市职工享受,而农民却很少享受。这种在享受社会保险方面的相对不均等性,特别是医疗保险,使农民由病返穷。虽然国家在2005年采取了农村医疗统筹,但就实际情况看,对于完全单纯靠土地生存、困难(孤寡老人)及大(多)病的农民群体,按现在的统筹标准,其本身支付的部分也是有相当难度的。
5教育机会不均等
在现实社会中,受过高等教育人员的收入水平普遍高于未受过教育或受过很少教育的成员。目前教育软硬件投资明显不足,特别是农村地区、西部地区。各级财政教育投入分配格局为:中央和省级政府掌握了主要财力,但只分别承担了义务教育经费的2%和11%,也就是说只承担了农村义务教育经费的极小部分责任,县乡政府财力薄弱,却分别负担了经费的绝大部分。事实上,县乡财政收入的大部分却是对农民的征收,这就客观上加重了农民的负担,而城镇居民则是无需缴纳这部分费用的,这就不可避免地加大了城乡居民收入之间的差距。
四.缩小城乡差距的建议和措施
1完善法律制度建设
通过法律形式来查处政府官员的渎职行为和打破垄断,保证机会的均等,允许民间资金进入,消除不正当竞争。通过反垄断法等法律法规,限制和打破垄断,逐步消除行业壁垒和垄断,降低垄断行业的市场准入标准,鼓励资本在行业之间的合理流动和有序竞争,促进行业之间平均利润的形成,逐步消除非法收入形成的条件与环境,缩小行业之间的收入差距。
2改革城乡户籍制度
改革城乡户籍制度就是实行开放式管理的户口制度,即任何人不论从何处迁往另外任何一处,只要符合一定的条件,就应该依法享有同当地居民同等的权利,如享受教育(子女上学问题)、医疗等。改革户籍制度的实质是去除依附在户籍关系上的种种社会差别,真正做到城乡居民在发展机会上的均等,社会身份的同等,使户籍只承担对人口的社会管理职能,不再与特定的社会经济利益联系在一起。
3优化产业结构
通过农村工业化、农业现代化等落实农业与国民经济协调发展的政策,发展农村经济和非农产业,以农村非农产业的发展带动农业和农村经济的发展是国际上农村经济发展的一条重要经验,也是解决贫困地区农业经济发展和农民增收的长期性和根本性措施。农村工业化,就是大力发展农村第二、三产业,不断提高第二、三产业在农村经济结构中的比重,使越来越多的农民剩余劳动力从事非农产业,提高农民收入。同时对于农村经济,政府应积极指导,使城乡对农产品供求双方信息得到尽可能对称,以便科学布局。
4加大对农村的投入
增加投资,加大对农业和农村基础设施和农村社会保障等的投入力度;增加资金、技术、人力投入,发挥政府投资的导向作用。同时改革农业投入体制,推进农村投资和金融体制改革,特别是搞好农村信用合作社的改革,坚持为农业、农村、农民服务的方向,信贷资金不准或按特定优势比例投向非农领域和非农产业,提高金融服务的质量和水平,加强农村金融服务体系建设;并广泛吸纳外资、工商资本和社会闲散资金,形成多元化的农业投融资体制,扩大农业投入来源,增加农业投入总量。通过各种投入,改善农业基础设施建设和完善农民的社会保障制度,为农业、农村的发展创造一个宽松的环境,并且使广大农民拥有最低生活保障、养老保
障和医疗保障。
5制定税收优惠政策
政府应进一步通过对高收入人群的征税来调整收入差距,因为税收可直接有效地减少高收入人群的比例,并且能增加国家财政收入,起到稳定社会的作用。对于农用物资也应制定一些税收优惠政策,国家虽然减免了农业特产税等税种,但是对于农业物资(如化肥等)也应依照一定比例来减少其税率,让农民最直接受益,让城乡居民收入差距能较快缩小。
6增加农村教育投入
国家应加大对农村教育的投入,把农村基础教育列入中央预算,改善农村办学条件和办学模式,并且在农村普及九年义务教育的基础上,加强农村实用技术的培训,完善农村职业技术教育,让广大的农村劳动者掌握一些实用技术,实现教育在农村的真正普及。此外,还要对农民进行法律法规培训,全面提高农村人员素质,从根本上缩小城乡居民收入差距。
五.正确看待城乡居民收入差距
解决城乡居民收入差距,不是哪一项具体措施就可以做到的,亦不是一蹴而就的,而是一个渐进过程,是一个系统工程。这就必须坚“持统筹安排”,不能因过分强调公平而忽视效率,重“返大锅饭”,如统筹初次分配和再分配,就要在初次分配中注重效率,公平、合理拉开收入差距,把劳动者的物质利益与劳动贡献直接结合起来,鼓励各种生产要素的所有者把生产要素投入到经济活动中去,按贡献参与分配;而在再分配中注重公平,把公平放在突出的位置,更多地考虑低收入群体的实际困难。统筹市场力量、政府力量和社会力量,更科学地对社会资源配置;从社会的角度出发,应切实贯彻收入分配政策,保护每一个社会成员各方面的积极性并使其收益最大化,使我国经济能在稳定中持续增长,让全社会成员共同过上富裕生活。
参考文献:
1 农村经济绿皮书
2 《应用线性回归》中国统计出版社
3 王雅鹏破解“三农”问题[J].理论月刊,
4 项俊波经济学/从结构视角看中国经济人民大学出版社
5 叶静怡发展经济学北京大学出版社,
6 《中国统计年鉴》各年中国统计出版社。
########实验报告 实验名称:回归分析
专业班级:333 姓名:#### 学号:#####实验日期: 33### 一、实验目的: 掌握相关系数的求解方法,能够熟练运用回归分析工具进行一元与多元线性回归分析,了解单因素方差分析工具的使用。 二、实验内容: (1)相关系数的计算 (2)单因素方差分析 (3)一元线性回归分析 三、实验过程: 1、利用图表进行回归分析 ①打开“饭店”工作表 ②插入“图表”,选择XY散点图。 ③在数据区域中输入B2:C11,选择“系列产生在——列”,单击“下一步”按钮。 ④打开“图例”页面,取消图例,省略标题。 ⑤单击“完成”按钮。 ⑥点击“趋势线”选项,选择“线性”选项,Excel将显示一条拟合数据点的直线。 ⑦打开“选项”页面,在对话框下部选择“显示公式”与“显示R平方根”选项,单击“确定”按钮,便得到趋势回归图。
⑦打开“选项”页面,在对话框下部选择“显示公式”与“显示R平方根”选项,单击“确定”按钮,便得到趋势回归图。
专业班级:¥¥¥姓名:### 学号: #### 实验日期:##### 2、利用工作表函数进行回归分析 ①打开“简单线性回归、xls”工作簿,选择“成本产 量”工作表。 ②在单元格A19、A20、A21与A22中分别输入“截距 b0”、“斜率b1”、“估计标准误差”与“测定系 数” 。 ③在单元格B19中输入公 式:“=INTERCEPT(C2:C15,B2:B15)” ,单击回车键。 ④在单元格B20中输入公式: “=SLOPE(C2:C15,B2:B15)”,单击回车键。 ⑤在单元格B21中输入公式: “=STEYX(C2:C15,B2:B15)”,单击回车键。 ⑥在单元格B22中输入公式: “=RSQ(C2:C15,B2:B15)”,单击回车键。 3、Excel 回归分析工具 ①打开“简单线性回归、xls”工作簿,选择“住房”工作表。 ②在“工具”菜单中选择“数据分析”选项,打开“数据分析”对话框。 ③在“分析工具”列表中选择“回归”选项,单击“确定”按钮,打开“回归”对话框。
问卷调查的常用统计分析方法 问卷调查的方法用得很广泛,对于没有接触过spss的人第一步面临的就是问卷编码问题,有很多外专业的同学都在问这个问题,现在通过举例的方法详细讲解如下,以方便第一次接触SPSS 的同学也能做简单的分析。后面还有分析时的操作步骤,以及比较适用的深入统计分析方法的简单介绍。 调查分析问卷回收,在经过核实和清理后就要用SPSS做数据分析,首先的第一步就是把问题编码录入。 SPSS的问卷分析中一份问卷是一个案,首先要根据问卷问题的不同定义变量。定义变量值得注意的两点:一区分变量的度量,Measure的值,其中Scale是定量、Ordinal是定序、Nominal 是指定类;二注意定义不同的数据类型Type 各色各样的问卷题目的类型大致可以分为单选、多选、排序、开放题目四种类型,他们的变量的定义和处理的方法各有不同,我们详细举例介绍如下: 问卷调查的方法用得很广泛,对于没有接触过spss的人第一步面临的就是问卷编码问题,有很多外专业的同学都在问这个问题,现在通过举例的方法详细讲解如下,以方便第一次接触SPSS的同学也能做简单的分析。后面还有分析时的操作步骤,
以及比较适用的深入统计分析方法的简单介绍。自己写的,错误之处请指正, 调查分析问卷回收,在经过核实和清理后就要用SPSS做数据分析,首先的第一步就是把问题编码录入。 SPSS的问卷分析中一份问卷是一个案,首先要根据问卷问题的不同定义变量。定义变量值得注意的两点:一区分变量的度量,Measure的值,其中Scale是定量、Ordinal是定序、Nominal 是指定类;二注意定义不同的数据类型Type 各色各样的问卷题目的类型大致可以分为单选、多选、排序、开放题目四种类型,他们的变量的定义和处理的方法各有不同,我们详细举例介绍如下: 1 、单选题:答案只能有一个选项 例一当前贵组织机构是否设有面向组织的职业生涯规划系统? A有 B 正在开创C没有D曾经有过但已中断 编码:只定义一个变量,Value值1、2、3、4分别代表A、
多元统计分析实例 院系:商学院 学号: 姓名:
多元统计分析实例 本文收集了2012年31个省市自治区的农林牧渔和相关农业数据,通过对对收集的数据进行比较分析对31个省市自治区进行分类.选取了6个指标农业产值,林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农村居民家庭经营耕地面积. 数据如下表: 一.聚类法
设定4个群聚,采用了系统聚类法.下表为spss分析之后的结果.
Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ 内蒙 5 -+ 吉林 7 -+ 云南 25 -+-+ 江西 14 -+ +-+ 陕西 27 -+-+ | 新疆 31 -+ +-+ 安徽 12 -+-+ | | 广西 20 -+ +-+ +-------+ 辽宁 6 ---+ | | 浙江 11 -+-----+ | 福建 13 -+ | 重庆 22 -+ +---------------------------------+ 贵州 24 -+ | | 山西 4 -+---+ | | 甘肃 28 -+ | | | 北京 1 -+ | | | 青海 29 -+ +---------+ | 天津 2 -+ | | 上海 9 -+ | | 宁夏 30 -+---+ | 西藏 26 -+ | 海南 21 -+ | 河北 3 ---+-----+ | 四川 23 ---+ | | 黑龙江 8 -+-+ +-------------+ | 湖南 18 -+ +---+ | | | 湖北 17 -+-+ +-+ +-------------------------+ 广东 19 -+ | | 江苏 10 -------+ | 山东 15 -----------+-----------+ 河南 16 -----------+
市场调查分析案例 市场调查分析是市场调查的重要组成部分。通过市场调查收集到的原始资料,是处于一种零散、模糊、浅显的状态,只有经过进一步的处理和分析,才能使零散变为系统、模糊走向清晰、浅显发展为深刻,分析研究其规律性,达到正确认识社会现象目的,为准确的市场预测提供参考依据,最终为调查者正确决策提供有力的依据。 市场调查分析的原则:从全部事实出发,坚持事实求实的观点;全面分析问题,坚持一分为二的观点;必须从事物的相互联系,相互制约中分析问题; 市场调查分析方法:单变量统计量分析、单变量频数分析、多变量统计量分析、多变量频数分析、相关分析、聚类分析、判别分析、因子分析等。 案例:某市家用汽车消费情况调查分析案例 随着居民生活水平的提高,私车消费人群的职业层次正在从中高层管理人员和私营企业主向中层管理人员和一般职员转移,汽车正从少数人拥有的奢侈品转变为能够被更多普通家庭所接受的交通工具。了解该市家用汽车消费者的构成、消费者购买时对汽车的关注因素、消费者对汽车市场的满意程度等对汽车产业的发展具有重要意义。 本次调研活动中共发放问卷400份,回收有效问卷368份,根据整理资料分析如下。 一、消费者构成分析 1 、有车用户家庭月收入分析
5000元以上8.69 100.00 目前该市有车用户家庭月收入在2000?3000元间的最多;有车用户平均月收入为2914.55元,与该市民平均月收入相比,有车用户普遍属于收入较高人群。61.96%的有车用户月收入在3000元以下,属于高收入人群中的中低收入档次。因此,目前该市用户的需求一般是每辆10?15万元的经济车型。 2、有车用户家庭结构分析 表2: 有车用户家庭结构 Di nk家庭(double in come no kid ),即夫妻二人无小孩的家庭,占有车家 庭的比重大,为36.96%。其家庭收入较高,负担较轻、支付能力较强,文化层次高、观念前卫,因此Dink家庭成为有车族中最为重要的家庭结构模式。核心家庭,即夫妻二人加上小孩的家庭,比重为34.78%。核心家庭是当前社会中最普遍的家庭结构模式,因此比重较高不足为奇。联合家庭,即与父母同住的家庭, 仅有8.70%。单身族占17.39%,这部分人个人收入高,且时尚前卫,在有车用户中占据一定比重。另外已婚用户比重达到了81.5%,而未婚用户仅为18.5%。 3、有车用户职业分析 调查显示有29%勺消费者在企业工作,20%勺消费者是公务员,另外还有自由职业者、机关工作人员和教师等。目前企业单位的从业人员,包括私营业主、高级主管、白领阶层仍是最主要的汽车使用者。而自由职业者由于收入较高及其工作性质,也在有车族中占据了较 高比重。详见图1。
选择合适的统计学方法 1连续性资料 1.1 两组独立样本比较 1.1.1 资料符合正态分布,且两组方差齐性,直接采用t检验。 1.1.2 资料不符合正态分布,(1)可进行数据转换,如对数转换等,使之服从正态分布,然后对转换后的数据采用t检验;(2)采用非参数检验,如Wilcoxon检验。 1.1.3 资料方差不齐,(1)采用Satterthwate 的t’检验;(2)采用非参数检验,如Wilcoxon检验。 1.2 两组配对样本的比较 1.2.1 两组差值服从正态分布,采用配对t检验。 1.2.2 两组差值不服从正态分布,采用wilcoxon的符号配对秩和检验。 1.3 多组完全随机样本比较 1.3.1资料符合正态分布,且各组方差齐性,直接采用完全随机的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.3.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Kruscal-Wallis法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用成组的Wilcoxon检验。 1.4 多组随机区组样本比较 1.4.1资料符合正态分布,且各组方差齐性,直接采用随机区组的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.4.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Fridman检验法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用符号配对的Wilcoxon检验。 ****需要注意的问题: (1)一般来说,如果是大样本,比如各组例数大于50,可以不作正态性检验,直接采用t 检验或方差分析。因为统计学上有中心极限定理,假定大样本是服从正态分布的。 (2)当进行多组比较时,最容易犯的错误是仅比较其中的两组,而不顾其他组,这样作容易增大犯假阳性错误的概率。正确的做法应该是,先作总的各组间的比较,如果总的来说差别有统计学意义,然后才能作其中任意两组的比较,这些两两比较有特定的统计方法,如上面提到的LSD检验,Bonferroni法,tukey法,Scheffe法,SNK法等。**绝不能对其中的两
经济管理类“十二五”规划教材统计学 -基于典型案例、问题和思想 主讲林海明
第一章绪论 【引言】我们从如下9个重要事例,说明统计学有什么用。 事例1:二次世界大战中,最激烈的空战是英国抗击德国的空战,英军为了提高战斗力,急需找到英军战机空战中的危险区域加固钢板,统计学家瓦尔德用统计学
方法找到了危险区域,英军用钢板加固了这些危险区域,使英军取得了空战的胜利。 事例2:上世纪20-30年代,为了找到中国革命的主力军和道路,政治家毛泽东悟出了统计学的频数方法,用此找到了中国革命的主力军是农民,中国革命的道路是农村包围城市。由此不屈不饶的奋斗,由弱变强,建立了独立自主的中华人民共和国,他还发现了“没有调查,就没有发
言权”的科学论断。 事例3:1998年,美国博耶研究型大学本科生教育委员会发表了题为《重建本科生教育:美国研究型大学发展蓝图》的报告,该报告指出:为了培养科学、技术、学术、政治和富于创造性的领袖,研究型大学必须“植根于一种深刻的、永久性的核心:探索、调查和发现”。这说明了统计学中调查的重要性。
事例4:在居民收入贫富差距的测度方面,美国统计学家洛仑兹(1907)、意大利经济学家基尼(1922)找到了统计学的洛仑兹曲线、基尼系数,由此给出了居民收入贫富差距的划分结果,为政府改进居民收入贫富不均的问题提供了政策依据。 事例5:二战后产品质量差的日本,以田口玄一为代表的质量管理学者用统计学方法找到了3σ质量管理原则,用其大幅提
高了企业的产品质量,其产品畅销海内外,日本因此成为当时的第二经济强国。该学科现已发展到了6σ质量管理原则。 事例6:在第二次世界大战的苏联卫国战争中,专家们用英国统计学家费歇尔(1 925)的最大似然法、无偏性,帮助苏军破解了德军坦克产量的军事秘密,由此苏军组织了充足的军事力量并联合盟军,打败了德军的疯狂进攻并占领了柏林。
何晓群编著,《现代统计分析方法与应用》第三版,中国人民大学出版社,2012。数据和部分程序下载 第2章 服装标准例程序利用R软件,运行如下R程序便可计算相应的条件均值和条件协方差矩阵: #均值向量 m=matrix(c(154.98,83.39,70.26,61.32,91.52),nrow=5,ncol=1); m; #协方差矩阵 sigma=matrix(c(29.66,6.51,1.85,9.36,10.34, 6.51,30.53,25.54,3.54,19.53, 1.85,25.54,39.86, 2.23,20.70, 9.36,3.54,2.23,7.03,5.21, 10.34,19.53,20.70,5.21,27.36),5,5); sigma; #条件均值 x5=85; m1=matrix(m[1:4,1],4,1)+matrix(sigma[1:4,5]*sigma[5,5]^(-1),4,1)%*%(x5-sigma[5,1]); m1; #条件协方差1(d[x1,x2,x3,x4|x5]) d1=sigma[1:4,1:4]-matrix(sigma[1:4,5]*sigma[5,5]^(-1),4,1)%*%matrix(sigma[5,1:4],1,4); d1; #条件协方差2(d[x1,x2,x3|x4,x5]) d2=d1[1:3,1:3]-matrix(d1[1:3,4]*d1[4,4]^(-1),3,1)%*%matrix(d1[4,1:3],1,3); d2; 注:上面程序假定 585 X ,可以根据实际情况更改 5 X的值以计算相应的条件均值。 利用R软件,运行如下的R程序便可计算出偏相关系数: #均值向量 m=matrix(c(154.98,83.39,70.26,61.32,91.52),nrow=5,ncol=1); m; #协方差矩阵 sigma=matrix(c(29.66,6.51,1.85,9.36,10.34, 6.51,30.53,25.54,3.54,19.53, 1.85,25.54,39.86, 2.23,20.70, 9.36,3.54,2.23,7.03,5.21, 10.34,19.53,20.70,5.21,27.36),5,5); sigma;
因子分析与主成分分析 一、问题概述 现希望对30个省市自治区经济发展基本情况的八项指标进行分析。具体采用的指标只有:GDP、居民消费水平、固定资产投资、职工平均工资、货物周转量、居民消费价格指数、商品零售价格指数、工业总产值。这是一个综合分析问题,八项指标较多,用主成分分析法进行综合。 二、数据处理与分析 1.因子分析 打开数据后,在SPSS中进行因子分析的步骤如下: 选择“分析---降维---因子分析”,在弹出的对话框里 (1)描述---系数、KMO与Bartlett的球形度检验 (2)抽取---碎石图、未旋转的因子解 (3)旋转---最大方差法、旋转解、载荷图 (4)得分---保存为变量、显示因子得分系数矩阵 (5)选项---按大小排序 点击确定得到如下各图: 图3-1 图3-2 KMO 和 Bartlett 的检验 取样足够度的 Kaiser-Meyer-Olkin 度量。.620 Bartlett 的球形度检验近似卡方231.285 df 28 Sig. .000 图3-3 公因子方差
图3-6 成份矩阵a
图3-9
(2)因子模型中各统计量的意义 A)因子载荷错误!未找到引用源。:因子载荷错误!未找到引用源。为第i个变量在第j个因子上的载荷,实际上就是错误!未找到引用源。与错误!未找到引用源。的相关系数,表示变量错误!未找到引用源。依赖因子错误!未找到引用源。的程度,反应了第i个变量错误!未找到引用源。对于第j个因子错误!未找到引用源。的重要性。 B)变量错误!未找到引用源。的变量共同度:k个公因子对第i个变量方差的贡献,也称为公因子方差比,记为错误!未找到引用源。,公式为:错误!未找到引用源。=错误!未找到引用源。(j=1,2,….,k)
统计调查方案设计案例 ▲统计调查方案的内容和撰写: 一、统计调查方案的主要内容 1、确定统计调查目的和任务 2、确定调查对象和调查单位 调查对象是指依据调查的任务和目的,确定本次调查的范围及需要调查的那些现象的总体。 调查单位是指所要调查的现象总体所组成的个体,也就是调查对象中所要调查的具体单位,即我们在调查中要进行调查研究的一个个具体的承担者。 3、确定调查内容和调查表 (1)调查课题如何转化为调查内容 调查课题转化为调查内容是把已经确定了的调查课题进行概念化和具体化。 (2)调查内容如何转化为调查表 如何把调查内容设计为调查表,这一问题会在下一章中专门介绍。 4、调查方式和调查方法 5、调查项目定价与预算 6、统计数据分析方案 7、其他内容 包括确定调查时间,安排调查进度,确定提交报告的方式,调查人员的选择、培训和组织等。 二、统计调查方案的撰写 1、统计调查方案的格式 包括摘要、前言、统计调查的目的和意义、统计调查的内容和范围、调查采用方式和方法、调查进度安排和有关经费开支预算、附件等部分。 2、撰写统计调查方案应注意的问题 (1)一份完整的统计调查方案,上述1—7部分的内容均应涉及,不能有遗漏。否则就是不完整的。 (2)统计调查方案的制订必须建立在对调查课题的背景的深刻认识上。
(3)统计调查方案要尽量做到科学性与经济性的结合。 (4)统计调查方案的格式方面可以灵活,不一定要采用固定格式。 (5)统计调查方案的书面报告是非常重要的一项工作。一般来说,统计调查方案的起草与撰写应由课题的负责人来完成。 三、统计调查方案的可行性研究 (一)统计调查方案的可行性研究的方法 1、逻辑分析法 逻辑分析法是指从逻辑的层面对统计调查方案进行把关,考察其是否符合逻辑和情理。 2、经验判断法 经验判断法是指通过组织一些具有丰富市场调查经验的人士,对设计出来的统计调查方案进行初步研究和判断,以说明统计调查方案的合理性和可行性。 3、试点调查法 试点调查法是通过在小范围内选择部分单位进行试点调查,对统计调查方案进行实地检验,以说明调查方案的可行性的方法。 (二)统计调查方案的模拟实施 统计调查方案的模拟实施是只对那些调查内容很重要,调查规模又很大的调查项目才采用模拟调查,并不是所有的统计调查方案都需要进模拟调查。模拟调查的形式很多,如客户论证会和专家评审会等形式。 (三)统计调查方案的总体评价 统计调查方案的总体评价可以从不同角度来衡量。但是,一般情况下,对统计调查方案进行评价应包括四个方面的内容,即:统计调查方案是否体现调查目的和要求;统计调查方案是否具有可操作性;统计调查方案是否科学和完整;统计调查方案是否具有调查质量高、效果好。 ▲案例:湘潭大学单放机市场调查计划书 一、前言
统计分析的八种方法 统计分析的八种方法一、指标对比分析法指标对比分析法,又称比较分析法,是统计分析中最常用的方法。是通过有关的指标对比来反映事物数量上差异和变化的方法。有比较才能鉴别。单独看一些指标,只能说明总体的某些数量特征,得不出什么结论性的认识;一经过比较,如与国外、外单位比,与历史数据比,与计划相比,就可以对规模大小、水平高低、速度快慢作出判断和评价。 指标分析对比分析方法可分为静态比较和动态比较分析。静态比较是同一时间条件下不同总体指标比较,如不同部门、不同地区、不同国家的比较,也叫横向比较;动态比较是同一总体条件不同时期指标数值的比较,也叫纵向比较。这两种方法既可单独使用,也可结合使用。进行对比分析时,可以单独使用总量指标或相对指标或平均指标,也可将它们结合起来进行对比。比较的结果可用相对数,如百分数、倍数、系数等,也可用相差的绝对数和相关的百分点(每1%为一个百分点)来表示,即将对比的指标相减。 二、分组分析法指标对比分析法是总体上的对比,但组成统计总体的各单位具有多种特征,这就使得在同一总体范围内的各单位之间产生了许多差别,统计分析不仅要对总体数量特征和数量关系进行分析,还要深入总体的内部进行分组分析。分组分析法就是根据统计分析的目的要求,把所研究的总体按照一个或者几个标志划分为若干个部分,加以整理,进行观察、分析,以揭示其内在的联系和规律性。 统计分组法的关键问题在于正确选择分组标值和划分各组界限。 三、时间数列及动态分析法时间数列。是将同一指标在时间上变化和发展的一系列数值,按时间先后顺序排列,就形成时间数列,又称动态数列。它能反映社会经济现象的发展变动情况,通过时间数列的编制和分析,可以找出动态变化规律,为预测未来的发展趋势提供依据。时间数列可分为绝对数时间数列、相对数时间数列、平均数时间数列。 时间数列速度指标。根据绝对数时间数列可以计算的速度指标:有发展速度、增长速度、平均发展速度、平均增长速度。 动态分析法。在统计分析中,如果只有孤立的一个时期指标值,是很难作出判断的。如果编制了时间数列,就可以进行动态分析,反映其发展水平和速度的变化规律。 进行动态分析,要注意数列中各个指标具有的可比性。总体范围、指标计算方法、计算价格和计量单位,都应该前后一致。时间间隔一般也要一致,但也可以根据研究目的,采取不同的间隔期,如按历史时期分。为了消除时间间隔期不同而产生的指标数值不可比,可采用年平均数和年平均发展速度来编制动态数列。此外在统计上,许多综合指标是采用价值形态来反映实物总量,如国内生产总值、工业总产值、社会商品零售总额等计算不同年份的发展速度时,必须消除价格变动因素的影响,才能正确的反映实物量的变化。
精品资料 一、对我国30个省市自治区农村居民生活水平作聚类分析 1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察。因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕地面积及农村就业人数。现从2010年的调查资料中
2、将数据进行标准化变换:
3、用K-均值聚类法对样本进行分类如下:
分四类的情况下,最终分类结果如下: 第一类:北京、上海、浙江。 第二类:天津、、辽宁、、福建、甘肃、江苏、广东。 第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南。 第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、。从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平。 二、判别分析 针对以上分类结果进行判别分析。其中将新疆作作为待判样本。判别结果如下:
**. 错误分类的案例 从上可知,只有一个地区判别组和原组不同,回代率为96%。 下面对新疆进行判别: 已知判别函数系数和组质心处函数如下: 判别函数分别为:Y1=0.18x1 +0.493x2 + 0.087x3 + 1.004x4 + 0.381x5 -0.041x6 -0.631x7 Y2=0.398x1+0.687x2 + 0.362x3 + 0.094x4 -0.282x5 + 1.019x6 -0.742x7 Y3=0.394x1-0.197x2 + 0.243x3-0.817x4 + 0.565x5-0.235x6 + 0.802x7 将西藏的指标数据代入函数得:Y1=-1.08671 Y2=-0.62213 Y3=-0.84188 计算Y值与不同类别均值之间的距离分别为:D1=138.5182756 D2=12.11433124 D3=7.027544292 D4=2.869979346 经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符。 三,因子分析: 分析数据在上表的基础上去掉两个耕地面积和农村固定资产投资两个指标。经spss软件分析结果如下:
16种常用的数据分析方法汇总 2015-11-10 分类:数据分析评论(0) 经常会有朋友问到一个朋友,数据分析常用的分析方法有哪些,我需要学习哪个等等之类的问题,今天数据分析精选给大家整理了十六种常用的数据分析方法,供大家参考学习。 一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策 树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前 需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在 可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验
非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致 性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。 列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关;
1、甲乙两地某病的死亡率进行标准化计算时,其标准选择()* A.不能用甲地数据 B.不能用乙地数据 C.不能用甲地和乙地的合并数据 D.可能用甲地或乙地的数据 E.以上都不对 2、实验设计应遵循的基本原则是()* A.随机化、对照、盲法 B.随机化、盲法、配对 C.随机化、重复、配对 D.随机化、齐同、均衡 E.随机化、对照、重复 3、对于一组服从双变量正态分布的资料,经直线相关分析得相关系数r=,对该资料拟合回归直线,则其回归系数b值()* >0 =0 <0 =1 E.不能确定正负 4、以下属于分类变量的是()* 得分 B.心率
C.住院天数 D.性别 E.胸围 5、抽样调查某市正常成年男性与女性各300人,测得其血红蛋白含量( g/L)。欲比较男性与女性的血红蛋白含量是否有差异,假设男性和女性的血红蛋白含量的总体方差相等,应采用()*c A.样本均数与总体均数比较的t检验 B.配对t检验 C.成组t检验 D.配对设计差值的符号秩和检验 E.成组设计两样本比较的秩和检验 6、进行方差分析时,数据应满足()* A.独立性、正态性、大样本 B.独立性、正态性、方差齐性 C.独立性、方差齐性、大样本 D.独立性、正态性、平行性 E.正态性、方差齐性、大样本 7、同类定量资料下列指标,反映样本均数对总体均数代表性的是()* A.四位分数间距 B.标准误 C.变异系数 D.百位分数
E.中位数 8、完全随机设计的方差分析组间变异来自于()* A.个体 B.全部观察值 C.随机因素 D.处理因素 E.随机因素和处理因素 9、统计工作的基本步骤是()* A.及时收集完整、准确的资料 B.综合资料 C.方差分析时要求个样本所在总体的方差相等 D.完全随机设计的方差分析时,组内均方就是误差均方 E.完全随机设计的方差分析时,F=MS组间/MS组内 10、生存分析中的结果变量是()*d A.生存时间 B.寿命表法生存曲线呈阶梯型 C.生存率 D.生存时间与随访结局 E.生存时间与生存率 11、反映血型为AB型的人在人群中所占的比例,宜计算()* A.率
多元统计分析模拟试题(两套:每套含填空、判断各二十道) A卷 1)判别分析常用的判别方法有距离判别法、贝叶斯判别法、费歇判别法、逐步 判别法。 2)Q型聚类分析是对样品的分类,R型聚类分析是对变量_的分类。 3)主成分分析中可以利用协方差矩阵和相关矩阵求解主成分。 4)因子分析中对于因子载荷的求解最常用的方法是主成分法、主轴因子法、极 大似然法 5)聚类分析包括系统聚类法、模糊聚类分析、K-均值聚类分析 6)分组数据的Logistic回归存在异方差性,需要采用加权最小二乘估计 7)误差项的路径系数可由多元回归的决定系数算出,他们之间的关系为 P e= 1?R2 8)最短距离法适用于条形的类,最长距离法适用于椭圆形的类。 9)主成分分析是利用降维的思想,在损失很少的信息前提下,把多个指标转化 为几个综合指标的多元统计方法。 10)在进行主成分分析时,我们认为所取的m(m 统计案例分析及典型例题 §11.1 抽样方法 1.为了了解所加工的一批零件的长度,抽取其中200个零件并测量了其长度,在这个问题中,总体的一个样本是 . 答案 200个零件的长度 2.某城区有农民、工人、知识分子家庭共计2 004户,其中农民家庭1 600户,工人家庭303户,现要从中抽取容量为40的样本,则在整个抽样过程中,可以用到下列抽样方法:①简单随机抽样,②系统抽样,③分层抽样中的 . 答案 ①②③ 3.某企业共有职工150人,其中高级职称15人,中级职称45人,初级职称90人.现采用分层抽样抽取容量为30的样本,则抽取的各职称的人数分别为 . 答案 3,9,18 4.某工厂生产A 、B 、C 三种不同型号的产品,其相应产品数量之比为2∶3∶5,现用分层抽样方法抽出一个容量为n 的样本,样本中A 型号产品有16件,那么此样本的容量n = . 答案 80 例1 某大学为了支援我国西部教育事业,决定从2007应届毕业生报名的18名志愿者中,选取6人组成志愿小组.请 用抽签法和随机数表法设计抽样方案. 解 抽签法: 第一步:将18名志愿者编号,编号为1,2,3, (18) 第二步:将18个号码分别写在18张外形完全相同的纸条上,并揉成团,制成号签; 第三步:将18个号签放入一个不透明的盒子里,充分搅匀; 第四步:从盒子中逐个抽取6个号签,并记录上面的编号; 第五步:所得号码对应的志愿者,就是志愿小组的成员 . 基础自测 随机数表法: 第一步:将18名志愿者编号,编号为01,02,03, (18) 第二步:在随机数表中任选一数作为开始,按任意方向读数,比如第8行第29列的数7开始,向右读; 第三步:从数7开始,向右读,每次取两位,凡不在01—18中的数,或已读过的数,都跳过去不作记录,依次可得到12,07,15,13,02,09. 第四步:找出以上号码对应的志愿者,就是志愿小组的成员. 例2 某工厂有1 003名工人,从中抽取10人参加体检,试用系统抽样进行具体实施. 解 (1)将每个人随机编一个号由0001至1003. (2)利用随机数法找到3个号将这3名工人剔除. (3)将剩余的1 000名工人重新随机编号由0001至1000. (4)分段,取间隔k = 10 000 1=100将总体均分为10段,每段含100个工人. (5)从第一段即为0001号到0100号中随机抽取一个号l . (6)按编号将l ,100+l ,200+l ,…,900+l 共10个号码选出,这10个号码所对应的工人组成样本. 例3 (14分)某一个地区共有5个乡镇,人口3万人,其中人口比例为3∶2∶5∶2∶3,从3万人中抽取一个300人 的样本,分析某种疾病的发病率,已知这种疾病与不同的地理位置及水土有关,问应采取什么样的方法?并写出具体过程. 解 应采取分层抽样的方法. 3分 过程如下: (1)将3万人分为五层,其中一个乡镇为一层. 5分 (2)按照样本容量的比例随机抽取各乡镇应抽取的样本. 300×153=60(人);300× 15 2 =40(人); 300×155=100(人);300×15 2=40(人); 300× 15 3=60(人), 10分 因此各乡镇抽取人数分别为60人,40人,100人,40人,60人. 12分 (3)将300人组到一起即得到一个样本. 14分 练习: 统计分析方法:应用及案例名称: 姓名: 学号: 年级专业:12级电子科学与技术 年月日 成绩: 评语: 指导教师:(签名) 关于某地区361个人旅游情况统计分析报告 一、提出问题 为了了解某地区的旅游情况,发展该地的旅游经济,促进该地人民的生活水平的提高,现通过SPSS软件对某地区361个人旅游情况进行分析,从而更好地掌握该地旅游情况,为经济发展提出决策 二、数据收集 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系 此数据来源于https://www.doczj.com/doc/e78514082.html,/publications/jse/jse_data_archive.htm 三、数据统计处理 1、频数分析 基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性况的基本分布。 Statistics 性别 N Valid 359 Missing 0 首先,对该地区的男女性别分布进行频数分析,结果如下 性别 Frequency Percent Valid Percent Cumulative Percent Valid 女198 55.2 55.2 55.2 男161 44.8 44.8 100.0 Total 359 100.0 100.0 表说明,在该地区被调查的359个人中,有198名女 质量管理常用的七种统计方法 日本质量管理专家石川馨博士将全面质量管理中应用的统计方法分为初级、中级、高级三类,本节将要介绍的七种统计分析方法是他的这种分类中的初级统计分析方法。 日本规格协会10年一度对日本企业推行全面质量管理的基本情况作抽样统计调查,根据1979年的统计资料,在企业制造现场应用的各种统计方法中,应用初级统计分析方法的占98%。 由此可见,掌握好这七种方法,在质量管理中非常之必要;同时,在我国企业的制造现场,如何继续广泛地推行这七种质量管理工具(即初级的统计分析方法),仍然是开展全面质量管理的重要工作。 一、排列图 排列图法又叫帕累特图法,也有的称之为ABC分析图法或主项目图法。它是寻找影响产品质量主要因素,以便对症下药,有的放矢进行质量改善,从而提高质量,以达到取得较好的经济效益的目的。故称排列法。由于这种方法最初是由意大利经济学家帕累特(Pareto)用来分析社会财富分布状况的,他发现少数人占有社会的大量财富,而多数人却仅有少量财富,即发现了“关键的少数和次要的多数”的关系。因此这一方法称为帕累特图法。后来美国质量管理专家朱兰(J.M.Juran)博士将此原理应用于质量管理,作为在改善质量活动中寻找影响产品质量主要因素的一种方法.在应用这种方法寻找影响产品质量的主要因素时,通常是将影响质量的因素分为A、B、C三类,A类为主要因素,B类为次要因素,C 类为一般因素。根据所作出的排列图进行分析得到哪些因素属于A类,哪些属于B类,哪些属于C类,因而这种方法又把它叫做ABC分析图法。由于根据排列图我们可以一目了然地看出哪些是影响产品质量的关键项目,故有的亦把它叫主项目图法。 所谓排列图,它是由一个横坐标、两个纵坐标、几个直方形和一条曲线所构成的图。其一般形式如图1所示,其横坐标表示影响质量的各个因素(即项目),按影响程度的大小从左到右排列;两个纵坐标中,左边的那个表示频数(件数、金额等),右边的那个表示频率(以百分比表示);直方形表示影响因素,有直方形的高度表示该因素影响的大小;曲线表示各影响因素大小的累计百分数,这条曲线称为帕累特曲线。 二、因果分析图法 因果分析图法是一种系统地分析和寻找影响质量问题原因的简便而有效的图示方法。因其最初是由日本质量管理专家石川馨于1953年在日本川琦制铁公司提出使用的,故又称为石川图法。由于因果图形似树枝或鱼刺,故也有称之为树枝图法或鱼刺图法。另外,还有的 稳健统计方法应用实例分析 摘要本文介绍了稳健统计技术发展历史,有关统计量的基本术语及统计方法,并结合实例对实验室能力验证结果进行分析。 关键词稳健统计;中位值;四分位距;实例分析 1 基本原理简介 稳健统计技术至20世纪60年代兴起,80年代初基本定型,20世纪末得到广泛的应用和普及。由于采用的是中位值和标准化四分位距,从而减少了极端结果对平均值和标准偏差的影响。对每一个测定项目将计算下列总体统计量,即结果总数(N)、中位值(Median)、标准化四分位距(Norm IQR)、稳健变异系数(Robust CV)、极小值(Minimum)、极大值(Maximum)和变动范围(Range)。 在实验室能力验证的数据统计与分析中,我们对每个实验室给出相应的实验室间Z比分数(ZB)和实验室内Z比分数(ZW),并依此评价每个参加实验室的能力。 1.1有关统计量的含义结果总数 有关统计量的含义结果总数:在统计分析中某项测定结果的总数。 中位值:一组按大小顺序排列结果数值的中间值,若N为奇数,则X(N+1)/2的结果数值为中位值,若N为偶数,则两个中心值的平均值为中位值,即(XN/2+ XN/2+1)/2。 标准化四分位距:对一组按顺序排列的数据,上四分位值Q3与下四分位值Q1之间的差称为四分位距(IQR),即IQR=Q3-Q1。IQR乘以因子0.7413得标准化四分位距(Norm IQR),它是稳健统计技术处理中用于表示数据分散程度的一个量,其值相当于正态分布中的标准偏差(SD)。 稳健变异系数:标准化四分位距除以中位值,并以百分数表示。 极大值:一组结果中的最大值。 极小值:一组结果中的最小值。 变动范围:极大值减极小值。 1.2 标准化和与标准化差 一对样品A和B中某项结果之和除以,称为标准化和(S),即,一组S数据 常用统计分析方法 排列图 因果图 散布图 直方图 控制图 控制图的重要性 控制图原理 控制图种类及选用 统计质量控制是质量控制的基本方法,执行全面质量管理的基本手段,也是CAQ系统的基础,这里简要介绍制造企业应用最广的统计质量控制方法。 常用统计分析方法与控制图 获得有效的质量数据之后,就可以利用各种统计分析方法和控制图对质量数据进行加工处理,从 中提取出有价值的信息成分。 常用统计分析方法 此处介绍的方法是生产现场经常使用,易于掌握的统计方法,包括排列图、因果图、散布图、直方图等。 排列图 排列图是找出影响产品质量主要因素的图表工具.它是由意大利经济学家巴洛特(Pareto)提出的.巴洛特发现人类经济领域中"少数人占有社会上的大部分财富,而绝大多数人处于贫困状况"的现象是一种相当普遍的社会现象,即所谓"关键的少数与次要的多数"原理.朱兰(美国质量管理学家)把这个原理应用到质量管理中来,成为在质量管理中发现主要质量问题和确定质量改进方向的有力工具. 1.排列图的画法 排列图制作可分为5步: (1)确定分析的对象 排列图一般用来分析产品或零件的废品件数、吨数、损失金额、消耗工时及不合格项数等. (2)确定问题分类的项目 可按废品项目、缺陷项目、零件项目、不同操作者等进行分类。 (3)收集与整理数据 列表汇总每个项目发生的数量,即频数fi、项目按发生的数量大小,由大到小排列。最后一项是无法进一步细分或明确划分的项目统一称为“其它”。 (4)计算频数fi、频率Pi和累计频率Fi 首先统计频数fi,然后按(1)、(2)式分别计算频率Pi和累计频率Fi (1) 式中,f为各项目发生频数之和。 (2) (5)画排列图统计案例分析及典型例题
统计分析方法:应用及案例
质量管理常用的七种统计方法1
稳健统计方法应用实例分析
常用统计分析方法
相关主题
文本预览