
14. 量表的初步处理
一、量表层面加总
调查问卷通常是针对某个考察因素设置几个子问题,这些具有共同属性的题项需要先做加总处理,以便后续进行相关的统计分析。
例如,如下的“知识管理”量表:
题“a1-a6”,都属于“知识获取”层面,即
“a1-a6”加总= “知识获取”
题“a7-a10”都属于“知识流通”层面;
“知识获取”+“知识流通”再加总到“知识管理”层面。
数据文件为:
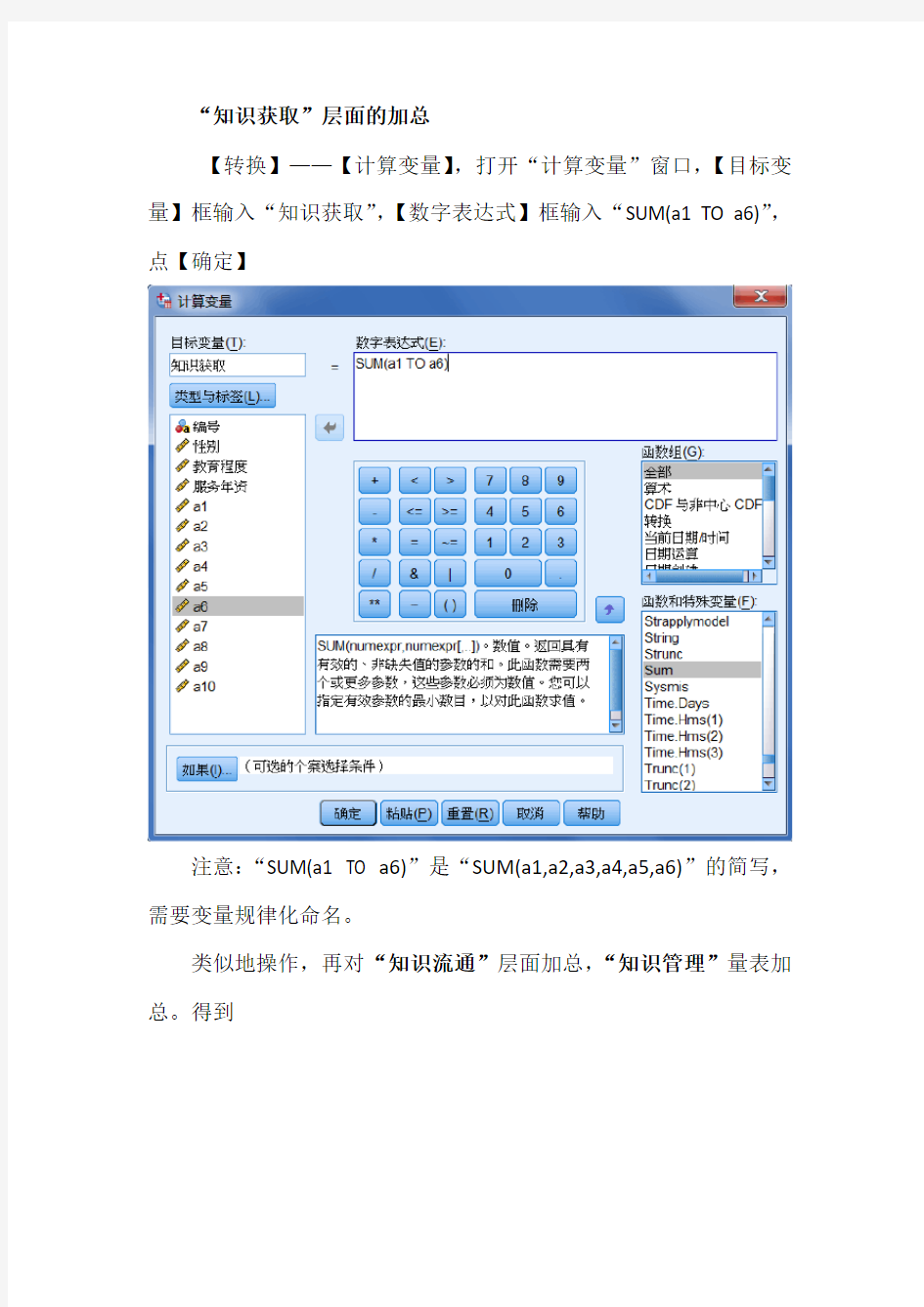
“知识获取”层面的加总
【转换】——【计算变量】,打开“计算变量”窗口,【目标变量】框输入“知识获取”,【数字表达式】框输入“SUM(a1 TO a6)”,点【确定】
注意:“SUM(a1 TO a6)”是“SUM(a1,a2,a3,a4,a5,a6)”的简写,需要变量规律化命名。
类似地操作,再对“知识流通”层面加总,“知识管理”量表加总。得到
二、层面的平均得分
层面的平均得分,即“层面总分”除以“层面题数”,能反映出该层面的平均程度。例如,“工作满意”层面,1-5分别代表“非常同意、同意、不知道、不同意、非常不同意”,若该层面平均得分为4.30,则表示平均具有较高的工作满意度。
【转换】——【计算变量】,目标变量输入“获取平均”,数字表达式输入“知识获取/6”;
类似地,“流通平均”=“知识流通/4”;
“知识管理平均”=“知识管理/10”。
得到运行结果:
三、量表的描述统计
【分析】——【描述统计】——【描述】,打开“描述性”窗口,将变量“知识获取、知识流通、知识管理、获取平均、流通平均、知识管理平均”选入【变量】框,
【选项】,(默认)勾选“均值、标准差、最小值、最大值”,点【确定】,得到
注:层面加总的均值无参考意义,层面平均的“获取平均”的均值为3.0000,流通平均的均值为3.4182,说明两个层面的“同意程度”是有差异的,该差异是否在统计学有显著意义?则需要做【分析】——【比较均值】——【配对样本T检验】。
四、多选题量表初步处理
例如. 测试人格倾向的问卷,每种人格倾向设置9道问题,每选中一道“人格A”倾向的题项,该变量累积得分+1,最终得到“人格A”得分;类似地还有“人格B、人格C、人格D”得分,哪个得分最高即判定该人具有该种人格,若有两个相同最高得分,则无法判定其人格。
有数据文件:
判断每个个案的“人格类型”:1 = A类型;2 = B类型;3 = C类型;4 = D类型;0 = 不确定类型。
1.【转换】——【计算变量】,打开“计算变量”窗口,【目标变量】框输入“人格A标记”,【数字表达式】框输入逻辑表达式:(人格A >人格B) & (人格A >人格C) & (人格A >人格D)
点【确定】,得到
注:“人格A标记”=1,表示“人格A”的值为四个人格中的最大值,否则“人格A标记”=0.
2.类似地,计算
“人格B标记”=(人格B >人格A) & (人格B >人格C) & (人格B >人格D)
“人格C标记”=(人格C >人格A) & (人格C >人格B) & (人格C >人格D)
“人格D标记”=(人格D >人格A) & (人格D >人格B) & (人格D >人格C)
得到
3. 计算“人格类型”
【转换】——【计算变量】,打开“计算变量”窗口,【目标变量】框输入“人格类型”,【数字表达式】框输入:
1*人格A标记+2*人格B标记+3*人格C标记+4*人格D标记
点【确定】得到
注:“人格标记”只是没用的临时变量,可以删除。
点【确定】,得到
注意:个案10的人格类型为7 > 4,原因是其“人格C、人格D”的值均为最大值9,该个案的人格类型应该是无法判定(=0)。
第一步:建立数据 1. 打开SPSS 2. 在左下角点”variable view” 3. 在左上角输入“调查问卷”——将“Type类型”调成“sting字符型”——“Decimals 小数点”位数改成“0” 4. 从第二行开始依次输入“问题1,问题2,问题N”,并在每个问题的“Values 变量值”在输入:变量值Values框中为“1”/标签Label框中“非常不同意”点“add 添加”;然后依次输入2不同意3不一定4同意5非常同意 5. 以同样的方式输完所有的问题 第二步:输入数据 1. 左下角选“Data View数据视图” 2. 将每份问卷每道题的结果输入对应的框中 3. 以同样的方式将150份问卷输入 第三步:分析数据 1.在标题栏选择“Analyze分析”——“Description statistics描述性统计”——“Frequencies频数分析” 2.在频数分析对话框中,从左框选择要分析的问题到右框中 3.选择“Statistics统计”出现对话框 4.选择对应输出项即可:Mean平均数Std. deviation标准差variance方差range极差max最大min最小 5.同时也可以用“charts图表”选择要输出的图形 6.点击“OK确定”即可 7.然后再Output表中读取分析结果 8.注:因为所要分析的比较简单,能够很直观的从结果中分析出来,所以结果分析就不多解释了 PS:当然Excel也可以完成这样的分析,但SPSS软件比起Excel来要更专业些,所以用spss 做出来的结果更容易得到认可,也容易得高分,并且对于更复杂的问题Excel就显的不够用了
S P S S学习系列30.主 成份分析 -CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN
30. 主成份分析 一、基本原理 主成份分析,是数学上对数据降维的一种方法,是将多个变量转化为少数综合变量(集中了原始变量的大部分信息)的一种多元统计方法。其主要目的是将变量减少,并使其改变为少数几个相互独立的线性组合形成的新变量(主成份,其方差最大),使得原始资料在这些成份上显示最大的个别差异来。 在所有的线性组合中所选取的F1应该是方差最大的,称为第一主成分。如果第一主成分不足以代表原来所有指标的信息,再考虑选取第二个线性组合F2, 称为第二主成分。为了有效地反映原有信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0. 依此类推可以构造出第三、第四、…、第p个主成分。 主成份分析,可以用来综合变量之间的关系,也可用来减少回归分析或聚类分析中的变量数目。 设有n个样品(多元观测值),每个样品观测p项指标(变量):X1,…,X p,得到原始数据资料阵: 其中,X i = (x1i,x2i,…,x ni)T,i = 1, …, p.
用数据矩阵X的p个列向量(即p个指标向量)X1,…,X p作线性组合,得到综合指标向量: 简写成: F i = a1i X1 + a2i X2+…+a pi X p i = 1, …, p 限制系数a i = (a1i,a2i,…,a pi)T为单位向量,即 且由下列原则决定: (1)F i与F j互不相关,即COV(F i, F j)= a i T∑a i=0,其中∑为X 的协方差矩阵; (2)F1是X1,X2,…,X p的所有满足上述要求的线性组合中方差最大的,即 F2是与F1不相关的X1,…,X p所有线性组合中方差最大的,…,F p 是与F1,…,F p-1都不相关的X1,…,X p所有线性组合中方差最大的。 满足上述要求的综合指标向量F1,F2,…,F p就是主成分,这p个主成分从原始指标所提供的信息总量中所提取的信息量依次递减,每一个主成分所提取的信息量用方差来度量,主成分方差的贡
spss统计分析实习心得3篇五天的SPSS软件实训终于结束了,虽然实训过程充满了酸甜苦辣,但实训结果却是甜的。看着小组的课题报告,心里有种说不出来的感触。高老师在对统计理论及 SPSS 软件功能模块的讲解的同时更侧重于统计分析在各项工作中的实际应用,使我们不仅掌握 SPSS 软件及技术原理而且学会运用统计方法解决工作和学习中的实际问题这个实训。我真真正正学到了不少知识,另外,也提高了自己分析问题解决问题的能力。 小组中每个人完成不同的任务,我的任务是用独立样本T检验的方法分析市、县及县以下的分类对社会消费品零售总额的影响,分析方差,均值,P值,显著性如何并进行T 检验,得出结论报告。结果中比较有用的值为差值变量的均值Mean和Sig显著性在初级统计中,通常都要求所分析的数据呈现正态分布。通过对spss软件对数据的实践处理,我感觉显著性检验问题还是比较简单的,但对具体数据分析的目的性,实用性以及自己在做研究时如何使用,还有待进一步实践和提高。 SPSS 有具体的使用者要求的分析深度,同时是一个可视化的工具,使我们非常容易使用,这样我们可以自己对结果进行检查。电算化老师曾经说过,学习软件其实只是学习软件的操作流程,而要真正掌握整个软件,就得自己摸索探
究,真真正正弄懂它,还要下一定的功夫的。我也深刻体会到了这点。前几次实训都是关于会计实验的,虽然时间安排比此次实训紧,任务量大,但实训结束后,基本的试训内容都完全掌握。而这次实训,虽然时间安排较为轻松,内容也不多,操作起来也有一定的难度,另外受外界因素的影响,根本就听不见看不见老师讲的,即便后来老师一讲就去前面,由于没有条件跟着操作,导致一部分内容总是不熟练,请教同学他们也不会,不过,问题也总会用解决的办法。经过我坚持不懈的努力,在本次实训结束之前,我终于弥补了自己不熟练的那部分内容。 学习SPSS软件,对于我们这些将来要时刻与数据打交道的人是有很大的帮助的,它主要的是运用SPSS软件结合所学统计知识对数据进行需要的处理,相对于EXCEL处理,SPSS软件处理不仅效率高,而且操作简单。我个人觉得,SPSS 软件是一门专业性较强的课程,对于我们财务管理专业的学生是一门必备的课程,也是一门必须熟练掌握的课程,很庆幸,我是抱着将来要学习运用SPSS软件进行此次实训的。这次实训,使我对统计工作的过程和 SPSS应用的流程取得一定的感性认识,拓展了视野,巩固所学理论知识,提高了分析问题、解决问题的能力,也增强了我的职业意识、劳动观点以及适应社会的能力,最重要的是它使我获得了思想和课题分析处理上的双丰收。
第五节利用SPSS进行量表分析 在第五章调查研究中,我们介绍了量表得类型、编制得步骤及其应用,在本节将介绍利用SPS S软件对量表进行处理分析。 ?在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析与信度分析。 项目分析,目得就是找出未达显著水准得题项并把它删除。它就是通过将获得得原始数据求出量表中题项得临界比率值——CR值来作出判断。通常,量表得制作就是要经过专家得设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者得反应程度。故往往在量表处理中可以省去这一步。 因素分析,目得就是在多变量系统中,把多个很难解释,而彼此有关得变量,转化成少数有概念化意义而彼此独立性大得因素,从而分析多个因素得关系。在具体应用时,大多数采用“主成份因素分析”法,它就是因素分析中最常使用得方法。 信度分析,目得就是对量表得可靠性与有效性进行检验。如果一个量表得信度愈高,代表量表愈稳定。也就表示受试者在不同时间测量得分得一致性,因而又称“稳定系数”。根据不同专家得观点,量表得信度系数如果在0、9以上,表示量表得信度甚佳。但就是对于可接受得最小信度系数值就是多少,许多专家得瞧法也不一致,有些专家定为0、8以上,也有得专家定位 0、7以上。通常认为,如果研究者编制得量表得信度过低,如在0、6以下,应以重新编制较为 适宜。 ?在本节中,主要介绍利用SPSS软件对量表进行因素分析。 一、因素分析基本原理 因素分析就是通过求出量表得“结构效度”来对量表中因素关系作出判断。在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目得即在此。变量得第一个线性组合可以解释最大得变异量,排除前述层次,第二个线性组合可以解释次大得变异量,最后一个成份所能解释总变异量得部份会较少. ?主成份数据分析中,以较少成份解释原始变量变异量较大部份。成份变异量通常用“特征值”表示,有时也称“特性本质”或“潜在本质”。因素分析就是一种潜在结构分析法,其模式理论中,假定每个指针(外在变量或称题项)均由两部分所构成,一为“共同因素"、一为“唯一因素"。共同因素得数目会比指针数(原始变量数)还少,而每个指针或原始变量皆有一个唯一因素,亦即一份量表共有n个题项数,则会有n个唯一因素。唯一因素性质有两个假定: ?(1)所有得唯一因素彼此间没有相关; ?(2)所有得唯一因素与所有得共同因素间也没有相关. 至于所有共同因素间彼此得关系,可能有相关或可能皆没有相关。在直交转轴状态下,所有得共同因素间彼此没有相关;在斜交转轴情况下,所有得共同因素间彼此就有相关.因素分析最常用 得理论模式如下:??? 其中 (1)为第i个变量得标准化分数。
16.统计量与统计图 针对连续变量做描述性统计。描述性统计量分为: (1)刻画集中趋势一一均值、中位数、众数; (2)刻画离散程度——方差、标准差、极差、变异系数; (3)刻画分布形态一一偏度、峰度。 一、简单的描述性统计 有数据文件: 对“数学成绩”、“英语成绩”做描述性统计。 1. 【分析】一一【描述统计】一一【描述】,打开“描述性”窗口,将变量“数学成绩” “英语成绩”选入【变量】框,
欢迎下载 2 2. 点【选项】,打开“选项”子窗口,根据需要勾选 抱述:选项 V 均值也) d 合廿 禹歆 ---------------- /标淮差①4晨小值 易方羞 厨最丈值 ①变童列夷电} J 字婷顺序追) 总按沟值的升序排序吃) 「掩韵俏曲降序排序( Q ) 怫剰、取汛L 帮咄 点【继续】回到原窗口; 若需要得到Z 标准分数,勾选“将标准化得分另存为变量”;点 【确定】得到 描述统计量 /范穷 ”埠值的标准i 歎号
注:默认是按变量选入顺序输出上表 二、探索性描述统计 输出统计量和统计图,其主要作用有: (1)检查异常值;(2)检验数据的分布特征(是否服从正态分布); 1.【分析】一一【描述统计】一一【探索】,打开“探索”窗口, 将变量“数学成绩” “英语成绩”选入【变量】框
注:若在【因子变量】框选入若干分类变量,将按其水平值组合分别统计分析;注意勾选【输出】可选项的“两者都”。
2?点【统计量】,打开“统计量”子窗口, “ M-估计量” 当数据背离正态分布、带长尾、或有极端数据 时,M-估计量仍能提供很好的中心趋势估计; “界外值”一一可以检验数据是否有极端值存在; 3?点【绘制】,打开“图”子窗口,【箱图】勾选“按因子水平 分组”,【描述性】勾选“茎叶图”、“直方图”,勾选“带检验的正态图”(检验数据是否具有正态性) 点【继续】回到原窗口,点【确定】得到
SPSS实验心得体会 在老师的指导下,用SPSS完成了实验四有关两变量相关性分析,偏相关分析,一元线性回归分析,一元线性回归分析四大实验内容。 首先打开数据文件“3-4身体素质”数据,点击“图形→旧对话框→散点图→简单分布”,把身高做为Y轴,体重做为X轴,拟合线选择线性,置信区间无。 得出散点图。从散点图可以明显看出,从身高和体重的散点图中可以看出身高和体重存在线性相关关系,可以进行线性相关分析。然后选择“分析”→“相关”→“双变量”命令,弹出“双变量相关”对话框。 选择进行相关分析的变量。在左侧选择“身高”和“体重”变量,将其添加到右侧的“变量”框中。设定显著性检验的类型。在“显著性检验”选项组中,选择“双尾检验”。选择相关统计量的输出和缺失值的处理方法。单击“双变量相关性”对话框中“选项”按钮,在“统计量”选项组中选中“均值和标准差”,也就是输出变量的均值和标准差,然后选中“叉积偏差和协方差”。 在分析出的描述性统计量表格中,参与相关分析三个变量的样本数各有213,身高均值为166.69,体重均值为56.49,性别均值为1.68。标准差分别为7.703,9.370,.469。 然后打开数据文件“3-4身体素质”,选择“分析”→“相关”→“偏相关”命令,弹出“偏相关”对话框。选择进行偏相关分析的变量和控制变量。在左侧选择“身高”和“体重”变量,将其添加到右侧的“变量”框中。然后选中“性别”将其移入“控制”变量列表。设置显著性检验的类型,选择“双尾检验”。选择是标记显著性相关。选择相关统计量的输出。单击“偏相关”中的“选项”按钮,选中“均值和标准差”以及“零阶相关系数”。 在分析出的描述性统计量表格中,参与偏相关分析的两个变量各有213个样本数据。身高、体重、性别的均值和标准差分别是166.69,56.49,1.68 和7.703,9.370,.469。从相关性表格中可以看出,不控制性别时身高和体重的相关系数为0.771,显著性水平为0.000,小于0.01。控制性别后身高和体重的相关系数为0.545,显著性水平也为0.000.所以身高和体重的相关关系为高度正相关。 接着打开数据文件“3-4身体素质”,选择“分析”→“回归”→“线性”命令,选择进行简单线性回归分析的变量。在左侧的列表框中选择“体重”变量,移入右侧的“因变量”框中。选中“身高”,并使其进入“自变量”列表框。单击“统计量”按钮,弹出“线性回归:统计量”,线性回归选项选择使用F的概率,选择默认值,使用均值替换。 模型汇总图中显示的是一元线性回归模型的拟合情况。相关系数R为0.771,反映的是自变量与因变量之间的密切程度,其值在0~1之间,越大越好。决定系数(判定系数)R2为0.594,调整的R2为0.592。可见,模型的拟合效果很理想。系数表中回归归方程的系数是各个变量在回归方程中的系数值,Sig值表示回归系数的显著性,越小越显著,一般将其与0.05进行比较,如果小于0.05,即为显著、有统计学意义。 本例中常数项对应的系数其t检验的Sig值为0.000,自变量总收入的t 检验的Sig值为0.000。都具有显著的统计意义。
SPSS软件在医学科研中的应用计算机实习(SPSS10.0) 何平平 北大医学部流行病与卫生统计学系
实习六Logistic回归分析
(一)Logistic回归分析的任务 影响因素分析在流行病学研究中,logistic回归常用于疾病 的危险 因素分析,logistic回归分析可以提供一个重要的指标: OR。 (二)Logistic回归分析的基本原理 1.变量特点因变量:二分类变量,若令因变量为y,则常 用y=1表 示“发病”,y=0表示“不发病”(在病例对照研究中,分别表示病例组和对照组)。 自变量:可以为分类变量,也可以为连续变量。
2.Logistic模型 Log P 1 P = ? +? 1 x 1 + ? 2 x 2 + ...... + ? m x m P=P(y=1|x),为发病概率;1-P=P(y=0|x),为不发病概率。?0为常数项,?1 ,?2 ….. ?m分别为m个自变量的回归系数。 模型估计方法:最大似然法(Maximum Likelihood Method)。构造似然函数(L ikelihood function )L= P(y=1|x) P(y=0|x),通过迭代法估计一组参数(?0,?1 ,?2 ….. ?m)使L达到最大。
3.自变量的相对重要性分析 衡量变量相对重要性的指标 (1)Wald值:(?i /SE(?i ))2,近似?2分布,用于检验自变量的显著性。 (2)对自变量作显著性检验的概率P值。当Wald值越大,P值越小时,自变量的影响就越大。 4.自变量的筛选与多元线性回归分析类似,有Forward法(实际上是逐 步向前法)、Backward法(默认方法为Enter,即所有自变量一次全部进入方程)。
SPSS(社会科学统计软件)学习资料 SPSS for Windows:Base System User’ s Guide. Marija J. Norusis. SPSS Inc. 卢纹岱等编着:SPSS for Windows 从入门到精通。电子工业出版社,1996年. SPSS for Windows made Simple. 3rd ed. Paul R. Kinnear & Colin D. Gray Psychological Press,Ltd.,1999 作业: 必须在次周周一前用电子邮件,磁盘或打印形式交给主讲教师和辅导上机的助教。 讲义: 课前在网上下载或接收电子邮件。 成绩评定方法: 期末考试, 期中考试,和作业,出勤。 期末考试 40% 期中考试 30% 作业,出勤 30% 总成绩
1准备分析用数据 1.1数据收集 主要是通过测量方法收集必需的数据。测量方法可以是实验、测验、问卷调查等等。应尽可能包括自己所需要的所有变量,因为从分析中排除不必要的变量比收集附加变量要容易得多。 1.2数据编码 当我们通过问卷或测验收集了很多的数据回来后,接下来的工作就是把这些数据录入到计算机里。为了输入数据简单,一种方法是在录入前用数据或符号表述被试的回答,这就是数据编码。下面是一个编码表: 些特殊信息的Case。 (编码示例) 不管你自己对SPSS使用多么熟悉,在数据录入前对数据进行系统的编码是非常必要的,它可以使你避免混乱,清楚了解数据的意义。 1.3数据文件 SPSS有三种文件:SYNTAX 文件(文本文件,以.sps为后缀)、DATA文件(数据文件,以.sav为后缀)、OUTPUT文件(结果文件,以.spo为后缀)。SYNTAX 文件主要是保存命令及相关的文本资料;DATA文件则是保存供SPSS统计的数据,只有这种文件里的数据才可以直接进行统计使用;OUTPUT文件保存统计的结果。 SPSS所用的数据文件有很多种,主要是根据自己分析数据的量及每一Case 包括变量多少来选择适当的文件形式。
spss实验心得体会 篇一:SPSS学习报告总结心得 应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。最后总结出这篇报告,以巩固所学。 SPSS,全称是Statistical Product and Service Solutions,即“统计产品与服务解决方案”软件,是IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,SPSS 1 也是一个进行数据分析和预测的强大工具。这门课中也会用到AMOS软件。 关于SPSS的书,很多都是首先介绍软件的。这个软件易于安装,我装的是19.0的,虽然20.0有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。
首先是T检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。结果出来后依然分不清楚是接受原假设还是拒绝原假设。不过现在弄懂了。这部分很有用的是T检验。T检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。T检验分为单样本T检验、独立样本T检验、配对样本T检验。其中,单样本T 检验是样本均数与总体均数的比较的T检验,用于推断样本所代表的未知总体 均数μ与已知的总体均数uo有无差别;独立样本T检验主要用于检验两个样本是否来自具有相同均值的总体,即比较两个样本的均值是否相同,要求两个样本是相互独立的; 2 配对样本T检验中,要正确理解“配对”的含义,主要用于检验两个有联系的正态总体的均值是否有显著差异,跟独立检验的区别就是样本是否是配对样本。这几个方法用软件操作起来都是相对简单的,关键是分清楚什么时候用这个什么时候用那个。 然后是方差分析。方差分析就是将索要处理的观测值作为一个整体,按照变异的不同来源把观测值总变异的平方和以及自由度分解为两个或多个部分,获得不同变异来源的均值与误差均方,通过比较不同变异来源的均方与误差均方,判断各样本所属总体方差是否相等。方差分析主要包括单因素方差分析、多因素方差分析和协方差分析等。这一部分在学习的过程中出现一些问题,就是用SPSS来操作的时候分不清观测变量和控制变量,如果反了的话会导致结果的不准确。其次,对Bonferroni、Tukey、Scheffe等方法的使用目的不清楚,现在基本掌握了多重比
应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,spss也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现spss的功能相当强大。最后总结出这篇报告,以巩固所学。 spss,全称是statistical product and service solutions,即“统计产品与服务解决方案”软件,是ibm公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。spss具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,spss也是一个进行数据分析和预测的强大工具。这门课中也会用到amos软件。 关于spss的书,很多都是首先介绍软件的。这个软件易于安装,我装的是的,虽然有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和t检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是t检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。结果出来后依然分不清楚是接受原假设还是拒绝原假设。不过现在弄懂了。这部分很有用的是t检验。t检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。t检验分为单样本t检验、独立样本t检验、配对样本t检验。其中,单样本t 检验是样本均数与总体均数的比较的t检验,用于推断样本所代表的未知总体 均数μ与已知的总体均数uo有无差别;独立样本t检验主要用于检验两个样本是否来自具有相同均值的总体,即比较两个样本的均值是否相同,要求两个样本是相互独立的;配对样本t检验中,要正确理解“配对”的含义,主要用于检验两个有联系的正态总体的均值是否
spss实验心得体会 篇一:SPSS学习报告总结心得 应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSspss实验心得体会)S也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。最后总结出这篇报告,以巩固所学。 SPSS,全称是StatisticalProductandServiceSolutions,即“统计产品与服务解决方案”软件,是Ibm公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。这门课中也会用到AmoS软件。关于SPSS的书,很多都是首先介绍软件的。这个软件易于安装,我装的是19.0的,虽然20.0有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、
结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是T检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。结果出来后依然分不清楚是接受原假设还是拒绝原假设。不过现在弄懂了。这部分很有用的是T检验。T检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。T检验分为单样本T检验、独立样本T检验、配对样本T检验。其中,单样本T检验是样本均数与总体均数的比较的T检验,用于推断样本所代表的未知总体 均数μ与已知的总体均数uo有无差别;独立样本T检验主要用于检验两个样本是否来自具有相同均值的总体,即比较两个样本的均值是否相同,要求两个样本是相互独立的;配对样本T检验中,要正确理解“配对”的含义,主要用于检验两个有联系的正态总体的均值是否有显著差异,跟独立检验的区别就是样本是否是配对样本。这几个方法用软件操作起来都是相对简单的,关键是分清楚什么时候用这个什么时候用那个。 然后是方差分析。方差分析就是将索要处理的观测值作为一个整体,按照变异的不同来源把观测值总变异的平方和以及自由度分解为两个或多个部分,获得不同变异来源的均值与误差均方,通过比较不同变异来源的均方与误差均方,判断各样本所属总体方差是否相等。方差
SPSS教程:可靠性分析 2.1主要功能 在精神卫生与社会医学研究中,经常需要借助量表来了解对象的某一特性。如常用的症状自评量表(SCL-90)即用于评定对象精神病症状的表现形式与强度;又如生活事件量表(LES)即用于对精神刺激进行定性和定量分析。在完成一份量表的编制工作后,或在准备将一份已有的量表作实际应用前,需要对量表的信度进行考核。 量表的使用是为了了解被测对象的某一特征,因而在编制一份量表时,所设立的一系列项目是为了体现量表需要测定的这一特征。如果所设立的测定项目无法获得这一特征,则表示该量表可靠性差,即信度低。所以,研究者有时需要了解量表中各测定项目之间的一致性(同质信度考核),有时需要将量表的测定项目按原编号的奇、偶数分半后,对各自的测定结果进行相关性检验(分半信度考核),等等,这就是量表的可靠性分析,亦即信度研究。 量表的可靠性分析可通过调用Reliability过程完成。 12.2实例操作 [例12.1]采用家庭环境量表(FES)研究30名女医师的家庭特征,测定结果按10个分量表的实际得分整理如下。请以此资料对FES的信度作评价。 12.2.1数据准备 激活数据管理窗口,定义变量名:亲密度、情感表达、矛盾性、独立性、成功性、知识性、娱乐性、道德宗教观、组织性、控制性等十个分量表的变量名依次是FES1、FES2、FES3、FES4、FES5、FES6、FES7、FES8、FES9、FES10,输入原始数据。 12.2.2统计分析 激活Statistics菜单选Scale中的Reliability Analysis...项,弹出Reliability
Analysis对话框(如图12.1示)。从对话框左侧的变量列表中选fes1~fes10共十个变量,点击 钮使之进入Items框。点击Model处的下拉菜单,系统提供5种分析模型: Alpha:计算信度系数Cronbach α值; Split half:分半信度的分析; Guttman:真实可靠性的Guttman低界; Parallel:并行模型假定下的极大似然可靠性估计; Strict parallel:严格并行模型假定下的极大似然可靠性估计。 本例选用Alpha模型。 点击Statistics...钮,弹出Reliability Analysis: Statistics对话框(图12.2),该对话框内含如下选项: 在Descriptives for栏中选Item、Scale、Scale if item deleted项,以指定对各项目、测定得分情况和项目与量表总体特征关系进行描述性统计; 在Summaries处有四个选项:Means、Variances、Covariances和Correlations,可分别要求系统计算在Descriptives for栏中指定对象的平均数、方差、协方差和相关系数,本例选Means、Variances和Correlations三项; 在Inter-Item处有Correlations和Covariances两项,前者可计算项目间的两两相关系数,后者可计算项目间的两两协方差值,本例选Correlations项; 在ANOV A Table处有None、F test、Friedman chi-square、Cochran chi-square 四个选项,其意义分别是:不作方差分析、作重复度量的方差分析、计算Friedman 和Kendall谐和系数(适用于等级资料)、计算Cohran Q值(适用于所有项目均为二分变量),本例选F test项;
07. 计算与计数 (一)计算 对数据变量做四则运算,并将计算结果存为新变量。 有数据文件: 用【计算】功能,求“数学”、“英文”两科的平均成绩。 1. 【转换】——【计算变量】,打开“计算变量”窗口;
2. 【目标变量】框输入“平均成绩”作为存放计算结果的新变量,【类型和标签】可选填,
3.【数字表达式】框,输入计算表达式:“(数学+英文) / 2”,也可以选用【函数组】中的函数——统计量:“MEAN(数学,英文)” 注:使用“自定义表达式”和“函数”的计算结果可能不同,因为二者处理缺失值的方式不同。例如,自定义加和时,有一个缺失值则和为缺失值;而SUM函数只有全是缺失值时和才为缺失值。另外,变量可从左侧框中选入。 注:“**”表示次幂; 若需要只选择满足某条件的个案进行计算,可以点【如果】,打开“计算变量:If个案”子窗口,设置筛选条件,例如只计算1班学生的平均成绩:
4.点【确定】,得到
(二)计数 统计指定变量“取某个值”或“落入某区间”的出现次数。例如,统计不及格的学生人数。 有数据文件: 一、标记“语文”不及格的学生 1.【转换】——【对个案的值计数】,打开“计算个案值的出现次数窗口; 2.【目标变量】框输入新变量名“语文不及格”,【目标标签】可选填,将左侧变量“语文”选入右侧变量框,
3.点【定义值】,打开“要统计的值”子窗口,勾选【围,从最低到值】,填入59,点【添加】 右侧窗口出现“Lowest thru 59”,表示语文成绩最低分到59分的观察值,新变量计数为1,否则计数为0; 注:【如果】可选择只满足某条件的个案进行上述计数操作。 4. 点【继续】回到原窗口,点【确定】,得到
一、实训目的 SPSS统计软件实训课是在我们在学习《统计学》理论课程之后所开设的一门实践课。其目的在于,通过此次实训,使学生在掌握了理论知识的基础上,能具体的运用所学的统计方法进行统计分析并解决实际问题,做到理论联系实际并掌握统计软件SPSS的使用方法。, 二、实训时间与地点: 时间:2012年1月9日至2012年1月13日 地点:唐山学院北校区A座502机房 三、实训要求: 这次实训内容为上机实训,主要学习SPSS软件的操作技能,以及关于此软件的一些理论和它在统计工作中的重要作用。对我们的主要要求为,运用SPSS 软件功能及相关资料来完成SPSS操作,选择有现实意义的课题进行计算和分析,最后递交统计分析报告,加深学生对课程内容的理解的。我们小组的研究课题是社会消费品零售总额的分析。 四、实训的主要内容与过程: 此次实训,我大概明白了SPSS软件的基本操作流程,也掌握了如何排序、分组、计算、合并、增加、删除以及录入数据;学会了如何计算定基发展速度、环比发展速度等动态数列的计算;明白了如何进行频数分析、描述分析、探索分析以及作图分析;最大的收获是学会了如何运用SPSS软件对变量进行相关分析、回归分析和计算平均值、T检验和假设性检验。通过这次试训,我基本上掌握了SPSS软件的主要操作过程,也学会了运用SPSS软件进行各种数据分析。这些内容,也就是我们SPSS统计软件实训的主要内容。 四、实训结果与体会 五天的SPSS软件实训终于结束了,虽然实训过程充满了酸甜苦辣,但实训结果却是甜的。看着小组的课题报告,心里有种说不出来的感触。高老师在对统计理论及SPSS软件功能模块的讲解的同时更侧重于统计分析在各项工作中的 实际应用,使我们不仅掌握SPSS软件及技术原理而且学会运用统计方法解决工作和学习中的实际问题这个实训。我真真正正学到了不少知识,另外,也提高了自己分析问题解决问题的能力。
30. 主成份分析 一、基本原理 主成份分析,是数学上对数据降维的一种方法,是将多个变量转化为少数综合变量(集中了原始变量的大部分信息)的一种多元统计方法。其主要目的是将变量减少,并使其改变为少数几个相互独立的线性组合形成的新变量(主成份,其方差最大),使得原始资料在这些成份上显示最大的个别差异来。 在所有的线性组合中所选取的F1应该是方差最大的,称为第一主成分。如果第一主成分不足以代表原来所有指标的信息,再考虑选取第二个线性组合F2, 称为第二主成分。为了有效地反映原有信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0. 依此类推可以构造出第三、第四、…、第p个主成分。 主成份分析,可以用来综合变量之间的关系,也可用来减少回归分析或聚类分析中的变量数目。 设有n个样品(多元观测值),每个样品观测p项指标(变量):X1,…,X p,得到原始数据资料阵: 其中,X i = (x1i,x2i,…,x ni)T,i = 1, …, p. 用数据矩阵X的p个列向量(即p个指标向量)X1,…,X p作线性组
合,得到综合指标向量: 简写成: F i = a1i X1 + a2i X2 +…+a pi X p i = 1, …, p 限制系数a i = (a1i,a2i,…,a pi)T为单位向量,即 且由下列原则决定: (1)F i与F j互不相关,即COV(F i, F j)= a i T∑a i=0,其中∑为X 的协方差矩阵; (2)F1是X1,X2,…,X p的所有满足上述要求的线性组合中方差最大的,即 F2是与F1不相关的X1,…,X p所有线性组合中方差最大的,…,F p是与F1,…,F p-1都不相关的X1,…,X p所有线性组合中方差最大的。 满足上述要求的综合指标向量F1,F2,…,F p就是主成分,这p 个主成分从原始指标所提供的信息总量中所提取的信息量依次递减,每一个主成分所提取的信息量用方差来度量,主成分方差的贡献就等于原指标相关系数矩阵相应的特征值λi,每一个主成分的组合系数 a i = (a1i,a2i,…,a pi)T
spss实验报告心得体会 篇一:SPSS学习报告总结心得 应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。最后总结出这篇报告,以巩固所学。 SPSS,全称是Statistical Product and Service Solutions,即“统计产品与服务解决方案”软件,是IBM公司推出的一系
列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。这门课中也会用到AMOS软件。 关于SPSS的书,很多都是首先介绍软件的。这个软件易于安装,我装的是的,虽然有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是T检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东
第三篇常用推断方法 二、综合分析题 1.略 2.略 3.为了解某校本科学生体质合格率的性别差异,随机抽查了本科男生 110人和女生 130 人,其中男生有 100 人合格,女生有 70 人合格,请问该校本科男女生体质合格率是否不同? 表3-1某校本科学生体质合格率 体质状况合格不合格合计 男100 10 110 女70 60 130 合计170 160 240 【操作】 (1)数据准备 1)定义变量:性别(Value定义:1=男,2=女)、结果(Value定义:0=合格,1=不合格)、频数。输入数据,如图3-1所示。 图3-1 SPSS的Date View窗口 2)频数加权:点击Data菜单下的Weigh Cases选项,弹出Weigh Cases对话框,如图3-2,选择Weigh cases by,选中变量“频数”将其送入Frequency Variable框中,如图3-3所示,单击OK。
图3-2 Data→Weigh Cases 图3-3 Weigh Cases对话框 (2)统计分析 1)点击Analyze菜单下的Descriptive Statistics子菜单,选择Crosstabs选项,如图3-4所示,系统弹出Crosstabs主对话框,选择变量“性别”将其送入Row(s)框内,选择变量“体质状况”将其送入Column(s)框中,如图3-5所示。
图3-4Analyze→DescriptiveStatistics→Crosstabs 图3-5 Crosstabs主对话框 2)单击右侧的Statistics,弹出Statistics子对话框,选择Chi-square,如图3-6所示,单击Continue返回。 图3-6 Statistics子对话框图9-13 Cells子对话框
22. 方差分析 一、方差分析原理 1. 方差分析概述 方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。 方差分析是对总变异进行分析。看总变异是由哪些部分组成的,这些部分间的关系如何。 方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks’∧检验)。 方差分析可用于: (1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料; (2)可对两因素间交互作用差异进行显著性检验; (3)进行方差齐性检验。 要比较几组均值时,理论上抽得的几个样本,都假定来自正态总体,且有一个相同的方差,仅仅均值可以不相同。还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。所谓的方差是离均差平方和除以自由度,在方差分析中常简称为均方(Mean Square)。
2. 基本思想 基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。 根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总自由度也被分成相应的各个部分,各部分的离均差平方除以各自的自由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。 方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。 效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来自回归的变异项),等等。 当分析和确定了各个效应项S后,根据原始观察资料可计算出各个离均差平方和SS,再根据相应的自由度df,由公式MS=SS/df,求出均方MS,最后由相应的均方,求出各个变异项的F值,F值实际上是两个均方之比值,通常情况下,分母的均方是误差项的均方。
10. 数据分类汇总 分类汇总,是分割数据和统计分析的综合,即按指定的分类变量对个案进行分组,并按分组对变量做描述统计。 有关教师的某数据文件: 性别:1=男生,2=女生 学校规模:1=大型学校,2=中型学校,3=小型学校 问题1. 按不同性别与学校规模,统计“年龄”在30岁以下的人数的百分比; 问题2. 按不同性别与学校规模,统计“工作压力”在28以上的人数的百分比; 问题3. 按不同性别与学校规模,统计“工作满意”的平均值; 问题4. 按不同性别与学校规模,统计“组织承诺”的标准差。
操作步骤: 1.【数据】——【分类汇总】,打开“汇总数据”窗口,将分类变量“性别”和“学校规模”选入【分组变量】框;将变量“年龄”、“工作压力”、“工作满意”、“组织承诺”选入【汇总变量】的“变量摘要”框; 注意:默认是汇总各变量的“平均数”;
2.针对问题1:选中【变量摘要】框中的“年龄_mean=MEAN(年龄)”,点【函数】,打开“汇总函数”子窗口,在【百分比】框,勾选【下方】,【值】框填入“30”,表示“年龄在30岁以下”,点【继续】 针对问题2:类似地选中“工作压力_mean=MEAN(工作压力)”,点【函数】,在【百分比】框,勾选【上】,【值】框填入“28”,表示“工作压力在28以上”,点【继续】
问题3已经是平均值,不用改动。 针对问题4:选中“组织承诺_mean=MEAN(组织承诺)”,点【函数】,勾选【标准差】,点【继续】
3.【变量名与标签】按钮,可以设置新变量名和变量标签; 注意:为了能显示各分组中的个案数,需要勾选【个案数】,【名称】框填入变量名“人次”; 4.【保存】方式有三种选项: (1)将新变量添加到活动数据集——直接在原数据集中增加列; (2)创建只包含汇总变量的新数据集; (3)写入只包含汇总变量的新数据文件aggr.sav; 注意:最好选(2)或(3),若直接在原数据集中增加列将出现大量重复的汇总数据。 5.实际中最好勾选【适用于大型数据集的选项】下的“在汇总之前排序文件”。