
一、浏览器内核
要搞清楚浏览器内核是什么,首先应该先搞清楚浏览器的构成。简单来说浏览器可以分为两部分,shell+内核。其中shell的种类相对比较多,内核则比较少。Shell是指浏览器的外壳:例如菜单,工具栏等。主要是提供给用户界面操作,参数设置等等。它是调用内核来实现各种功能的。内核才是浏览器的核心。内核是基于标记语言显示内容的程序或模块。也有一些浏览器并不区分外壳和内核。从Mozilla将Gecko独立出来后,才有了外壳和内核的明确划分。
1.什么是浏览器内核
浏览器内核又可以分成两部分:渲染引擎(layout engineer或者Rendering Engine)和JS引擎。它负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。(JS引擎则是解析Javascript语言,执行javascript语言来实现网页的动态效果。最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎。
1)常见的浏览器内核
●Trident(又称为MSHTML),是微软的视窗操作系统(Windows)搭载的网页浏
览器—Internet Explorer的页面渲染引擎的名称,目前是互联网上最流行的
排版引擎。
●Gecko是套开放源代码的、以C++编写的页面渲染引擎。Gecko是跨平台的,能
在Microsoft Windows、Linux和Mac OS X等主要操作系统上运行。它是最流
行的页面渲染引擎之一,其流行程度仅次于Trident。
●Webkit是苹果公司基于KHTML开发的。他包括Webcore和JavaScriptCore
(SquirrelFish,V8)两个引擎。
●Presto由Opera Software公司开始的,用于Opera的渲染引擎。Macromedia
Dreamweaver (MX版本及以上)和Adobe Creative Suite 2也使用了Presto
的内核。
2)JS引擎
JavaScript最初由网景公司的Brendan Eich设计,是一种动态、弱类型、基于原型的语言,内置支持类。以它为基础,制定了ECMAScript标准。他的起源并不是如《Javascript高级程序设计》书中所述,是Brendan Eich自主发明的。(参考aimingoo的考证文章)JavaScript在浏览器的实现中还必须含有DOM和BOM。Web浏览器一般使用公共API来创建主机对象来负责将DOM对象反射进JavaScript。
3)常见的浏览器的排版引擎(又称渲染引擎)及脚本引擎
2.浏览器内核实现原理
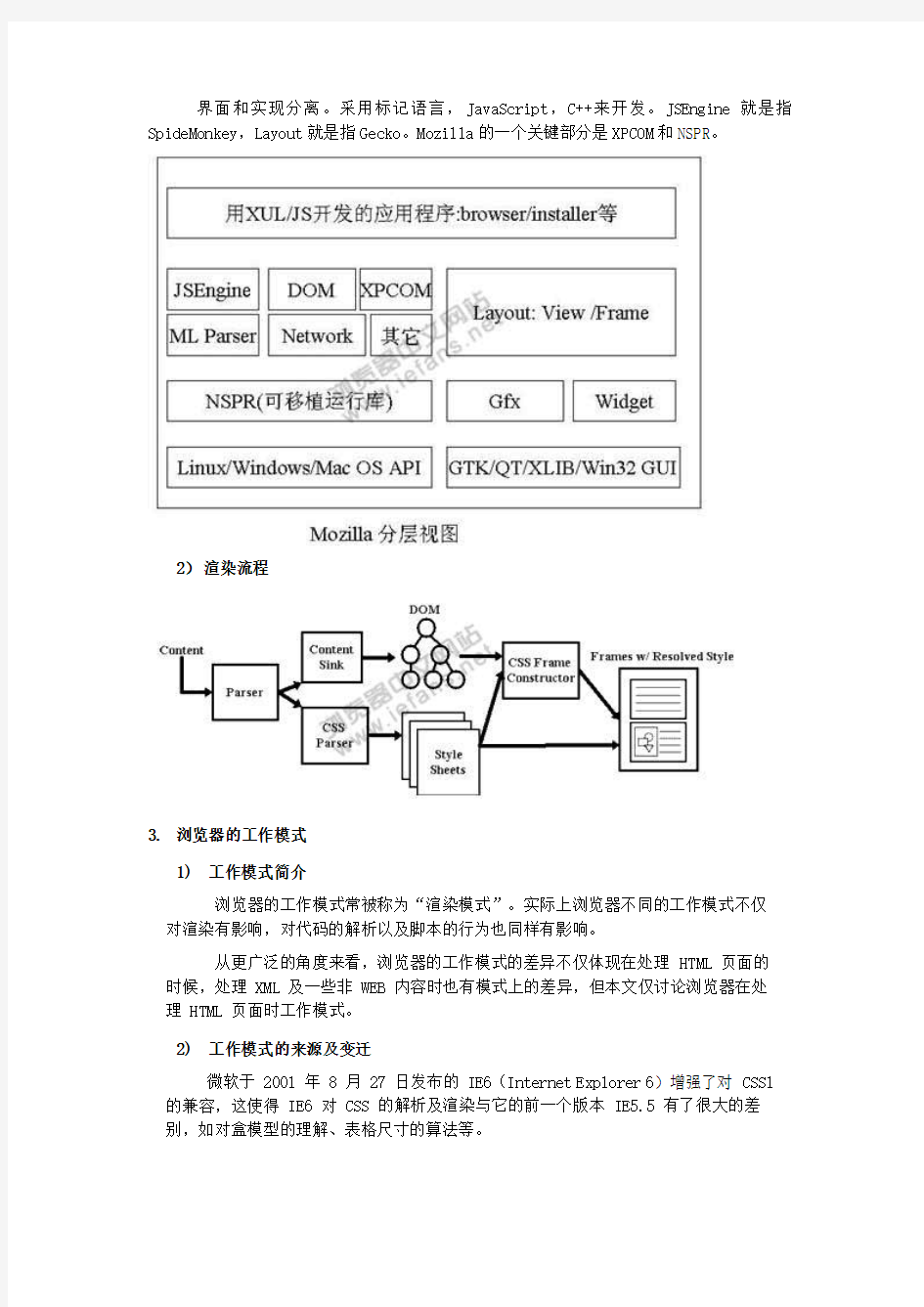
1)Mozilla架构设计
界面和实现分离。采用标记语言,JavaScript,C++来开发。JSEngine就是指SpideMonkey,Layout就是指Gecko。Mozilla的一个关键部分是XPCOM和NSPR。
2)渲染流程
3.浏览器的工作模式
1)工作模式简介
浏览器的工作模式常被称为“渲染模式”。实际上浏览器不同的工作模式不仅对渲染有影响,对代码的解析以及脚本的行为也同样有影响。
从更广泛的角度来看,浏览器的工作模式的差异不仅体现在处理 HTML 页面的时候,处理 XML 及一些非 WEB 内容时也有模式上的差异,但本文仅讨论浏览器在处理 HTML 页面时工作模式。
2)工作模式的来源及变迁
微软于 2001 年 8 月 27 日发布的 IE6(Internet Explorer 6)增强了对 CSS1 的兼容,这使得 IE6 对 CSS 的解析及渲染与它的前一个版本 IE5.5 有了很大的差别,如对盒模型的理解、表格尺寸的算法等。
为了保持良好的向后兼容性,微软为用户提供了一个“开关”,来决定浏览器的工作模式,这个“开关”就是页面顶部的 DTD。
某些 DTD 将使 IE6 工作在“标准兼容模式”(即“标准模式”),这种模式使用了IE6 最新的处理方式,包括对 CSS1 的兼容及一些 DHTML 方面的增强。
而另一些 DTD,包括不设置 DTD 将使 IE6 工作在“向后兼容模式”(即“混杂模
式”),这种模式对页面的处理是与 IE5.5 保持一致的,这样就可以保证对一些在IE5.5 中表现良好的页面在 IE6 中也能达到同样的效果。
微软在后续推出的 IE7、IE8 中,也使用了上述“开关”,与 IE6 一样,在 IE7、IE8 的“混杂模式”下,对页面处理方式仍与 IE5.5 一致。因此可以说,IE 系列的“混杂模式”,将浏览器的行为冻结在了 IE5.5 这个版本,虽然 IE 各版本的混杂模式也略有区别,但它们的本意都是向后兼容。
随着时间的推进和标准的进步,IE6、IE7 的“标准模式”逐渐已经变得不够标准了,2009年3月19日发布的 IE8 重新定义了“标准模式”,再次增强了对标准规范的支持,同时为了保持对 IE7 的兼容,IE8 增加了一种工作模式:“接近标准模式”。
于是,IE8 的工作模式就分成了三种:“标准模式”、“接近标准模式”和“混杂模式”。
目前所有主流浏览器对于向后兼容问题的处理都与 IE 系列一样,提供了不同的模式来保证向后兼容。
浏览器的工作模式就是在这种背景下诞生的,它很好的解决了浏览器对标准支持上的不断增强及对一些错误的修复而导致的向后兼容问题,但也将浏览器在不同情况下的表现及行为变得更加复杂多样。
通过以上的内容,我们可以得出结论:如果一个页面能使各浏览器都工作在“标准模式”下,那么各浏览器都将尽量兼容标准,因此各浏览器之间表现出的差异是很少的。相反,如果一个页面使各浏览器都工作在“混杂模式”下,那么各浏览器都将尽量向后兼容,因此各浏览器之间表现出的差异将会最大化。
二、浏览器兼容性问题
目前市面上流行的浏览器有多种,这些浏览器在处理一个相同的页面时,表现或行
为有时会有差异。这种差异可能很小,甚至不会被注意到;也可能很大,甚至造成在某
个浏览器下无法正常浏览。我们把引起这些差异的问题统称为“浏览器兼容性问题”。
1.浏览器兼容性问题分类
1)渲染相关
和样式相关的问题,即体现在布局效果上的问题。
2)脚本相关
和脚本相关的问题,包括JavaScript和DOM、BOM方面的问题。对于某些浏览器的功能方面的特性,也属于这一类
3)其他类别
除以上两类问题外的功能性问题,一般是浏览器自身提供的功能,在内核层之上的。
2. 浏览器兼容性问题产生原因
造成浏览器兼容性问题的根本原因就是浏览器各浏览器使用了不同的内核,并且它们处理同一件事情的时候思路不同。
1) 不同内核处理同一件事情的时候方法不同
比如:鼠标在元素内的位置。IE 中使用offsetX 和offsetY 来获取鼠标在网页中
某一元素的位置,FireFox 使用layerX 和layerY 来得到鼠标在网页中某一元素的位置
2) 不同内核对html ,css ,js 支持情况不同
有时候,同是Trident 内核的不同
ie 版本仍会出现兼容问题,原因是Trident
有不同版本,对html ,
css ,
js 的支持情况也不同。
不同浏览器内核和使用的js引擎版本情况:
3)浏览器自身特性差异
比如:ie浏览支持active插件,非ie浏览器不支持
三、拍拍侧前端开发对兼容性的支持
1.hack
是一种在CSS和HTML中使用的,针对兼容性问题进行修复的语句.它的表现形式多种多样,如特殊字符(*,+,_等)
1)css属性Hack
比如 IE6能识别下划线"_"和星号" * ",IE7能识别星号" * ",但不能识别下划线"_",而firefox两个都不能认识
2)选择器Hack
比如IE6能识别*html .class{},IE7能识别*+html .class{}或者*:first-child+html .class{}。
2.条件注释
条件注释只能在windows Internet Explorer(以下简称IE)下使用,因此我们可以通过条件注释来为IE添加特别的指令。条件注释从IE5开始被支持
条件注释的基本结构和HTML的注释()是一样的。因此IE以外的浏览器将会把它们看作是普通的注释而完全忽略它们
〈!--[if !IE]〉〈!--〉除IE外都可识别〈!--〈![endif]
〈!--[if IE]〉所有的IE可识别〈![endif]--〉
https://www.doczj.com/doc/ef625322.html,er-agent嗅探
是浏览器的一种自我标记方式
https://www.doczj.com/doc/ef625322.html,erAgent
参考资料:
1. 浏览器引擎CSS支持比较
https://www.doczj.com/doc/ef625322.html,/wiki/%E7%80%8F%E8%A6%BD%E5%99%A8%E5%BC%95%E6%93%8EC SS%E6%94%AF%E6%8F%B4%E6%AF%94%E8%BC%83
2. Trident (排版引擎)
https://www.doczj.com/doc/ef625322.html,/wiki/Trident_(%E6%8E%92%E7%89%88%E5%BC%95%E6%93%8E)
3. 前端js开发中的浏览器兼容性.ppt ----kpxu
Linux内核崩溃原因分析及错误跟踪技术 随着嵌入式Linux系统的广泛应用,对系统的可靠性提出了更高的要求,尤其是涉及到生命财产等重要领域,要求系统达到安全完整性等级3级以上[1],故障率(每小时出现危险故障的可能性)为10-7以下,相当于系统的平均故障间隔时间(MTBF)至少要达到1141年以上,因此提高系统可靠性已成为一项艰巨的任务。对某公司在工业领域14 878个控制器系统的应用调查表明,从2004年初到2007年9月底,随着硬软件的不断改进,根据错误报告统计的故障率已降低到2004年的五分之一以下,但查找错误的时间却增加到原来的3倍以上。 这种解决问题所需时间呈上升的趋势固然有软件问题,但缺乏必要的手段以辅助解决问题才是主要的原因。通过对故障的统计跟踪发现,难以解决的软件错误和从发现到解决耗时较长的软件错误都集中在操作系统的核心部分,这其中又有很大比例集中在驱动程序部分[2]。因此,错误跟踪技术被看成是提高系统安全完整性等级的一个重要措施[1],大多数现代操作系统均为发展提供了操作系统内核“崩溃转储”机制,即在软件系统宕机时,将内存内容保存到磁盘[3],或者通过网络发送到故障服务器[3],或者直接启动内核调试器[4]等,以供事后分析改进。 基于Linux操作系统内核的崩溃转储机制近年来有以下几种: (1) LKCD(Linux Kernel Crash Dump)机制[3]; (2) KDUMP(Linux Kernel Dump)机制[4]; (3) KDB机制[5]; (4) KGDB机制[6]。 综合上述几种机制可以发现,这四种机制之间有以下三个共同点: (1) 适用于为运算资源丰富、存储空间充足的应用场合; (2) 发生系统崩溃后恢复时间无严格要求; (3) 主要针对较通用的硬件平台,如X86平台。 在嵌入式应用场合想要直接使用上列机制中的某一种,却遇到以下三个难点无法解决: (1) 存储空间不足 嵌入式系统一般采用Flash作为存储器,而Flash容量有限,且可能远远小于嵌入式系统中的内存容量。因此将全部内存内容保存到Flash不可行。
从输入网址到显示页面:浏览器工作原理拆解分析本文将深入的研究当你输入一个网址的时候,后台到底发生了一件件什么样的事~ 1. 首先嘛,你得在浏览器里输入网址: 2. 浏览器查找域名的IP地址 导航的第一步是通过访问的域名找出其IP地址。DNS查找过程如下: 1.浏览器缓存–浏览器会缓存DNS记录一段时间。有趣的是,操作系统没有告诉 浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。 2.系统缓存–如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调 用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。 3.路由器缓存–接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。 4.ISP DNS 缓存–接下来要check的就是ISP缓存DNS的服务器。在这一般都能 找到相应的缓存记录。 5.递归搜索–你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com 顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.co m域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。 DNS递归查找如下图所示:
DNS有一点令人担忧,这就是像https://www.doczj.com/doc/ef625322.html, 或者https://www.doczj.com/doc/ef625322.html,这样的整个域名看上去只是对应一个单独的IP地址。还好,有几种方法可以消除这个瓶颈:1. 循环DNS 是DNS查找时返回多个IP时的解决方案。举例来说,Faceboo https://www.doczj.com/doc/ef625322.html,实际上就对应了四个IP地址。 2. 负载平衡器是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。 3. 地理DNS 根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。 4. Anycast是一个IP地址映射多个物理主机的路由技术。美中不足,Anycast 与TCP协议适应的不是很好,所以很少应用在那些方案中。 大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。 3. 浏览器给web服务器发送一个HTTP请求 因为像Facebook主页这样的动态页面,打开后在浏览器缓存中很快甚至马上就会过期,毫无疑问他们不能从中读取。 所以,浏览器将把一下请求发送到Facebook所在的服务器: GET https://www.doczj.com/doc/ef625322.html,/ HTTP/1.1 Accept: application/x-ms-application, image/jpeg, application/xaml+x ml, [...] User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Host: https://www.doczj.com/doc/ef625322.html, Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=210 1[...] GET 这个请求定义了要读取的URL:“https://www.doczj.com/doc/ef625322.html,/”。浏览器自身定义(User-Agent头),和它希望接受什么类型的相应(Accept and Accept-Encodin g头). Connection头要求服务器为了后边的请求不要关闭TCP连接。 请求中也包含浏览器存储的该域名的cookies。可能你已经知道,在不同页面请求当中,cookies是与跟踪一个网站状态相匹配的键值。这样cookies会存储登录用户名,服务器分配的密码和一些用户设置等。Cookies会以文本文档形式存储在客户机里,每次请求时发送给服务器。 用来看原始HTTP请求及其相应的工具很多。作者比较喜欢使用fiddler,当然也有像FireBug这样其他的工具。这些软件在网站优化时会帮上很大忙。
浏览器内部工作原理 浏览器可以被认为是使用最广泛的软件,我将介绍浏览器的简单基本的工作原理,我们将看到,从你在地址栏输入https://www.doczj.com/doc/ef625322.html,到你看到facebook主页过程中都发生了什么。
URL解析过程 ? 1. You enter a URL into the browser(输入一个url地址) –https://www.doczj.com/doc/ef625322.html, ? 2.The browser looks up the IP address for the domain name(浏览器查找域名的ip地址) –浏览器缓存 –系统缓存 –路由器缓存 –ISP DNS缓存 –递归搜索
? 3.The browser sends a HTTP request to the web server(浏览器给web服务器发送一个HTTP请求) –GET https://www.doczj.com/doc/ef625322.html,/ HTTP/1.1 –Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...] –User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] –Accept-Encoding: gzip, deflate –Connection: Keep-Alive –Host: https://www.doczj.com/doc/ef625322.html, –Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...] ?Get : 以GET的方式提交发送请求| POST ?https://www.doczj.com/doc/ef625322.html,/ 发送请求的URL地址 ?Http/1.1 HTTP协议 ?User-Agent : 浏览器自身定义 ?Accept-Encoding : 希望接收什么类型相应数据 ?Connection : 表示要求服务器为了后边的请求不要关闭TCP连接 ?请求中也包含浏览器存储的该域名的cookies,cookies会存储登录用户名,服务器分配的密码和一些用户设置等?像“https://www.doczj.com/doc/ef625322.html,/”中的斜杠是至关重要的。这种情况下,浏览器能安全的添加斜杠。而像“http: //https://www.doczj.com/doc/ef625322.html,/folderOrFile”这样的地址,因为浏览器不清楚folderOrFile到底是文件夹还是文件,所以不能自动添加斜杠。这时,浏览器就不加斜杠直接访问地址,服务器会响应一个重定向,结果造成一次不必要的握手
探究linux内核,超详细解析子系统 Perface 前面已经写过一篇《嵌入式linux内核的五个子系统》,概括性比较强,也比较简略,现在对其进行补充说明。 仅留此笔记,待日后查看及补充!Linux内核的子系统 内核是操作系统的核心。Linux内核提供很多基本功能,如虚拟内存、多任务、共享库、需求加载、共享写时拷贝(Copy-On-Write)以及网络功能等。增加各种不同功能导致内核代码不断增加。 Linux内核把不同功能分成不同的子系统的方法,通过一种整体的结构把各种功能集合在一起,提高了工作效率。同时还提供动态加载模块的方式,为动态修改内核功能提供了灵活性。系统调用接口用户程序通过软件中断后,调用系统内核提供的功能,这个在用户空间和内核提供的服务之间的接口称为系统调用。系统调用是Linux内核提供的,用户空间无法直接使用系统调用。在用户进程使用系统调用必须跨越应用程序和内核的界限。Linux内核向用户提供了统一的系统调用接口,但是在不同处理器上系统调用的方法
各不相同。Linux内核提供了大量的系统调用,现在从系统 调用的基本原理出发探究Linux系统调用的方法。这是在一个用户进程中通过GNU C库进行的系统调用示意图,系 统调用通过同一个入口点传入内核。以i386体系结构为例,约定使用EAX寄存器标记系统调用。 当加载了系统C库调用的索引和参数时,就会调用0x80软件中断,它将执行system_call函数,这个函数按照EAX 寄存器内容的标示处理所有的系统调用。经过几个单元测试,会使用EAX寄存器的内容的索引查system_call_table表得到系统调用的入口,然后执行系统调用。从系统调用返回后,最终执行system_exit,并调用resume_userspace函数返回用户空间。 linux内核系统调用的核心是系统多路分解表。最终通过EAX寄存器的系统调用标识和索引值从对应的系统调用表 中查出对应系统调用的入口地址,然后执行系统调用。 linux系统调用并不单层的调用关系,有的系统调用会由
FTP(文件传输协议)服务器工作原理FTP(文件传输协议)工作原理 目前在网络上,如果你想把文件和其他人共享。最方便的办法莫过于将文件放FTP服务器上,然后其他人通过FTP客户端程序来下载所需要的文件。 1、FTP架构 如同其他的很多通讯协议,FTP通讯协议也采用客户机 / 服务器(Client / Server )架构。用户可以通过各种不同的FTP客户端程序,借助FTP协议,来连接FTP服务器,以上传或者下载文件。 2、FTP通讯端口知识 FTP服务器和客户端要进行文件传输,就需要通过端口来进行。FTP协议需要的端口一般包括两种:控制链路--------TCP端口21所有你发往FTP服务器的命令和服务器反馈的指令都是通过服务器上的21 端口传送的。数据链路--------TCP端口20数据链路主要是用来传送数据的,比如客户端上传、下载内容,以及列目录显示的内容等。 3、FTP连接的两种方式在数据链路的建立上,FTP Server 为了适应不同的网络环境,支持两种连接模式:主动模式(Port)和被动模式(Pasv)。其实这两种连接模式主要是针对数据链路进行的,和控制链路无关。 主动模式主动模式是这样工作的:客户端把自己的高位端口和服务器端口21建立控制链路。所有的控制命令比如Is或get都是通过这条链路传送的。当客户端需要服务器端给它传送数据时,客户端会发消息给服务器端,告诉自己的位置和打开的高位端口(一般大于1024的端口都就叫高位端口),等候服务器的20端口和客户端打开的端口进行连接,从而进行数据的传输。当服务器端收到信息后,就会和客户端打开的端口连接,这样数据链路就建立起来了。
本文档的Copyleft归wwwlkk所有,使用GPL发布,可以自由拷贝、转载,转载时请保持文档的完整性,严禁用于任何商业用途。 E-mail: wwwlkk@https://www.doczj.com/doc/ef625322.html, 来源: https://www.doczj.com/doc/ef625322.html,/?business&aid=6&un=wwwlkk#7 linux2.6.35内核IMQ源码实现分析 (1)数据包截留并重新注入协议栈技术 (1) (2)及时处理数据包技术 (2) (3)IMQ设备数据包重新注入协议栈流程 (4) (4)IMQ截留数据包流程 (4) (5)IMQ在软中断中及时将数据包重新注入协议栈 (7) (6)结束语 (9) 前言:IMQ用于入口流量整形和全局的流量控制,IMQ的配置是很简单的,但很少人分析过IMQ的内核实现,网络上也没有IMQ的源码分析文档,为了搞清楚IMQ的性能,稳定性,以及借鉴IMQ的技术,本文分析了IMQ的内核实现机制。 首先揭示IMQ的核心技术: 1.如何从协议栈中截留数据包,并能把数据包重新注入协议栈。 2.如何做到及时的将数据包重新注入协议栈。 实际上linux的标准内核已经解决了以上2个技术难点,第1个技术可以在NF_QUEUE机制中看到,第二个技术可以在发包软中断中看到。下面先介绍这2个技术。 (1)数据包截留并重新注入协议栈技术
(2)及时处理数据包技术 QoS有个技术难点:将数据包入队,然后发送队列中合适的数据包,那么如何做到队列中的数
激活状态的队列是否能保证队列中的数据包被及时的发送吗?接下来看一下,激活状态的队列的 证了数据包会被及时的发送。 这是linux内核发送软中断的机制,IMQ就是利用了这个机制,不同点在于:正常的发送队列是将数据包发送给网卡驱动,而IMQ队列是将数据包发送给okfn函数。
浏览器工作原理拆解分析 1. 首先嘛,你得在浏览器里输入网址: 2. 浏览器查找域名的IP地址 导航的第一步是通过访问的域名找出其IP地址。DNS查找过程如下: 浏览器缓存——浏览器会缓存DNS记录一段时间。有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。 系统缓存——如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows 里是gethostbyname)。这样便可获得系统缓存中的记录。 路由器缓存——接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。 ISP DNS缓存——接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。 递归搜索——你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。 DNS递归查找如下图所示: DNS有一点令人担忧,这就是像https://www.doczj.com/doc/ef625322.html, 或者 https://www.doczj.com/doc/ef625322.html,这样的整个域名看上去只是对应一个单独的IP地址。还好,有几种方法可以消除这个瓶颈: 循环 DNS是DNS查找时返回多个IP时的解决方案。举例来说,https://www.doczj.com/doc/ef625322.html,实际上就对应了四个IP地址。 负载平衡器是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。 地理 DNS 根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。
前端必读:浏览器内部工作原理 目录 一、介绍 二、渲染引擎 三、解析与DOM树构建 四、渲染树构建 五、布局 六、绘制 七、动态变化 八、渲染引擎的线程 九、CSS2可视模型 英文原文:How Browsers Work: Behind the Scenes of Modern Web Browsers 一、介绍 浏览器可以被认为是使用最广泛的软件,本文将介绍浏览器的工作原理,我们将看到,从你在地址栏输入https://www.doczj.com/doc/ef625322.html,到你看到google主页过程中都发生了什么。 将讨论的浏览器 今天,有五种主流浏览器——IE、Firefox、Safari、Chrome及Opera。 本文将基于一些开源浏览器的例子——Firefox、Chrome及Safari,Safari是部分开源的。 根据W3C(World Wide Web Consortium万维网联盟)的浏览器统计数据,当前(2011年5月),Firefox、Safari及Chrome的市场占有率综合已接近60%。(原文为2009年10月,数据没有太大变化)因此,可以说开源浏览器已经占据了浏览器市场的半壁江山。 浏览器的主要功能 浏览器的主要功能是将用户选择的web资源呈现出来,它需要从服务器请求资源,并将其显示在浏览器窗口中,资源的格式通常是HTML,也包括PDF、image及其他格式。用户用URI(Uniform Resource Identifier统一资源标识符)来指定所请求资源的位置,在网络一章有更多讨论。 HTML和CSS规范中规定了浏览器解释html文档的方式,由W3C组织对这些规范进行维护,W3C是负责制定web标准的组织。 HTML规范的最新版本是HTML4(https://www.doczj.com/doc/ef625322.html,/TR/html401/),HTML5还在制定中(译注:两年前),最新的CSS规范版本是2(https://www.doczj.com/doc/ef625322.html,/TR/CSS2),CSS3也还正在制定中(译注:同样两年前)。 这些年来,浏览器厂商纷纷开发自己的扩展,对规范的遵循并不完善,这为web开发者带来了严重的兼容性问题。 但是,浏览器的用户界面则差不多,常见的用户界面元素包括: ?用来输入URI的地址栏 ?前进、后退按钮 ?书签选项 ?用于刷新及暂停当前加载文档的刷新、暂停按钮
看完了路由表,重新回到netif_receive_skb ()函数,在提交给上层协议处理前,会执行下面一句,这就是网桥的相关操作,也是这篇要讲解的容。 view plaincopy to clipboardprint? 1. s kb = handle_bridge(skb, &pt_prev, &ret, orig_dev); 网桥可以简单理解为交换机,以下图为例,一台linux机器可以看作网桥和路由的结合,网桥将物理上的两个局域网LAN1、LAN2当作一个局域网处理,路由连接了两个子网1.0和2.0。从eth0和eth1网卡收到的报文在Bridge模块中会被处理成是由Bridge收到的,因此Bridge也相当于一个虚拟网卡。 STP五种状态 DISABLED BLOCKING LISTENING LEARNING FORWARDING 创建新的网桥br_add_bridge [net\bridge\br_if.c] 当使用SIOCBRADDBR调用ioctl时,会创建新的网桥br_add_bridge。 首先是创建新的网桥: view plaincopy to clipboardprint?
1. d ev = new_bridge_dev(net, name); 然后设置dev->dev.type为br_type,而br_type是个全局变量,只初始化了一个名字变量 view plaincopy to clipboardprint? 1. S ET_NETDEV_DEVTYPE(dev, &br_type); 2. s tatic struct device_type br_type = { 3. .name = "bridge", 4. }; 然后注册新创建的设备dev,网桥就相当一个虚拟网卡设备,注册过的设备用ifconfig 就可查看到: view plaincopy to clipboardprint? 1. r et = register_netdevice(dev); 最后在sysfs文件系统中也创建相应项,便于查看和管理: view plaincopy to clipboardprint? 1. r et = br_sysfs_addbr(dev); 将端口加入网桥br_add_if() [net\bridge\br_if.c] 当使用SIOCBRADDIF调用ioctl时,会向网卡加入新的端口br_add_if。 创建新的net_bridge_port p,会从br->port_list中分配一个未用的port_no,p->br会指向br,p->state设为BR_STATE_DISABLED。这里的p实际代表的就是网卡设备。 view plaincopy to clipboardprint? 1. p = new_nbp(br, dev); 将新创建的p加入CAM表中,CAM表是用来记录mac地址与物理端口的对应关系;而刚刚创建了p,因此也要加入CAM表中,并且该表项应是local的[关系如下图],可以看到,CAM表在实现中作为net_bridge的hash表,以addr作为hash值,链入 net_bridge_fdb_entry,再由它的dst指向net_bridge_port。
WEB浏览器工作原理【来自网络】 2007-04-13 17:15 WWW 的工作基于客户机/服务器计算模型,由Web 浏览器(客户机)和Web服务器(服务 器)构成,两者之间采用超文本传送协议(HTTP)进行通信, HTTP协议的作用原理包括四 个步骤:连接,请求,应答。根据上述HTTP协议的作用原理,本文实现了GET 请求的Web服 务器程序的方法,通过创建 TcpListener类对象,监听端口8080;等待、接受客户机连 接到端口8080;创建与socket字相关联的输入流和输出流;然后,读取客户机的请求信 息,若请求类型是GET,则从请求信息中获取所访问的HTML文件名,如果HTML 文件存在, 则打开HTML文件,把HTTP头信息和 HTML文件内容通过socket传回给Web浏览器,然后关闭 文件。否则发送错误信息给Web浏览器。最后,关闭与相应Web浏览器连接的socket 字。 一、HTTP协议的作用原理 WWW是以Internet作为传输媒介的一个应用系统,WWW网上最基本的传输单位是Web网 页。WWW的工作基于客户机/服务器计算模型,由Web 浏览器(客户机)和Web服务器(服务 器)构成,两者之间采用超文本传送协议(HTTP)进行通信。HTTP协议是基于TCP/IP协议 之上的协议,是Web浏览器和Web服务器之间的应用层协议,是通用的、无状态的、面向对 象的协议。HTTP协议的作用原理包括四个步骤: 连接:Web浏览器与Web服务器建立连接,打开一个称为socket(套接字)的虚拟文 件,此文件的建立标志着连接建立成功。 请求:Web浏览器通过socket向Web服务器提交请求。HTTP的请求一般是GET 或POST命 令(POST用于FORM参数的传递)。GET命令的格式为: GET 路径/文件名 HTTP/1.0 文件名指出所访问的文件,HTTP/1.0指出Web浏览器使用的HTTP版本。 应答:Web浏览器提交请求后,通过HTTP协议传送给Web服务器。Web服务器接
浏览器加载和渲染网页的过程 2009-07-20 20:26 关于网页加载和渲染的过程,在网络上的讨论并不多。可能是因为这个过程比较复杂,而且浏览器执行的速度太快,目前还没有发现什么比较好的工具可以清楚的看到浏览器解析网页的每一个过程。通过firedug和httpWatch可以看到浏览器的http请求,但是对于浏览器如何paint和flow处理html元素,我们仍然是不得而知。“flow”这个词借鉴于reflow,表示浏览器第一次加载网页的过程。在网络上搜索了一下,学习如下。 关于浏览器加载网页过程的有趣视频 可以参见:https://www.doczj.com/doc/ef625322.html,/blog/2008/05/reflow/(形象化的reflow)。这个视频展现了网页加载的过程,看着比较有趣。要是可以更加形象化,就更好了,可以帮助我们书写更好的提高网页加载速度的代码。 浏览器内核 不同的浏览器内核,对于网页的解析过程肯定也不尽相同。 https://www.doczj.com/doc/ef625322.html,/post/Trident-Gecko-WebKit-Presto.php一文对各种浏览器的页面渲染引擎进行了简介。目前主要有基于 (1)Trident页面渲染引擎–> IE系列浏览器; (2)Gecko页面渲染引擎–> Mozilla Firefox; (3)KHTML页面渲染引擎或WebKit框架–> Safafi和Google Chrome; (4)Presto页面渲染引擎–> Opera 详细的介绍可以参见原文。 浏览器解析网页的过程 https://www.doczj.com/doc/ef625322.html,/seosky/blog/item/78d3394c130f86ffd72afc56.html浏览器加载 和渲染原理分析一文中通过一定的方法,推断了浏览器加载解析网页的顺序大致如下: 1. IE下载的顺序是从上到下,渲染的顺序也是从上到下,下载和渲染是同时进行的; 2. 在渲染到页面的某一部分时,其上面的所有部分都已经下载完成(并不是说所有相关联的元素都已经下载完); 3. 在下载过程中,如果遇到某一标签是嵌入文件,并且文件是具有语义解释性的(例如:JS脚本,CSS样式),那么此时IE的下载过程会启用单独连接进行下载,并且在下载后进行解析,解析(JS、CSS中如有重定义,后定义函数将覆盖前定义函数)过程中,停止页面所有往下元素的下载; 4. 样式表文件比较特殊,在其下载完成后,将和以前下载的所有样式表一起进行解析,解析完成后,将对此前所有元素(含以前已经渲染的)重新进行样
总结 第一章java web 工作原理 1.1、web应用程序有web服务器,web客服端浏览器,HTTP协议以及静态HTML文件。 Web服务器的作用是接受客服端请求,然后向客服端返回些结果;浏览器的作用是允许用户请求服务器上的某个资源,并且向用户显示请求的结果; HTML是用于告诉浏览器怎么样向用户显示内容; HTTP是web上客服端和服务器之间通信所用的协议。 1.1.2 HTTP协议将来自于客服端的请求信息封装成HTTP请求; 封装的信息当中包括请求行、请求头、消息体、分隔请求头、消息体的一个空行。 请求行是一个ASCII文本行,由三个标记组成:请求的HTTP方法、请求的URL、HTTP版本;中间用空格分开例如: GET /lovobook/index.html HTTP/1.0 在HTTP1.1版本中请求方法有八种分别是下面: GET:用于向服务器检索资源在HTTP请求头 POST:用于向服务器发送资源,并要求指定的URI处理在消息体HEAD:于GET方法相同,服务器只返回状态行和头标,并不返回请求文档。 PUT:请求服务器保持请求数据作为指定的URI新内容;
DELETE:请求服务器删除URI中命名的资源; OPTIONS:请求关于服务器支持的请求方法信息; TRACE:请求web服务器反馈HTTP请求和其头标;CONNECT:已文档化但当前未实现的一个方法,预留做隧道处理;请求头: HTTP协议使用HTTP头来传递请求的元信息。HTTP头是一个用冒号分隔的名称/值对,冒号前面是HTTP头的名称,后面是HTTP头的值。 1.1.3 HTTP响应包括:状态行、响应头、消息体、分割消息头、响应头。状态行里面出现: 1XX:表示信息,请求收到,继续处理。 2XX:表示成功 3XX:表示重定向 4XX:表示客服端错误 5XX:表示服务器错误 1.2 Web服务器的缺陷是只能向用户提供静态网页内容。 1.3 服务器端网页编程就是web服务器创建动态服务器端内容的过程。 1.3.1 服务器端网页编程出现得最早的技术就是CGI,它的缺点就是每次请求一个CGI资源,将在服务器上创建一个新的进程,并且通过标准输
基于Linux内核编程的实验报告(Linux内核分析实验 报告) 以下是为大家整理的基于Linux内核编程的实验报告(Linux内核分析实验报告)的相关范文,本文关键词为基于,Linux,内核,编程,实验,报告,分析,,您可以从右上方搜索框检索更多相关文章,如果您觉得有用,请继续关注我们并推荐给您的好友,您可以在教育文库中查看更多范文。 Linux内核分析实验报告
实验题目:文件系统实验 实验目的:linux文件系统使用虚拟文件系统VFs作为内核文件子系统。可以安装多种 不同形式的文件系统在其中共存并协同工作。VFs对用户提供了统一的文件访问接口。本实验的要求是 (1)编写一个get_FAT_boot函数,通过系统调用或动态模块调用它可以提 取和显示出FAT文件系统盘的引导扇区信息。这些信息的格式定义在内核文件的fat_boot_sector结构体中。函数可通过系统调用或动态模块调用。 (2)编写一个get_FAT_dir函数,通过系统调用或动态模块调用它可以 返回FAT文件系统的当 前目录表,从中找出和统计空闲的目录项(文件名以0x00打头的为从未使用过目录项,以0xe5打头的为已删除的目录项),将这些空闲的目录项集中调整到目录表的前部。这些信息的格式定义在内核文件的msdos_dir_entry结构体中。 硬件环境:内存1g以上 软件环境:Linux(ubuntu)2-6实验步骤: 一:实验原理: 以实验4为蓝本,在优盘中编译并加载模块,启动测试程序,查
/proc/mydir/myfile的文件内容。从优盘得到fat文件系统的内容存在msdos_sb_info结构中,然后得到msdos_sb_info结构相应的属性值,得到实验一的数据。实验二中,得到fat文件系统第一个扇区的十六个文件信息。然后按照文件名头文字的比较方法,应用归并排序的方法,将头文件是0x00和0xe5的文件调到前面,其他的文件调到后面 二:主要数据结构说明: (1)超级块对象: 数据结构说明:一个已经安装的文件系统的安装点由超级块对象代表。 structsuper_block{... conststructsuper_operations*s_op;} (2)索引i节点对象 数据结构说明:索引i节点对象包含了内核要操作的文件的全部控制信息,对应着打开文件的i节点表。structinode{ conststructinode_operations*i_op;...} (3)目录项对象 数据结构说明:录项对象代表了文件路径名的各个部分,目录文件名和普 通文件名都属于目录项对象。structdentry{
Web服务器工作原理概述 很多时候我们都想知道,web容器或web服务器(比如Tomcat或者jboss)是怎样工作的?它们是怎样处理来自全世界的http请求的?它们在幕后做了什么动作?Java Servlet API(例如ServletContext,ServletRequest,ServletResponse和Session这些类)在其中扮演了什么角色?这些都是web应用开发者或者想成为web应用开发者的人必须要知道的重要问题或概念。在这篇文章里,我将会尽量给出以上某些问题的答案。 请集中精神! 文章章节: ?什么是web服务器、应用服务器和web容器? ?什么是Servlet?他们有什么作用? ?什么是ServletContext?它由谁创建? ?ServletRequest和ServletResponse从哪里进入生命周期? ?如何管理Session?知道cookie吗? ?如何确保线程安全? 什么是web服务器,应用服务器和web容器? 我先讨论web服务器和应用服务器。让我在用一句话大概讲讲: “在过去它们是有区别的,但是这两个不同的分类慢慢地合并了,而如今在大多在情况下和使用中可以把它们看成一个整体。” 在Mosaic浏览器(通常被认为是第一个图形化的web浏览器)和超链接内容的初期,演变出了“web服务器”的新概念,它通过HTTP协议来提供静态页面内容和图片服务。在
那个时候,大多数内容都是静态的,并且HTTP 1.0只是一种传送文件的方式。但在不久后web服务器提供了CGI功能。这意味着我们可以为每个web请求启动一个进程来产生动态内容。现在,HTTP协议已经很成熟了并且web服务器变得更加复杂,拥有了像缓存、安全和session管理这些附加功能。随着技术的进一步成熟,我们从Kiva和NetDynamics学会了公司专属的基于Java的服务器端技术。这些技术最终全都融入到我们今天依然在大多数应用开发里使用的JSP中。 以上是关于web服务器的。现在我们来讨论应用服务器。 在同一时期,应用服务器已经存在并发展很长一段时间了。一些公司为Unix开发了Tuxedo(面向事务的中间件)、TopEnd、Encina等产品,这些产品都是从类似IMS和CICS的主机应用管理和监控环境衍生而来的。大部分的这些产品都指定了“封闭的”产品专用通信协议来互连胖客户机(“fat”client)和服务器。在90年代,这些传统的应用服
长沙理工大学 《网络系统》课程设计报告 学院城南学院专业计算机科学与技术班级计算机1101 学号201186250222 学生姓名高扬指导教师周书仁 课程成绩完成日期2013年6月28日
课程设计成绩评定 学院城南学院专业计算机科学与技术班级计算机1101 学号201186250222 学生姓名高扬指导教师周书仁完成日期2013年6月28日 指导教师对学生在课程设计中的评价 指导教师对课程设计的评定意见
课程设计任务书 城南学院学院计算机科学与技术专业
浏览器的设计与实现 学生姓名:高扬指导老师:周书仁 摘要论文主要介绍了本课题的开发背景,所要完成的功能和开发的过程。重点说明了系统设计重点、设计思想、难点技术和解决方案;同时也论述了基于HTTP协议的Web浏览器的开发思路、开发过程、利用的主要技术及本浏览器应用程序的功能模块的说明。本课题是在深入理解HTTP协议的工作机理,系统掌握了TCP/UDP网络通信协议及网络编程的基本方法,掌握了使用Windows Sockets API和MFC Socket编程技术之后,采用Visual C++作为开发工具来设计并实现一个Web浏览器,其功能主要包括:浏览器的界面实现;实现收藏菜单;显示超文本;删除相关历史记录;将应用程序加入到时工具栏、禁止弹出窗口、禁止浏览某些网站访问Web页,保存网页,打印网页,停止当前访问,刷新网页,查看源文件和Internet属性等等。 关键词:Visual C++;MFC;HTTP协议;浏览器 目录 第1章绪论 1.1 软件开发背景 随着社会的发展和需求,在20世纪中叶人类研制了电子计算机。电子计算机运算速度快,计算精度高,存储能力强,具有逻辑判断能力,具有自动运行能力等特点。进过半个多世纪的飞速发展,电子计算在许多领域得到了广泛的应用,已成为衡量一个国家现代化水平的重要标志。而
很久以前分析的,一直在电脑的一个角落,今天发现贴出来和大家分享下。由于是word直接粘过来的有点乱,敬请谅解! S3C2410 Linux 2.6.35.7启动分析(第一阶段) arm linux 内核生成过程 1. 依据arch/arm/kernel/vmlinux.lds 生成linux内核源码根目录下的vmlinux,这个vmlinux属于未压缩, 带调试信息、符号表的最初的内核,大小约23MB; 命令:arm-linux-gnu-ld -o vmlinux -T arch/arm/kernel/vmlinux.lds arch/arm/kernel/head.o init/built-in.o --start-group arch/arm/mach-s3c2410/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o drivers/built-in.o net/built-in.o --end-group .tmp_kallsyms2.o 2. 将上面的vmlinux去除调试信息、注释、符号表等内容,生成arch/arm/boot/Image,这是不带多余信息的linux内核,Image的大小约 3.2MB; 命令:arm-linux-gnu-objcopy -O binary -S vmlinux arch/arm/boot/Image 3.将 arch/arm/boot/Image 用gzip -9 压缩生成arch/arm/boot/compressed/piggy.gz大小约 1.5MB;命令:gzip -f -9 < arch/arm/boot/compressed/../Image > arch/arm/boot/compressed/piggy.gz 4. 编译arch/arm/boot/compressed/piggy.S 生成arch/arm/boot/compressed/piggy.o大小约1.5MB,这里实 际上是将piggy.gz通过piggy.S编译进piggy.o文件中。而piggy.S文件仅有6行,只是包含了文件piggy.gz; 命令:arm-linux-gnu-gcc -o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/piggy.S 5. 依据arch/arm/boot/compressed/vmlinux.lds 将arch/arm/boot/compressed/目录下的文件head.o 、piggy.o 、misc.o链接生成arch/arm/boot/compressed/vmlinux,这个vmlinux是经过压缩且含有自解压代码的内核, 大小约1.5MB; 命 令:arm-linux-gnu-ld zreladdr=0x30008000 params_phys=0x30000100 -T arch/arm/boot/compressed/vmlinux.lds a rch/arm/boot/compressed/head.o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/misc.o -o arch/arm /boot/compressed/vmlinux
浏览器(browser) 定义: 万维网(Web)服务的客户端浏览程序。 可向万维网(Web)服务器发送各种请求,并对从服务器发来的超文本信息和各种多媒体数据格式进行解释、显示和播放。 浏览器工作原理 WWW 的工作基于客户机/服务器计算模型,由Web 浏览器(客户机)和Web服务器(服务器)构成,两者之间采用超文本传送协议(HTTP)进行通信,HTTP协议的作用原理包括四个步骤:连接,请求,应答。根据上述HTTP协议的作用原理,本文实现了GET请求的Web服务器程序的方法,通过创建TcpListener 类对象,监听端口8080;等待、接受客户机连接到端口8080;创建与socket字相关联的输入流和输出流;然后,读取客户机的请求信息,若请求类型是GET,则从请求信息中获取所访问的HTML文件名,如果HTML文件存在,则打开HTML文件,把HTTP头信息和HTML文件内容通过socket传回给Web浏览器,然后关闭文件。否则发送错误信息给Web浏览器。最后,关闭与相应Web浏览器连接的socket 字。 HTTP协议的作用原理 WWW是以Internet作为传输媒介的一个应用系统,WWW网上最基本的传输单位是Web网页。WWW 的工作基于客户机/服务器计算模型,由Web 浏览器(客户机)和Web服务器(服务器)构成,两者之间采用超文本传送协议(HTTP)进行通信。HTTP协议是基于TCP/IP协议之上的协议,是Web浏览器和Web 服务器之间的应用层协议,是通用的、无状态的、面向对象的协议。HTTP协议的作用原理包括四个步骤:连接:Web浏览器与Web服务器建立连接,打开一个称为socket(套接字)的虚拟文件,此文件的建立标志着连接建立成功。 请求:Web浏览器通过socket向Web服务器提交请求。HTTP的请求一般是GET或POST命令(POST 用于FORM参数的传递)。GET命令的格式为: GET 路径/文件名HTTP/1.0 文件名指出所访问的文件,HTTP/1.0指出Web浏览器使用的HTTP版本。 应答:Web浏览器提交请求后,通过HTTP协议传送给Web服务器。Web服务器接到后,进行事务处理,处理结果又通过HTTP传回给Web浏览器,从而在Web浏览器上显示出所请求的页面。 例:假设客户机与https://www.doczj.com/doc/ef625322.html,:8080/mydir/index.html建立了连接,就会发送GET命令:GET /mydir/index.html HTTP/1.0。主机名为https://www.doczj.com/doc/ef625322.html,的Web服务器从它的文档空间中搜索子目录mydir的文件index.html。如果找到该文件,Web服务器把该文件内容传送给相应的Web浏览器。 为了告知Web浏览器传送内容的类型,Web服务器首先传送一些HTTP头信息,然后传送具体内容(即HTTP体信息),HTTP头信息和HTTP体信息之间用一个空行分开。 常用的HTTP头信息有: ①HTTP 1.0 200 OK 这是Web服务器应答的第一行,列出服务器正在运行的HTTP版本号和应答代码。代码 “200 OK”表示请求完成。 ②MIME_V ersion:1.0
详解内核驱动操作GPIO引脚API函数 函数原型: void s3c2410_gpio_cfgpin(unsigned int pin, unsigned int function); unsigned int s3c2410_gpio_getcfg(unsigned int pin); void s3c2410_gpio_pullup(unsigned int pin, unsigned int to); void s3c2410_gpio_setpin(unsigned int pin, unsigned int to); unsigned int s3c2410_gpio_getpin(unsigned int pin); unsigned int s3c2410_modify_misccr(unsigned int clear, unsigned int change); int s3c2410_gpio_getirq(unsigned int pin); 关于函数中用到的虚拟地址到物理地址转换的变量及算法可以参考 https://www.doczj.com/doc/ef625322.html,/hefeng330467115@126/blog/static/78205842201 0620511659/ 或https://www.doczj.com/doc/ef625322.html,/u3/102836/showart_2065945.html 看简单led驱动程序是用到的文件及头文件可能有: linux/include/asm-arm/arch-s3c2410/map.h linux/include/asm-arm/arch-s3c2410/regs-gpio.h linux/arch/arm/plat-s3c24xx/gpio.c linux/include/asm-arm/io.h 用Source Insight 打开这些文件,然后再看驱动程序,可以随意跳转到定义处,很是方便 pin参数: gpio引脚及特殊功能寄存器助记符都在 linux/include/asm-arm/arch-s3c2410/regs-gpio.h中定义: eg: S3C2410_GPACON S3C2410_GPADAT S3C2410_GPA0 - S3C2410_GPA22 //引脚 S3C2410_GPA0_OUT - S3C2410_GPA22_OUT //设置引脚为输出 用到哪个不清楚的可以直接到这个文件去查找 还有中断和GSTATUS: S3C2410_EXTINT0 -> irq sense control for EINT0..EINT7 S3C2410_EXTINT1 -> irq sense control for EINT8..EINT15 S3C2410_EXTINT2 -> irq sense control for EINT16..EINT23 …… function参数: 指定引脚功能:输出、输入还是特殊功能,也在 linux/include/asm-arm/arch-s3c2410/regs-gpio.h中定义。 函数功能: 1原型:void s3c2410_gpio_cfgpin(unsigned int pin, unsigned int