
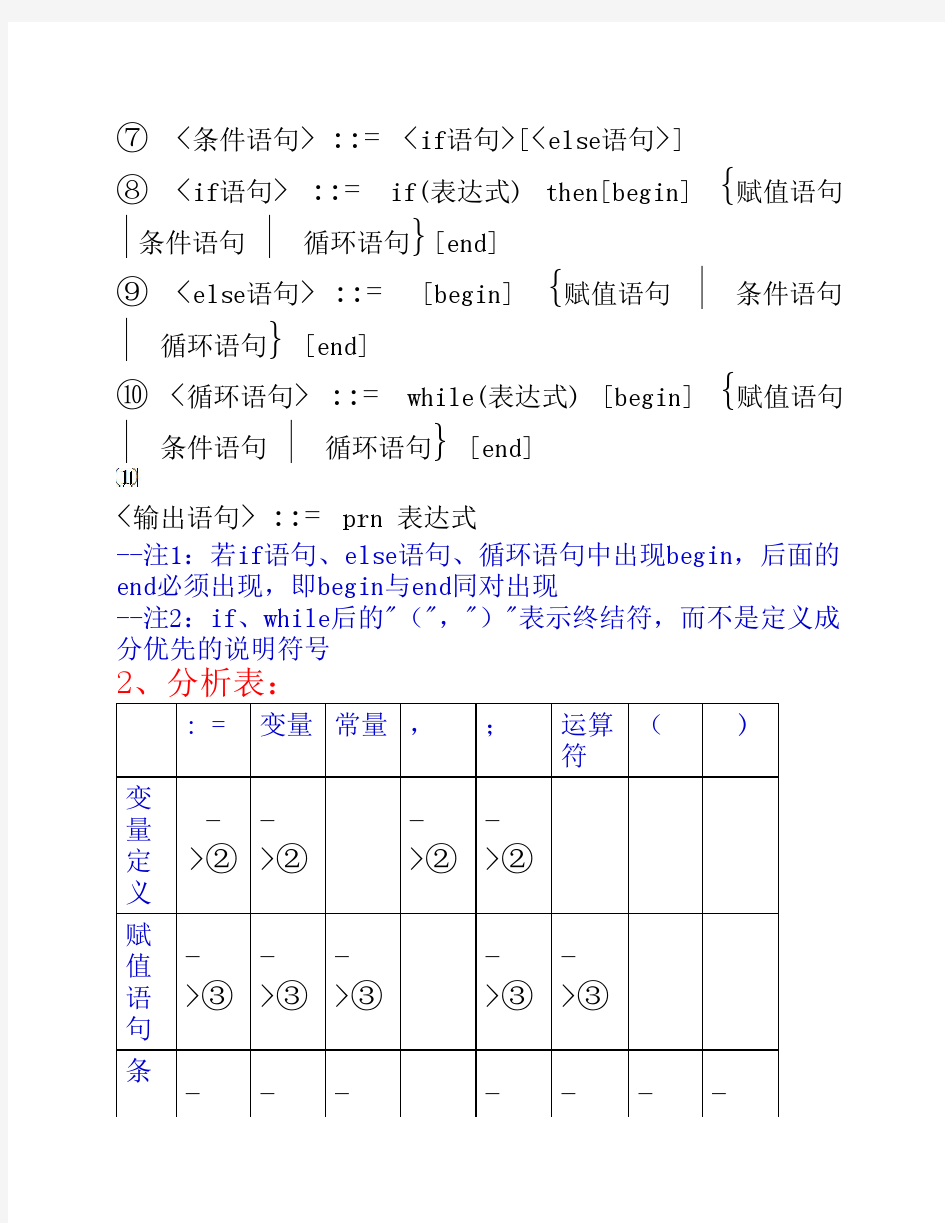
《LL(1)分析器的构造》实验报告 一、实验名称 LL(1)分析器的构造 二、实验目的 设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。 三、实验内容和要求 设计并实现一个LL(1)语法分析器,实现对算术文法: G[E]:E->E+T|T T->T*F|F F->(E)|i 所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。 实验要求: 1、检测左递归,如果有则进行消除; 2、求解FIRST集和FOLLOW集; 3、构建LL(1)分析表; 4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。 四、主要仪器设备 硬件:微型计算机。 软件: Code blocks(也可以是其它集成开发环境)。 五、实验过程描述 1、程序主要框架 程序中编写了以下函数,各个函数实现的作用如下: void input_grammer(string *G);//输入文法G
//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u, int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GG int* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空 string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集 string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集 string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表 void analyse(string **table,string U,string u,int t,string s);//分析符号串s 2、编写的源程序 #include 编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日 一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为 华北水利水电学院编译原理实验报告 2010~2011学年第二学期xxxx 级计算机专业 班级:xxxxx 学号:xxxxx 姓名:xxx 一、实验目的 通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。 二、实验要求 ⑴选择最有代表性的语法分析方法,如LL(1)分析法、算符优先法或LR分析法 ⑵选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。 ⑶实习时间为6小时。 三、实验内容 选题1:使用预测分析法(LL(1)分析法)实现语法分析: (1)根据给定文法,先求出first集合、follow集合和select集合,构造预测分析表(要求预测分析表输出到屏幕或者输出到文件); (2)根据算法和预测分析表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程) (3)给定表达式文法为: G(E): S→TE E→+TE | ε T→FK K→*FK |ε F→(S)|i (4)分析的句子为: (i+i)*i和i+i)*i 四、程序源代码 #include "stdafx.h" #include "SyntaxAnalysis.h" #include "SyntaxAnalysisDlg.h" #ifdef _DEBUG #define new DEBUG_NEW #undef THIS_FILE static char THIS_FILE[] = __FILE__; #endif /////////////////////////////////////////// // CAboutDlg dialog used for App About 实验二语法分析器 一、实验目的 通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。有利于提高学生的专业素质,为培养适应社会多方面需要的能力。 二、实验内容 ◆根据某一文法编制调试LL (1 )分析程序,以便对任意输入的符号串 进行分析。 ◆构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分 析程序。 ◆分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号 以及LL(1)分析表,对输入符号串自上而下的分析过程。 三、LL(1)分析法实验设计思想及算法 ◆模块结构: (1)定义部分:定义常量、变量、数据结构。 (2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等); (3)控制部分:从键盘输入一个表达式符号串; (4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。 四、实验要求 1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。 2、如果遇到错误的表达式,应输出错误提示信息。 3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG (2)G->+TG|—TG (3)G->ε (4)T->FS (5)S->*FS|/FS (6)S->ε (7)F->(E) (8)F->i 输出的格式如下: 五、实验源程序 LL1.java import java.awt.*; import java.awt.event.*; import javax.swing.*; import javax.swing.table.DefaultTableModel; import java.sql.*; import java.util.Vector; public class LL1 extends JFrame implements ActionListener { /** * */ private static final long serialVersionUID = 1L; JTextField tf1; JTextField tf2; JLabel l; JButton b0; JPanel p1,p2,p3; JTextArea t1,t2,t3; JButton b1,b2,b3; . 编译原理实验专业:13级网络工程 语法分析器1 一、实现方法描述 所给文法为G【E】; E->TE’ E’->+TE’|空 T->FT’ T’->*FT’|空 F->i|(E) 递归子程序法: 首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。以分号作为结束符。 二、实现代码 头文件shiyan3.h #include #include int a=0; cout<<"按1结束程序"< 编译原理实验报告 实验名称:分析调试语义分析程序 TEST抽象机模拟器完整程序 保证能用!!!!! 一、实验目的 通过分析调试TEST语言的语义分析和中间代码生成程序,加深对语法制导翻译思想的理解,掌握将语法分析所识别的语法范畴变换为中间代码的语义翻译方法。 二、实验设计 程序流程图 extern int TESTScan(FILE *fin,FILE *fout); FILE *fin,*fout; //用于指定输入输出文件的指针 int main() { char szFinName[300]; char szFoutName[300]; printf("请输入源程序文件名(包括路径):"); scanf("%s",szFinName); printf("请输入词法分析输出文件名(包括路径):"); scanf("%s",szFoutName); if( (fin = fopen(szFinName,"r")) == NULL) { printf("\n打开词法分析输入文件出错!\n"); return 0; } if( (fout = fopen(szFoutName,"w")) == NULL) { printf("\n创建词法分析输出文件出错!\n"); return 0; } int es = TESTScan(fin,fout); fclose(fin); fclose(fout); if(es > 0) printf("词法分析有错,编译停止!共有%d个错误!\n",es); else if(es == 0) { printf("词法分析成功!\n"); int es = 0; 题目:词法分析器的设计与实现 一、引言................................ 错误!未定义书签。 二、词法分析器的设计 (3) 2.1词的内部定义 (3) 2.2词法分析器的任务及功能 (3) 3 2.2.2 功能: (4) 2.3单词符号对应的种别码: (4) 三、词法分析器的实现 (5) 3.1主程序示意图: (5) 3.2函数定义说明 (6) 3.3程序设计实现及功能说明 (6) 错误!未定义书签。 7 7 四、词法分析程序的C语言源代码: (7) 五、结果分析: (12) 摘要:词法分析是中文信息处理中的一项基础性工作。词法分析结果的好坏将直接影响中文信息处理上层应用的效果。通过权威的评测和实际应用表明,IRLAS是一个高精度、高质量的、高可靠性的词法分析系统。众所周知,切分歧义和未登录词识别是中文分词中的两大难点。理解词法分析在编译程序中的作用,加深对有穷自动机模型的理解,掌握词法分析程序的实 现方法和技术,用c语言对一个简单语言的子集编制一个一遍扫描的编译程序,以加深对编译原理的理解,掌握编译程序的实现方法和技术。Abstract:lexical analysis is a basic task in Chinese information processing. The results of lexical analysis will directly affect the effectiveness of the application of Chinese information processing. The evaluation and practical application show that IRLAS is a high precision, high quality and high reliability lexical analysis system. It is well known that segmentation ambiguity and unknown word recognition are the two major difficulties in Chinese word segmentation. The understanding of lexical analyse the program at compile, deepen of finite automata model for understanding, master lexical analysis program implementation method and technology, using C language subset of a simple language compilation of a scanned again compiler, to deepen to compile the principle solution, master compiler implementation method and technology. 关键词:词法分析器?扫描器?单词符号?预处理 Keywords: lexical analyzer word symbol pretreatment scanner 一、引言 运用C语言设计词法分析器,由指定文件读入预分析的源程序,经过词法分析器的分析,将结果写入指定文件。本程序是在Visual?Studio环境下,使用C语言作为开发工具。基于实验任务 词法分析器实验报告 词法分析器设计 一、实验目的: 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状 态转换图设计词法分析器的基本方法。利用该词法分析器完成对源程 序字符串的词法分析。输出形式是源程序的单词符号二元式的代码, 并保存到文件中。 二、实验内容: 1. 设计原理 词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。 理论基础:有限自动机、正规文法、正规式 词法分析器(Lexical Analyzer) 又称扫描器(Scanner):执行词法分析的程序 2. 词法分析器的功能和输出形式 功能:输入源程序、输出单词符号 程序语言的单词符号一般分为以下五种:关键字、标识符、常数、运算符,界符 3. 输出的单词符号的表示形式: 单词种别用整数编码,关键字一字一种,标识符统归为一种,常数一种,各种符号各一种。 4. 词法分析器的结构 单词符号 5. 状态转换图实现 三、程序设计 1.总体模块设计 /*用来存储目标文件名*/ string file_name; /*提取文本文件中的信息。*/ string GetText(); /*获得一个单词符号,从位置i开始查找。并且有一个引用参数j,用来返回这个单词最后一个字符在str的位置。*/ string GetWord(string str,int i,int& j); /*这个函数用来除去字符串中连续的空格和换行 int DeleteNull(string str,int i); /*判断i当前所指的字符是否为一个分界符,是的话返回真,反之假*/ bool IsBoundary(string str,int i); /*判断i当前所指的字符是否为一个运算符,是的话返回真,反之假*/ bool IsOperation(string str,int i); 学号20102798 专业软件工程姓名薛建东 实验日期2013.04.08 教师签字成绩实验报告 【实验名称】LL(1)语法分析 【实验目的】 通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。使了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练掌握开发应用程序的基本方法。 【实验内容】 ◆根据某一文法编制调试LL ( 1)分析程序,以便对任意输入的符号串进行分析。 ◆构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。 ◆分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1) 分析表,对输入符号串自上而下的分析过程。 【设计思想】 (1)、LL(1)文法的定义 LL(1)分析法属于确定的自顶向下分析方法。LL(1)的含义是:第一个L表明自顶向下分析是从左向右扫描输入串,第2个L表明分析过程中将使用最左推导,1表明只需向右看一个符号便可决定如何推导,即选择哪个产生式(规则)进行推导。 LL(1)文法的判别需要依次计算FIRST集、FOLLOW集和SELLECT集,然后判断是否为LL(1)文法,最后再进行句子分析。 需要预测分析器对所给句型进行识别。即在LL(1)分析法中,每当在符号栈的栈顶出现非终极符时,要预测用哪个产生式的右部去替换该非终极符;当出现终结符时,判断其与剩余输入串的第一个字符是否匹配,如果匹配,则继续分析,否则报错。LL(1)分析方法要求文法满足如下条件:对于任一非终极符A的两个不同产生式A→α,A→β,都要满足下面条件:SELECT(A→α)∩SELECT(A→β)=? (2)、预测分析表构造 LL(1)分析表的作用是对当前非终极符和输入符号确定应该选择用哪个产生式进行推 实验二--语法分析(算符优先)-(2) 编译原理实验报告实验名称:语法分析器设计 专业:计算机科学与技术 姓名:田莉莉 学号:201117906 语法分析—算符优先分析程序 一.实验要求 ⑴ 选择最有代表性的语法分析方法,如算符优先法、递归子程序法或LR 分析法 ⑵ 选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。 ⑶ 实习时间为6 学时。 二.实验内容及要求 ( 1)根据给定文法,先求出 FirstVt 和 LastVt 集合,构造算符优先关系表(要求算符优先关系表输出到屏幕或者输出到文件); ( 2)根据算法和优先关系表分析给定表达式是否是该文法识别的正确的算术表达式(要求输出归约过程) (3)给定表达式文法为: G(E ' ): E'T #E# E—E+T | T T—T*F |F F—(E)|i (4)分析的句子为 : (i+i)*i 和 i+i)*i 三.程序设计思想及实现步骤 程序的设计思想: 按照编译原理教材提供的算法,本程序的设计主要实现三个主要的过程: (1) 求解 FristVT 集和 LastVT 集:利用 CString 数组存放 VT 集,利用数组 下标对应非终结符关系; (2) 输出算符优先分析表:利用 MFC 中的 ClistCtrl 控件输出显示算符表, 比 利用二维数组对应其在内存中的关系。 (3) 利用算符优先分析表进行归约:根据教材所给算法,并对其进行实现在 屏幕上输 出归约过程。 实现步骤: 1、为程序各变量设计存储形式,具体设计如下所示: CString m_strTElem[T_LEN]; CString m_strNTElem[NT_LEN]; // 非终结符 CMapStringToPtr m_mapProdu; // 存放产生式 CMapStringToPtr m_mapProduEX; // 存放 扩展产生式 CString m_strFristVT[NT_LEN]; CString m_strLastVT[NT_LEN]; int m_nPriSheet[T_LEN+1][T_LEN+1]; // 终结符 //fristVT 集 //lastVT 集 编译原理程序设计实验报告 ——表达式语法分析器的设计班级:计算机1306班姓名:张涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器 实验内容: ⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。然后利用LL(1)分析法实现语法分析。 ⑵数据结构: int op=0; //当前判断进度 char ch; //当前字符 char nowword[10]=""; //当前单词 char operate[4]={'+','-','*','/'}; //运算符 char bound[2]={'(',')'}; //界符 struct Token { int code; char ch[10]; }; //Token定义 struct Token tokenlist[50]; //Token数组 struct Token tokentemp; //临时Token变量struct Stack //分析栈定义 { char *base; char *top; int stacksize; }; ⑶分析表及流程图 Begin PUSH(#),PUSH(E) POP(x) x ∈VT x ∈VN x=w end W=#n y NEXT(w) y n err 查LL (1)分析表空? n PUSH (i )err n y 逆序压栈 ⑷关键函数: int IsLetter(char ch) //判断ch 是否为字母 int IsDigit(char ch) //判断ch 是否为数字 int Iskey(char *string) //判断是否为关键字 int Isbound(char ch) //判断是否为界符 int Isboundnum(char ch) //给出界符所在token 值 int init(STack *s) //栈初始化 int pop(STack *s,char *ch) //弹栈操作 int push(STack *s,char ch) //压栈操作 void LL1(); //分析函数 源程序代码:(加入注释) 实验二语法分析 一、实验目的: 设计MiniC的上下文无关文法,利用JavaCC生成调试递归下降分析程序,以便对任意输入的符号串进行分析。本次实验的目的主要是加深对递归下降分析法的理解。 二、语法分析器: 按照MiniC语言的语法规则检查词法分析输出的记号流是否符合这些规则,并根据这些规则所体现出的语言中的各种语法结构的层次性。把规则写入到JavaCC的.jjt文件中,可以生成树状的层次结构。 三、JavaCC: 在JavaCC的文法规范文件中,不仅可以描述语言的语法规范,而且可以描述词法规范,本次实习中,利用JavaCC以MiniC语言构造一个不含语义分析的编译器前端,包括词法分析、语法分析,并要考虑语法分析中的错误恢复问题。通过使用JavaCC, 可以体会LL(k)文法的编写特点,掌握编写JavaCC文法规范文件的方法。 内容:利用JavaCC生成一个MiniC的语法分析器; 要求: 1.用流的形式读入要分析的C语言程序,或者通过命令行输入源程序。 2.具有错误检查的能力,如果有能力可以输出错误所在的行号,并简单提示 3.如果输入的源程序符合MiniC的语法规范,输出该程序的层次结构的语法树本次实习仅完成以下语法范畴的语法分析: 1. 写出一个源程序中仅包含if…else, else语句的语法分析。要求能分析其自身 嵌套. 其他语句可简化处理 2. 写出一个源程序中仅包含for语句的语法分析。要求能分析其自身嵌套, 其他语句可简化处理 3. 写出一个源程序中仅包含while语句的语法分析。要求能分析其自身嵌套。 其他语句可简化处理 4. 写出一个源程序中包含上面的12或者13或者23或者123语句的语法分析。 要求能分析除其自身嵌套外,还包括相互嵌套。其他语句可简化处理 具体实施步骤如下: 1.把MiniC转换为文法如下 <程序〉→ main()〈语句块〉 〈语句块〉→{〈语句串〉} 目录 一.设计题目 (2) 二.设计要求 (2) 1. 词法分析器的定义 (2) 2. 设计要求 (2) 3. 本程序自行规定: (3) 三.设计作用与目的 (4) 1. 设计作用 (4) 2. 设计目的 (4) 四.运行环境及工具软件 (4) 五.系统设计 (5) 1. 系统总体设计 (5) (1)词法分析器的设计 (5) (2)总体设计框图 (6) (3)总程序流程图 (6) 2. 各子模块设计 (8) (1)字符的识别 (8) (2)关键字的识别 (8) (3)数字的识别 (8) (4)界符的识别 (10) (5)运算处理 (10) 3.相关函数分析 (11) 4. 源程序设计 (12) 六.实验调试结果 (29) 1. 调试工具 (29) 2. 调试步骤 (29) 3. 调试结果 (29) 七.设计中的问题及解决方法 (31) 八.设计心得 (32) 九.参考文献 (34) 词法分析器的设计与实现 一.设计题目 词法分析器的设计与实现 二.设计要求 1. 词法分析器的定义 词法分析顾名思义就是分词。它以程序设计语言编制的源程序作为输入,以单词序列作为输出。分词过程可以通过编制程序自动完成,我们通常称这个分词程序为词法分析器。词法分析器分析的源程序可以是现有的各类程序设计语言源程序也可以是人为给定的模型语言的源程序。本文中的源程序为后者。从词的角度来看,它涉及的内容较为简单,只包括几个较为常用的词类,词类的构成上也适当的作了一些简化。对词进行分析时,我们是按类型进行分析的。不同类型的词在后续的分析中所起的作用不同,相应的操作也各有不同,但同种类型中的词虽然单词的构成不同但从宏观上看它们的操作大体一致。模型语言中的单词可以分为“关键字”、“标识符”、“常数”、“分隔符”、“运算符”几类。一般,关键字在程序设计语言中人为给定 2. 设计要求 对给定的程序通过词法分析器能够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。另外,如果是算术表达式,则需要通过栈、运算符的优先级比较处理等从而计算出最终结果并显示。通过此次课程设计要求掌握从源程序文件中读取有效字符的方法,掌握词法分析的实现方法并上机调试编出的词法分析程序。 在处理表达式前,首先设置两个栈:一是运算符栈,用于在表达式处理过程中存放运算符。在开始时,运算符栈中先压入一个表达式结束符“#”。二是操作数栈,用于在表达式处理过程中存放操作数。然后从左到右依次读出表达式中的各个符号(运算符或操作数),每读出一个符号按以下原则进行处理: 词法分析器实验报告 一、实验目的及要求 本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。 运行环境: 硬件:windows xp 软件:visual c++6.0 二、实验步骤 1.查询资料,了解词法分析器的工作过程与原理。 2.分析题目,整理出基本设计思路。 3.实践编码,将设计思想转换用c语言编码实现,编译运行。 4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。 三、实验内容 本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。标识符、常数是在分析过程中不断形成的。 对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。 输出形式例如:void $关键字 流程图、程序流程图: 程序: #include 实习二语法分析-自上而下分析 一、实验目的 使用预测分析方法对输入的表达式进行分析,掌握其具体的使用并且学会去分析一个文法。 二、实验内容 1.设计表达式的语法分析器算法(使用预测分析) 2.编写一段代码并上机调试查看其运行结果 三、实验要求 使用LL(1)分析算法设计表达式的语法分析器 LL(1)文法是一个自上而下的语法分析方法,它是从文法的开始符号出发,生成句子的最左推导,从左到右扫描源程序,每次向前查看一个字符,确定当前应该选择的产生式。 实现LL(1)分析的另一种有效方法是使用一张分析表和一个栈进行联合控制。 预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前a的输入符号行事的。对于任何(X,a),总控程序每次都执行三种可能的动作之一。 1.若X=a=“#”,则宣布分析成功,停止分析过程 2.若X=a≠“#”,则把X从STACK栈顶逐出,让a指向下一 个输入符号。 3.若X是一个非终结符,则查看分析表。 四、运行结果 (本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析) 五、源程序实现 /*LL(1)分析法源程序,只能在VC++中运行*/ #include 编译原理语法分析器实验报告 班级: 学号: 姓名: 实验名称语法分析器 一、实验目的 1、根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。 2、本次实验的目的主要是加深对自上而下分析法的理解。 二、实验内容 [问题描述] 递归下降分析法: 0.定义部分:定义常量、变量、数据结构。 1.初始化:从文件将输入符号串输入到字符缓冲区中。 2.利用递归下降分析法分析,对每个非终结符编写函数,在主函数中调用文法开始符号的函数。 LL(1)分析法: 模块结构: 1、定义部分:定义常量、变量、数据结构。 2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等); 3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则; 4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式 符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简 单的错误提示。 [基本要求] 1. 对数据输入读取 2. 格式化输出分析结果 2.简单的程序实现词法分析 public static void main(String args[]) { LL l = new LL(); l.setP(); String input = ""; boolean flag = true; while (flag) { try { InputStreamReader isr = new InputStreamReader(System.in); BufferedReader br = new BufferedReader(isr); System.out.println(); System.out.print("请输入字符串(输入exit退出):"); input = br.readLine(); } catch (Exception e) { e.printStackTrace(); } if(input.equals("exit")){ flag = false; }else{ l.setInputString(input); l.setCount(1, 1, 0, 0); l.setFenxi(); System.out.println(); System.out.println("分析过程"); System.out.println("----------------------------------------------------------------------"); System.out.println(" 步骤| 分析栈 | 剩余输入串| 所用产生式"); System.out.println("----------------------------------------------------------------------"); boolean b = l.judge(); System.out.println("----------------------------------------------------------------------"); if(b){ System.out.println("您输入的字符串"+input+"是该文法的一个句子"); }else{ System.out.println("您输入的字符串"+input+"有词法错误!"); 实验二语法分析程序设计与实现 一、实验目的 任选一种有代表性的语法分析方法,如算符优先法、递归下降法、LL(1)、SLR(1)、LR(1)等,通过设计、编制、调试实现一个典型的语法分析程序,对实验一所得扫描器提供的单词序列进行语法检查和结构分析,实现并进一步掌握常用的语法分析方法。 二、基本实验内容与要求 选择对各种常见高级程序设计语言都较为通用的语法结构——算术表达式的一个简化子集——作为分析对象,根据如下描述其语法结构的BNF定义G2[<算术表达式>],任选一种学过的语法分析方法,针对运算对象为无符号常数和变量的四则运算,设计并实现一个语法分析程序。 G2[<算术表达式>]: <算术表达式> → <项> | <算术表达式>+<项> | <算术表达式>-<项> <项> → <因式> | <项>*<因式> | <项>/<因式> <因式> → <运算对象> | (<算术表达式>) 若将语法范畴<算术表达式>、<项>、<因式>和<运算对象>分别用E、T、F 和i代表,则G2可写成: G2[E]:E → T | E+T | E-T T → F | T*F | T/F F → i | (E) 输入:由实验一输出的单词串,例如:UCON,PL,UCON,MU,ID ······ 输出:若输入源程序中的符号串是给定文法的句子,则输出“RIGHT”,并且给出每一步分析过程;若不是句子,即输入串有错误,则输出“ERROR”,并且显示分析至此所得的中间结果,如分析栈、符号栈中的信息等,以及必要的出错说明信息。 要求: 1、确定语法分析程序的流程图,同时考虑相应的数据结构,编写一个语法分析源程序。 2、将词法、语法分析合在一起构成一个完整的程序,并调试成功。 3、供测试的例子应包括符合语法规则的语句,及分析程序能判别的若干错例。对于所输入的字符串,不论对错,都应有明确的信息输出。 编译原理课程设计报告 课题名称:编译原理课程设计 C-语言词法与语法分析器的实现 提交文档学生姓名: 提交文档学生学号: 同组成员名单: 指导教师姓名: 指导教师评阅成绩: 指导教师评阅意见: . . 提交报告时间:年月日 C-词法与语法分析器的实现 1.课程设计目标 (1)题目实用性 C-语言拥有一个完整语言的基本属性,通过编写C-语言的词法分析和语法分析,对于理解编译原理的相关理论和知识有很大的作用。通过编写C-语言词法和语法分析程序,能够对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个比较清晰的了解和掌握。(2)C-语言的词法说明 ①语言的关键字: else if int return void while 所有的关键字都是保留字,并且必须是小写。 ②专用符号: + - * / < <= > >= == != = ; , ( ) [ ] { } /* */ ③其他标记是ID和NUM,通过下列正则表达式定义: ID = letter letter* NUM = digit digit* letter = a|..|z|A|..|Z digit = 0|..|9 注:ID表示标识符,NUM表示数字,letter表示一个字母,digit表示一个数字。 小写和大写字母是有区别的。 ④空格由空白、换行符和制表符组成。空格通常被忽略。 ⑤注释用通常的c语言符号/ * . . . * /围起来。注释可以放在任何空白出现的位置(即注释不能放在标记内)上,且可以超过一行。注释不能嵌套。 (3)程序设计目标 能够对一个程序正确的进行词法及语法分析。 2.分析与设计 (1)设计思想 a.词法分析 词法分析的实现主要利用有穷自动机理论。有穷自动机可用作描述在输入串中识别模式的过程,因此也能用作构造扫描程序。通过有穷自动机理论能够容易的设计出词法分析器。b.语法分析 语法分析采用递归下降分析。递归下降法是语法分析中最易懂的一种方法。它的主要原理是,对每个非终结符按其产生式结构构造相应语法分析子程序,其中终结符产生匹配命令,而非终结符则产生过程调用命令。因为文法递归相应子程序也递归,所以称这种方法为递归子程序下降法或递归下降法。其中子程序的结构与产生式结构几乎是一致的。 (2)程序流程图 程序主流程图: 词法分析: 语法分析:编译原理词法分析器语法分析器实验报告
编译原理 语法分析实验二
编译原理-语法分析器-(java完美运行版) - 副本
编译原理实验报告(语法分析器)
TEST语言 -语法分析,词法分析实验报告
词法分析器的实现与设计
词法分析器实验报告
编译原理LL(1)语法分析实验报告
实验二--语法分析-
编译原理实验二语法分析器LL(1)实现
编译原理实验二
词法分析器的设计与实现
词法分析器实验报告
语法分析(自上而下分析)实验报告
编译原理语法分析器实验报告
实验二 语法分析程序设计与实现
编译原理课程设计报告C-语言词法与语法分析器的实现
相关主题
文本预览