
了解云计算标杆 Google 的技术构架
一、前言
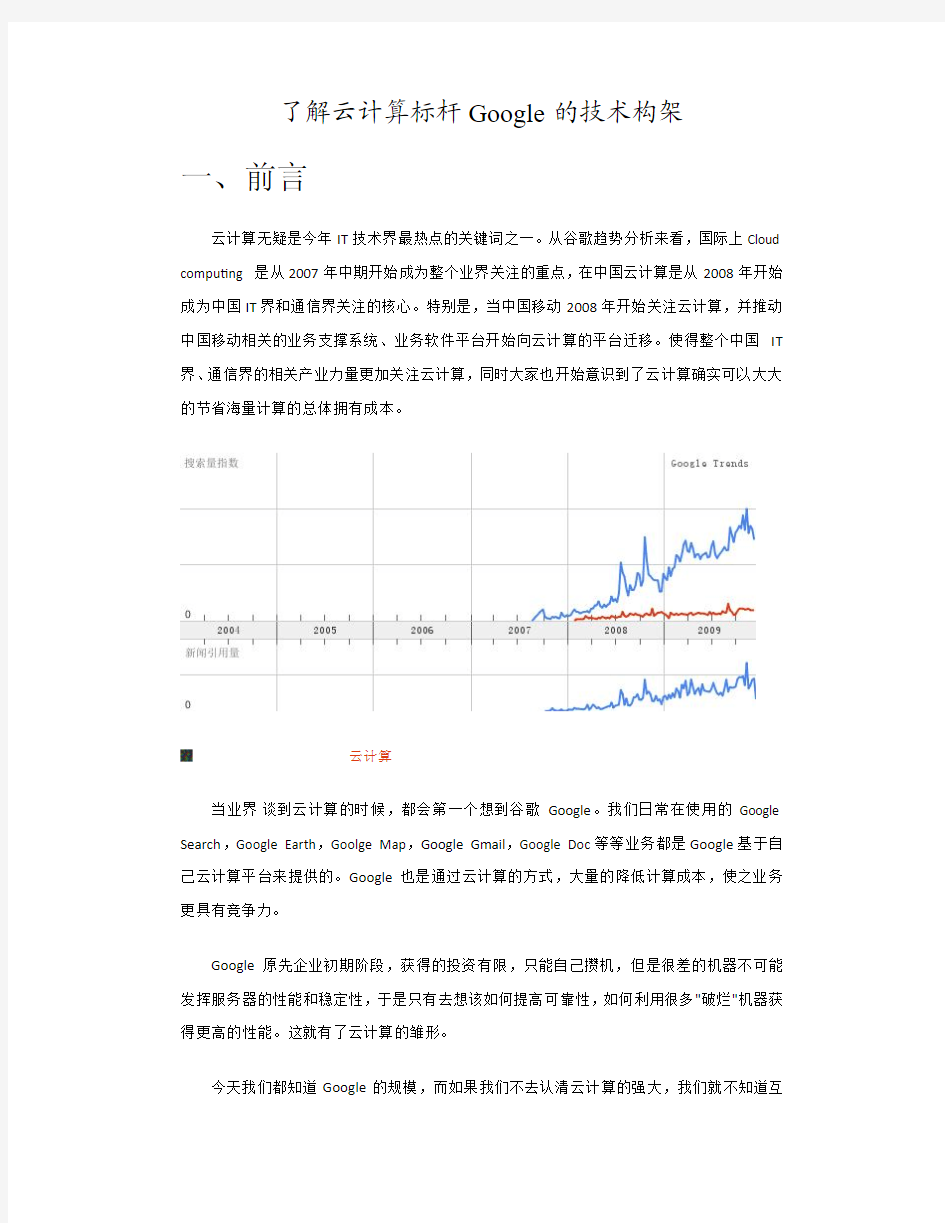
云计算无疑是今年 IT 技术界最热点的关键词之一。从谷歌趋势分析来看,国际上 Cloud computing 是从 2007 年中期开始成为整个业界关注的重点, 在中国云计算是从 2008 年开始 成为中国 IT 界和通信界关注的核心。特别是,当中国移动 2008 年开始关注云计算,并推动 中国移动相关的业务支撑系统、业务软件平台开始向云计算的平台迁移。使得整个中国 IT 界、 通信界的相关产业力量更加关注云计算, 同时大家也开始意识到了云计算确实可以大大 的节省海量计算的总体拥有成本。
cloud computing
云计算
当业界 谈到云计算的时候,都会第一个想到谷歌 Google。我们日常在使用的 Google Search,Google Earth,Goolge Map,Google Gmail,Google Doc 等等业务都是 Google 基于自 己云计算平台来提供的。Google 也是通过云计算的方式,大量的降低计算成本,使之业务 更具有竞争力。 Google 原先企业初期阶段,获得的投资有限,只能自己攒机,但是很差的机器不可能 发挥服务器的性能和稳定性,于是只有去想该如何提高可靠性,如何利用很多"破烂"机器获 得更高的性能。这就有了云计算的雏形。 今天我们都知道 Google 的规模,而如果我们不去认清云计算的强大,我们就不知道互
联网的未来和规则。Google 在 98 年的时候被迫发现了这一规则,然后我们看到了聚合的力 量,今天微软、IBM、雅虎、百度、亚马逊这些企业看到了规则,于是开始进入云计算领域。 所以我们研究云计算,可以系统剖析一下 Google 的技术构架,这对于我们搭建自己自身的 云计算平台有比较好的借鉴意义和标杆意义!
二、Google 的整体技术构架说明
由于 Google 没有官方发布一个自身的技术构架说明。本文主要的信息都来自互联网中 对于 Google 网络技术构架的分析,大量信息来自 https://www.doczj.com/doc/ed16851746.html, 。 Google 最大的 IT 优势在于它能建造出既富于性价比(并非廉价)又能承受极高负载的高 性能系统。因此 Google 认为自己与竞争对手,如亚马逊网站(Amazon)、电子港湾(eBay)、微 软(Microsoft)和雅虎 (Yahoo)等公司相比,具有更大的成本优势。其 IT 系统运营约为其他互 联网公司的 60%左右。 同时 Google 程序员的效率比其他 Web 公司同行们高出 50%~100%,原因是 Google 已 经开发出了一整套专用于支持大规模并行系统编程的定制软件库。
从整体来看,Google 的云计算平台包括了如下的技术层次。 1)网络系统:包括外部网络(Exterior Network) ,这个外部网络并不是指运营商自己的 骨干网,也是指在 Google 云计算服务器中心以外,由 Google 自己搭建的由于不同地区/国 家, 不同应用之间的负载平衡的数据交换网络。 内部网络 (Interior Network) 连接各个 Google , 自建的数据中心之间的网络系统。 2)硬件系统:从层次上来看,包括单个服务器、整合了多服务器机架和存放、连接各 个服务器机架的数据中心(IDC) 。 3) 软件系统: 包括每个服务器上面的安装的单机的操作系统经过修改过的 Redhat Linux。 Google 云计算底层软件系统(文件系统 GFS、并行计算处理算法 Mapreduce、并行数据库 Bigtable,并行锁服务 Chubby Lock,云计算消息队列 GWQ) 4)Google 内部使用的软件开发工具 Python、Java、C++ 等
5)Google 自己开发的应用软件 Google Search 、Google Email 、Google Earth
三、Google 各个层次技术介绍
1、Google 外部网络系统介绍 当一个互联网用户输入 https://www.doczj.com/doc/ed16851746.html, 的时候, 这个 URL 请求就会发到 Google DNS 解 析服务器当中去,那么 Google 的 DNS 服务器就会根据用户自身的 IP 地址来判断,这个用 户请求是来自那个国家、那个地区。根据不同用户的 IP 地址信息,解析到不同的 Google 的 数据中心。
进入第一道防火墙,这次防火墙主要是根据不同端口来判断应用,过滤相应的流量。如 果仅仅接受 浏览器应用的访问,一般只会开放 80 端口 http,和 443 端口 https (通过 SSL 加密) 。将其他的来自互联网上的非 Ipv4 /V6 非 80/443 端口的请求都放弃,避免遭受互联 网上大量的 DOS 攻击。 据说 Google 使用了思杰科技(Citrix Systems)的 Netscaler 应用交换机来做 web 应用
的优化。NetScaler 可将 Web 应用性能加速高达 5 倍。使用高级优化技术如动态缓存时, 或者当网络延迟或数据包丢失增大时, 性能增益会更高。这里提到的 http multiplexting 技术 是可以是进行 http 的每个 session 分解开。从不同的后端服务器(缓存)来获取内容,这 样可以大大提升 web http 性能,同时有效降低后端 web 应用服务器的处理和联接压力。 在大量的 web 应用服务器群 (Web Server Farm) Google 使用反向代理 前, (Reverse Proxy) 的技术。反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求, 然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求 连接的客户端,此时代理服务器对外就表现为一个服务器。 Google 使用的是 Squid Cache 的软件方式来实现反向代理应用的 ,Squid Cache 一个流 行的自由软件(GNU 通用公共许可证)的代理服务器和 Web 缓存服务器。Squid 有广泛的 用途,从作为网页服务器的前置 cache 服务器缓存相关请求来提高 Web 服务器的速度。 在 Google web 应用服务器需要调用 Google 内部存储的信息和资源的时候, 在通过一个 防火墙进入内部的网络,来访问其他的基于自身 GFS II 系统的应用服务和数据库。
2、Google 内部网络架构介绍 Google 自己已经建设了跨国的光纤网络,连接跨地区、跨国家的高速光纤网络。内部 网络已经都是 Ipv6 的协议在运行。网络中的路由交换设备主要还是来自 Juniper, Cisco, Foundry, HP 这四家公司。内部网关协议(IRP)是基于 OSPF(开放式最短路径优先)进行修改
的。在每个服务器机架内部连接每台服务器之间网络是 100M 以太网,在服务器机架之间连 接的网络是 1000M 以太网。 在每个服务器机架内, 通过 IP 虚拟服务器 (IP Virtual Server) 的方式实现传输层负载 Linux 内核内的平衡,这个就是所谓四层 LAN 交换。 IPVS 使一个服务器机架中的众多服务成为基 于 Linux 内核虚拟服务器。这就像在一堆服务器前安装一个负载均衡的服务器一样。当 TCP/UDP 的请求过来后,使一群服务器可以使用一个单一的 IP 地址来对外提供相关的服务 支撑。 3、Google 的大规模 IDC 部署战略 Google 应该是目前世界上存储信息最多的企业了。而且还在一直不断的致力于将传统 信息仅可能的数字化。 将这样海量的信息进行存储、 进行处理。 就需要大量的计算机服务器。 为了满足不断增长的计算需求。Google 很早就进行了全球的数据中心的布局。由于数据中 心运行后, 面临的几个关键问题的就是充足电力供应、 大量服务器运行后的降温排热和足够 的网络带宽支持。所以 Google 在进行数据中心布局的时候,就是根据互联网骨干带宽和电 力网的核心节点进行部署的, 尽快考虑在河边和海边, 想办法通过引入自然水流的方式来降 低降温排热的成本。 达拉斯(Dalles)是美国俄勒冈州北部哥伦比亚河( Columbia river)岸上的一个城市, Google 在 Dalles 的边上拥有的 30 英亩土地,他们在这里建立了几乎是世界上最大,性能最 好的数据中心。四个装备有巨大空调设施的仓库内,放置着数万台 Internet 服务器,这些服 务器每天处理着数十亿条 Google 网站传递给世界各个角落的用户的数据。
Google 达拉斯这个数据中心占用了附近一个 180 万千瓦(1.8GW)水力发电站的大部分 电力输出。对比来看目前中国长江三峡水电站的额定功率是 1820 万千瓦。 目前 Google 已经在全球运行了 38 个大型的 IDC 中心,超过 300 多个 GFSII 服务器集 群,超过 80 万台计算机。从服务器集群部署的数量来看美国本地的数量第一,欧洲地区第 二,亚洲地区第三,在南美地区和俄罗斯各有一个 IDC 数据中心。 目前 Google 在中国的北京和香港建设了自己的 IDC 中心, 并部署了自己的服务器农场。 其中目前还在进行建设的第 38 个 IDC 是在奥地利的林茨市 (Linz) 附近的 Kronstorf 村。 未来,Google 还准备在中国台湾地区、马来西亚、立陶宛等地区来进行部署。从目前 的 Google 数据中心部署的情况来看,中东和非洲地区目前 Google 还没有建设计划。 下图是 Google 的 IDC 中心/服务器农场(Google Server Farm)的全球分布图。
Google 自己设计了创新的集装箱服务器,数据中心以货柜为单位, 标准谷歌模块化集装箱装有 30 个的机架, 1160 台服务器, 每台服务器的功耗是 250KW。 (Google2009 年公布的信息) 。下图是 Google 模块化集装箱的设计示意图。这种标准的 集装箱式的服务器部署和安装策略可以是 Google 非常快速的部署一个超大型的数据中心。 大大降低了对于机房基建的需求。
4、Google 自己设计的服务器机架构架 Google 的服务器机架有两种规格 40U/80U 的。 这主要是因为原来每个服务器刀片是 1U
高,新的服务器刀片都是 2U 高的。据说 Google 后期使用的服务器主板是台湾技嘉,服务器 主板可以直接插入到服务器机架中。
5、Google 自己设计的 PC 服务器刀片 绝大部分企业都会跟诸如戴尔、惠普、IBM 或 Sun 购买服务器。不过 Google 所拥有的 八十万台服务器都是自己设计打造来的,Google 认为这是公司的核心技术之一。Google 的 硬件设计人员都是直接和芯片厂商和主板厂商协作工作的。 2009 年,Google 开始大量使用 2U 高的低成本解决方案。标准配置是双核双通道 CPU, 据说有 Intel 的,也有 AMD 的在使用。8 个 2GB 的 DDR3,支持 ECC 容错的高速内存,采用 RAID 1 的磁盘镜像,来提升 I/O 效率。磁盘采用 SATA,单机存储容量可以达到 1-2TB。每个 服务器刀片自带 12V 的电池来保证在短期没有外部电源的时候可以保持服务器刀片正常运 行。Google 的硬件设计人员认为,这个自带电池的方式,要比传统的使用 UPS 的方式效率 更高。
一般数据中心多倚赖称为不间断电源系统(UPS)的大型中控机型,这基本上算是大电池,
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2007 For Evaluation Only.
会在主电力失效而发电机还来不及启动时,暂时协助供电。Google 的硬件设计人员表示, 直接把电力内建到服务器比较便宜,而且成本能直接跟服务器数量相符合。 “这种作法比使 用大型 UPS 节省得多,如此也不会浪费多余的容量。 ” 效率也是另一个财务考量因素。大型 UPS 可达 92-95%的效率,这意味着许多电力还是 被浪费掉了。但 Google 采用的内建电池作法却好很多,Google 相关人员表示, “我们测量的 结果是效率超过 99.9% 。
年份 1999/2000 2003/2004
Google 服务器刀片硬件配置 PII/PIII 128MB+ Celeron 533, PIII 1.4 SMP, 2-4GB DRAM, Dual XEON 2.0/1-4GB/40-160GB IDE - SATA Disks via Silicon Images SATA 3114/SATA 3124
2006 2009
Dual Opteron/Working Set DRAM(4GB+)/2x400GB IDE (RAID0?) 2-Way/Dual Core/16GB/1-2TB SATA
6、Google 服务器使用的操作系统 Google 服务器使用的操作系统是基于 Redhat Linux2.6 的内核,并做了大量修改。修改 了 GNU C 函数库(glibc) ,远程过程调用(RPC) ,开发了自己的 Ipvs,自己修改了文件系统,形
成了自己的 GFSII,修改了 linux 内核和相关的子系统,是其支持 IPV6。采用了 Python 来作为主要 的脚本语言。
下表是一些大型互联网公司使用的操作系统对比。
网站 Google
操作系统 Linux
Web 应用服务器 Google Web Server
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2007 For Evaluation Only.
微软 ebay 阿里巴巴 新浪 百度 163 搜狐 Windows server Windows server Linux Free BSD Linux Linux Sco Unix IIS IIS Apache Apache Apache Apache Apache
7、Google 云计算文件系统 GFS/GFSII GFSII cell 是 Google 文件系统中最基础的模块。任何文件和数据都可以利用这种底层模 块。GFSII 通过基于 Linux 分布存储的方式,对于服务器来说,分成了主服务器(Master Servers)和块存储服务器(Chunk Servers) ,GFS 上的块存储服务器上的存储空间以 64MB 为 单位,分成很多的存储块,由主服务器来进行存储内容的调度和分配。每一份数据都是一式 三份的方式, 将同样的数据分布存储在不同的服务器集群中, 以保证数据的安全性和吞吐的 效率提高。当需要对于文件、数据进行存储的时候,应用程序之间将需求发给主服务器,主 服务器根据所管理的块存储服务器的情况, 将需要存储的内容进行分配, 并将可以存储的消 息(使用那些块存储服务器,那些地址空间) ,有应用程序下面的 GFS 接口在对文件和数据 直接存储到相应的块存储服务器当中。
块存储服务器要定时通过心跳信号的方式告知主服务器, 目前自己的状况, 一旦心跳信 号出了问题, 主服务器会自动将有问题的块存储服务器的相关内容进行复制。 以保证数据的 安全性。 数据被存储时是经过压缩的。采用的 BMDiff 和 Zippy 算法。BMDiff 使用最长公共子序 列进行压缩, 压缩 100MB/s, 解压缩约 1000MB/s.类似的有 IBM Hash Suffix Array Delta Compression.Zippy 是 LZW 的改进版本, 压缩比不如 LZW, 但是速度更快.
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2007 For Evaluation Only.
8、Google 并行计算构架 –Mapreduce 有了强大的分布式文件系统,Google 遇到的问题就是怎么才能让公司所有的程序员都 学会些分布式计算的程序呢?于是,那些 Google 工程师们从 lisp 和其他函数式编程语言中 的映射和化简操作中得到灵感,搞出了 Map/Reduce 这一套并行计算的框架。Map/Reduce 被 Google 拿来重新了 Google Search Engine 的整个索引系统。而 Doug Cutting 同样用 Java 将 这一套实现和 HDFS 合在一起成为 Hadoop 的 Core。 MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于 1TB)的并行运 算。概念“Map(映射) ”和“Reduce(化简),和他们的主要思想,都是从函数式编程语 ” 言借来的,还有从矢量编程语言借来的特性。
映射和化简
简单说来,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成 绩的列表)的每一个元素进行指定的操作(比如前面的例子里,有人发现所有学生的成绩都 被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。。事实上,每个 ) 元素都是被独立操作的, 而原始列表没有被更改, 因为这里创建了一个新的列表来保存新的 答案。这就是说,Map 操作是可以高度并行的,这对高性能要求的应用以及并行计算领域 的需求非常有用。
而化简操作指的是对一个列表的元素进行适当的合并 (继续看前面的例子, 如果有人想 知道班级的平均分该怎么做?他可以定义一个化简函数,通过让列表中的元素 跟自己的相
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2007 For Evaluation Only.
邻的元素相加的方式把列表减半, 如此递归运算直到列表只剩下一个元素, 然后用这个元素 除以人数,就得到了平均分。。虽然他不如映射函数那么并 行,但是因为化简总是有一个 ) 简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。
分布和可靠性 MapReduce 通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个 节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保 持沉默超过一个预 设的时间间隔,主节点(类同 Google File System 中的主服务器)记录下这个节点状态为死 亡, 并把分配给这个节点的数据发到别的节点。 每个操作使用命名文件的原子操作以确保不 会发生并行线程间 的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的 另一个名字上去。 (避免副作用) 。
化简操作工作方式很类似, 但是由于化简操作在并行能力较差, 主节点会尽量把化简操 作调度在一个节点上,或者离需要操作的数据尽可能进的节点上了;这个特性可以满足 Google 的需求,因为他们有足够的带宽,他们的内部网络没有那么多的机器。 在 Google,MapReduce 用在非常广泛的应用程序中,包括“分布 grep,分布排序,web 连接图反转,每台机器的词矢量,web 访问日志分 析,反向索引构建,文档聚类,机器学习, 基于统计的机器翻译...”值得注意的是,MapReduce 实现以后,它被用来重新生成 Google 的整个索 引,并取代老的 ad hoc 程序去更新索引。MapReduce 会生成大量的临时文件,为 了提高效率,它利用 Google 文件系统来管理和访问这些文件。
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2007 For Evaluation Only.
9、Google 并行计算数据库 Bigtable 有了强大的存储,有了强大的计算能力,剩下的 Google 要面对的是:它的应用中有很 多结构化、半结构化的数据,如何高效地管理这些结构化、半结构化的数据呢?Google 需 要的是一个分布式的类 DBMS 的系统,于是催生了 BigTable 这个东西 Google 的 BigTable 从 2004 年初就开始研发了, BigTable 让 Google 在提供新服务时的 运行成本降低,最大限度地利用了计算能力。BigTable 是建立在 GFS ,Scheduler ,Lock Service 和 MapReduce 之上的。 每个 Table 都是一个多维的稀疏图 sparse map。Table 由行和列组成,并且每个存储单 元 cell 都有一个时间戳。在不同的时间对同一个存储单元 cell 有多份拷贝,这样就可以记 录数据的变动情况。数据存储的结构是(row:string, column:string, time:int64) --> string
行:
表中的行键(目前任意字符串至 64KB 的大小) 。每一个读取或写入的数据下单行的关键是 原子(不论数目不同的列被读取或行中写的) 更容易为客户的原因关于系统中的行为同时存 ,
在对同一行的更新。
列:
列项分为集合称为列的家族, 它们形成了访问控制的基本单位。 所有数据在一列中存储 的家族通常是同一类型。当数据以这个列键值被存储之前,列的家族必须被创建。家族内的 任何列键值可以使用。因为,重叠的列键值比较少,与此相反,一个表可能有无限的列数。
时间戳:
Bigtable 的每一个细胞中可以包含多个版本同样的数据,这些版本的时间戳索引。Bigtable 的时间戳 64 位整数。它们可以被分配由 Bigtable 的,在这种情况下,他们真正代表联聪以微秒 的时间,或明确指定的客户端应用程序。应用程序需要避免冲突必须创造自己独特的时间戳。
不同一个单元格的版本都存储在时间戳顺序递减,因此,最近的版本可以首先阅读。
为了管理巨大的 Table,把 Table 根据行分割,这些分割后的数据统称为:Tablets。每个 Tablets 大概有 100-200 MB,每个机器存储 100 个左右的 Tablets。底层的架构是:GFS。由 于 GFS 是一种分布式的文件系统,采用 Tablets 的机制后,可以获得很好的负载均衡。比如: 可以把经常响应的表移动到其他空闲机器上,然后快速重建。Tablets 在系统中的存储方式 是不可修改的 immutable 的 SSTables,一台机器一个日志文件。 BigTable 中最重要的选择是将数据存储分为两部分,主体部分是不可变的,以 SSTable 的格式存储在 GFS 中, 最近的更新则存储在内存 (称为 memtable) 读操作需要根据 SSTable 中。 和 memtable 还综合决定要读取的数据的值。
Google 的 Bigtable 是不支持事务,只保证对单条记录的原子性。事务是好东西,但事 务也是导致数据库实现复杂化、性能下降最主要的根源。BigTable 的开发者通过调研后发现 其实大家对事务都没什么需求,只要保证对单条记录的更新是原子的就可以了。这样,为了 支持事务所要考虑的串行化、事务的回滚等、死锁检测(一般认为,分布式环境中的死锁检 测是不可能的,一般都用超时解决)等等复杂问题都不见了。系统实现进一步简化。 10、Google 并行锁服务 Chubby lock 在 Google 这种的分布式系统中,需要一种分布式锁服务来保证系统的一致性。于是 Google 有了 Chubby lock service。而同样是 Yahoo! Research 向开源贡献了 Zookeeper,一 个类似 Google Chubby 的项目。 在 Google File System(GFS)中,有很多的服务器,这些服务器需要选举其中的一台作为 master server。Value 就是 master server 的地址,GFS 就是用 Chubby 来解决的这个问题,所 有的 server 通过 Chubby 提供的通信协议到 Chubby server 上创建同一个文件, 当然,最终只 有一个 server 能够获准创建这个文件,这个 server 就成为了 master,它会在这个文件中写 入自己 的地址,这样其它的 server 通过读取这个文件就能知道被选出的 master 的地址。 Chubby 首先是一个分布式的文件系统。Chubby 能够提供机制使得 client 可以在 Chubby service 上创建文件和执行一些文件的基本操作。说它是分布式的文件系统,是因为一个 Chubby cell 是一个分布式的系统。但是,从更高一点的语义层面上,Chubby 是一个 lock service,一个针对松耦合的分布式系统的 lock service。所谓 lock service,就是这个 service 能够提供开发人员经常用的“锁”“解锁”功能。通过 Chubby,一个分布式系统中的上千 , 个 client 都能够 对于某项资源进行“加锁”“解锁” , 。 Chubby 中的“锁”就是建立文件,在上例 中,创建文件其实就是进行“加锁”操作,
创建文件成功的那个 server 其实就是抢占到了“锁” 。用户通过打开、关闭和读取文件,获 取共享锁或者独占锁; 并且通过通信机制,向用户发送更新信息。 11、Google 消息序列处理系统 Google Workqueue GWQ (Google Workqueue)系统是负责将 Mapreduce 的工作任务安排各个各个计算单 位的(Cell/Cluster) 。仲裁(进程优先级)附表,分配资源,处理故障,报告情况,收集的 结果 - 通常队列覆盖在 GFS 上的。消息队列处理系统可以同时管理数万服务器。通过 API 接口和命令行可以调动 GWQ 来进行工作。 12、Google 的开发工具。 除了传统的 C++ 和 Java。还开始大量使用 Python。 Python 是一种面向对象、直译式计算机程序设计语言,也是一种功能强大而完善的通 用型语言,已经具有十多年的发展历史,成熟且稳定。这种语言具有非常简捷而清晰的语法 特点,适合完成各种高层任务,几乎可以在所有的操作系统中运行。 Python 可能被粗略地分类为“脚本语言” (Script Language) ,但实际上一些大规模软件 开发计划例如 Zope、Mnet 及 BitTorrent,Google 也广泛地使用它。 Python 的支持者较 喜欢称它为一种高级动态编程语言,原因是“脚本语言”泛指仅作简单编程任务的语言,如 shell script、 JavaScript 等只能处理简单任务的编程语言, 并不能与 Python 相提并论。 此外, 由于 Python 对于 C 和其他语言的良好支持,很多人还把 Python 作为一种“胶水语言” (Glue Language) 使用。 使用 Python 将其他语言编写的程序进行集成和封装。 在 Google 内部的很多项目使用 C++ 编写性能要求极高的部分,然后用 Python 调用相应的模块。
Sawzall,为了是内部的工程师和程序人员可以更方便的适应并行计算的方式,Google 自己开发的一种查询语言,Sawzall 是一种类型安全的脚本语言。由于 Sawzall 自身处理了很 多问题,所以完成相同功能的代码就简化了非常多-与 MapReduce 的 C++代码相比简化了 10 倍不止。
四、借鉴与总结
从 Google 的整体的技术构架来看,Google 云计算系统依然是边做科学研究,边进行商 业部署,依靠系统冗余和良好的软件构架来低成本的支撑庞大的系统运作的。 大型的并行计算,超大规模的 IDC 快速部署,通过系统构架来使廉价 PC 服务器具有超 过大型机的稳定性都已经不在是科学实验室的故事, 已经成为了互联网时代,IT 企业获得核 心竞争力发展的基石。 Google 在应对互联网海量数据处理的压力下,充分借鉴了大量开源代码,大量借鉴了 其他研究机构和专家的思路, 走了一条差异化的技术道路,构架自己的有创新性的云计算平 台。 从 Google 这样互联网企业可以看到,基于 Linux 系统的开源代码的方式,让企业可以 不收到商业软件系统的限制,可以自主进行二次、定制开发。而这种能充分利用社会资源, 并根据自己的能力进行定制化的系统设计最终将会成为互联网企业之间的核心竞争力。
云计算的关键技术及发展现状 周小华 摘要:本文主要对云计算技术的应用特点、发展现状、利处与弊端以及对云计算的应用存在的主要问题进行了探讨分析,最后是关于云计算的挑战及其展望。 关键词:云计算;数据存储;编程模型 1.云计算定义 云计算是由分布式计算、并行处理、网格计算发展而来的,是一种新兴的商业计算模型。目前,对于云计算的认识在不断地发展变化,云计算仍没有普遍一致的定义。计算机的应用模式大体经历了以大型机为主体的集中式架构、以pc机为主体的c/s分布式计算的架构、以虚拟化技术为核心面向服务的体系结构(soa)以及基于web2.0应用特征的新型的架构。云计算发展的时代背景是计算机的应用模式、技术架构及实现特征的演变。“云计算”概念由google提出,一如其名,这是一个美妙的网络应用模式。在云计算时代,人们可以抛弃u盘等移动设备,只要进入google docs页面,新建一个文档,编辑其内容,然后直接把文档的url分享给朋友或上司,他们就可以直接打开浏览器访问url。我们再也不用担心因pc硬盘的损坏而发生资料丢失事件。 IBM公司于2007年底宣布了云计算计划,云计算的概念出现在大众面前。在IBM的技术白皮书“Cloud Computing”中的云计算定义:“云计算一词用来同时描述一个系统平台或者一种类型的应用程序。一个云计算的平台按需进行动态地部署(provision)、配置
(configuration)、重新配置(reconfigure)以及取消服务(deprovision)等。在云计算平台中的服务器可以是物理的服务器或者虚拟的服务器。高级的计算云通常包含一些其他的计算资源,例如存储区域网络(SANs)。网络设备,防火墙以及其他安全设备等。云计算在描述应用方面,它描述了一种可以通过互联网Intemet进行访问的可扩展的应用程序。“云应用”使用大规模的数据中心以及功能强劲的服务器来运行网络应用程序与网络服务。任何一个用户可以通过合适的互联嘲接入设备以及一个标准的浏览器就能够访问一个云计 算应用程序。” 云计算是基于互联网的超级计算模式,包含互联网上的应用服务及在数据中心提供这些服务的软硬件设施,进行统一的管理和协同合作。云计算将IT 相关的能力以服务的方式提供给用户,允许用户在不了解提供服务的技术、没有相关知识以及设备操作能力的情况下,通过Internet 获取需要的服务。 通过对云计算的描述,可以看出云计算具有高可靠性、高扩展性、高可用性、支持虚拟技术、廉价以及服务多样性的特点。现有的云计算实现使用的技术体现了以下3个方面的特征: (1)硬件基础设施架构在大规模的廉价服务器集群之上.与传统的性能强劲但价格昂贵的大型机不同,云计算的基础架构大量使用了廉价的服务器集群,特别是x86架构的服务器.节点之间的巨联网络一般也使用普遍的千兆以太网. (2)应用程序与底层服务协作开发,最大限度地利用资源.传
1简介 1.1什么是google云计算? Google的云计算技术实际上是针对Google特定的网络应用程序而定制的。针对内部网络数据规模超大的特点,Google提出了一整套基于分布式并行集群方式的基础架构,利用软件的能力来处理集群中经常发生的节点失效问题。 1.2Google云计算平台 Google 提供了一个名为App Engine 的云计算平台,它基于的是Google 早就建立起来的底层平台。这个平台包括GFS(Google File System)和Bigtable(构建于GFS 之上的数据库系统)。Google App Engine 内的编程采用的是Python。程序员用Python 编写应用程序,然后再在App Engine 框架上运行。除Python 外的其他语言在将来也会得到支持。出于开发的需要,可以下载App Engine 环境的一个本地仿真程序。App Engine 可免费使用并且包括多达500 MB 的存储及足够的CPU 带宽来满足每天5 百万次页面浏览。 Google App Engine 提供了一些有用的基础设施,比如源自GFS 的数据存储和一个memcache实现。然而,它并不提供开箱即用的排队机制。不过,有了这样一个纯Python 的编程环境,就可以在App Engine 之上很容易地创建您自已的JMS 替代。这个数据存储很适合于混合应用程序,并且只需很少的Python 编程就可以打造出一个面向您的队列的RESTful式接口。 2原理 2.1 GFS(Google文件系统) 2.1.1特点 采用廉价的商用机器构建分布式文件系统,将容错的任务交由文件系统来完成,利用软件的方法解决系统可靠性问题,从而使存储的成本下降;保证在频繁的故障中确保数据存储的安全,保证提供不间断的数据存储服务。
从整体来看,Google的云计算平台包括了如下的技术层次。 ●网络系统:包括外部网络(Exterior Network) ,这个外部网络并不是指运营商自己的骨干网,也是指在Google 云计算服务器中心以外,由Google 自己搭建的由于不同地区/国家,不同应用之间的负载平衡的数据交换网络。内部网络(Interior Network),连接各个Google自建的数据中心之间的网络系统。 ●硬件系统:从层次上来看,包括单个服务器、整合了多服务器机架和存放、连接各个服务器机架的数据中心(IDC)。 ●软件系统:包括每个服务器上面的安装的单机的操作系统经过修改过的Redhat Linux。Google 云计算底层软件系统(文件系统GFS、并行计算处理算法Mapreduce、并行数据库Bigtable,并行锁服务Chubby Lock,云计算消息队列GWQ) ●Google 内部使用的软件开发工具Python、Java、C++ 等 ●Google 自己开发的应用软件Google Search 、Google Email 、Google Earth 外部网络系统介绍 当一个互联网用户输入的时候,这个URL请求就会发到Google DNS 解析服务器当中去,Google 的DNS 服务器会根据用户自身的IP 地址来判断,这个用户请求是来自哪个国家、哪个地区。根据不同用户的IP地址信息,解析到不同的Google的数据中心。 进入第一道防火墙,这次防火墙主要是根据不同端口来判断应用,过滤相应的流量。如果仅仅接受浏览器应用的访问,一般只会开放80 端口http,和443 端口https (通过SSL加密)。将其他的来自互联网上的非Ipv4 /V6 非80/443 端口的请求都放弃,避免遭受互联网上大量的DOS 攻击。 在大量的web 应用服务器群(Web Server Farm)前,Google使用反向代理(Reverse Proxy)的技术。反向代理(Reverse Proxy)方式是指以代理服务器来接受internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给Internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
2015年高职技能大赛 “云计算技术与应用”练习卷第一部分:云平台架构准备(2分) 云平台信息 网络部署规划:部署图和IP表。 网络拓扑图
IP地址规划表 根据以上云平台信息,检查硬件连线情况及网络设备配置,确保符合要求。提交交换机配置信息、防火墙网络2个接口的网页截图和防火墙规则的网页截图到本题的答题框中。(本题2分) 第二部分:云平台搭建(43分) 场景说明 你们是某企业的IT部分,目前负责公司云平台的构建,你们需完成云平台设计、部署和运维,同时实现云存储企业网盘开发。试搭建满足以上云计算要求的平台。 任务一、IaaS平台系统准备(10分) 1.环境配置 手动配置云平台IaaS各节点系统参数: (1)控制节点主机名:controller;计算节点主机名:compute;使用hostname命令进 行查询。 (2)根据部署图配置ip,永久关闭服务NetworkManager;使用ifconfig命令、chkconfig 命令进行查询。 (3)修改hosts,映射各节点管理ip与主机名;2 使用cat命令进行查询。 (4)各个节点的selinux设为permissive,使用getenforce命令进行查询。
提交控制节点的各项配置查询信息和计算节点的各项配置查询信息到本题答题框中。(本题4分) 2.FTP配置 把软件包拷贝到控制节点/opt/路径下,安装并配置ftp服务,配置控制节点与计算节点使用yum源文件yum.repo,地址使用ftp形式。提交控制节点和计算节点yum.repo 配置文件内容的信息到本题答题框中。(本题2分) 3.NTP和QPID配置 在各节点安装ntp服务并在控制节点上启动服务,计算节点时钟同步到控制节点,并设置开机自启动;在控制节点安装qpid服务,修改配置文件后启动服务。提交以下信息到本题答题框中:ntp配置文件名、配置修改内容、chkconfig查询结果和在计算节点同步结果;qpid配置文件名,修改内容、chkconfig查询结果。(本题2分) 4.数据库安装 安装数据库mysql。提交查询数据库的databases列表信息的命令及结果到本题答题框中。(本题3分) 任务二、IaaS系统组建(18分) 1.keystone安装 安装keystone组件。提交Keystone tenant列表查询信息到答题框中,admin-openrc.sh 环境变量配置文件在/etc/keystone/目录。(本题2分) 2.keystone管理 创建keystone用户user,密码为passw0rd,创建tenant名为group,赋予user在group 中拥有_member_权限。提交user列表查询命令及信息、tenant列表查询命令及信息和user-role查询命令及信息到答题框中。(本题2分) 3.glance安装 安装glance组件。提交image列表查询信息到答题框中。(本题2分) 4.glance管理 使用镜像文件centos_65_x86_6420140327.qcow2创建glance镜像centos,格式为qcow2,提交查询该镜像的信息文本到答题框中。(本题2分) 5.nova安装
第1章绪论 很少有一种技术能够像“云计算”这样,在短短的两年间就产生巨大的影响力。Google、亚马逊、IBM和微软等IT巨头们以前所未有的速度和规模推动云计算技术和产品的普及,一些学术活动迅速将云计算提上议事日程,支持和反对的声音不绝于耳。那么,云计算到底是什么?发展现状如何?它的实现机制是什么?它与网格计算是什么关系?。本章将分析这些问题,目的是帮助读者对云计算形成一个初步认识。 1.1 云计算的概念 云计算(Cloud Computing)是在2007年第3季度才诞生的新名词,但仅仅过了半年多,其受到关注的程度就超过了网格计算(Grid Computing),如图1-1所示。 搜索量指数Google Tronds 云计算 网格计算 图1-1 云计算和网格计算在Google中的搜索趋势 然而,对于到底什么是云计算,至少可以找到100种解释,目前还没有公认的定义。本书给出一种定义,供读者参考。 云计算是一种商业计算模型,它将计算任务分布在大量计算机构成的资源池上,使用户能够按需获取计算力、存储空间和信息服务。 这种资源池称为“云”。“云”是一些可以自我维护和管理的虚拟计算资源,通常是一些大型服务器集群,包括计算服务器、存储服务器和宽带资源等。云计算将计算资源集中起来,并通过专门软件实现自动管理,无需人为参与。用户可以动态申请部分资源,支持各种应用程序的运转,无需为烦琐的细节而烦恼,能够更加专注于自己的业务,有利于提高效率、降低成本和技术创新。云计算的核心理念是资源池,这与早在2002年就提出的网格计算池(Computing Pool)的概念非常相似[3][4]。网格计算池将计算和存储资源虚拟成为一个可以任意组合分配的集合,池的规模可以动态扩展,分配给用户的处理能力可以动态回收重用。这种模式能够大大提高资源的利用率,提升平台的服务质量。 之所以称为“云”,是因为它在某些方面具有现实中云的特征:云一般都较大;云的
Google 云计算技术架构: Google 云计算技术架构应用均依赖于四个基本组件1.分布式文件存储(GFS),2,并行数据处理模型(MapReduce).3分布式锁(Chubby).4,结构化数据表(BigTable). Chubby的作用:1.为GFS提供锁服务,选择Master节点:记录Master的相关描述信息;2:通过独占锁记录Chunk Server 的活跃情况;3:为BigTable提供锁服务,记录子表信息(如子表文件信息,子表分类信息,子表服务信息);4:记录MapReduce的任务信息;5:为第三方提供锁服务与文件存储. GFS的作用:1.存储Bigtable的子表文件,2:为第三方应用提供大尺寸文件存储功能;3:文件读操作流程(API与Mater 通信,获取文件元信息,根据指定的读取位置与读取长度,API发动兵发起操作,分别从若干ChunkServer上读取数据,API组装所得数据,返回结果. BigT able的作用:1.为Google云计算应用(或第三方应用)提供数据结构化存储功能;2:类似于数据库;3:为应用提供简单数据查询功能(不支持联合查询);4:为MapReduce提供数据源或者数据结果存储. BigT able的存储于服务请求的响应:1.换分为子表存储,每一个子表对应一个子表文件,子表文件存储于GFS 上;2:bigTable通过元数据组织子集;3:每个子集都被分配给一个子表服务器;4:一个子表服务器可同时分配多个子表;4:子表服务器负责对外提供服务,响应查询请求. MapReduce的作用:对BigTable中的数据进行并行计算处理;2使用BigTable或者GFS存储计算结果 Google Analytics:免费的企业级网络分析解决方案;2:帮助企业了解网站流量和营销效果;3:能以灵活的反噬(各类报表)查看并分析流量数据 Google网站流量分析的基本功能:统计网站的基本数据,包括会话,综合浏览量,点击量和字节流量;2:分析网站页面关注度,帮助企业调整或者增删页面;3:分析用户浏览路径,优化页面布局;4:分析用户访问来源连接,提供广告投资回报;5:分析用户访问环境,帮助美化页面 EC2:Eastic Compute Cloud)简言之,EC2就是一部具有无限采集能力的虚拟计算机,用户能够用来执行一些处理任务EC2的主要特征:1:灵活性,可以自行配置的实例类型,数量,还可以选择实例运行的地理位置,可以根据影虎的需求随时改变实例的使用数量;2:低成本:SSH,可配置的防火墙机制,监控等;3:易用性:用户可以根据亚马逊提供的模块自由构建自己的应用程序,同时EC2还会对用户的服务请求自动进行负载均衡;3:容错性,弹性IP 简单队列服务SQS:目标:解决低耦合系统间的通信问题,支持分布式计算机系统之间的工作流, 简单队列服务SQS:特点:简单,无处不在 简单队列服务SQS:的机制:冗余存储,给予加权随机分布的消息取样,并发管理和故障排除,消息的可见性超时值与生命周期 SDB与S3的区别:S3是专为大型,费结构化的数据块设计的;SimpleDB是为复杂的,结构化数据建立的,支持数据的查找,删除,插入等操作
Computer Knowledge and Technology电脑知识与技术第5卷第25期(2009年9月) 基于Google的云计算实例分析 蔡键1,王树梅2 (1.徐州师范大学现代教育技术中心,江苏徐州221116;2.徐州师范大学计算机科学与技术学院,江苏徐州221116) 摘要:首先介绍了云计算产生的背景、概念、基本原理和体系结构,然后以Google系统为例详细阐述了云计算的实现机制。云计算是并行计算、分布式计算和网格计算等计算机科学概念的商业实现。Google拥有自己云计算平台,提供了云计算的实现机制和基础构架模式。该文阐述了Google云计算平台:GFS分布式文件、分布式数据库BigTable及Map/Reduce编程模式。最后分析了云计算发展所面临的挑战。 关键词:云计算;集群;谷歌文件系统;大表;映射/化简 中图分类号:TP311文献标识码:A文章编号:1009-3044(2009)25-7093-03 Cloud Computing System Instances Based on Google CAI Jian1,WANG Shu-mei2 (1.Xuzhou Normal University Modern Educational Technology Center,Xuzhou221116,China;2.Xuzhou Normal University,School of Computer Science&Technology,Xuzhou221116,China) Abstract:This paper introduces the backgrounds,concept,basic principle and infrastructure of cloud computing firstly.Then it surveys im-plementation mechanism of clouding computing based on the instances of Google.Cloud computing is the system in enterprises based on the concepts of computer science.These concepts include parallel computing,distributed computing and grid computing.Google has his own platform of cloud computing.It provides implementation mechanism and infrastructure of cloud computing.This paper surveys the platform of cloud computing:Google File System,Distributed database-BigTable and Map/Reduce.Finally the paper analyse the challenge of cloud computing. Key words:cloud computing;cluster;GFS;bigtable;map/reduce 自2007年第4季度开始,“云计算”变成了IT领域新的热点。而2008年被称为云计算的元年,Google、Amazon、IBM、微软等IT 巨头们以前所未有的速度和规模推动云计算技术和产品的普及。本文介绍一些关于云计算的一些基本概念及Google提出的云计算模型及实现机制。 1云计算综述 云计算是并行计算(Parallel Computing)、分布式计算(Distributed Computing)和网格计算(Grid Computing)的发展,或者说是这些计算机科学概念的商业实现。 云计算是虚拟化(Virtualization)、效用计算(Utility Computing)、IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等概念混合演进并跃升的结果。 1.1云计算的概念 云计算现在还没有统一标准的定义,一些大公司在自己的技术文档里给出了自己的定义。例如云计算在IBM的文档中对云计算的定义是:云计算一词用来描述一个系统平台或者一种类型的应用程序。一个云计算的平台按需进行动态的部署、配置、重新配置以及撤销服务等。 而对云计算更加通用的的定义是:云计算是一种商业计算模型。它 将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根 据需要获取计算力、存储空间和各种软件服务。从这个定义上讲可把云 计算看成是“存储云”与“计算云”的有机结合。存储云对第三方用户公 开存储接口,用户通过这个接口可以把数据存储到“云”。计算云通过并 行计算和虚拟化技术给用户提供计算力,它的商业模式是给用户提供计 算力。 1.2云计算实现机制 图1简单的描述了云计算的实现机制。用户通过用户交互接口 (User interaction interface)来请求服务云。一个用户能够请求的所有服务 目录存放在服务目录(Services catalog)里。系统管理(System manage- ment)是用户管理计算机资源是否可用。服务提供工具(Provisioning tool)用来处理请求的服务,需要部署服务配置。监控统计(Monitoring 收稿日期:2009-05-07 作者简介:蔡键,硕士,讲师,主研领域为图形图像处理,网格技术。图1云计算实现机制 ISSN1009-3044 Computer Knowledge and Technology电脑知识与技术Vol.5,No.25,September2009,pp.7093-7095,7107 E-mail:info@https://www.doczj.com/doc/ed16851746.html, https://www.doczj.com/doc/ed16851746.html, Tel:+86-551-56909635690964
谷歌云计算的现状与发展
摘要:Google作为世界云计算的“领头人”,它在云计算的研究与开发方面做得非常出色,从Google 的整体的技术构架来看,Google计算系统依然是边做科学研究,边进行商业部署,依靠系统冗余和良好的软件构架来低成本的支撑庞大的系统运作的,大型的并行计算,超大规模的IDC 快速部署,通过系统构架来使廉价PC 服务器具有超过大型机的稳定性都已经不在是科学实验室的故事,已经成为了互联网时代,IT 企业获得核心竞争力发展的基石。尽管云计算是个刚刚出现没多久的新词汇,尽管我们还处在在云计算的起跑阶段,但是,我们从Google的与计算技术构架里,就可以获得很多信息,那些信息可能就是我们通向未来互联网全新格局的钥匙。 关键词:云计算 Google 技术构架 云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。 我们可以认为:云计算是通过网络按需提供可动态伸缩的廉价计算服务。 提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。这种特性经常被称为像水电一样使用IT基础设施。
有人打了个比方:这就好比是从古老的单台发电机模式转向了电厂集中供电的模式。它意味着计算能力也可以作为一种商品进行流通,就像煤气、水电一样,取用方便,费用低廉。最大的不同在于,它是通过互联网进行传输的。 云计算是并行计算、分布式计算和网格计算的发展,或者说是这些计算机科学概念的商业实现。云计算是虚拟化、公用计算、IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等概念混合演进并跃升的结果。 总的来说,云计算可以算作是网格计算的一个商业演化版。 “Google”是美国一家上市公司,于1998年9月7日以私有股份公司的形式创立,以设计并管理一个互联网搜索引擎。Google公司的总部称作“Googleplex”,它位于加利福尼亚山景城。Google公司致力于互联网的应用与高新产业的开发。它在云计算的研发与发展方面,同样走在世界的前列。2006年8月9日,Google首席执行官埃里克·施密特在搜索引擎大会首次提出“云计算”的概念。Google“云端计算”源于Google工程师克里斯托弗·比希利亚所做“Google 101”项目。 2007年10月,Google与IBM开始在美国大学校园,包括卡内基梅隆大学、麻省理工学院、斯坦福大学、加州大学柏克莱分校及马里兰大学等,推广云计算的计划,这项计划
云计算环境下的应用特点 多年来应用程序开发者和架构师们都在努力设计一种既能够在功能上满足当前业务需求,另外又能够在用户需求发生变化或者能够在可预见的将来适应环境变化的应用。尤其是在互联网领域,架构师都在努力让自己设计的应用具有比较强的扩展能力,能够跟得上用户不断增长或者出现突发请求的一些情况。在传统的 Web应用设计中,我们在架构上一般采用基于多层架构的设计,在Web层中大量使用了负载均衡等技术。一般我们的处理方式都是在应用程序设计好之后,在应用部署的过程中事先把环境配置好,应用程序在运行过程配置都是不发生变化的。但是,随着云计算时代的到来,我们面对一些新的挑战,相应的应用程序设计方式随之发生了一些变化。我们首先从云计算的技术特点开始讨论应用的变化。 从技术角度看云计算的特点 毫无疑问,云计算是目前信息产业中讨论得最多的话题。虽然大家对于云计算还没有一致定义,但是对于云计算的一些特点,相关的服务模型等内容日渐趋于统一。在讨论云计算应用架构特点之前,我们先从技术的角度来讨论一下云计算本身的一些特点。 * 按需服务 云计算是一个把信息技术作为服务(IT as a Service)提供的一种方式。这种服务的概念都是从消费方(用户)角度出发,而不是从服务提供方出发考虑问题,因此,一个基本特点是云计算要求按需服务,即用户可以根据需求即时得到服务。从这个角度讲,云计算就像我们公共服务中的自来水、电和煤气一样,集中供应并按需服务和计费。 * 资源池 云计算的一个好处是提高资源的利用率,而这个一般需要通过共享的方式来达到这个目的。这里可以类比一下我们日常吃饭中的自助餐和桌餐的差别。如果需要共享就需要先把资源集中到一个公共的资源池中。在云计算当中,根据这个资源池中资源的类别,我们把云计算的服务模型分为三种,即所谓的SPI 模型,如下表所示: * 高可扩展性 云计算平台的资源池相对于单个用户的需求而言是比较大的,因此考虑到会有大量不同用户共用一个资源池,他们之间的资源使用模式一般存在一定的互补性,所以对于某个用户的需求而言,云计算具有很高的扩展性。另外,云计算平台在做架构设计的时候,都会考虑到如何让用户可以平滑扩展他们的资源需求,比如计算资源,存储资源等。 * 弹性服务 弹性服务指的是云计算的资源分配可以根据应用访问具体情况进行动态地调整。也正是因为如此,云计算对于非恒定需求的应用,比如需求波动很大、阶段性需求等,具有非常好的应用效果。在云计算的环境中,资源的扩展方式可以分为两大类,一种是事先可以预测的,比如一些季节性的需求。另一种是完全基于某种规则实时动态调整的。无论是哪一种,都要求云计算平台提供弹性的服务。 * 自服务和自动化 对于自服务和自动化概念本身都比较好理解,但是我把这两个放在一起是因为它们之间的内在联系。自服务是云计算中降低服务成本,提高服务便捷性的一种途
云计算技术的发展和应用 班级:2011级计科系计本班姓名:何玲芳 摘要:重点解读了云计算这种新的网络应用模式的概念,阐述了 其实现的方式,分析了其在现阶段的优势,并对现有的云计算服务进行了简略的介绍。最后以实例阐述了云计算技术的应用。 关键字:云计算网络发展应用 在计算机网络不断发展过程当中,总是能够提出一些新的概念让我们目不暇接。在“网络”概念提出10余年后,又一个类似其改进版的新概念“云计算”被重新提了出来。 云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机和其他设备。云是网络、互联网的一种比喻说法。过去在图中往往用云来表示电信网,后来也用来表示互联网和底层基础设施的抽象。云计算是继1980年代大型计算机到客户端-服务器的大转变之后的又一种巨变。用户不再需要了解“云”中基础设施的细节,不必具有相应的专业知识,也无需直接进行控制。云计算描述了一种基于互联网的新的IT服务增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展而且经常是虚拟化的资源,它意味着计算能力也可作为一种商品通过互联网进行流通。 云计算是分布式处理,并行处理和网络计算的发展,或者说是这些计算机科学概念的商业实现。云计算的基本原理是:通过使计算机分布在大量的分布式计算机上,而非本地计算机或远程服务器中,企业数据中心的运行将更与互联网相似。这使得企业能够将资源切换到需要的应用上,根据需求访问计算机和存储系统。这就好比是从古老的单台发电机模式转向了电厂集中供电的模式,它意味着计算机能力也可以作为一种商品进行流通,就像煤气,水电一样,取用方便,费用低廉。最大的不同在于,它是通过互联网进行传输的。因此,在未来,只需要一台笔记本或者一个手机,就可以通过网络服务来实现我们需要的一切,甚至包括超级计算这样的任务,从这个角度而言,最终用户才是云计算的真正拥有者。云计算的应用包括这样的一种思想,把力量联合起来,给其中的每一个成员使用。对于云计算,李开复(原Google全球副总裁,中国区总裁)打了一个形象的比喻:钱庄。最早人们只是把钱放在枕头底下,后来有了钱庄,很安全,不过,兑现起来比较麻烦。现在发展到银行可以到任何一个网点取钱,甚至通过ATM,或者国外的渠道。“云计算”带来的这样一种变革——由谷歌,IBM这样的专业网络公司来搭建计算机存储,运算中心,用户通过一根网线借助浏览器就可以很方便的访问,把“云”作为资料存储以及应用服务的中心。 云计算的优势毫不保留的展现在世人面前,人们确实体会到了它的伟大与神奇。它的优势有:廉价,计算能力比以往的任何方式都强大,数据存储在云端,人们不用担心数据的丢失。IBM曾经表示,他们的管理使任何用户的数据都存储三份,当其中一份出现崩溃,丢失之类的问题后检测系统会自然的在另外一个地方再次复制一份。数据丢失对用户来说是个从来不用担心的问题。云计算的规模性可以使所有的资源充分共享,同步。在这方面苹果公司的同步功能无疑是令人印象深刻的。云计算对于数据的存储能力也是毋庸置疑的,仿佛人类世界的所有数据都不足以填满,事实也的确是这样,不然Google怎
云计算典型应用案例
郑萌
版权
} 华清远见嵌入式培训中心版权所有; } 未经华清远见明确许可,不能为任何目的以任何形式复制
或传播此文档的任何部分; } 本文档包含的信息如有更改,恕不另行通知; } 保留所有权利。
2
https://www.doczj.com/doc/ed16851746.html,
云计算已成为业界趋势
l 云计算是一种新兴的计算模式,通过网络将应用、数据及IT资源通过服务的方式 来提供。
l 云计算的推动力
l 商业需求: 降低IT成本、简化IT管理和快速响应市场变化 l 运营的需求:规范流程、降低成本、节约能源
2010
l 计算的需求:更大的数据量、更多的用户
l 技术的进步:虚拟化、多核、自动化、Web技术
云计算
随需应变的计算
1990
网格计算
? 用并行计算解 决大的计算问 题
效用计算
? 把计算资源 作为一种可计 量的服务提供 出来
软件即是服务
? 基于网络的 应用订购
? 整合的端到 端业务,能 够快速响应 任何客户需 求、市场机 会或者外部 威胁
? 在任何时间、 任何地点访问 动 态 提 供 的 IT 资源
https://www.doczj.com/doc/ed16851746.html,
云计算的理想
} 开放标准
} 一个云 vs. 多个云 } 基于开放标准的云的交互性 } 开放云标准组织 (DMTF)
} Open Cloud Standards Incubator (OCSI) } IBM、惠普、VMware、Citrix 等多家国际厂商参与
} 安全管理、高可用性、性能管理及服务管理能力 } 着重于业务价值的实现 } 企业架构的平滑过渡,保护既有投资
https://www.doczj.com/doc/ed16851746.html,
云计算应用若干典型案例 胡经国 本文作者的话 本文是根据有关文献和资料编写的《漫话云计算》系列文稿之一。现作为云计算学习笔录,奉献给云计算业外读者,作为进一步学习和研究的参考。希望能够得到大家的指教和喜欢! 下面是正文 有人问,云计算飘忽不定,到底可不可以落地?下面,介绍天云科技做过的三个主要的云计算应用典型案例。让大家看看,云计算到底是如何落地的,在哪里可以落地。 一、上海浦东软件园区公有云服务平台 第一个案例是在上海浦东软件园区部署的公有云服务平台。 1、功能和定位 首先是提供云计算环境,提供通用的企业管理软件。这是作为云计算SaaS (软件即服务)的组成部分。另外,提供开发测试环境PaaS(平台即服务)。提供SaaS和PaaS是该项目的功能和定位。 2、规模 在一期工程时,项目规模并不是非常大。它的服务器节点数大概是100台服务器,800个CPU,网络结点20个,存储加起来大概有300T。 3、三层服务 提供云计算三层服务,包括基础设施服务、平台服务和软件服务。 4、服务优势 这个IT服务云的服务优势大概有以下几点: ⑴、经济性 从以前购买到现在的租赁方式,会有更加经济实惠的考量。 ⑵、高效 这也是核心的部分,包括计算、存储、网络资源的共享。 打破传统数据方式的壁垒,同时利用虚拟化技术来提高系统的整合程度。
⑶、海量 云计算讲究有海量数据的存储和海量数据的处理。这些都是属于云计算很典型的使用场景。 ⑷、高可靠性 它的高可靠性,实际上是依靠一系列的手段,比如虚拟机的迁移,文件存储多备份,负载均衡等。采用这些技术手段来保证系统的高可靠性。 ⑸、灵活弹性扩容和在线扩容能力 5、云服务平台架构 整个云平台架构包括以下几个组成部分: ⑴、物理基础设施 最下层,是比较常见的物理服务器,还包括网络、存储设备。 ⑵、资源池虚拟化部分 在此之上,是资源池虚拟化部分,包括服务器虚拟化、存储虚拟化、网络虚拟化。 ⑶、运行支持系统 在虚拟化之上,是一个运行支持系统。 ①、服务门户 在这里,提供一些服务门户。这些服务门户根据不同的用户来讲,可以分为:前端和后端用户。前端用户,就是我们直接服务的互联网的最终用户。后端用户可分成几类,包括服务管理,业务管理人员,还有系统维护人员。这几类用户会使用我们的门户系统。 ②、服务管理系统 还有一个是服务管理系统,包括云计算的三层架构都作为服务。必须要有一个服务的设计、服务的开发测试、服务的发布、服务目录等等。这是独立的服务管理部分。 ⑷、业务支撑系统 再上面,是业务支撑系统。既然作为服务系统,必须要有客户关系管理、计费、订单。 以上就是目前天云能够实现的云服务平台的架构。 6、平台特点 它是运营商级的IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS (软件即服务)的平台。 它是基于通用x86的平台,还可以提供弹性计算资源和弹性存储资源。
Google云计算的关键技术(一) Google云计算的关键技术主要包括:Google文件系统GFS、分布式计算编程模型MapReduce、分布式锁服务Chubby和分布式结构化数据存储系统BigTable等。其中: 1)GFS提供了海量数据存储和访问的能力; 2)MapReduce使得海量信息的并行处理变得简单易行; 3)Chubby保证了分布式环境下并发操作的同步问题; 4)BigTable使得海量数据的管理和组织十分方便。 ●GFS GFS是一个面向海量数据密集型应用的、可伸缩的分布式文件系统,它为Google云计算提供了海量存储的能力,处于整个Google云计算技术体系的最底层。 GFS使用廉价的商用机器构建分布式文件系统,将容错的任务交由文件系统来完成,利用软件的方法解决系统可靠性的问题,不但使得存储的成本成倍下降,更是很好地在频繁的故障中确保了数据存储的安全和数据存储服务的连续性,从整体上确保了整个系统的可靠性,进而可以为大量客户机提供高性能的服务。 一、架构 一个GFS集群包含一个单独的Master逻辑节点、多台Chunk服务器,并且同时被多个客户端访问,如下图所示。
GFS存储的文件都被分割成固定大小的Chunk。在Chunk创建的时候,Master服务器会给每个Chunk分配一个不变的、全球唯一的64位的Chunk标识。Chunk服务器把Chunk以linux文件的形式保存在本地硬盘上,并且根据指定的Chunk标识和字节范围来读写块数据。出于可靠性的考虑,每个块都会复制到多个块服务器上。缺省情况下,我们使用3个存储复制节点,不过用户可以为不同的文件命名空间设定不同的复制级别。 Master节点管理所有的文件系统元数据,在逻辑上只有一个。这些元数据包括名字空间、访问控制信息、文件和Chunk的映射信息、以及当前Chunk的位置信息;Master节点还管理着系统范围内的活动,比如Chunk在Chunk服务器之间的迁移等。Master节点使用心跳信息周期地和每个Chunk服务器通讯,发送指令到各个Chunk服务器并接收Chunk服务器的状态信息。 GFS客户端代码以库的形式被链接到客户程序里。客户端代码实现了GFS文件系统的API 接口函数、应用程序与Master节点和Chunk服务器通讯、以及对数据进行读写操作。客户端和Master节点的通信只获取元数据,所有的数据操作都是由客户端直接和Chunk服务器进行交互的。 无论是客户端还是Chunk服务器都不需要缓存文件数据(客户端会缓存元数据)。客户端缓存数据几乎没有什么用处,因为大部分程序要么以流的方式读取一个巨大文件,要么工作集太大根本无法被缓存。Chunk服务器不需要缓存文件数据的原因是:Chunk以本地文件的方式保存,Linux操作系统的文件系统缓存会把经常访问的数据缓存在内存中。 设计思路:集中+分布。单一的Master节点便于通过全局的信息精确定位Chunk的位置以及进行复制决策。同时,为了避免Master节点成为系统的瓶颈,必须减少对Master节点的读写:客户端并不通过Master节点读写文件数据,只是通过其询问应该联系的Chunk服务器,后续的操作将直接和Chunk服务器进行数据读写操作。 二、客户端访问GFS流程 首先,客户端把文件名和程序指定的字节偏移,根据固定的Chunk大小,转换成文件的Chunk 索引。然后,它把文件名和Chunk索引发送给Master节点。Master节点将相应的Chunk 标识和副本的位置信息发还给客户端。客户端用文件名和Chunk索引作为key缓存这些信息。 之后客户端发送请求到其中的一个副本处,一般会选择最近的。请求信息包含了Chunk的标识和字节范围。在对这个Chunk的后续读取操作中,客户端不必再和Master节点通讯了,除非缓存的元数据信息过期或者文件被重新打开。 三、Chunk尺寸的设定 Chunk的大小是关键的设计参数之一。选择64MB这个较大尺寸有几个重要的优点。首先,它减少了客户端和Master节点通讯的需求,因为只需要一次和Mater节点的通信就可以获
**省 装备制造业、信息产业职工职业技能大赛“云计算技术与应用”样题
第一部分竞赛说明 本套竞赛题目共包含理论知识竞赛、实际操作竞赛两个部分,其中: 第一部分理论知识竞赛部分满分100分,占总成绩的30%,竞赛时间60分钟,含: (一)单项选择题(50分),共10小题(每小题5分) (二)多项选择题(50分),共5小题(每小题10分) 第二部分实际操作竞赛部分满分100分,占总成绩的70%,竞赛240分钟,含 (一)云平台搭建(80分),任务一4小题(每小题6分),任务二8小题(每小题7分) (二)工作总结报告(10分) (三)职业素养(10分)
第二部分理论知识竞赛部分 (一)单项选择题(50分) 在每小题列出的四个备选项中只有一个是符合题目要求的,请将其选出并将“答题纸”的相应代码涂黑。错涂、多涂或未涂均无分。(本大题共10小题,每小题5分,共50分) 1.下列哪一个选项不属于云计算中需要安装的服务 A.IaaS(基础架构即服务) B. PaaS(平台即服务) C.SaaS(软件即服务) D.BTB 2. OpenStack是目前一套主流云平台,是一整套开源软件项目的综合, 它允许企业或服务提供者建立、运行自己的云计算和存储设施,OpenStack的底层核心技术是 A.虚拟化技术 B.路由交换技术 C.移动互联技术 D.计算机组装技术 3.下列关于云计算的说法错误的是 A. 云计算是一种 IT 资源的交付和使用模式 B. 云计算就是基于互联网的计算。共享的资源,软件和信息,以按需 的方式提供服务,就像用水,用电一样,按需缴费,不用关心水、电是哪里来的” C. 云计算就是用来计算海量的数据,它只具有计算能力 D. 通过网络以按需、易扩展的方式获得所需的硬件、平台、软件及服
云计算在生活的实例 云正在与我们的生活越飘越近,然而,它的概念却离我们越来越远。笔者日前在网上看到一组调查数据,有90%以上的读者不知道云计算为何物。当我拿着这组数据,跟一位业内人士诉说时,他却不屑地回答:不止90%吧,真正懂的估计不到1%。 他也纠结于云计算的理解障碍,太抽象了,没有具体可感的东西,所以理解起来费劲。龙真也告诉笔者,这个概念本身就是一个很扯淡的事。基于此,笔者四处向专业人士取经,直到有人推荐了这本《IT不再重要》。 云计算是个浮躁的概念,被商业化的速度远超过我们想象。由于云计算的应用,一大批云产品被问世,这其中有真货,也有水货。但是,只要我们理解了云计算概念的本质,就自然能清晰地辨别,所谓的他们口中云产品,究竟是个什么东西。 云计算是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。云是网络、互联网的一种比喻说法。过去在图中往往用云来表示电信网,后来也用来表示互联网和底层基础设施的抽象。因此,云计算甚至可以让你体验每秒10万亿次的运算能力,拥有这么强大的计算能力可以模拟核爆炸、预测气候变化和市场发展趋势。用户通过电脑、笔记本、手机等方式接入数据中心,按自己的需求进行运算。 云计算在生活的实例云计算开始被我们广泛认知,大量的SaaS、PaaS、IaaS等名词开始出现,很多人也许都会说这些都是使用IT服务业的省钱的好办法。的确,服务器的虚拟化与互联网技术的快速发展,使IT资源的使用逐渐增加,当然我们可以采用如拼车和团购类似的做法以达到利益的最大化。云服务上的团购和拼车可以比现实生活中的版本做的更好。首先可以对每一个客户按资源的使用量和使用时间进行不同的收费。还可以对客房的大小做出相对应的动态调整。 既然云计算的主要任务是在异地执行(off-premises execuTIon)的,计算所需容量就不必受某地具备的计算处理资源量所限制,弹性可扩展也就自然成为云计算的一大特点。这个
云计算实例分析:Google的云计算平台 2010-01-10 17:23 Google的云计算技术实际上是针对Google特定的网络应用程序而定制的。针对内部网络数据规模超大的特点,Google提出了一整套基于分布式并行集群方式的基础架构,利用软件的能力来处理集群中经常 发生的节点失效问题。 从2003年开始,Google连续几年在计算机系统研究领域的最顶级会议与杂志上发表论文,揭示其内部的分布式数据处理方法,向外界展示其使用的云计算核心技术。从其近几年发表的论文来看,Google使用的云计算基础架构模式包括四个相互独立又紧密结合在一起的系统。包括Google建立在集群之上的文件系统Google File System,针对Google应用程序的特点提出的Map/Reduce编程模式,分布式的锁机制Chubby以及Google开发的模型简化的大规模分布式数据库BigTable。 Google File System 文件系统 为了满足Google迅速增长的数据处理需求,Google设计并实现了Google文件系统(GFS,Google File System)。GFS与过去的分布式文件系统拥有许多相同的目标,例如性能、可伸缩性、可靠性以及可用性。然而,它的设计还受到Google应用负载和技术环境的影响。主要体现在以下四个方面: 1. 集群中的节点失效是一种常态,而不是一种异常。由于参与运算与处理的节点数目非常庞大,通常会使用上千个节点进行共同计算,因此,每时每刻总会有节点处在失效状态。需要通过软件程序模块,监视系统的动态运行状况,侦测错误,并且将容错以及自动恢复系统集成在系统中。 2. Google系统中的文件大小与通常文件系统中的文件大小概念不一样,文件大小通常以G字节计。另外文件系统中的文件含义与通常文件不同,一个大文件可能包含大量数目的通常意义上的小文件。所以,设计预期和参数,例如I/O操作和块尺寸都要重新考虑。 3. Google文件系统中的文件读写模式和传统的文件系统不同。在Google应用(如搜索)中对大部分文件的修改,不是覆盖原有数据,而是在文件尾追加新数据。对文件的随机写是几乎不存在的。对于这类巨大文件的访问模式,客户端对数据块缓存失去了意义,追加操作成为性能优化和原子性(把一个事务看做是一个程序。它要么被完整地执行,要么完全不执行)保证的焦点。 4. 文件系统的某些具体操作不再透明,而且需要应用程序的协助完成,应用程序和文件系统API 的协同设计提高了整个系统的灵活性。例如,放松了对GFS一致性模型的要求,这样不用加重应用程序的负担,就大大简化了文件系统的设计。还引入了原子性的追加操作,这样多个客户端同时进行追加的时候,就不需要额外的同步操作了。 总之,GFS是为Google应用程序本身而设计的。据称,Google已经部署了许多GFS集群。有的集群拥有超过1000个存储节点,超过300T的硬盘空间,被不同机器上的数百个客户端连续不断地频繁访问着。