
视图名字说明
1. V$FIXED_TABLE 列出当前发行的固定对象的说明
这个视图显示数据库中所有动态性能表、视图和导出表。某些V$表(如V$ROLLNAME) 涉及实际的表,因此没有列出。
列数据类型说明
NAME V ARCHAR2(30) 对象名
OBJECT_ID NUMBER 固定对象的标识符
TYPE V ARCHAR2(5) 对象类型:TABLE、VIEW
TABLE_NUM NUMBER 如果动态性能表为TABLE类型,
则为标识它的号码
2. V$INSTANCE 显示当前实例的状态
这个视图显示当前实例的状态。这个版本的V$INSTANCE与前面版本的的V$INSTANCE 不兼容。
列数据类型说明
INSTANCE_NUMBER NUMBER 实例注册所用的实例号。对
应与INSTANCE _NUMBER
初始化参数。可参阅
INSTANCE_NUMBER
INSTANCE_NAME V ARCHAR2(16) 实例名
HOST_NAME V ARCHAR2(64) 主机名
VERSION V ARCHAR2(17) RDBMS版本
STARTUP_TIME DATE 实例启动的时间
STATUS V ARCHAR2(7) STARTED/MOUNTED/OPE
N
STARTED:启动安装后或数
据库关闭后,OPEN:启动后
或数据库打开后PARALLEL V ARCHAR2(3) YES/NO:是否并行服务器模
式
THREAD# NUMBER 实例打开的重做线程ARCHIVER V ARCHAR2(7) STOPPED/STARTED/FAILE
D;FAILED表示归档程序最
后一次归档某个日志失败,
但在5分钟内将重试
LOG_SWITCH_WAIT V ARCHAR2(11) 正在等待
ARCHIVELOG/CLEAR
LOG/ CHECKPOINT事件日
志切换。注意:如果ALTER
SYSTEM SWITCH
LOGFILE挂起,但在当前联
机重做日志中还有空间则
这个值为NULL
LOGINS V ARCHAR2(10) ALLOWED/RESTRICTED SHUTDOWN_PENDING
V ARCHAR2(3) YES/NO
DATABASE_STATUS V ARCHAR2(17) 数据库的状态
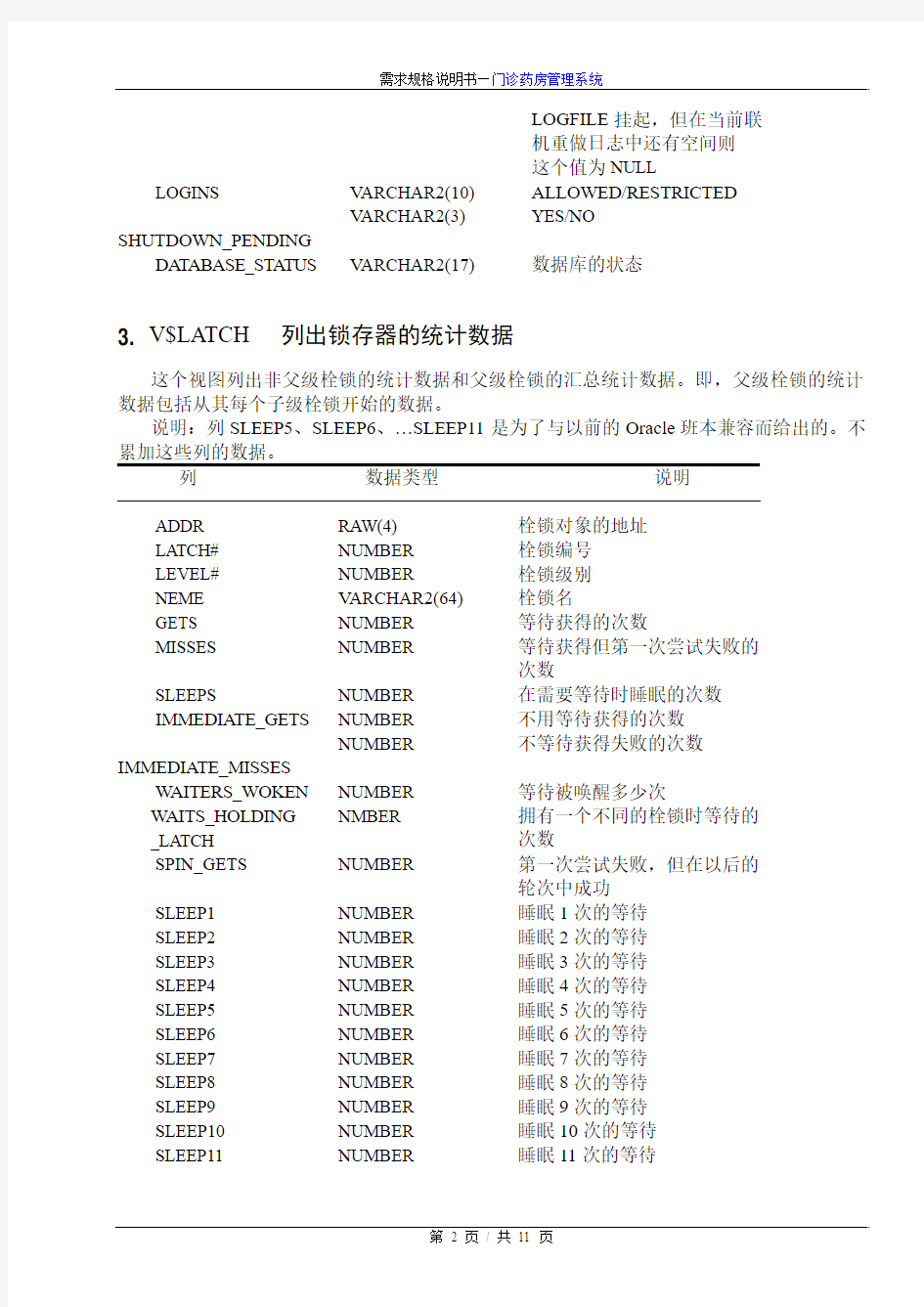
3. V$LATCH 列出锁存器的统计数据
这个视图列出非父级栓锁的统计数据和父级栓锁的汇总统计数据。即,父级栓锁的统计数据包括从其每个子级栓锁开始的数据。
说明:列SLEEP5、SLEEP6、…SLEEP11是为了与以前的Oracle班本兼容而给出的。不累加这些列的数据。
列数据类型说明
ADDR RAW(4) 栓锁对象的地址
LATCH# NUMBER 栓锁编号
LEVEL# NUMBER 栓锁级别
NEME V ARCHAR2(64) 栓锁名
GETS NUMBER 等待获得的次数
MISSES NUMBER 等待获得但第一次尝试失败的
次数
SLEEPS NUMBER 在需要等待时睡眠的次数
IMMEDIATE_GETS NUMBER 不用等待获得的次数
IMMEDIATE_MISSES
NUMBER 不等待获得失败的次数
WAITERS_WOKEN NUMBER 等待被唤醒多少次
WAITS_HOLDING _LATCH NMBER 拥有一个不同的栓锁时等待的
次数
SPIN_GETS NUMBER 第一次尝试失败,但在以后的
轮次中成功
SLEEP1 NUMBER 睡眠1次的等待
SLEEP2 NUMBER 睡眠2次的等待
SLEEP3 NUMBER 睡眠3次的等待
SLEEP4 NUMBER 睡眠4次的等待
SLEEP5 NUMBER 睡眠5次的等待
SLEEP6 NUMBER 睡眠6次的等待
SLEEP7 NUMBER 睡眠7次的等待
SLEEP8 NUMBER 睡眠8次的等待
SLEEP9 NUMBER 睡眠9次的等待
SLEEP10 NUMBER 睡眠10次的等待
SLEEP11 NUMBER 睡眠11次的等待
4. V$LIBRARYCACHE 有关库缓存性能的统计数据
这个视图包含库高速缓存性能与活动的有关统计数据。
列数据类型说明
NAMESPACE V ARCHAR2(15) 名称空间
GETS NUMBER 为这个名称空间中的对象请求
某个锁的次数
GETHITS NUMBER 在内存中找到某个对象的句柄
的次数
GETHITRATIO NUMBER GETHITS与GETS的比例
PINS NUMBER 为这个名称空间中的对象请求
PIN的次数
PINHITS NUMBER 在内存中找到相应库对象的所
有元数据片的次数PINHITRATIO NUMBER PINHITS与PINS的比例
RELOADS NUMBER 自某个对象句柄建立以来,进
行该对象的非第一次PIN的任
意PIN,这样需要将对象从磁
盘装入
INV ALIDATIONS NUMBER 此名称空间中的对象由于相关
的对象被修改而无效的总次数DLM_LOCK_
REQUESTS
NUMBER GET请求锁定实例锁的次数
DLM_PIN_REQUESTS NUMBER PIN请求锁定实例锁的次数DLM_PIN_RELEASES NUMBER 发布请求PIN实例锁的次数DLM_INV ALIDATION
_REQUESTS
NUMBER GET请求无效实例锁的次数
DLM_INV ALIDATIONS NUMBER 从其他实例接收到的无效ping
的次数
5. V$ROLLSTAT 列出联机的回滚段的名字
这个视图包含回退段统计数据。
列数据类型说明USN NUMBER 回退段号
EXTENTS NUMBER 回退段中的区数
RSSIZE NUMBER 回退段以字节极的尺寸WRITES NUMBER 写到回退段的字节数XACTS NUMBER 活动的事务处理数
GETS NUMBER 标题获得的数目
WAITS NUMBER 标题等待的数目
OPTSIZE NUMBER 回退段的最佳尺寸
HWMSIZE NUMBER 回退段尺寸的高水位标记
SHRINKS NUMBER 回退段尺寸减少的倍数
WRAPS NUMBER 回退段缠绕的倍数
EXTENDS NUMBER 回退段段尺寸扩展的倍数
A VESHRINK NUMBER 平均收缩尺寸
A VEACTIVE NUMBER 活动区随时间平均的当前尺
寸
STATUS V ARCHAR2(15) 回退段状态
CUREXT NUMBER 当前区
CURBLK NUMBER 当前块
6. V$ROWCACHE 显示活动数据字典的统计
这个视图显示数据字典活动的统计数据。每行包含一个数据字典高速缓存的统计数据。
列数据类型说明
CACHE# NUMBER 行高速缓存ID号
TYPE V ARCHAR2 父级或子级行高速缓存类型
SUBORDINATE# NUMBER 子级集合号
PARAMETER NUMBER 确定数据字典高速缓存中项
数的初始化参数名
COUNT NUMBER 高速缓存中项的总数
USAGE NUMBER 包含有效数据的高速缓存项
数
FIXED NUMBER 高速缓存中的固定项数
GETS NUMBER 请示数据对象信息的总数
GETMISSES NUMBER 导致高速缓存未中的数据请
求数
SCANS NUMBER 扫描请求数
SCANMISSES NUMBER 查找高速缓存中的数据扫描
失败的次数
SCANCOMPLETES NUMBER 对于子级项的列表,完全扫
描列表的次数
MODIFICATIONS NUMBER 插入、更新与删除的次数
FLUSHES NUMBER 对磁盘进行刷新的次数
DLM_REQUESTS NUMBER DLM请求的次数
DLM_CONFILICTS NUMBER DLM冲突的次数
DLM_RELEASES NUMBER DLM释放的次数
7. V$SGA 有关系统全局区的总结信息
这个视图包含系统全局区的摘要信息。
列数据类型说明
NAME V ARCHAR2 SGA组件名
V ALUE NUMBER 以字节表示的内存尺寸
8. V$SGASTAT 有关系统全局区的详细信息
这个视图包含系统全局区的详细信息
列数据类型说明
NAME V ARCHAR2 SGA组件名
BYTES NUMBER 以字节表示的内存尺寸
POOL V ARCHAR2 指出NAME中内存驻留的池
子。其值可以是:LARGE
POO——从大型池中分配的
内存SHARED POOL—从共
享池中分配的内存
9. V$SORT_USAGE 显示临时段的大小及会话,可以看出哪些进程在进行硬盘排序
这个视图描述排序用法。
列数据类型说明
USER V ARCHAR2(30) 请求临时空间的用户
SESSION_ADDR RAW(4) 共享SQL游标的地址
SESSION_NUM NUMBER 会话的系列号
SQLADDR RAW(4) SQL语句的地址
SQLHASH NUMBER SQL语句的散列值
TABLESPACE V ARCHAR2(31) 在其中分配空间的表空
间
CONTENTS V ARCHAR2(9) 指出表空间是否是
TEMPORARY/
PERMANENT
SEGFILE# NUMBER 初始区的文件号
SEGBLK# NUMBER 初始区的块号
EXTENTS NUMBER 分配给排序的区
BLOCKS NUMBER 分配给排序的以块表示
的区
SEGFNO NUMBER 初始区的相对文件号
10. V$SQLAREA 列出共享区的统计。包括每个SQL串有一个行。提供SQL 语句在内存、分析及执行准备的统计。文本限制在1000个字符内,整个文本从V$SQLTEXT中剪出64个有效的字节。
这个视图列出没有GROUP BY子句的共享SQL区的有关统计数据,而且对录入的原始SQL文本的每个孩子包含一行。
列数据类型说明
SQL_TEXT V ARCHAR2(1000) 当前游标的SQL文本的前8位字
符
SHARABLE_MEM NUMBER 这个子级游标使用的以字节
表示的共享内存量
PERSISTENT_MEM NUMBER 这个子级游标使用的以字节
表示的持久内存量
RUNTIME_MEM NUMBER 这个子级游标使用的临时结构
尺寸
SORTS NUMBER 为这个子级游标完成的排序数
LOADED_VERSIONS NUMBER 如果装载了上下文堆栈,为1,
否则为0
OPEN_VERSIONS NUMBER 如果锁定了子级游标,为1,
否则为0
USERS_OPENING NUMBER 执行相应语句的用户数目
EXECUTIONS NUMBER 自这个对象装入库高速缓存以
来,在这个对象上的执行数目
USERS_EXECUTING NUMBER 执行这个语句的用户数目
LOADS NUMBER 对象被装入或重新装入的数目
FIRST_LOAD_TIME V ARCHAR2(19) 父级创建时间的时间戳
INV ALIDATIONS NUMBER 使子级游标无效的次数
PARSE_CALLS NUMBER 这个子级游标的分析调用数目
DISK_READS NUMBER 这个子级游标的磁盘读取数目
BUFFER_GETS NUMBER 这个子级游标的缓冲区获取数
目
ROWS_PROCESSED NUMBER 分析SQL语句返回的总行数
COMMAND_TYPE NUMBER Oracle命令类型定义
OPTIMIZER_MODE V ARCHAR2(10) SQL语句在其下执行的模式
OPTIMIZER_COST NUMBER 优化程序给出这个查询的代价
PARSING_USER_ID NUMBER 最初建立这个子游标的用户的
用户ID
PARSING_SCHMA_ID NUMBER 最初用来建立这个子级游标的
模式ID
KEPT_VERSIONS NUMBER 指出这个子级游标是否已经利
用DBMS_SHARED_POOL程序
包标记为固定在高速缓存中ADDRESS RAW(4) 这个子级游标的双亲的句柄地
址
TYPE_CHK_HEAP RAW(4) 这个子级游标的类型描述符的
检查堆栈
HASH_V ALUE NUMBER 库高速缓存中的父级语句的散
列值
CHILD_NUMBER NUMBER 这个子级游标的编号
MODULE V ARCHAR2(64) 包含第一次分析SQL语句执行
时的模块名,正如调用DBMS_
APPLICATION_INFO.SET_MO
DEL所设置的那样
MODEL_HASH NUMBER 在MODULE列中指定的模块的
散列值
ACTION V ARCHAR2(64) 包含第一次分析SQL语句时执
行的动作名,正如调用DBMS_
APPLICATION_INFO.SET_MO
DEL所设置的那样
ACTION_HASH NUMBER 在ACTION列中指定的动作的
散列值
SERIALIZABLE_ABORT NUMBER 每个游标的串行化事务处理失
败,产生ORA-8177错误的次数
11. V$SQLTEXT 在SGA中属于共享SQL光标的SQL语句内容。
这个视图包含属于SGA共享SQL游标的SQL语句文本。
列数据类型说明ADDRESS RAW(4) 与HASH_V ALUE一道用
来唯一标识一个高速缓存
游标
HASH_V ALUE NUMBER 与ADDRESS一道用来唯
一标识一个高速缓存游标PIECE NUMBER 用来排序SQL文本片段的
编号
SQL_TEXT V ARCHAR2 一列包含SQL文本的一个
片段
COMMAND_TYPE NUMBER SQL语句(SELECT、
INSERT)等的类型代码
12. V$SYSSTAT 包括基本的实例统计数据
这个视图显示列在V$SESSTAT和V$SYSSTA T表中的统计数据的解码统计数据名。详细信息,请参阅V$SESSTAT和SYSSTAT。
列数据类型说明
STATISTIC# NUMBER 统计数据号
NAME V ARCHAR2 统计数据名。参见表B-13
CLASS NUMBER 1(用户);2(重做);4
(排队);8(高速缓存);
16(操作系统);32(并
行服务器);128(调试)
表B-13列出了V$ATATNAME返回的普通Oracle统计数据。
表B-13 V$SESSETAT和V$SYSSTAT的统计数据名
此会话使用的CPU 调用开始时使用的CPU
建立的CR块引用的高速缓存提交SCN
引用的提交SCN 为CR转换的当前块
扫描的DBWR缓冲区DBWR检查点缓冲区写入
DBWR检查点DBWR强制写入
找到的DBWR可用缓冲区DBWRLRL扫描
DBWR构造可用空间请求访问被写入缓冲区的DBWR
DBWR事务处理表写入DBWR累加扫描深度
并行化DDL语句DBWR撤消块写入
并行化DML语句并行化DFO数
读写OShars OS所有其他睡眠时间
OS Input块OS数据页故障睡眠时间
OS Karnel页故障睡眠时间OS强制上下文切换
接收到的OS Messages OS消息发送
OS Minor页故障OS其他系统陷阱CPU时间
OS Output块OS进程堆尺寸
OS Process堆栈尺寸OS信号接收
OS交换OS系统调用CPU时间
OS系统调用OS文本叶故障睡眠时间
OS用户级CPU时间OS用户锁等待睡眠时间
OS主动环境切换OS等待CPU(延迟时间)
接收到的PX本地消息PX本地消息发送
接收到的PX远程消息PX远程消息发送
串行卸载的并行操作SQL*Net从客户机往返
SQL*Net往返数据库连接SCN批处理的不必要的进程清除
完成的后台检查点后台检查点开始
后台超时未固定缓冲区计数
固定缓冲区计数通过SQL*Net从客户机接收的字节通过SQL*Net从数据库连接接收到的
通过SQL*Net发送到客户机的字节字节
取得快照的SCN调用:kcmgss 通过SQL*Net发送到数据库连接的字
节
对kcmgas的调用调用kcmgss
对kcmgrs的调用更改写入时间
清除和回退一致性读获取只清除一致性读获取
簇键扫描块获取簇键扫描
提交清除失败;块丢失提交清除故障:缓冲区被写入
提交清除失败;回叫失败提交清除故障:不能固定
提交清除失败;正在进行热备份提交清除故障:写禁止
提交清除一致性获取
游标验证数据库块更改
数据库块获取延迟(当前)块清除应用程序
查到灰缓冲区排队转换
排队死锁排队释放
排队请求排队超时
排队等待交死锁
执行计数查到空闲缓冲区
请求的空闲缓冲区全局高速缓存转换时间
全局高速缓存转换超时全局高速缓存转换
全局高速缓存cr块接收时间全局高速缓存cr块接收
全局高速缓存从磁盘读取全局高速缓存cr超时
全局高速缓存延迟全局高速缓存顺利转换
全局高速缓存空闲列表等待全局高速缓存获取时间
全局高速缓存转换时间全局高速缓存排队转换
全局锁同义词转换@@@@@ 全局锁异步获取
全局锁转换时间全局锁转换(异步)
全局锁转换(非异步)全局锁获取时间
全局高速缓冲散栓锁等待全局锁获取(异步)
全局锁获取(非异步)全局锁释放
全局锁同义词转换@@@@@ 全局锁同步获取
热缓冲区移动到LRU的标题立即(CR)清除应用程序
立即(CURRENT)块清除应用程序实例恢复数据库冻结计数
kcmccs调用取得当前scn kcmccs读取scn不转到DCM
kcmccs等待批处理登录累计
当前登录收到消息
消息发送本地散列算法执行
本地散列算术失败不用转到DLM取得的下一scm
无缓冲区固定计数非工作一致性读获取
累计打开的游标当前打开的游标
打开替换文件打开请求高速缓存替换
分析计数(硬)分析计数(总计)
分析CPU时间占用的分析时间
物理读取物理写
直接物理读取直接物理写
非检查点物理写非检查点物理写
查到固定换冲区处理最后非空闲时间
并行化查询恢复数组读取时间
恢复数组读取恢复块读取
递归调用递归cpu用法
写入重做块重做缓冲区分配项
重做项重做日志空间请求
重做日志空间等待时间重做日志切换中断
重做排序标记重做尺寸
重估同步时间重做同步写
重做消耗重做写时间
重做写入程序闭锁时间重做写
远程实例撤消块写入远程实例撤消标题写入
应用回退更改撤消记录回退段仅一致性读取获取
可串行终止会话连接时间
会话游标高速缓存计数会话游标高速缓存命中
会话逻辑读取会话pga内存
最大会话pga内存会话存储过程空间
会话uga内存最大会话uga内存
排序(磁盘)排序(内存
排序(行)总计灰队列长度
按行标识符的表取数表取数据连续行
获取的表扫描块获得表扫描行
表扫描(高速缓存分区)表扫描(直接读取)
表扫描(长表)表扫描(行标识范围)
表扫描(短表)总的文件打开
事务处理锁后台获取时间事务处理锁后台获取
事务处理锁前台请求事务处理锁前台等待时间
事务处理回退事务处理表一致性读取回退
应用事务处理表一致性读取撤消记录用户调用
用户提交用户回退
其他信息:在某些平台上,NAME和CLASS列将包含其他操作系统的专门数据。
13. V$SYSTEM_EVENT 包括一个事件的总等待时间
这个视图包含所有等待某个事件的相关信息。注意,TIME_WAITED和A VERAGE_WAIT 列在那些不支持快速时间机制的平台上将包含零值。如果在这些平台上运行,并且希望此列反映真正的等待时间,则必须设置参数文件中的TIMED_STATISTICS
为TRUE。请注意,这样做对系统性能有轻微的负面影响。更多的信息,请参阅“TIMED_STATISTICS”。
列数据类型说明
EVENT V ARCHAR2(64) 等待事件的名称
TOTAL_WAITS NUMBER 这个事件的总等待次数
TOTAL_TIMEOUTS NUMBER 这个事件的总等待超时
次数
TIME_WAITED NUMBER 这个事件的总等待时间
数,以百分之一秒计
A VERAGE_WAIT NUMBER 这个事件的平均等待时
间,以百分之一秒计
14. V$WAITSTAT 列出块竞争统计数据,只有当时间统计参数被“使能”时系统才能对其更新。
此视图列出块争用统计信息。此表只能在启用计时统计信息时更新。
列数据类型说明
CLASS V ARCHAR2 块类
COUNT NUMBER 针对块类的操作的等待
次数
TIME NUMBER 针对块类的操作的所有
等待次数的总和
视图名字说明
DBA_TABLES 表的存储、行及块等的信息
DBA_INDEXES 索引的存储、行及块的信息
INDEX_STATS 索引深度及差量(dispersion )信息
DBA_DATA_FILES 数据文件位置、名字及大小信息
DBA_SEGMENTS 数据库中任意能占用空间的对象的有关信息
DBA_HISTOGRAMS 定义信息的直方图
1.视图的概述 视图其实就是一条查询sql语句,用于显示一个或多个表或其他视图中的相关数据。视图将一个查询的结果作为一个表来使用,因此视图可以被看作是存储的查询或一个虚拟表。视图来源于表,所有对视图数据的修改最终都会被反映到视图的基表中,这些修改必须服从基表的完整性约束,并同样会触发定义在基表上的触发器。(Oracle支持在视图上显式的定义触发器和定义一些逻辑约束) 2.视图的存储 与表不同,视图不会要求分配存储空间,视图中也不会包含实际的数据。视图只是定义了一个查询,视图中的数据是从基表中获取,这些数据在视图被引用时动态的生成。由于视图基于数据库中的其他对象,因此一个视图只需要占用数据字典中保存其定义的空间,而无需额外的存储空间。 3.视图的作用 用户可以通过视图以不同形式来显示基表中的数据,视图的强大之处在于它能够根据不同用户的需要来对基表中的数据进行整理。视图常见的用途如下: 通过视图可以设定允许用户访问的列和数据行,从而为表提供了额外的安全控制 隐藏数据复杂性 视图中可以使用连接(join),用多个表中相关的列构成一个新的数据集。此视图就对用户隐藏了数据来源于多个表的事实。 简化用户的SQL 语句 用户使用视图就可从多个表中查询信息,而无需了解这些表是如何连接的。 以不同的角度来显示基表中的数据 视图的列名可以被任意改变,而不会影响此视图的基表 使应用程序不会受基表定义改变的影响 在一个视图的定义中查询了一个包含4 个数据列的基表中的3 列。当基表中添加了新的列后,由于视图的定义并没有被影响,因此使用此视图的应用程序也不会被影响。 保存复杂查询 一个查询可能会对表数据进行复杂的计算。用户将这个查询保存为视图之后,每次进行类似计算只需查询此视图即可。
六、TOP-N 八、数据字典与动态性能视图 第一节什么是视图 一、创建视图: 创建视图的主法是:CREATE [OR REPLACE] VIEW 视图名AS 查询语句。例如,如下语句就创建了一个视图: sid=41 pid=17> create view ydsp_v1 as select nvl(spbh,'待定') spbh,sum(nvl(jg,0)) sum from ydsp group by spbh; 视图已创建。 视图的名字是YDSP_V1。 哪么,它有什么用呢?很简单,如果以后你再想查看SPBH(商品编号)对JG(价格)列进行分组求和的结果,不必再使用“select nvl(spbh,'待定') spbh,sum(nvl(jg,0)) sum from ydsp group by spbh; ”,直接SELECT 视图即可: sid=41 pid=17> select * from ydsp_v1; SPBH SUM ---- ---------- 101 43500 待定0 102 6000 201 9800 202 9800 这样比你每次输入分组查询简单一些。我们可以将常用的比较复杂的查询操作像上面这样,建立为视图。这样每次查询视图就可看到结果,比输入复杂查询语句更省事。 创建视图命令中的[OR REPLACE]的意义,REPLACE有替换的意思。它的主要作用是修改视图的定义,也就是修改视图内的SQL语句。比如说上面的YDSP_V2,我想为YDSP_V2中增加一个COUNT(*),命令如下:create or replace view ydsp_v1 as select nvl(spbh,'待定') spbh,sum(nvl(jg,0)),count(*) CT sum from ydsp group by spbh; 这个命令非常简单,我不再试了。这条命令的意思是把YDSP_V1再创建一次。用新的YDSP_V1替代老的YDSP_V1,也就是重建视图。视图在创建后,它的结构、定义等信息不能修改,要想改变视图的定义信息,只能使用CREATE OR REPLACE,用新的定义重建视图。 在创建视图时,对这种使用各种函数,或运算表达式的列,一定要起别名,如没有别名视图创建就会失败,例如: sid=41 pid=17> create view ydsp_v1 as select nvl(spbh,'待定') ,sum(nvl(jg,0)) SUM from ydsp group by spbh; create view ydsp_v1 as select nvl(spbh,'待定') ,sum(nvl(jg,0)) SUM from ydsp group by spbh * 第 1 行出现错误: ORA-00998: 必须使用列别名命名此表达式 我把NVL()函数后的别名去掉了,创建失败。ORACLE报出的错误,就是说“我在这里缺少列的别名”。 为什么一定要为列起别名,因为一个创建好的视图,就像一个表一样,就像我们刚开始所举的例子,它有两个列:SPBH和SUM。用户可以通过select spbh,sum from ydsp_v1来显示这两个列中的数据。像nvl(spbh,'待定')这样的表达式,如果你没有指定别名的话,ORACLE将无法确定在视图中,它的列名是什么。因此,在创建视图时,对于这种复杂的表达式,一定要为它起别名。 当使用SELECT查询一个视图时,和查询表是一某一样的,我们就可以把视图当表一样去查询。SELECT 语句中,所有适用于表特性,都同样适用性视图。比如我们可以增长条件: sid=41 pid=17> select * from ydsp_v1 where spbh<>'待定'; SPBH SUM ---- ---------- 101 43500
ORACLE优化总结和注意事项 本文档中对优化方法进行详述,并对在优化过程中发现的一些问题进行总结。列出ORACLE的一些注意事项 注意事项: 1.安装的过程中,请务必进行正确安装。 2.当安装过程中出现错误的时候,最好清除原有遗留信息,进行重装,否则在数据库运行 的过程中可能会出现各种诡异的问题。 3.当数据库安装的过程中如果有警告信息,请记录下来,存档,方便排查数据库问题 4.安装的过程中请选择OLTP的数据模板Transaction Processing 5.安装过程中文件的创建
Controlfile、Datafiles、Redo Log Groups如果条件允许,最好分别放于不同的磁盘上。其中Controlfile和Redo Log Groups要尽量保证放在不同的磁盘上 6.其中Redo Log Groups重做日志组最好建5组以上,每个文件大小在1G以上,最大不超 过3G,避免出现进行check_point的时候造成buffer wait 导致数据库宕机 7.检查/etc/hosts文件 配置最后一行信息,将当前的主机名和ip配对起来,避免应用服务连接数据库导致的性能损耗 8.安装完成后,请启动数据库确保数据库基本安装成功 步骤: sqlplus /nolog connect /as sysdba startup//启动数据库实例 exit//退出sqlplus lsnrctl start//启动监听
emctl start dbconsole 上述步骤如果执行完,没有报错,则说明数据库基本安装正确,并可正常运行。如果执行上述操作的时候出现了问题,则说明数据库安装的过程中出现了某些问题,即使数据库实例当前可以启动连接,但是在以后稳定服务的过程中也是有可能会出现一些数据库问题的。 配置OCI连接 因为当前应用服务采用OCI连接的方式,因此在运行应用服务之前要配置OCI的连接条件 1、需求软件: 如果应用服务是跟ORACLE数据库安装在一台机器上,则不需要额外软件,直接进入第2步即可 如果应用服务是跟ORACLE数据库分开部署,则需要在部署应用服务的机器上安装一个客户端(精简客户端即可大小几M)需要从官方网站下载三个文件instantclient-basic-linux-x86-64-10.2.0.3-20070103.zip instantclient-sqlplus-linux-x86-64-10.2.0.3-20070103.zip instantclient-jdbc-linux-x86-64-10.2.0.3-20070103.zip 解压到同一个目录中,同时在该目录下新建一个文件tnsnames.ora文件,文件中添加以下内容 # Generated by Oracle configuration tools. HMS = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.15.61)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = hms) ) )
Previous Next View PDF 6 Data Dictionary and Dynamic Performance Views Previous Next View PDF 第6章数据字典和动态性能视图 This chapter describes the central set of read-only reference tables and views of each Oracle database, known collectively as the data dictionary. The chapter also describes the dynamic performance views, which are special views that are continuously updated while a database is open and in use. 本章介绍了每个 Oracle 数据库都具有的只读参考表和视图中最重要的部分,统称为数据字典。本章还介绍了动态性能视图,它们是一些会在数据库处于打开状态时不断更新的特殊视图。 This chapter contains the following sections: 本章包含以下各节: ?Overview of the Data Dictionary o Contents of the Data Dictionary o Storage of the Data Dictionary o How Oracle Database Uses the Data Dictionary ?Overview of the Dynamic Performance Views o Contents of the Dynamic Performance Views o Storage of the Dynamic Performance Views ?Database Object Metadata ?数据字典概述 o数据字典的内容 o数据字典存储 o Oracle数据库如何使用数据字典?动态性能视图概述 o动态性能视图的内容 o动态性能视图的存储 ?数据库对象元数据 Overview of the Data Dictionary 数据字典概述 An important part of an Oracle database is its data dictionary, which is a read-only set of tables that provides administrative metadata about the database. A data dictionary contains information such as the following: Oracle 数据库的一个重要部分是它的数据字典,它是一组提供有关数据库管理元数据的只读表。数据字典包含如下信息: ?The definitions of every schema object in the database, including default values for columns and integrity constraint information ?在数据库中每个模式对象的定义,包括列的默认值和完整性约束信息 ?The amount of space allocated for and currently used by the schema objects ?分配给模式对象的空间量及当前已使用量 ?The names of Oracle Database users, privileges and roles granted ?Oracle数据库用户的名称、授予用户的权限和角色、和与用户相关
Oracle创建视图 在本练习中,将在HR模式中练习如何创建视图,查询视图的定义,并对视图进行更新。 (1)创建一个视图EMPLOYEES_IT,该视图是基于HR模式中的EMPLOYEES表,并且该视图只包括那些部门为IT的员工信息。在创建视图时使用WITH CHECK OPTION,防止更新视图时,输入非IT部门的员工信息。 create or replace view employees_it as select * from employees where department_id =( select department_id from departments where departments.department_name='IT') with check option; (2)创建一个联接视图EMP_DEPT,它包含EMPLOYEES表中的列和DEPARTMENTS 表中的DNAME列。 create or replace view emp_dept as select t1.employee_id,t1.first_name,https://www.doczj.com/doc/e86522967.html,st_name,t1.email, t1.phone_number,t1.hire_date,t1.job_id,t1.salary,t2.department_name from employees t1,departments t2 where t1.department_id=t2.department_id with check option; (3)Oracle针对创建的视图,只在数据字典中存储其定义。输入并执行如下的语句查看创建的视图定义: select text from user_views where view_name=UPPER('emp_dept'); (4)查看视图各个列是否允许更新。 col owner format a20 col table_name format a20 col column_name format a20 select * from user_updatable_columns where table_name=UPPER('emp_dept');
fnd_user 系统用户表 fnd_application 应用信息表 FND_PROFILE_OPTIONS_VL 系统配置文件 fnd_menus 菜单 fnd_menu_entries_tl FND_NEW_MESSAGES 消息表 FND_FORM 表单表 FND_CONCURRENT_PROGRAMS_VL 并发程序视图 FND_CONCURRENT_PROGRAMS_TL FND_CONCURRENT_PROGRAMS FND_DESCR_FLEX_COL_USAGE_VL FND_DESCR_FLEX_COL_USAGE_TL FND_DESCR_FLEX_COLUMN_USAGES FND_EXECUTABLES_FORM_V 可执行并发程序视图FND_EXECUTABLES_TL FND_EXECUTABLES FND_DESCRIPTIVE_FLEXS FND_CONC_REQ_SUMMARY_V 并发请求视图FND_CONCURRENT_REQUESTS FND_RESPONSIBILITY 职责表
FND_RESPONSIBILITY_VL 职责FND_USER_RESP_GROUPS 用户职责 fnd_flex_value_sets 值集表 FND_FLEX_VALUES FND_IREP_ALL_INTERFACES 接口表 FND_IREP_CLASSES Fnd_Irep_Classes_Tl fnd_territories_vl 国家视图 fnd_log_messages 日志表 fnd_form_functions 功能 FND_DOCUMENT_SEQUENCES 单据序列 FND_DOC_SEQUENCE_ASSIGNMENTS 序列分配 fnd_id_flexs 关键弹性域定义表 FND_ID_FLEX_STRUCTURES 弹性域结构表 FND_ID_FLEX_SEGMENTS 弹性域段表 fnd_descriptive_flexs 描述性弹性域属性表 FND_DESCR_FLEX_CONTEXTS 弹性域列类别表 FND_DESCR_FLEX_COLUMN_USAGES 弹性域列类别属性表FND_FLEX_VALUE_SETS 值集表 FND_FLEX_VALUES 值表 Fnd_Flex_Values_Tl 值描述表
ORACLE常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not nul l],..) 根据已有的表创建新表: A:select * into table_new from table_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only<仅适用于Oracle> 5、说明:删除表 drop table tablename
6、说明:增加一个列,删除一个列 A:alter table tabname add column col type B:alter table tabname drop column colname 注:DB2DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、添加主键: Alter table tabname add primary key(col) 删除主键: Alter table tabname drop primary key(col) 8、创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、创建视图:create view viewname as select statement 删除视图:drop view viewname 10、几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、几个高级查询运算词 A:UNION 运算符 UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。 B:EXCEPT 运算符 EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。 C:INTERSECT 运算符 INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。 注:使用运算词的几个查询结果行必须是一致的。 12、使用外连接
ORACLE 数据库性能优化 参考书目: 《ORACLE 9i Database Performance Tuning Guide and Reference》《ORACLE 9i Database Reference》 《ORACLE 9i SQL Reference》 《ORACLE 9i Database Administrator’s Guide》
一、数据库实例创建过程参数确定 在创建数据库实例过程中,需要确定以下几个参数: 1. 数据块大小(DB_BLOCK_SIZE) 该参数指明了ORACLE所处理的数据存贮于数据文档以及SGA内存中的数据块大小。 该参数的可选择的范围为:4k,8k,16k,32k,64k。对于OLTP系统而言,取值可以为4K或8K,对于DSS系统而言,则可以取较大的数据,如32K或64K 建议统一取8K(即8192) 说明 DB_BLOCK_SIZE的大小将影响创建表时的EXTENT的大小。例如指定db_block_size=16K,某表空间的EXTENT MANAGEMENT 为local autoallocate,则其系统将extent的大小最小指定为1M.所以将可能导致空间的浪费。 2. 字符集(Character set) 该参数确定数据库以何种字符集来存贮CHAR以及V ARCHAR、V ARCHAR2等字符类型的值。对于ORACLE数据字典中的字符(如表及字段的COMMENT 内容)具有同样的作用。因此需要考虑如字符集的使用。对于国际项目,因为数据库中的comment内容(包括表及字符、存贮过程中的中文字符等内容)可能性需要以中文存贮,而用户业务数据使用的字符可能性是使用本地的语言,基于此,该参数需要选择支持UNICODE的字符编码的字符集。目前ORACLE9i支持以下二种UNICODE字符集: ?UTF8 ?AL32UTF8 建议统一取AL32UTF8
oracle中以dba_、user_、v$_、all_、session_、index_开头的常用表和视图(https://www.doczj.com/doc/e86522967.html,/gzz%5Fgzz/blog/item/1f6ef92a67599392033bf6de.html) 2009年08月10日星期一 17:06 oracle中以dba_、user_、v$_、all_、session_、index_开头的常用表和视图dba_开头 dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space 数据库空闲空间信息 dba_profiles 数据库用户资源限制信息 dba_sys_privs 用户的系统权限信息 dba_tab_privs 用户具有的对象权限信息 dba_col_privs 用户具有的列对象权限信息 dba_role_privs 用户具有的角色信息 dba_audit_trail 审计跟踪记录信息 dba_stmt_audit_opts 审计设置信息 dba_audit_object 对象审计结果信息 dba_audit_session 会话审计结果信息 dba_indexes 用户模式的索引信息 user_开头 user_objects 用户对象信息 user_source 数据库用户的所有资源对象信息 user_segments 用户的表段信息 user_tables 用户的表对象信息 user_tab_columns 用户的表列信息 关于这个还涉及到两个常用的例子如下: 1、oracle中查询某个字段属于哪个表 Sql代码 select table_name,owner from dba_tab_columns t where t.COLUMN_NAME like upper('%username%'); select table_name,owner from dba_tab_columns t where t.COLUMN_NAME like
第七章视图 一、填空题 1. ____视图___是由一个或多个数据表(基本表)或视图导出的虚拟表。 2.在SQL S erver 2000中,创建视图有三种方法:____SQL语句___、__企业管理器_____、和___视图向导____。 3.视图名及创建日期等信息放在系统表_sysobjects______中。 4.视图是从一个或多个基本表(或视图)派生出的__虚拟_____表。 5.可以使用系统存储过程____ sp_help ___显示视图特征,使用___ sp_help text____显示视图 在系统表中的定义,使用__sp_depands_____显示该视图所依赖的对象。 二、选择题 1.关于视图下列哪一个说法是错误的(B )。 A 视图是一种虚拟表 B 视图中也保存有数据 C 视图也可由视图派生出来 D 视图是保存在SELECT查询 2.SQL Server2000提供了系统过程(),可以用来修改视图的名称。 A sp_help B SP_bindefault C SP_rename D 其他 3.下面语句中,哪种语句用来创建视图()。 A CREA TE TABLE B ALTER VIEW C DROP VIEW D CREAT E VIEW 4.下面语句中,哪种语句用来修改视图()。 A CREA TE TABLE B ALTER VIEW C DROP VIEW D CREA T E VIEW 5.下面语句中,哪种语句用来删除视图()。 A CREA TE TABLE B ALTER VIEW C DROP VIEW D CREA T E VIEW 6.视图是各种关系数据库应用较为成熟的技术,对于安的描述,下面正确的是()。 A视图中的数据是在运行时动态产生的。 B视图是一种特殊的表,同数据库设计人员或程序定义,它存在于数据库中 C从视图中查询数据与从表中查询数据的结果不一致 D使用视图可以提高数据安全性,但是它会降低系统性能 7.通过视图,可以进行的操作有()。 A插入数据B修改数C删除数据D查询数据 E以上全是 三、简答题 1.简述视图优点、缺点。P154 ? 1. 视图的优点 ?视图可以屏蔽数据的复杂性,简化用户对数据库的操作,还可以使用视图重新组织数据。 ?视图可以让不同的用户以不同的方式看到不同或者相同的数据集。 ?安全保护:视图可以定制不同用户对数据的访问权限。 ? 2.视图的缺点 ?性能降低: ?修改的限制:
OracleSQL性能优化方法 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访咨询Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访咨询数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访咨询 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14运算记录条数 (9) 15用Where子句替换HA VING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及储备参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存体会,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用咨询题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建立分区一样以关键字为分区的标志,也能够以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时能够进行讲明: create table TABLENAME(
V$SYSSTAT中包含多个统计项,这部分介绍了一些关键的v$sysstat统计项,在调优方面相当有用。下列按字母先后排序: 数据库使用状态的一些关键指标: l CPU used by this session:所有session的cpu占用量,不包括后台进程。这项统计的单位是百分之x秒.完全调用一次不超过10ms l db block changes:那部分造成SGA中数据块变化的insert,update或delete操作数这项统计可以大概看出整体数据库状态。在各项事务级别,这项统计指出脏缓存比率。 l execute count:执行的sql语句数量(包括递归sql) l logons current:当前连接到实例的Sessions。如果当前有两个快照则取平均值。l logons cumulative:自实例启动后的总登陆次数。 l parse count (hard):在shared pool中解析调用的未命中次数。当sql语句执行并且该语句不在shared pool或虽然在shared pool但因为两者存在部分差异而不能被使用时产生硬解析。如果一条sql语句原文与当前存在的相同,但查询表不同则认为它们是两条不同语句,则硬解析即会发生。硬解析会带来cpu和资源使用的高昂开销,因为它需要oracle 在shared pool中重新分配内存,然后再确定执行计划,最终语句才会被执行。 l parse count (total):解析调用总数,包括软解析和硬解析。当session执行了一条sql语句,该语句已经存在于shared pool并且可以被使用则产生软解析。当语句被使用(即共享) 所有数据相关的现有sql语句(如最优化的执行计划)必须同样适用于当前的声明。这两项统计可被用于计算软解析命中率。 l parse time cpu:总cpu解析时间(单位:10ms)。包括硬解析和软解析。 l parse time elapsed:完成解析调用的总时间花费。 l physical reads:OS blocks read数。包括插入到SGA缓存区的物理读以及PGA中的直读这项统计并非i/o请求数。 l physical writes:从SGA缓存区被DBWR写到磁盘的数据块以及PGA进程直写的数据块数量。 l redo log space requests:在redo logs中服务进程的等待空间,表示需要更长时间的log switch。 l redo size:redo发生的总次数(以及因此写入log buffer),以byte为单位。这项统计显示出update活跃性。
使用SpotLight监控数据库性能 8.1.4 使用SpotLight监控数据库性能(1) SpotLight On Oracle是由Quest公司出品的一款针对Oracle进行监控的软件。SpotLight监控Oracle的基本原理与LoadRunner监控类似,通过获取Oracle的数据字典和动态性能视图,然后把性能数据按直观的方式展现出来,如图8.11所示。 (点击查看大图)图8.11 SpotLight On Oracle监控数据库下面简要介绍使用SpotLight对Oracle进行监控的过程。 1.建立Oracle连接 第一步要建立Connection,如图8.12所示,这样才能够使用SpotLight连接到要监测的数据库。
新建连接,然后输入Oracle连接用户账号,确定之后即可进入监控主页面。 2.查看系统主界面进行Oracle监控 系统主界面反映了系统的整体运行情况,如果系统哪方面出现问题,会报相应的警告,最严重为红色警告。然后根据警告可转到相应的子窗口,查看相应的情况。下面介绍各子窗口。 1)Sessions面板 Response:系统的响应时间。 Total Users:总的用户Session数量。 Active Users:当前正在执行的用户Session数量。 2)Host面板 Host面板主要显示CPU利用率和内存使用情况。 3)Server Processes面板 Server Processes面板主要显示服务器进程的信息。主要关注以下几点。 PGA Target/Used:PGA目标总数及当前使用数。 Dedicated:专用服务器进程的个数。 Shared:共享服务器进程的个数。 Job Queue:作业进程的个数。 4)SGA面板 SGA面板主要显示SGA中各组件的内存使用情况,主要关注以下几点。
Oracle常用数据字典表(系统表或系统视图)及查询SQL 2014年12月15日?数据库?共4187字?暂无评论?阅读861 次 文章目录 ?数据字典分类 ?dba_开头 ?user_开头 ?v$开头 ?all_开头 ?session_开头 ?index_开头 ?伪表 ?数据字典常用SQL查询 数据字典是Oracle存放有关数据库信息的地方,其用途是用来描述数据的。比如一个表的创建者信息,创建时间信息,所属表空间信息,用户访问权限信息的视图等。 数据字典系统表,保存在system表空间中。查询所有数据字典可用语句“select * from dictionary;”。 数据字典分类 数据字典主要可分为四部分: 1)内部RDBMS表:x$*,用于跟踪内部数据库信息,维持DB的正常运行。是加密命名的,不允许sysdba以外的用户直接访问,显示授权不被允许。
2)数据字典表:*$,如tab$,obj$,ts$等,用来存储表、索引、约束以及其他数据库结构的信息。 3)动态性能视图:gv$*,v$*,记录了DB运行时信息和统计数据,大部分动态性能视图被实时更新以反映DB当前状态。 4)数据字典视图:user_*、all_*、dba_*,在非Sys用户下,我们访问的都是同义词,而不是V$视图或GV视图。 数据库启动时,动态创建x$,在X$基础上创建GV$,在GV$基础上创建V$X$表-->GV$(视图)--->V$(视图)。 数据字典视图可分为静态数据字典视图和动态数据字典视图。 静态数据字典是指在用户访问数据字典时内容不会发生改变。这类数据字典主要是由表和视图组成,应该注意的是,数据字典中的表是不能直接被访问的,但是可以访问数据字典中的视图。 静态数据字典中的视图分为三类,它们分别由三个前缀够成:user_*(该用户方案对象的信息)、all_*(该用户可以访问的所有对象的信息)、dba_*(全部数据库对象的信息)。 动态数据字典是Oracle包含的一些潜在的由系统管理员如SYS维护的表和视图,由于当数据库运行的时候它们会不断进行更新,所以称它们为动态数据字典。这些视图提供了关于内存和磁盘的运行情况,所以我们只能对其进行只读访问而不能修改它们。Oracle中这些动态性能视图都是以v$开头的视图,比如v$access。 dba_开头 dba_users数据库用户信息
达梦数据库的性能优化 “棱镜门”、“微软XP系统停摆”的接踵而至给我国信息安全敲响了警钟,也加速了国内“去IOE”运动的进程。达梦数据库作为连续5年国产数据库市场占有率第一的高性能、高可靠性、高安全性、高兼容性大型关系型数据库管理系统,已成功替代了Oracle,在电力、金融、电子政务、教育等行业领域得到了广泛的应用,逐渐成为国家信息化建设的重要基础平台。为了更好地支撑业务应用,有效管理和利用信息时代不断产生并急剧膨胀的数据,对达梦数据库的优化显得尤为重要。 一、数据库参数优化 1.优化内存 公共内存池 公共内存池提供了一组内存申请/释放接口,为系统中需要动态分配内存的模块提供服务。 MEMORY_POOL决定了以M为单位的公共内存池的大小,上例中40M;N_MEM_POOLS决定把内存池划分为几个独立的单元,以减少并发访问的冲突,提升并发效率;MEMORY_BAK_POOL表示系统保留的备用内存量,当常规的内存申请都失败时,从这个备用内存里分配,然后在上层模块中进行必要的容错处理。 可以在v$sysstat中查看当前公用内存池的使用情况:
这里的STAT_VAL给出的是已经使用的字节数。正常情况下,应该小于配置的池大小,否则系统不得不从池外向操作系统申请/释放内存,造成效率低下,并可能把操作系统的内存搞得很零碎。 系统缓冲区BUFFER 为了加速数据访问,系统开辟了一个缓冲区,使用LRU算法存放经常访问的数据页,逐步淘汰不用的数据页。 使用下列参数,可配置基本的系统缓冲区的大小: 其中HUGE_BUFFER 是专门用于列存表的缓存区,BUFFER是用户行存表的系统缓冲区。BUFFER表示初始的系统缓冲区大小,单位为M。通常情况下,如果物理数据量大于物理内存,则应该把BUFFER调到物理内存的三分之二比较合适。 当BUFFER_POOLS = 1时,系统支持缓冲区的自动扩展。MAX_BUFFER表示最多能扩到多大。在自动扩展后,如果系统的压力在一段时间内比较低,系统又会自动收缩缓冲区。 系统缓冲区是一个共享资源,受一个mutex保护,在一个时间点,只允许一个线程可以持有这个资源。在高并发情况下,这个限制将极大降低并发效率,因此,可以配置BUFFER_POOLS把一个大的系统缓冲区分割为多个小的部分,每一个小的部分作为临界资源,这样只要所访问的数据页不在同一个子池里,就不会发生冲突,从而提升并发性能。注意,如果配置了BUFFER_POOLS > 1, 则MAX_BUFFER参数就失效了,最大可用的缓冲区由BUFFER参数决定。 系统缓冲区RECYCLE 这是DM新引入的缓冲区,专门用于缓冲临时表空间。RECYCLE的淘汰算法与BUFFER完全一样,但是它有独立的HASH表, LRU和更新链。引入 RECYCLE的目的是防止某些复杂查询的中间结果挤占大量的BUFFER空间,降低BUFFER的命中率,从而增加额外的 IO操作。
Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11)
18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建