
国外结算模型体系的主流方法比较
焦燕冬
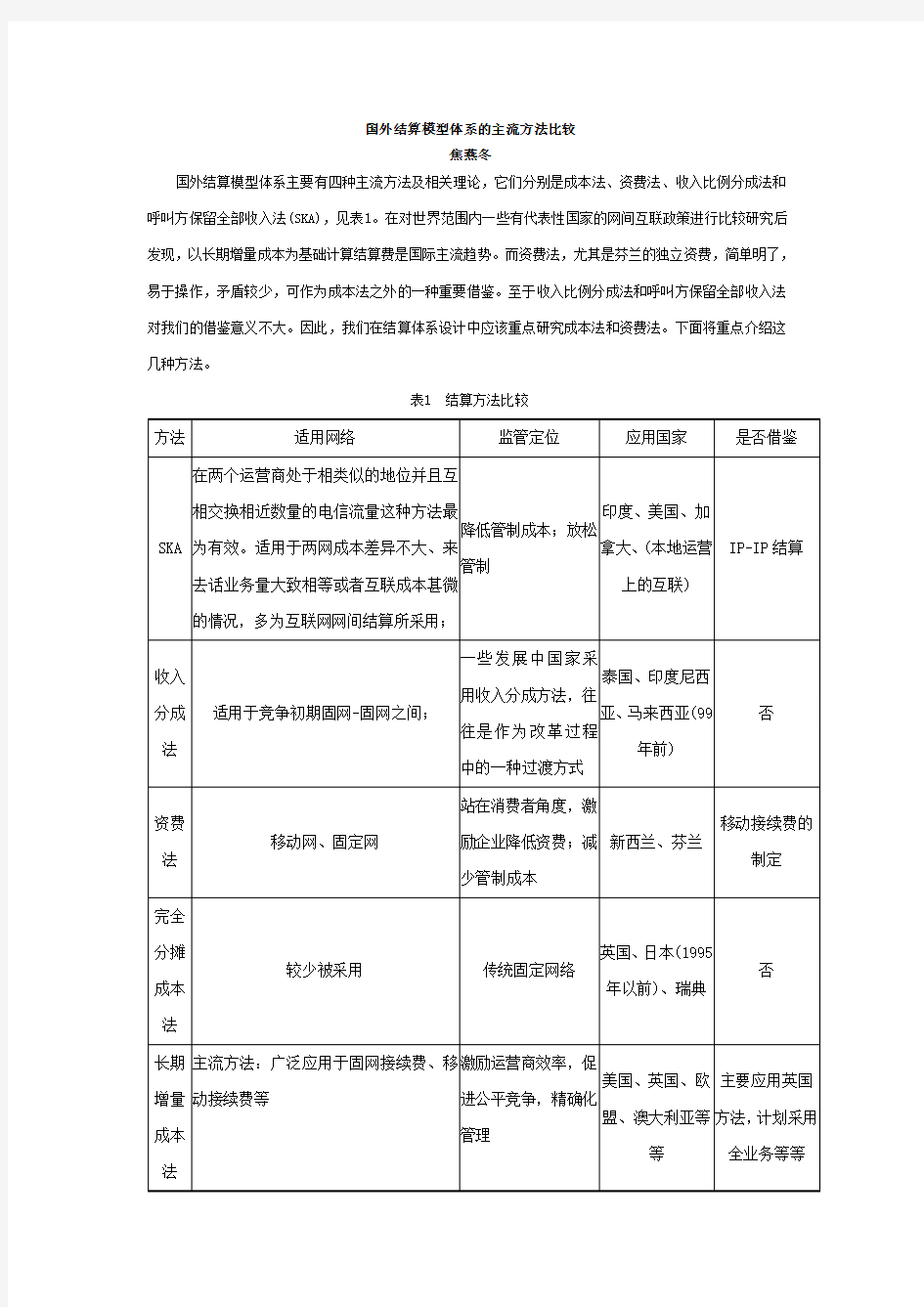
国外结算模型体系主要有四种主流方法及相关理论,它们分别是成本法、资费法、收入比例分成法和呼叫方保留全部收入法(SKA),见表1。在对世界范围内一些有代表性国家的网间互联政策进行比较研究后发现,以长期增量成本为基础计算结算费是国际主流趋势。而资费法,尤其是芬兰的独立资费,简单明了,易于操作,矛盾较少,可作为成本法之外的一种重要借鉴。至于收入比例分成法和呼叫方保留全部收入法对我们的借鉴意义不大。因此,我们在结算体系设计中应该重点研究成本法和资费法。下面将重点介绍这几种方法。
表1 结算方法比较
方法适用网络监管定位应用国家是否借鉴
SKA 在两个运营商处于相类似的地位并且互
相交换相近数量的电信流量这种方法最
为有效。适用于两网成本差异不大、来
去话业务量大致相等或者互联成本甚微
的情况,多为互联网网间结算所采用;
降低管制成本;放松
管制
印度、美国、加
拿大、(本地运营
上的互联)
IP-IP结算
收入
分成法适用于竞争初期固网-固网之间;
一些发展中国家采
用收入分成方法,往
往是作为改革过程
中的一种过渡方式
泰国、印度尼西
亚、马来西亚(99
年前)
否
资费
法移动网、固定网
站在消费者角度,激
励企业降低资费;减
少管制成本
新西兰、芬兰
移动接续费的
制定
完全分摊
成本法较少被采用传统固定网络
英国、日本(1995
年以前)、瑞典
否
长期增量成本法主流方法:广泛应用于固网接续费、移
动接续费等
激励运营商效率,促
进公平竞争,精确化
管理
美国、英国、欧
盟、澳大利亚等
等
主要应用英国
方法,计划采用
全业务等等
一、SKA
SKA是指呼叫方保留全部收入,在互联的运营商间提供终接业务不收取任何费用的方法。当两个运营商处于相类似的地位并且互相交换相近数量的电信流量时,这种方法最有效。它的缺点包括:(1)当流量存在不平衡而又不收费的情况下,该方法将阻碍运营商对农村或其他业务的融资和发展;(2)不利于公平竞争,甚至会造成各运营商对来话进行限制;
在许多市场上,这种方法曾经是互联网接入业务商之间实现互联的主要模式。然而情况正在转变,一些较大的互联网接入业务商开始有了大规模的骨干网设施和覆盖范围,他们开始不将较小的互联网接入商当作伙伴,而是要为其提供的介入服务对他们进行收费。
二、收入分成法
收入分成法要求收费的一方按一定的比例把收入分摊给提供了接续服务而没收到费用的运营商,这个分成比例由运营商之间协商达成。
该方法的优点为:比较简单,不需要通过成本分析来决定网间互联费用。缺点为:(1)不透明;(2)分成比例不好确定,影响网间接续的时效性;(3)收入分成把各运营商的收入捆绑在一起,使它们缺乏应对市场竞争的灵活性;
有时,在较为封闭的市场,政府管制部门将这种方法规定为实现网间互联的唯一方法;而收取的费用是作为在一个国家开展业务需要提交的税收,在向更有效的方法过渡的过程中可以采用收入分成法作为中间步骤。
三、资费法
资费法是以现行的零售资费为基础来确定互联费的方法。其优点包括:(1)简便易行,便于操作,避免了大量成本核算的复杂程序;(2)以现有零售资费为基础,可以在互联双方之间迅速达成互联协议,实现网间互联互通。
缺点包括:(1)市话资费中往往存在着扭曲,因此,互联费与市话资费并不存在必然的相关关系;(2)不符合“成本导向”的原则。零售资费有可能是偏离成本制定的,而如果依据偏离成本的零售资费制定互联费的话,可能导致公司之间利益分配的扭曲;(3)不符合“消除交叉补贴”的原则。为互联网提供通信服务的网络资源有别于运营商其他业务的网络资源,与互联网服务相关的成本才能计入互联成本中,禁止业务之间进行交叉补贴,而各国的市话资费中很多都存在交叉补贴。因此,根据业务资费得出的互联费是不科学的;(4)将资费作为制定互联费的基础,将使新运营商不可避免地依赖于垄断经营者的资费水平和资费结构,一方面,不能给新进入者提供正确的成本信号,另一方面,也有损于新运营商的利益。
资费法根据具体的使用形式不同,又分为三种:国际资费比较法、独立资费法和最低资费法。
1.国际资费比较法
国际资费比较方法(Benchmarking)是通过对本国与国际上其它国家的互联费进行比较来修正本国互联费或制订新的互联费的方法。对于有些国家,尚未确定互联费的计算方法或已确定了方法但有关数据资料的收集尚需大量的工作,这时可以采取国际比较的方法。
该方法主要应用于欧洲委员会EC、英国的咨询机构OVUM等。欧洲委员会EC定期比较各成员国当前主导运营商实施中的互联费,并从中选择互联费最低的三个国家的平均水平作为最佳实践互联费(best current practice,考虑到各个成员国实际成本等经济因素差别,EC以区间形式来表示这个平均水平)作为对其成员国下一个时期互联费的建议(参考)值。这个建议值主要是针对那些没有形成固定方法来计算互联费的成员国而提出的。
2.独立资费法
采用独立资费法的代表国家是芬兰。在芬兰,对于市话网间的互联,由主叫方用户的电话公司向被叫方用户公司结算50%的通话费作为互联费;对于长途网与市话网间的互联,当市话网用户拨打长途电话时,市话公司按照用户所选长话公司的通话费标准和本地通话费标准向用户收费,其中,长途话费由发端市话公司留5%手续费后划给长话公司,市话通话费由发端市话公司和收端市话公司各得50%;对于移动网与固定网间的互联,当移动网通过固定网完成呼叫接续时,由移动网付给固定网固定电话费的90%,当固定网通过移动网完成呼叫接续时,固定网付给移动网移动话费的50%。
3.最低资费法
由于欧盟成本会计系统的不成熟,导致他们无法贯彻执行长期增量成本为基础的定价原则。为了解决网间互联接续费的问题,欧盟委员会最近决定以全欧洲最低的资费作为网间接续费用标准,而不去考虑提供服务的潜在成本。可是全欧洲最低的资费经常会变化,从而会导致欧盟的网间接续费标准不稳定,并不利于欧洲统一政策的施行。从欧盟的折衷做法也可以反映,管制机构要去核算企业成本是一件非常艰难、甚至是不可能的事情。
四、成本法
成本法是基于对网间互联通话的单位互联接入成本(包括传输成本、交换成本和用户线成本及共同成本的分摊等)的计算来制定互联费。用成本法设定互联费时,最常用的是完全分摊成本定价法(FDC)和长期增量成本(LRIC)定价法。
1.长期增量成本
今天大多数监管机构和电信专家普遍接受的计算网间互联费的最佳方法是以提供相关设施和业务的预期成本为基础,基于当前先进的技术条件,对网间互联的长期成本进行估算。这就是所谓的前瞻性的“长期增量成本(LRIC,Long Run Incremental Cost)”的概念,近年来,这种确定互联费的方式越来越受到人们的青睐。
增量成本,是指产量的增加或减少而引起的总成本的变化。对于网间互联而言,增量成本是指主导运营商因提供互联而增加的成本。长期增量成本包括短期内变动的经营成本和短期内不发生变化的成本,虽然这些成本短期内是不变化的,但从长期而言却是必要的固定投资。在竞争的市场中,产品的价格最终将趋于长期增量成本。LRIC基于现有重置成本记帐法,改变了用历史成本的计算方法,即采用目前最高效的技术构造一个与现有网络功能相同的网络模型,然后对这个网络模型的成本等因素进行计算和评价来得到网间互联的成本模型。
根据长期增量成本法,新进入的运营商仅需向主导运营商支付由于他的进入使网络上增加的电信流量而产生的额外成本。因此,新进入的运营商仅需向主导运营商支付本地交换的部分可变成本。支付比例的确定可以依据市场份额或其他标准,例如,比例的确定可以根据新进入运营商使用主导运营商网络的路由时间。
归结起来,LRIC法的主要优点有:(1)根据当前最有效率的成本标准而不是企业的历史成本确定互联费,对主导运营商以前的投资和过时的技术所形成的成本不进行补偿,因此有利于形成较低的互联费用,降低新进入者的成本;(2)以当前最有效的方式组织运营,激励主导电信公司降低成本;(3)新进入者不必被迫支付过期成本和额外成本,有利于促进竞争。
但是,LRIC法也存在一些缺陷:(1)LRIC法涉及基于网络重置价值的预期成本计算,需要准确的数据信息支持,而这些数据获取的难度较大。例如,在没有达成最终的购买合同时,难以从设备商那里得到真实的售价,因此,难以确定现实重置成本。此外,LRIC要考虑技术进步的影响,必须对未来技术进步率进行估计,这同样难以把握。LRIC的计算受人为因素影响较大,难以保证相关成本数据的客观性;(3)采用LRIC方法制定网间互联费时,如果采用的方法不当,会对在位运营商的共同成本和共享成本补偿不足,会使在位运营商无法回收网络投资,影响到在位运营商投资建设网络的积极性;(4)由于LRIC法使在位运营商不能通过提供互联服务而赢利,所以在位运营商会设法偏向自己的附属企业,从而对新进入者造成伤害,影响竞争的有效性。(5)采用LRIC法确定互联费需要更多的管制资源,而且也为利益集团提供了活动空间,使他们有很强的动机去影响管制机构的互联政策,这一结果与逐步减轻管制力度的总体思路是不一致的。
实际中,在对长期增量成本法进行调整的基础上,最为各国监管机构和专家广泛接受的方法包括以下几种:
(1)长期平均增量成本法:这种方法将增量定义为全部业务。这种方法不同于传统的边际和增量成本法,它包括了对于特定相关业务固定成本的补贴。这种方法为欧洲委员会采用;目前香港也是采用的这种方法。
(2)全业务长期增量成本法:这种方法考察提供一种业务和不提供一种业务之间的成本差值。全业务长期增量成本法是将整个业务作为增量的长期增量成本法。因此,需要通过设定增加值来弥补一部分长期增量成本没有包括的成本。长期增量成本法没有包括特定业务的固定成本,因此,本地交换业务的固定成本
完全由主导运营商来承担了。我们一般将把本地交换业务的全部成本作为增量来考虑。澳大利亚就采用了该方法。
(3)全要素长期增量成本法:这种方法从长远考虑,增加或减少一个特定的网络元素加上分摊部分的共同成本而产生的增量成本。它首先由美国联邦通信委员会(FCC)采用。
(4)全业务长期增量成本+统一增加值的方法:采用全业务长期增量成本法没有包括对主导运营商共同成本的分摊。总体上,大多数管制机构认为网间互联费用应该包括一部分共同成本的分摊。通常的做法是对全业务长期增量成本补充一个增加值。如果网间互联费用中不包括一个增加值来弥补主导运营商的共同成本和连带成本,那么这些成本就不得不从主导运营商的用户身上收取,大多数的管制机构和电信专家认为这是不公平的。因此,需要对全业务长期增量成本补充一个增加值。加拿大就采用这种方法,加成比例为25%。
(5)英国的Top-Down模型和Bottom-Up模型:英国的“互联及核算任务指导工作组”组织开发了两类模型,一类是由BT开发的Top-Down模型,它以一种高度分布而表述清晰的方式来审查成本,而且完全说明并反映了在将成本与网络元素相关联时经常发生的复杂的内部联系;另一类是由增量工作组提出的Bottom-Up模型,其主要优点在于它的透明性和相对简单的结构。该方法能让运营商们明白网络成本产生的过程。
2.完全成本分摊法(也称为“历史成本”)
完全成本分摊法(FDC,Fully Distributed Cost)是根据运营商的历史会计记录,将提供接入方的总成本(不变成本和可变成本,直接成本和公共成本)全部分摊到每个话务量上,以此作为互联费率,即互联费率=总成本/总话务量。所有的成本都可以分为两部分:与业务有关的直接成本和共同成本。直接成本可以直接分配给相关业务,共同成本则可以通过业务量、收入或边际利润等因素分摊到各种业务中。
它的优点为:(1)成本分摊考虑了所有的成本因素,可以使公司的所有成本都得到补偿;(2)容易获得数据,具有很强的可操作性,简单实用;(3)基于帐面记录的成本数据,对互联双方和监管机构均是透明的;
(4)鼓励运营商投资改造自己的网络。其缺点为:(1)通过帐面数据很难清楚划分属于各业务或模块的直接成本和共同成本;(2)主观随意性大,将共同成本分摊给各业务或模块时,采用ROM、GRM、ACM三种分摊方法的分摊结果差别很大;(3)FDC方法利用的是帐面上记录的成本数据,是历史成本,在制定网间互联费用的时候,可能会把公司历史上一些低效率的投资转嫁给互联单位,使他们承担比较高的互联费用,从而不利于有效竞争;(4)多年积累的资产难以估价准确,折旧为零的资产仍可能在继续使用;(5)成本反映的是过去的投资情况、技术水平和管理水平,而非当前最优。
由于以上优点,使FDC方法有广泛的应用。英国、日本都曾采用FDC法确定网间互联费,但也是由于它的不足,目前英国、日本都已经放弃了这种方式。现在仍采取这种定价方式的国家包括韩国、法国以及
挪威等国家。
综上所述,各种互联定价方法均是有利有弊,充分体现了网间互联费问题的复杂性和争议性。从本文的分析来看,目前,世界上绝大多数国家、地区和组织网间结算的指导原则都是成本原则,因此,以成本为基础的互联费定价和网间结算是全球发展的主流趋势。但是,鉴于成本法实施的复杂性和困难性,资费法作为一种简便易行的方法,仍旧应用于其他国家和业务中。
运维概况 2013年9月26日 13:46 https://www.doczj.com/doc/2c15647962.html,神州泰岳北京 010-******** https://www.doczj.com/doc/2c15647962.html,/北塔软件上海 4008207719 https://www.doczj.com/doc/2c15647962.html,广通信达北京 4008106677 https://www.doczj.com/doc/2c15647962.html,东华软件北京 010—62662288 IT运维管理应该包括以下几个子系统: 第一、设备管理:对网络设备、服务器设备、操作系统运行状况进行监控,对各种应用支持软件如数据库、中间件、群件以及各种通用或特定服务的监控管理,如邮件系统、DNS、Web等的监控与管理; 第二、数据/存储/容灾管理:对系统和业务数据进行统一存储、备份和恢复; 第三、业务管理:包含对企业自身核心业务系统运行情况的监控与管理,对于业务的管理,主要关注该业务系统的CSF(关键成功因素Critical Success Factors)和KPI(关键绩效指标Key Performance Indicators); 第四、目录/内容管理:该部分主要对于企业需要统一发布或因人定制的内容管理和对公共信息的管理; 第五、资源资产管理:管理企业中各IT系统的资源资产情况,这些资源资产可以是物理存在的,也可以是逻辑存在的,并能够与企业的财务部门进行数据交互; 第六、信息安全管理:该部分包含了许多方面的内容,目前信息安全管理主要依据的国际标准是ISO17799,该标准涵盖了信息安全管理的十大控制方面,36个控制目标和127中控制方式,如企业安全组织方式、资产分类与控制、人员安全、物理与环境安全、通信与运营安全、访问控制、业务连续性管理等; 第七、日常工作管理:该部分主要用于规范和明确运维人员的岗位职责和工作安排、提供绩效考核量化依据、提供解决经验与知识的积累与共享手段IT运行维护管理的每一个子系统中都包含着十分丰富的内容,实现完善的IT运维管理是企业提高经营水平和服务水平的关键。 核心提示:在IT运维管理软件市场,国内一些本土软件厂商正在逐渐兴起,以神州泰岳、广通信达等厂商为代表,走出了一条中国式的IT运维管理的发展之路。 通过直销模式,本土厂商在银行、制造、政府、能源和教育行业都树立了很多IT运维管理的典型用户。与此同时,在中低端产品方面,本土厂商则充分利用了渠道分销模式,积累了大量的中小企业客户。 2003年,商务部对ITIL(信息技术基础架构库)的实践开启了ITIL在中国的应用大门。由于是舶来品,最初能提供IT运维服务的大都是一些国外公司,比如IBM、HP。后来,ITIL部署为电信运营商带来的效益让更多企业看到了运维管理的好处,ITIL一时名声大噪,吸引更多提供服务管理的公司进入该领域。 不仅如此,随着国内信息化建设的不断升级,很多用户的信息系统变得庞大而复杂,重复出现的IT问题让信息中心的工作人员疲于奔命,对于IT管理的需求变得迫切起来。 用户认知趋于明确
1. Cmk和Cpk等名词解释 Cmk是德国汽车行业常采用的参数,是“Machine Capability Index” 的缩写,称为临界机器能力指数,它仅考虑设备本身的影响,同时考虑分布的平均值与规范中心值的偏移;由于仅考虑设备本身的影响,因此在采样时对其他因素要严加控制,尽量避免其他因素的干扰,计算公式与Ppk相同,只是取样不同。 CP(或Cpk)工序能力指数,是指工序在一定时间里,处于控制状态(稳定状态)下的实际加工能力。它是工序固有的能力,或者说它是工序保证质量的能力。 这里所指的工序,是指操作者、机器、原材料、工艺方法和生产环境等五个基本质量因素综合作用的过程,也就是产品质量的生产过程。产品质量就是工序中的各个质量因素所起作用的综合表现CPK:强调的是过程固有变差和实际固有的能力; CMK:考虑短期离散,强调设备本身因素对质量的影响; CPK:分析前提是数据服从正态分布,且过程受控;(基于该前提,CPK一定>0) CMK:用于新机验收时、新产品试制时、设备大修后等情况; CPK:至少1.33 CMK:至少1.67 CMK一般在机器生产稳定后约一小时内抽样10组50样本 CPK在过程稳定受控情况下适当频率抽25组至少100个样本
2.对Cmk和Cmk指标参数的分析 对Cmk,我们关心的是机器设备本身的能力,在取样过程中要尽量消除其他因素的影响,因此,在尽量短的时间内(减少环境影响),相同的操作者(减少人的因素影响),采用标准的作业方法(法),针对相同的加工材料(同一批原材料),只考核机器设备本身的变差。 在计算方法上,取样数目可以按照实际情况(客户要求,公司规定,采样成本等综合考虑),但原则上应该大于30个,这是因为取样的子样空间实际上不是正态分布而是t分布,当样本数大于30时,才接 近正态分布。而我们所采用的公式是以正态分布为基础的。 设备能力指数Cmk表示仅由设备普通原因变差决定的能力,与Cpk Ppk不同在于取样方法不同,是在机器稳定工作时至少连续50件的数据,Cmk=T/6sigma,sigma即可用至少连续50件的数据s估计,又可用至少连续50件的数据分组后的Rbar/d2来估计,由于根据美国工业界的经验,过程变差的75%来自设备变差,如果用至少连续50件的数 据s估计的sigma或用至少连续50件的数据分组后的Rbar/d2估计 的sigma来计祘Cpk的话,人机料法环总普通原因变差为8sigma, Cpk=T/8sigma,(为方便,上面公式都是分布中心和公差中重合时) 机器能力:“机器能力”由公差与生产设备的加工离散之比得出。通常采用数理统计的方法进行测量和证明,此时只考虑短期的离散,尽可能地排除对过程有影响而非机器的因素。(比较VDA第4卷的第 1部分)
人力资源管理师三级(三版)计算题汇总 历年考点:定员,劳动成本,人工成本核算,招聘与配置,新知识:劳动定额的计算 一、劳动定额完成程度指标的计算方法 1.按产量定额计算产量定额完成程度指标=(单位时间内实际完成的合格产品产量/产量定额)×100% 2.按工时定额计算工时定额完成程度指标=(单位产品的工时定额/单位产品的 【能力要求】: 一、核定用人数量的基本方法(原) (一)按劳动效率定员根据生产任务和工人的劳动效率,以及出勤率来计算。 实际上是根据工作量和劳动定额来计算。适用于:有劳动定额的人员,特别是以手工操作为主的工种。公式中:工人劳动效率=劳动定额×定额完成率。劳动定额可以分为工时定额和产量定额两种基本形式,两者转化关系为: 所以无论采用产量定额还是工时定额,两者计算的结果都是相同的。一般来说,某工种生产产品的品种单一,变化较小而产量较大时,宜采用产量定额来计算。可采用下面的公式: 如果把废品率考虑进来,则计算公式为: 二、劳动定员 【计算题】: 某企业主要生产 A、B、C 三种产品,三种产品的单位产品工时定额和 2011年的订单如表所示。预计该企业在 2011 年的定额完成率为 110%,废品率为 2.5%,员工出勤率为95%。 请计算该企业 2011 年生产人员的定员人数 【解答】: A 产品生产任务总量=150×100=15000(工时) B 产品生产任务总量=200×200=40000(工时) C 产品生产任务总量=350×300=105000(工时) D 产品生产任务总量=400×400=160000(工时) 总生产任务量=15000+40000+105000+160000=320000(工时) 2011 年员工年度工日数=365-11-104=250(天/人年) 【解答】:
LES,DNS,RANS模型计算量比较 摘要:湍流流动是一种非常复杂的流动,数值模拟是研究湍流的主要手段,现有的湍流数值模拟的方法有三种:直接数值模拟(Direct Numerical Simulation: DNS),Reynolds平均方法(Reynolds Average Navier-Stokes: RANS)和大涡模拟(Large Eddy Simulation: LES)。直接数值模拟目前只限于较小Re数的湍流,其结果可以用来探索湍流的一些基本物理机理。RANS方程通过对Navier-Stokes方程进行系综平均得到描述湍流平均量的方程;LES方法通过对Navier-Stokes方程进行低通滤波得到描述湍流大尺度运动的方程,RANS和LES方法的计算量远小于DNS,目前的计算能力均可实现。 关键词:湍流;直接数值模拟;大涡模拟;雷诺平均模型 1 引言 湍流是空间上不规则和时间上无秩序的一种非线性的流体运动,这种运动表现出非常复杂的流动状态,是流体力学中有名的难题,其 性。传统计算复杂性主要表现在湍流流动的随机性、有旋性、统计[]1 流体力学中描述湍流的基础是Navier-Stokes(N-S)方程,根据N-S 方程中对湍流处理尺度的不同,湍流数值模拟方法主要分为三种:直接数值模拟(DNS)、雷诺平均方法(RANS)和大涡模拟(LES)。直接数值模拟可以获得湍流场的精确信息,是研究湍流机理的有效手段,但现有的计算资源往往难以满足对高雷诺数流动模拟的需要,从而限制了它的应用范围。雷诺平均方法可以计算高雷诺数的复杂流动,但给出的是平均运动结果,不能反映流场紊动的细节信息。大涡模拟基于湍动能传输机制,直接计算大尺度涡的运动,小尺度涡运动对大尺度涡的影响则通过建立模型体现出来,既可以得到较雷诺平均方法更多的诸如大尺度涡结构和性质等的动态信息,又比直接数值模拟节省计算量,从而得到了越来越广泛的发展和应用。
阿尔法资产模型及计算方法 阿尔法资产(Alpha investment)是一种风险调整过的积极投资回报。它是根据所承担的超额风险而得到的回报,因此经常用来衡量基金经理的管理和表现水平。通常会在计算时,将基准的回报减去,以便看出它的相对水平。 阿尔法资产是资本资产定价模型中的一个量效率市场假说阿尔法系数为零 计算公式: 其中的阿尔法系数(αi)是资本资产定价模型中的一个量,是证券特征线与纵坐标的截距。在效率市场假说中,阿尔法系数为零。 阿尔法系数(α系数,Alpha(α)Coefficient) α系数的定义:α系数是一投资或基金的绝对回报(Absolute Return) 和按照β系数计算的预期回报之间的差额。绝对回报(Absolute Return)或额外回报(Excess Return)是基金/投资的实际回报减去无风险投资收益(在中国为1年期银行定期存款回报)。绝对回报是用来测量一投资者或基金经理的投资技术。预期回报(Expected Return)贝塔系数β和市场回报的乘积,反映投资或基金由于市场整体变动而获得的回报。 一句话,平均实际回报和平均预期回报的差额即α系数。 α系数计算方法 α系数简单理解 α>0,表示一基金或股票的价格可能被低估,建议买入。亦即表示该基金或股票以投资技术获得平均比预期回报大的实际回报。 α<0,表示一基金或股票的价格可能被高估,建议卖空。亦即表示该基金或股票以投资技术获得平均比预期回报小的实际回报。 α=0,表示一基金或股票的价格准确反映其内在价值,未被高估也未被低估。亦即表示该基金或股票以投资技术获得平均与预期回报相等的实际回报。 例子分析
第三章: 总体方差:; 样本方差: = 样本协方差S xy 总体协方差 皮尔逊积矩相关系数:r xy= 第五章:离散型概率分布 数学期望, 方差 f(x)为概率 二项概率函数: f(x)= 5、5 泊松概率分布 f(x)=,在一个时间区间内事件发生x次得概率,μ为数学期望(与方差相差) 第六章:连续型概率分布 6、1均匀概率密度函数 a≤x≤b f(x)= 0其她 E(x)=,Var(x)= 连续型概率分布 6、3二项概率得正态近似 均值μ=np,标准差,当取概率p<p(x)时,x+0、5;当取概率p>p(x)时,x-0、5。 6、4指数概率分布 f(x)=,表示两起事件之间得时间间隔 累积概率:不超过X0分钟 P(x≤x0) =1- 第八章:总体均值区间估计 8、1总体标准差σ已知,求总体均值μ得置信区间估计 95%置信水平(confidence level),0、95置信系数(confidence coefficient),置信区间(confidenceinterval) =,边际误差==,α=1-0、95=0、05,α/2=0、025(上侧面积) 总体均值得区间估计=μ=+ 8.2总体标准差σ未知,求总体均值μ得置信区间估计(t分布) 用样本标准差s代替总体标准差σ,t代替z μ=+,自由度df=n-1 8.3样本容量得确定 n=,E为所希望得总体均值μ得边际误差 8.4总体比率:只有z,没有t =,边际误差===E 总体均值得区间估计=+
n= ()2p*(1-p*)/E2第九章:假设检验(一个μ) 总体均值μ假设检验H 0:μ=μ 0 ;H a :μ≠μ0 ,μ0为假定值 p-value≤α,即z≥(上侧)或z≤-(下侧),则拒绝 p(z≥1、96)=0、025 9、3总体标准差σ已知,求z z=, 为样本均值 置信区间法:+,瞧μ0就就是否落在该区间内 9、4总体标准差σ未知,求t ,df=n-1 9、5总体比率假设检验,求z H0:p=p0; H a:p≠p0,p0为假定值 z= 9、7计算第二类错误得概率 (1)在显著性水平α下,根据临界值法确定临界值并建立拒绝法则(如,如果z≤,则拒绝); (2)根据,解出样本均值取值范围(根据z=≤或≥); (3)建立接受域,如>a; (4)根据接受域(不变)与满足备择假设得新μ,计算概率(z=)。 第二类错误概率β,做出拒绝H0得正确结论得概率称为功效,值为1-β 越接近原假设均值μ,发生第二类错误得风险越大。 9、8 确定总体均值μ假设检验得样本容量 n= α为第一类错误概率,β为第二类错误概率,μ0为原假设总体均值,μa为第二类错误所用总体均值。 双侧检验中,以Zα/2代替Zα 第十章:两总体均值与比例得推断(两个μ) 10、1两总体均值之差(μ1-μ2)得推断,总体方差σ1与σ2已知 标准差=,Margin of error= μ1-μ2得区间估计: μ1-μ2得假设检验: H0:μ1-μ2=D0;Ha:μ1-μ2≠D0,双侧,求z: 10、2两总体均值之差(μ1-μ2)得推断,总体方差σ1与σ2未知 μ1-μ2得置信区间估计:, df=,自由度取小得整数 μ1-μ2得假设检验,求t: t= 10、3匹配样本 H0:μd=0, Ha:μd≠0,双侧 t= ,df=n-1,为两组数值之差得平均值,μd为总体数值之差得平均值(一般为0),S d为两组样本数值之差得标准差 置信区间= 10、4 两总体比例之差得推断 H 0:p1-p2=0; H a :p1-p2≠D0 , 两总体比例之差得置信区间= 第十一章:关于总体方差σ2得统计推断
复利终值与现值 由于利息的因素,货币是有时间价值的,从经济学的观点来看,即使不考虑通胀的因素,货币在不同时间的价值也是不一样的;今天的1万元,与一年后的1万元,其价值是不相等的。例如,今天的1万元存入银行,定期一年,年利10%,一年后银行付给本利共1.1万元,其中有0.1万元为利息,它就是货币的时间价值。货币的时间价值有两种表现形式。一是绝对数,即利息;一是相对数,即利率。 存放款开始的本金,又叫“现值”,如上例中的1万元就是现值;若干时间后的本金加利息,叫“本利和”,又叫“终值”,如上例的1.1万元就是终值。 利息又有单利、复利之分。单利的利息不转为本金;复利则是利息转为本金又参加计息,俗称“利滚利”。 设PV为本金(复利现值)i为利率n为时间(期数)S为本利和(复利终值) 则计算公式如下: 1.求复利终值 S=PV(1+i)^n (1) 2.求复利现值 PV=S/(1+i)^n (2) 显然,终值与现值互为倒数。 公式中的(1+i)^n 和1/(1+i)^n 又分别叫“复利终值系数”、“复利现值系数”。可分别用符号“S(n,i)”、“PV(n,i)”表示,这些系数既可以通过公式求得,也可以查表求得。
例1、本金3万元,年复利6%,期限3年,求到期的本利和(求复利终值)。 解:S=PV(1+i)^n 这(1+i)^n 可通过计算,亦可查表求得, 查表,(1+6%)^3=1.191 所以S=3万×1.191=3.573万元(终值) 例2、5年后需款3000万元,若年复利10%,问现在应一次存入银行多少?(求复利现值) 解:PV=S×1/(1+i)^n=3000万×1/(1+10%)^5查表,1/(1+10%)^5=0.621 所以,S=3000万×0.621=1863万元(现值)
计算方法公式总结 绪论 绝对误差 e x x * =-,x *为准确值,x 为近似值。 绝对误差限 ||||e x x ε*=-≤,ε为正数,称为绝对误差限 相对误差* r x x e e x x **-==通常用r x x e e x x *-==表示相对误差 相对误差限||r r e ε≤或||r r e ε≤ 有效数字 一元函数y=f (x ) 绝对误差 '()()()e y f x e x = 相对误差''()()()()()()() r r e y f x e x xf x e y e x y y f x =≈= 二元函数y=f (x 1,x 2)
绝对误差 12121212 (,)(,)()f x x f x x e y dx dx x x ??=+?? 相对误差121122 1212(,)(,)()()()r r r f x x x f x x x e y e x e x x y x y ??=+?? 机器数系 注:1. β≥2,且通常取2、4、6、8 2. n 为计算机字长 3. 指数p 称为阶码(指数),有固定上下限L 、 U
4. 尾数部 120.n s a a a =± ,定位部p β 5. 机器数个数 1 12(1)(1)n U L ββ-+--+ 机器数误差限 舍入绝对 1|()|2 n p x fl x ββ--≤截断绝对|()|n p x fl x ββ--≤ 舍入相对1|()|1||2 n x fl x x β--≤截断相对1|()|||n x fl x x β--≤ 秦九韶算法 方程求根 ()()()m f x x x g x *=-,()0g x ≠,*x 为f (x )=0的m 重根。 二分法
性能: HF << MP2 < CISD< MP4(SDQ) ~CCSD< MP4 < CCSD(T) MNDO:低估了激发能,活化能垒太高。键旋转能垒太低。超价化合物以及有些位阻的体系算出来过于不稳。四元环太稳定。过氧键太短,C-O-C醚键角太大,负电型元素间键长太短,氢键太弱且太长。 PRDDO:参数化到溴和第三周期金属。适合无机化合物、有机金属化合物、固态计算、聚合物模拟。目标数据是从头算结果。整体结果不错,偶尔碱金属的键长有误。 AM1:不含d轨。算铝比PM3好,整体好于MNDO。O-Si-O不够弯、旋转势垒只有实际1/3,五元环太稳定,含磷化合物几何结构差,过氧键太短,氢键强度虽对但方向性错,键焓整体偏低。 SAM1:开发AMPAC公司的semichem公司基于AM1扩展出来的,明确增加了d轨道。由于考虑更多积分,比其它半经验方法更耗时。精度略高于AM1和PM3。振动频率算得好,几乎不需要校正因子。特地考虑了表达相关效应。 PM3:比AM1整体略好一点点。不含d轨。氢键键能不如AM1但键角更好,氢键过短,肽键C -N键旋转势垒太低,用在锗化合物糟糕,倾向于将sp3的氮预测成金字塔形。Si-卤键太短。有一些虚假极小点。一些多环体系不平,氮的电荷不对。 PM3/MM:PM3基础上加入了对肽键的校正以更好用于生物体系。 PM3(TM):PM3加了d轨,参数是通过重现X光衍射结构得到的,因此对其它属性计算不好,几何结构好不好取决于化合物与拟合参数的体系是否相似。 PM4:没做出来或者没公布。 PM6:可以做含d轨体系。最适合一般的优化、热力学数据计算。Bi及之前的元素都能做。比其它传统和新发展的半经验方法要优秀。但也指出有不少问题,比如算P有点问题,算个别势垒有时不好,JCTC,7,2929说它对GMTKN24测试也就和AM1差不多,卤键不好。
并行计算综述 姓名:尹航学号:S131020012 专业:计算机科学与技术摘要:本文对并行计算的基本概念和基本理论进行了分析和研究。主要内容有:并行计算提出的背景,目前国内外的研究现状,并行计算概念和并行计算机类型,并行计算的性能评价,并行计算模型,并行编程环境与并行编程语言。 关键词:并行计算;性能评价;并行计算模型;并行编程 1. 前言 网络并行计算是近几年国际上并行计算新出现的一个重要研究方向,也是热门课题。网络并行计算就是利用互联网上的计算机资源实现其它问题的计算,这种并行计算环境的显著优点是投资少、见效快、灵活性强等。由于科学计算的要求,越来越多的用户希望能具有并行计算的环境,但除了少数计算机大户(石油、天气预报等)外,很多用户由于工业资金的不足而不能使用并行计算机。一旦实现并行计算,就可以通过网络实现超级计算。这样,就不必要购买昂贵的并行计算机。 目前,国内一般的应用单位都具有局域网或广域网的结点,基本上具备网络计算的硬件环境。其次,网络并行计算的系统软件PVM是当前国际上公认的一种消息传递标准软件系统。有了该软件系统,可以在不具备并行机的情况下进行并行计算。该软件是美国国家基金资助的开放软件,没有版权问题。可以从国际互联网上获得其源代码及其相应的辅助工具程序。这无疑给人们对计算大问题带来了良好的机遇。这种计算环境特别适合我国国情。 近几年国内一些高校和科研院所投入了一些力量来进行并行计算软件的应用理论和方法的研究,并取得了可喜的成绩。到目前为止,网络并行计算已经在勘探地球物理、机械制造、计算数学、石油资源、数字模拟等许多应用领域开展研究。这将在计算机的应用的各应用领域科学开创一个崭新的环境。 2. 并行计算简介[1] 2.1并行计算与科学计算 并行计算(Parallel Computing),简单地讲,就是在并行计算机上所作的计算,它和常说的高性能计算(High Performance Computing)、超级计算(Super Computing)是同义词,因为任何高性能计算和超级计算都离不开并行技术。
大数据治理系列,第一部分:大数据治理 统一流程模型概述和明确元数据管理策略大数据治理的核心是为业务提供持续的、可度量的价值 在各行各业中,随处可见因数量、速度、种类和准确性结合带来的大数据问题,为了更好地利用大数据,大数据治理逐渐提上日程。大数据治理的核心是为业务提供持续的、可度量的价值。本文主要介绍大数据治理的基本概念和大数据治理统一流程参考模型的前两步:“明确元数据管理策略”和“元数据集成体系结构”。 大数据治理概述 (狭义)大数据是指无法使用传统流程或工具在合理的时间和成本内处理或分析的信息,这些信息将用来帮助企业更智慧地经营和决策。而广义的大数据更是指企业需要处理的海量数据,包括传统数据以及狭义的大数据。(广义)大数据可以分为五个类型:Web和社交媒体数据、机器对机器(M2M )数据、海量交易数据、生物计量学数据和人工生成的数据。 ?Web和社交媒体数据:比如各种微博、博客、社交网站、购物网站中的数据和内容。 *M2M数据:也就是机器对机器的数据,比如RFID数据、GPS数据、智能仪表、监控记录数据以及其他各种传感器、监控器的数据。 ?海量交易数据:是各种海量的交易记录以及交易相关的半结构化和非结构化数据,比如电信行业的CDR、3G上网记录等,金融行业的网上交易记录、core
banking记录、理财记录等,保险行业的各种理赔等。 ?生物计量学数据:是指和人体识别相关的生物识别信息,如指纹、DNA、虹膜、视网膜、人脸、声音模式、笔迹等。 ?人工生成的数据:比如各种调查问卷、电子邮件、纸质文件、扫描件、录音和电子病历等。 在各行各业中,随处可见因数量、速度、种类和准确性结合带来的大数据问题,为了更好地利用大数据,大数据治理逐渐提上日程。在传统系统中,数据需要先存储到关系型数据库/数据仓库后再进行各种查询和分析,这些数据我们称之为静态数据。而在大数据时代,除了静态数据以外,还有很多数据对实时性要求非常高,需要在采集数据时就进行相应的处理,处理结果存入到关系型数据库/数据仓库、MPP数据库、Hadoop平台、各种NoSQL数据库等,这些数据我们称之为动态数据。比如高铁机车的关键零部件上装有成百上千的传感器,每时每刻都在生成设备状态信息,企业需要实时收集这些数据并进行分析,当发现设备可能出现问题时及时告警。再比如在电信行业,基于用户通信行为的精准营销、位置营销等,都会实时的采集用户数据并根据业务模型进行相应的营销活动。 大数据治理的核心是为业务提供持续的、可度量的价值。大数据治理人员需要定期与企业高层管理人员进行沟通,保证大数据治理计划可以持续获得支持和 帮助。相信随着时间的推移,大数据将成为主流,企业可以从海量的数据中获得更多的价值,而大数据治理的范围和严格程度也将逐步上升。为了更好地帮助企业进行大数据治理,笔者在IBM数据治理统一流程模型基础上结合在电信、金融、政府等行业进行大数据治理的经验,整理了大数据治理统一流程参考模型,整个参考模型分为必选步骤和可选步骤两部分。
2.配料 2.1概述 烧结配料是按烧结矿的质量指标要求和原料成分,将各种原料(含铁料、溶剂、燃料等)按一定的比例配合在一起的工艺过程,适宜的原料配比可以生产出数量足够的性能良好的液相,适宜的燃料用量可以获得强度高还原性好的烧结矿。 对配料的基本要求是准确。即按照计算所确定的配比,连续稳定配料,把实际下料量的波动值控制在允许的范围内,不发生大的偏差。实践表明,当配料发生偏差,会影响烧结过程的进行和烧结矿的质量。 生产中,当烧结机所需的上料量发生变化时,须按配比准确计算各种料在每米皮带或单位时间内的下料量;当料种或原料成分发生变化时,则应按规定要求,重新计算配比,并准确预计烧结矿的化学成分。 2.2配料方法——质量配料法 此法是按原料的质量进行配料的一种方法。其主要装置是皮带电子称——自动控制调节系统——调速圆盘给料机,配料时,每个料仓配料圆盘下的皮带电子称发出瞬时送料量信号,此信号输入调速圆盘自动调节系统,调节部分即根据给定值信号与电子皮带秤测量值信号的偏差,自动调节圆盘转速,达到所要求的给料量,质量配料系统如图1所示 质量配料法可实现配料的自动化,便于电子计算机集中控制与管理,配料的动态精度可高达0.5%-1%,为稳定烧结作业和产品成分创造了良好条件,也是劳动条件得到改善。 2.3配料室(本厂) 配料室采用单列布置,15个矿槽,混匀矿槽上采用移动B=1000卸料车向各配料槽给料;无烟煤、焦粉、冷返矿矿槽上采用B=650固定可逆胶带机向各配料槽给料。生石灰用外设压缩空气将汽车罐车送来的生石灰送至配料槽。混匀矿采用¢2500圆盘给料机排料,配料电子称称重;燃料和溶剂及冷返矿直接用配料电子称拖出;生石灰的排料、称量及消化通过叶轮给料机、电子称及消化器完成。以上几种原料按设定比例经称量后给到混合料的B=800胶带机上。料槽侧壁安装振动电机,防止料槽闭塞。 调速圆盘自 动调节系统 给定值 控制量 偏差 调节部分 调节量 操作部分 (圆盘) 操作量 控制部分 (圆盘给料机) 检出部分 (电子皮带秤) 图1 质量配料系统
国外结算模型体系的主流方法比较 焦燕冬 国外结算模型体系主要有四种主流方法及相关理论,它们分别是成本法、资费法、收入比例分成法和呼叫方保留全部收入法(SKA),见表1。在对世界范围内一些有代表性国家的网间互联政策进行比较研究后发现,以长期增量成本为基础计算结算费是国际主流趋势。而资费法,尤其是芬兰的独立资费,简单明了,易于操作,矛盾较少,可作为成本法之外的一种重要借鉴。至于收入比例分成法和呼叫方保留全部收入法对我们的借鉴意义不大。因此,我们在结算体系设计中应该重点研究成本法和资费法。下面将重点介绍这几种方法。 表1 结算方法比较 方法适用网络监管定位应用国家是否借鉴 SKA 在两个运营商处于相类似的地位并且互 相交换相近数量的电信流量这种方法最 为有效。适用于两网成本差异不大、来 去话业务量大致相等或者互联成本甚微 的情况,多为互联网网间结算所采用; 降低管制成本;放松 管制 印度、美国、加 拿大、(本地运营 上的互联) IP-IP结算 收入 分成法适用于竞争初期固网-固网之间; 一些发展中国家采 用收入分成方法,往 往是作为改革过程 中的一种过渡方式 泰国、印度尼西 亚、马来西亚(99 年前) 否 资费 法移动网、固定网 站在消费者角度,激 励企业降低资费;减 少管制成本 新西兰、芬兰 移动接续费的 制定 完全分摊 成本法较少被采用传统固定网络 英国、日本(1995 年以前)、瑞典 否 长期增量成本法主流方法:广泛应用于固网接续费、移 动接续费等 激励运营商效率,促 进公平竞争,精确化 管理 美国、英国、欧 盟、澳大利亚等 等 主要应用英国 方法,计划采用 全业务等等
5.方茴说:“那时候我们不说爱,爱是多么遥远、多么沉重的字眼啊。我们只说喜欢,就算喜欢也是偷偷摸摸的。” 6.方茴说:“我觉得之所以说相见不如怀念,是因为相见只能让人在现实面前无奈地哀悼伤痛,而怀念却可以把已经注定的谎言变成童话。” 7.在村头有一截巨大的雷击木,直径十几米,此时主干上唯一的柳条已经在朝霞中掩去了莹光,变得普普通通了。 8.这些孩子都很活泼与好动,即便吃饭时也都不太老实,不少人抱着陶碗从自家出来,凑到了一起。 9.石村周围草木丰茂,猛兽众多,可守着大山,村人的食物相对来说却算不上丰盛,只是一些粗麦饼、野果以及孩子们碗中少量的肉食。 钢架结构重量计算方法 材料重量计算 圆钢重量(公斤)=0.00617×直径×直径×长度 方钢重量(公斤)=0.00785×边宽×边宽×长度 六角钢重量(公斤)=0.0068×对边宽×对边宽×长度 八角钢重量(公斤)=0.0065×对边宽×对边宽×长度 螺纹钢重量(公斤)=0.00617×计算直径×计算直径×长度 角钢重量(公斤)=0.00785×(边宽+边宽-边厚)×边厚×长度 扁钢重量(公斤)=0.00785×厚度×边宽×长度 钢管重量(公斤)=0.02466×壁厚×(外径-壁厚)×长度 六方体体积的计算 公式① s20.866×H/m/k 即对边×对边×0.866×高或厚度 各种钢管(材)重量换算公式 钢管的重量=0.25×π×(外径平方-内径平方)×L×钢铁比重其中:π= 3.14 L=钢管长度钢铁比重取7.8 所以,钢管的重量=0.25×3.14×(外径平方-内径平方)×L×7.8 * 如果尺寸单位取米(M),则计算的重量结果为公斤(Kg) 钢的密度为:7.85g/cm3 (注意:单位换算) 钢材理论重量计算 钢材理论重量计算的计量单位为公斤(kg )。其基本公式为: W(重量,kg )=F(断面积mm2)×L(长度,m)×ρ(密度, 1.“噢,居然有土龙肉,给我一块!” 2.老人们都笑了,自巨石上起身。而那些身材健壮如虎的成年人则是一阵笑骂,数落着自己的孩子,拎着骨棒与阔剑也快步向自家中走去。
现在MapReduce/Hadoop以及相关的数据处理技术非常热,因此我想在这里将MapReduce的优势汇总一下,将MapReduce与传统基于HPC集群的并行计算模型做一个简要比较,也算是对前一阵子所学的MapReduce知识做一个总结和梳理。 随着互联网数据量的不断增长,对处理数据能力的要求也变得越来越高。当计算量超出单机的处理能力极限时,采取并行计算是一种自然而然的解决之道。在MapReduce出现之前,已经有像MPI这样非常成熟的并行计算框架了,那么为什么Google还需要MapReduce,MapReduce相较于传统的并行计算框架有什么优势,这是本文关注的问题。 文章之初先给出一个传统并行计算框架与MapReduce的对比表格,然后一项项对其进行剖析。 MapReduce和HPC集群并行计算优劣对比 ▲ 在传统的并行计算中,计算资源通常展示为一台逻辑上统一的计算机。对于一个由多个刀片、SAN构成的HPC集群来说,展现给程序员的仍旧是一台计算机,只不过这台计算拥有为数众多的CPU,以及容量巨大的主存与磁盘。在物理上,计算资源与存储资源是两个相对分离的部分,数据从数据节点通过数据总线或者高速网络传输到达计算节点。对于数据量较小的计算密集型处理,这并不是问题。而对于数据密集型处理,计算节点与存储节点之间的I/O将成为整个系统的性能瓶颈。共享式架构造成数据集中放置,从而造成I/O传输瓶颈。此外,由于集群组件间耦合、依赖较紧密,集群容错性较差。 而实际上,当数据规模大的时候,数据会体现出一定的局部性特征,因此将数据统一存放、统一读出的做法并不是最佳的。 MapReduce致力于解决大规模数据处理的问题,因此在设计之初就考虑了数据的局部性原理,利用局部性原理将整个问题分而治之。MapReduce集群由普通PC机构成,为无共享式架构。在处理之前,将数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(map),将处理后的数据进行合并(combine)、排序(shuffle and sort)后再分发(至reduce节点),避免了大量数据的传输,提高了处理效率。无共享式架构的另一个好处是配合复制(replication)策略,集群可以具有良好的容错性,一部分节点的down机对集群的正常工作不会造成影响。 硬件/价格/扩展性 传统的HPC集群由高级硬件构成,十分昂贵,若想提高HPC集群的性能,通常采取纵向扩展的方式:即换用更快的CPU、增加刀片、增加内存、扩展磁盘等。但这种扩展方式不能支撑长期的计算扩展(很容易就到顶了)且升级费用昂贵。因此相对于MapReduce集群,HPC集群的扩展性较差。 MapReduce集群由普通PC机构成,普通PC机拥有更高的性价比,因此同等计算能力的集群,MapReduce集群的价格要低得多。不仅如此,MapReduce集群
国外数据治理模型比较 (来源:图书馆论坛, 2018-06-19) 摘要:[目的/意义]深入探析国外数据治理模型的构成要素、治理特点、优势与不足等,为我国数据治理模型的构建提供理论基础与实践参考。[方法/过程]采用文献调研和网络调查法,对比分析国外4个典型数据治理模型,总结优劣之处。[结果/结论]国外数据治理模型各具特色,结合对比分析的结果,遵循由明确治理模型的原则与目的到理论回归实践的逻辑思路,从数据治理原则与目的、数据治理利益相关者、数据治理技术与系统、数据治理要素关系四个视角提出建议,以期为我国的数据治理模型构建提供借鉴与参考。 引言 继十八届三中全会首次提出国家治理体系和治理能力现代化之后,十九大对此进一步提出了明确的要求。由于国家治理体系体现的是数量与结构,治理能力体现的是品质与能力,而治理体系是一项系统工程,所以在治理体系和治理能力建设方面,应重结构提品质,分类细化治理,通过实现国家治理体系和治理能力现代化,实现其它目标。同样的,在学术界,通过实现数据治理,将提升数据管理,确保数据质量,形成开放共享的新局面等。研究人员指出数据治理是决策、职能以及操作流程有机组合的系统,并且人们对这些数据资产承担责任W。而构建一个数据治理模型,能为组织的数据治理工作提供直观清晰的操作指南与行动方针[2]。 一、数据治理模型概述 通过对国内外文献及相关网站的广泛调研,发现国外数据治理始于2004年在企业管理中的探讨[3],2005年后陆续有学者对其展开研
究,讨论数据治理在企业、政府等领域发挥的影响与作用[4_6]。国内数据治理的研究大多集中在计算机、行政学以及金融等领域。包冬梅在借鉴国外数据治理模型框架的基础上,首提我国高校图书馆数据治理框架CALib[7]。此外,国内己有多位学者从数据治理的内涵、要素、模型等角度进行述评,指出体系、模型等的设计是未来研究的重点方向,治理实践是其最终目的[8_9]。 通过在Web of science数据库中检索"data governance"相关的论文,发现国外研究集中在案例分析方面,指出行业或企业缺乏数据治理这一事实。例如,调查发现西澳大利亚警察枪支管理系统和卫生信息系统存在很多数据问题,数据管理人员对本系统数据的准确性没有信心,无法落实数据责任,这两个案例强调非常真实的数据管理问题,相关学者指出这些问题不是规则或技术造成的,而是由于缺乏完善的数据治理[10]。在第五届欧洲信息管理与评估会议中(European Conference on Information Management and Evaluation,简称ECIME),研究人员调查中小企业对数据治理的看法,以及数据治理模型是否适用于中小企业等问题。结果显示,尽管许多模型具有适应性和可扩展性,但缺乏可操作性,无法满足许多中小企业的要求。更需关注的是,大多数中小企业不承认数据的内在价值,没有将数据视为具有支持其业务流程的系统而独立存在。显然,随着大数据浪潮的推进,数据治理却并未普及,组织中缺乏数据治理的现象依然大量存在,组织各阶层管理人员对数据治理的重视程度依然欠缺。学术界对数据治理研究的透彻与全面,并不能代表组织机构愿意接受理论,使用模型。宄其根源,数据治理难以落实的原因可归纳为以下几点,首先组织内部的不同团体之间缺乏沟通与协调,导致数据信息滞留。其次,组织人员对数据资产无责任意识,无法确保数据质量,没有重视数据治理等。因此,构建数据治理模型是必要的,同时模型的可操作性和
WOFOST计算LAI的公式及率定的选择 1.什么是LAI,如何测量? WOFOST手册中给出的LAI翻译为: LAI-----leaf area index (leaf area)/(soil area) (ha ha-1) ,即单位土地面积上叶片的总面积。 《陆地生态系统生物观测规范》(中国生态系统研究网络科学委员会编2007)中可以查得以下关于叶面积指数定义及测定方法的信息: a.叶面积指数定义 叶面积指数是指一定地面积(投影面积)上所有植物叶面积之和与地面积的比值。是用来估测植物群体生产力的一个必不可少的参数。 b.叶面积指数的测定方法 测定叶面积的方法有直接测定法和间接测定法。 直接测定法可用叶面积仪测定; 间接测定法包括计算纸(方格纸)法、纸重法、称干重法、求积仪法、长宽系数法、拓印法等。 其中,叶面积仪法方便准确,长宽系数法和称重法由于不需要特殊的仪器,经常使用。 长宽系数测定法适用于大中型叶片,整株植物叶片大小相对均匀,且叶片比较规整的植物,但是需要知道特定品种作物的校正系数。 称重法选择标准植株10—20株,刈割后,确定所有叶片的干重,结合实测的比叶面积(单位叶片重量的面积),计算标准植株总叶面积,然后换算成群落的叶面积指数。
2.SWAP-WOFOST计算LAI的公式及其前提假设 a.净增长阶段 在计算叶面积指数时模型需要输入的相关参数如下: 1.出苗时叶面积指数(LAIEM); 2.叶面积指数最大相对增长速率(RGRLAI); 3.比叶面积(SLA); 4.茎和储存器官的绿色面积指数(SPA、SSA) 在叶片生长的初始阶段叶片外形和最终叶片大小受温度的限制,主要受到细胞分裂和延展的影响而非同化物的供应。较高的温度会加快生长发育,导致生长期缩短,对于相对较宽的温度范围,生长速率或多或少与温度呈线性反应(Hunt et al,1985; Causton and Venus,1981; Van Dobben,1962),因此,WOFOST使用温度和来描述温度对初始生长阶段的影响。。在这个所谓的指数生长阶段,叶面积指数的增长速度w LAI(ha ha-1 d-1)计算公式如下: 是叶面积指数最大相对增长速率(℃-1 d-1),有效温度T eff 其中的w LAI ,max 根据日平均气温计算,各作物及地区的取值不同,需要用户指定其与日平均气温的关系。 WOFOST假设叶面积指数的指数阶段增长速率将持续到等于受同化物供应限制下的叶面积指数增长速率,在此之后叶面积增长速率又进入了第二阶段
PU 资料 聚氨酯计算公式中有关术语及计算方法 1. 官能度 官能度是指有机化合物结构中反映出特殊性质(即反应活性)的原子团数目。对聚醚或聚酯多元醇来说,官能度为起始剂含活泼氢的原子数。 2. 羟值 在聚酯或聚醚多元醇的产品规格中,通常会提供产品的羟值数据。 从分析角度来说,羟值的定义为:一克样品中的羟值所相当的氢氧化钾的毫克数。 在我们进行化学计算时,一定要注意,计算公式中的羟值系指校正羟值,即 羟值校正 = 羟值分析测得数据 + 酸值 羟值校正 = 羟值分析测得数据 - 碱值 对聚醚来说,因酸值通常很小,故羟值是否校正对化学计算没有什么影响。 但对聚酯多元醇则影响较大,因聚酯多元醇一般酸值较高,在计算时,务必采用校正羟值。 严格来说,计算聚酯羟值时,连聚酯中的水份也应考虑在内。 例,聚酯多元醇测得羟值为224.0,水份含量0.01%,酸值12,求聚酯羟值 羟值校正 = 224.0 + 1.0 + 12.0 = 257.0 3. 羟基含量的重量百分率 在配方计算时,有时不提供羟值,只给定羟基含量的重量百分率,以OH%表示。 羟值 = 羟基含量的重量百分率×33 例,聚酯多元醇的OH%为5,求羟值 羟值 = OH% × 33 = 5 × 33 = 165 4. 分子量 分子量是指单质或化合物分子的相对重量,它等于分子中各原子的原子量总和。 (56.1为氢氧化钾的分子量) 例,聚氧化丙烯甘油醚羟值为50,求其分子量。 对简单化合物来说,分子量为分子中各原子量总和。 羟值 官能度分子量1000 1.56??= 3366 50 1000 31.56=??= 分子量
第三章并行计算模型和任务分解策略 首先,我们将研究不同类型的并行计算机,为了不严格限定于某个指定机型,我们通过模型把并行计算机抽象为几个特定属性。为了说明并行程序中处理器之间的通信概念模型我们讨论了不同的程序模型,另外为了分析和评估我们算法的性能,我们讨论了多计算机架构下评估并行算法复杂度的代价模型。在介绍并分析的各种代价模型的基础上给出了改进型的代价模型。 其次我们定义这样几个指标如负载均衡和网络半径等用来研究图分解问题的主要特性。并把图分解问题归纳为一般类型和空间映射图类型。我们重点研究的是后者,因为多尺度配置真实感光照渲染算法可以很方便的描述成空间映射图形式。 3.1 并行计算机模型 以下给出并行计算机的模型的概述,根据其结构并行计算机大致可分为以下几类。 多计算机(Multicomputer):一个von Neumann计算机由一个中央处理器(CPU)和一个存储单元组成。一个多计算机则由很多von Neumann计算机通过互联网络连接而成的计算机系统。见图3.1。每个计算机(节点)执行自己的计算并只能访问本地的存储。通过消息实现各计算机之间的互相通讯。在理想的网络中,两个计算节点之间的信息传送代价与本地的计算节点和它的网络阻塞无关,只和消息的长度相关。以上多计算机和分布式存储的MIMD机器之间的主要区别在于后者的两个节点间的信息传输不依赖于本地计算和其它网络阻塞。 分布式存储的MIMD类型的机器主要有IBM的SP, Intel的Paragon, 曙光4000系列, Cray 的T3E, Meiko的CS-2, NEC的Cenju 3, 和nCUBE等。通过本地网络的连接的集群系统可以认为是分布式存储的MIMD型计算机。 多处理器(Multiprocessor):一个多处理器型并行计算机(共享存储的MIMD计算机)由大量处理器组成,所有的处理器都访问一个共同的存储。理论上理想的模型就是PRAM模型(并行的随机访问系统),即任何一个处理器访问任一存储单元都是等效的(见图3.2)。并发存储访问是否允许取决于所使用的真正的模型【34】。 混合模型:分布式共享存储(DMS)计算机,提供了一个统一的存储访问地址空间但是分布式物理存储模块。编译器和运行时系统负责具体的并行化应用。这种系统软件比较复杂。 图3.1 多计算机模型图3.2 PRAM 模型 SIMD计算机:在一个SIMD(单指令流多数据流)计算机中在不同数据流阶段所有的处理器执行同样的指令流。典型的机型有MasPar的MP, 和联想机器CM2。 多计算机系统具有良好的可扩展性,价格低廉的集群式并行计算机就属于这种模型,本文中的算法主要基于多计算机体系结构。 3.2 程序模型 并行程序的编程语言如C或Fortan。并行结构以某种类库的形式直接整合进这些编程语言中。编程模型确定了并行程序的风格。一般可分为数据并行、共享存储和消息传递等模型[35]。 数据并行编程:数据并行模型开始于编写同步SIMD并行计算机程序。程序员需要在每个处理器上独立执行一个程序,每个处理器均有其自己的存储器。程序员需要定义数据如何分配到每个局部存储中。实际应用中大量的条件分支的需要使得其很难高效的运行在SIMD型的机器上。 共享存储编程:共享存储模型是一个简单的模型,因为程序员写并行程序就像写串行程序一样。一个程序的执行与几个处理器独立,也不需要同步。一个处理器的执行状态独立于其它处理器的运