
https://www.doczj.com/doc/723015110.html,
网页图片采集方法
网页上有许多我们中意的图片,想把它们都采采集下来,一张张图片的保存效率实在是太低,有没有好的工具可以提升效率?答案是有的。
本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【图片采集】为例,教大家如何使用八爪鱼采集软件采集网页图片的方法。
1、八爪鱼采集器能采集图片吗?
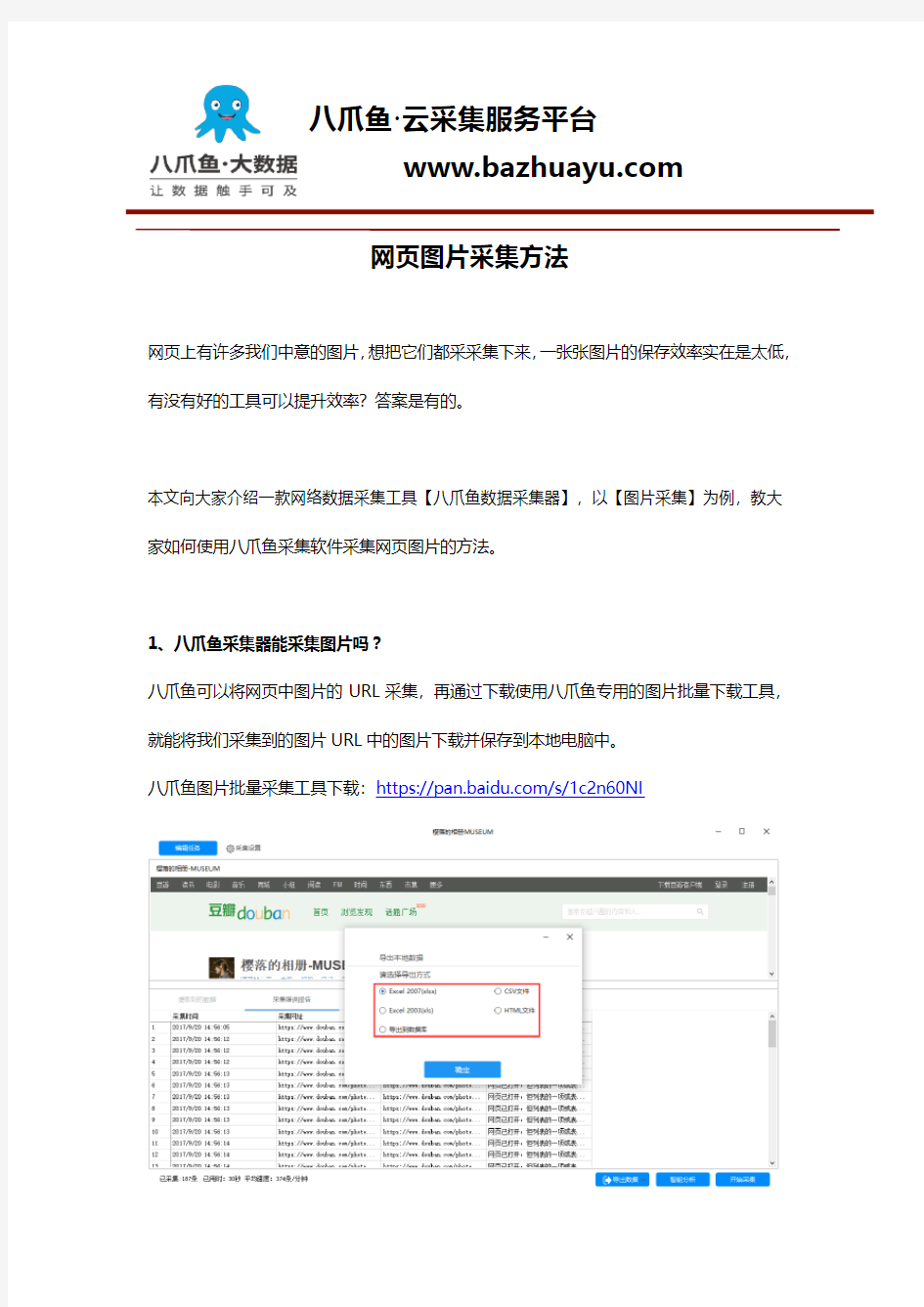
八爪鱼可以将网页中图片的URL采集,再通过下载使用八爪鱼专用的图片批量下载工具,就能将我们采集到的图片URL中的图片下载并保存到本地电脑中。
八爪鱼图片批量采集工具下载:https://https://www.doczj.com/doc/723015110.html,/s/1c2n60NI
https://www.doczj.com/doc/723015110.html,
抓取图片URL
2、如何采集瀑布流网站的图片
瀑布流网站的采集,需要按下面的步骤对采集规则进行设置:
点击采集规则打开网页步骤的高级选项;
勾选页面加载完成后下滚动;
填写滚动的次数及每次滚动的间隔;
滚动方式设置为:直接滚动到底部;
完成上面的规则设置后,接下来的步骤与1相同。
设置Ajax滚动
https://www.doczj.com/doc/723015110.html,
3、八爪鱼批量导出图片工具详细步骤
图片批量下载工具:https://https://www.doczj.com/doc/723015110.html,/s/1c2n60NI
1)下载八爪鱼图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件
2)打开File菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
3)进行相关设置,设置完成后,点击OK即可导入文件
https://www.doczj.com/doc/723015110.html,
选择EXCEL文件:导入你需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表内对应URL的列名称
保存文件夹名:EXCEL中需要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片存放至不同文件夹
如果要把文件保存到文件夹,则路径需要以“\”结尾,例如:“D:\同步\”,如果要下载后按照指定的文件名保存,则需要包含具体的文件名,例如“D:\同步\1.jpg”
如果下载的文件路径和文件名完全一样,则原先存在的文件会被删除
https://www.doczj.com/doc/723015110.html,
4、怎样采集图片中的信息?
八爪鱼暂不支持采集图片里的信息,想要提取图片中的信息,可以在将图片下载下来后,使用网上的图片信息提取工具进行图片信息的提取。
5、采集图片教程中的下载图片工具在哪下载?
八爪鱼的图片批量采集工具:八爪鱼为需要进行图片采集的用户提供的图片采集工具,可以使用八爪鱼采集到的批量图片URL,将图片的URL转化为图片下载到本地。
八爪鱼图片批量采集工具下载:https://https://www.doczj.com/doc/723015110.html,/s/1c2n60NI
6、使用图片下载器下载图片,为什么下载的图片未保存在指定文件夹中?
有些用户在使用八爪鱼的图片下载器下载图片后,发现图片未保存到指定的文件夹中。
原因:在使用图片下载器设置保存路径的时候,少加了“/”,所以导致下载的图片未保存到指定文件夹。
解决方法:在保存路径前添加好“/”即可将下载好的图片保存到指定文件夹中。
相关采集教程:
网站图片采集
https://www.doczj.com/doc/723015110.html,/tutorial/hottutorial/qita/tupian
豆瓣图片采集并下载保存本地的方法
https://www.doczj.com/doc/723015110.html,/tutorial/tpcj-7
https://www.doczj.com/doc/723015110.html,
京东商品图片采集详细教程
https://www.doczj.com/doc/723015110.html,/tutorial/jdpiccj
淘宝买家秀图片采集详细教程
https://www.doczj.com/doc/723015110.html,/tutorial/tbmjxpic
淘宝图片采集并下载到本地的方法
https://www.doczj.com/doc/723015110.html,/tutorial/tbgoodspic
ebay爬虫抓取图片
https://www.doczj.com/doc/723015110.html,/tutorial/ebaypicpc
微博图片采集
https://www.doczj.com/doc/723015110.html,/tutorial/wbpiccj
阿里巴巴图片抓取下载
https://www.doczj.com/doc/723015110.html,/tutorial/alibabapiccj
网站图片采集方法
https://www.doczj.com/doc/723015110.html,/tutorial/webpiccj
瀑布流网站图片采集方法,以百度图片采集为例
https://www.doczj.com/doc/723015110.html,/tutorial/bdpiccj
https://www.doczj.com/doc/723015110.html,
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。配置好采集任务后可关机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。
教你如何提取网页中的视频、音乐歌曲、flash、图片等多媒体文件(很实用) 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件 来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本 上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。不废话了,下面进入主题: 这款免费小软件就是YuanBox(元宝箱)v1.6,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 运行软件,初始界面如下图:
之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定
下面是搜索条件设定界面 以swf格式flash为例,进行搜索,选择类型中的第二项 点击确定,开始搜索,结果如下:
https://www.doczj.com/doc/723015110.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.doczj.com/doc/723015110.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.doczj.com/doc/723015110.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.doczj.com/doc/723015110.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.doczj.com/doc/723015110.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
屏幕截取招招看!教你十种“屏幕图文”抓取方法(图) 分类:电脑应用| 评论:0 | 引用:0 | 浏览:1750 说起屏幕截图,相信大家都不会陌生:随意翻翻每期的《电脑报》,哪篇不是图文并茂?但是对于刚刚接触电脑的朋友来说,对如何进行抓图还摸不着头脑,以为需要什么高深的技术或什么专业的软件,甚至还以为需要动用DC来帮忙呢。其实抓图的方法有很多种,但种种都很简单,看了下面的介绍,相信你也能抓出“美”图来! 一、PrintScreen按键+画图工具 不论你使用的是台式机还是笔记本电脑,在键盘上都有一个PrintScreen按键,但是很多用户不知道它是干什么用的,其实它就是屏幕抓图的“快门”!当按下它以后,系统会自动将当前全屏画面保存到剪贴板中,只要打开任意一个图形处理软件并粘贴后就可以看到了,当然还可以另存或编辑。 提示:PrintScreen键一般位于F12的右侧。 二、抓取全屏 抓取全屏幕的画面是最简单的操作:直接按一下PrintScreen键,然后打开系统自带的“画图”(也可以使用PS),再按下Ctrl+V即可。该处没有什么技术含量,只是要记住防止某些“不速之客”污染了画面,比如输入法的状态条、“豪杰超级解霸”的窗口控制按钮等等。 提示:提醒想投稿的朋友:这样的画面比较大,一般的报纸或杂志要求300像素×300像素,最大不超过500像素×500像素(当然特殊需要除外),这就需要到PS或ACDSee中进行调整。 三、抓取当前窗口 有时由于某种需要,只想抓取当前的活动窗口,使用全屏抓图的方法显然不合适了。此时可以按住Alt键再按下PrintScreen键就可只将当前的活动窗口抓下了。 四、抓取级联菜单 在写稿的过程中,免不了“以图代文”,特别是关于级联菜单的叙述,一张截图胜过千言万语。但是,若想使用抓取当前窗口的方法来抓级联菜单就不行了:当按下Alt键以后菜单就会消失。此时可以直接按下PrintScreen键抓取全屏,然后粘贴到图形处理软件中进行后期的处理。如果使用画图工具,就可以使用方形选定工具将所需要的部分“选定”并“剪切”,然后按下Ctrl+E打开“属性”界面将“宽度”和“高度”中的数值设的很小,最后再粘贴并另存即可(如图1)。 提示:如果“属性”中的数值大于剪切下来的图片,在“粘贴”以后会出现白色的多余背景,因此需要减小其值。
https://www.doczj.com/doc/723015110.html, 网页图片提取方法 对于新媒体运营来说,平日一定要注意积累图片素材,这样到写文案用的时候,才不会临时来照图片,耗费大量的时间。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【图片采集】为例,教大家如何使用八爪鱼采集软件采集网络图片的方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.doczj.com/doc/723015110.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.doczj.com/doc/723015110.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置:
https://www.doczj.com/doc/723015110.html, ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.doczj.com/doc/723015110.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.doczj.com/doc/723015110.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.doczj.com/doc/723015110.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
https://www.doczj.com/doc/723015110.html, 网站图片抓取方法 你是否有过想将网站上看到的图片抓取保存到本地电脑?图片少量时,还可以手动一张张下载,但是图片量巨大时,这个时候手动下载既耗费时间精力,效率又极其低下。遇到这种情况怎么办呢?让八爪鱼来帮你把~只需要在八爪鱼软件中配置相应的流程,图片下载到电脑就是so easy~下面就为大家介绍最全的网站图片抓取方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.doczj.com/doc/723015110.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.doczj.com/doc/723015110.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔;
https://www.doczj.com/doc/723015110.html, ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.doczj.com/doc/723015110.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.doczj.com/doc/723015110.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.doczj.com/doc/723015110.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
如何快速准确的从图片/PDF中获得曲线的数据 Little cai 2013-9-25 图1、带处理的图片(从PDF上截图,jpg格式) 图2、利用读取的数据作图的结果操作流程: 1.首先用截图工具如”FastStone Capture”(网上有序列号,自己搜。这个软件很好用)从文件 中将想要的图片包含坐标轴截取下来,保存为jpg格式; 2.打开getdataw.exe软件(建议从小木虫上下,安全省心.此软件是从图片读数据的首选利 器),双击运行软件; 3.点击”File””Open Image”,导入图片,点击”View””Show Grid”显示网格线;点击放大镜图 标或滚动鼠标中键可放大图像; 4.设置坐标轴的起点和终点(xmin,xmax,ymin,ymax):点击下面的坐标轴选取按钮, 在X坐标轴的起点单击左键,出现对话框,输入选取点的X坐标,在在X坐标轴的终点单击左键,出现对话框,输入选取点的X坐标(xmin,xmax); 然后依次选择Ymin,Ymax.(注意,取点是Ymin先出来,如果0在上面,则Ymin一定是负值,不要忘记加负号,否则图形会倒过来!); 出现对话款,如果没错,点确定;(如果是对数坐标,选中相应的选项再点确定) 5.读点:点击“Point capture mode”按钮,可以从曲线上读入数据点。如果点取的不好,
可以点击橡皮擦图标,擦出错误的点,然后再点“Point capture mode”按钮接着读数。 数据读取完毕,就该保存数据了。 6.保存数据:点击“File”,选择“Export Data”,数据类型为TXT,点“保存”即可。 7.后期处理:关掉软件,不保存(否)。打开origin软件,导入数据,作图,选 “Analysis”,”Interpolate/Extrapolate”进行插值,补足数据点。注意Make curve一栏输入的数值=(最大值-最小值)/公差+ 1。然后就可以得到插值后的数据,还可以对插值得到的数据做进一步拟合等优化处理(当然也可以导出插值的数据直接用了)。 FastStone Capture可以再网上下载,不超过2M的小软件,注册码网上也有。 感谢小木虫学术论坛提供软件支持和百度文库提供软件使用说明,一并感谢女朋友的支持和关怀。本人在以上基础上结合自己的实际操作经验总结出以上教程,如有遗漏错误之处,恳请广大读者赐教。
https://www.doczj.com/doc/723015110.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.doczj.com/doc/723015110.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.doczj.com/doc/723015110.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.doczj.com/doc/723015110.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
教你如何提取网页中的视频(主要flv),音乐,flash,图片 等多媒体文件 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。 工具/原料 这款免费小软件就是YuanBox(元宝箱)v1.6,全称:元宝箱FLV视频下载专家,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 步骤/方法 ○11运行软件,初始界面如下图:
○22之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定 ○33下面是搜索条件设定界面
https://www.doczj.com/doc/723015110.html, 图片爬虫如何使用 目标网站上有许多我们喜欢的图片,想用到自己的工作或生活中去,但苦于工作量太大,图片一张张保存太过耗时耗力,因此总是力不从心。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【ebay】为例,教大家如何使用八爪鱼采集软件采集ebay网站的方法。 可以将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。 采集网站: https://https://www.doczj.com/doc/723015110.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换
https://www.doczj.com/doc/723015110.html, 步骤1:创建采集任务 1)进入主界面,选择“自定义采集” ebay爬虫采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/723015110.html, ebay爬虫采集步骤2 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.doczj.com/doc/723015110.html, ebay爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接” ebay爬虫采集步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
https://www.doczj.com/doc/723015110.html, 最全的网页图片采集方法 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.doczj.com/doc/723015110.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.doczj.com/doc/723015110.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集
https://www.doczj.com/doc/723015110.html, 采集示例:百度网图片采集教程https://www.doczj.com/doc/723015110.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.doczj.com/doc/723015110.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.doczj.com/doc/723015110.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
一、在键盘右上侧有一个键print screen sys rq键(打印屏幕),可以用它将显示屏显示的画面抓下来,复制到“剪贴板”中,然后再把图片粘贴到“画图”、“Photoshop”之类的图像处理软件中,进行编辑处理后保存成图片文件,或粘贴到“Word”、“Powerpoint”、“Wps”等支持图文编辑的应用软件里直接使用。 1、截获屏幕图像 ①将所要截取的画面窗口处于windows窗口的最前方(当前编辑窗口); ②按键盘上的“Print Screen”键,系统将会截取全屏幕画面并保存到“剪贴板”中; ③打开图片处理软件(如“画图”),点击该软件工具栏上的“粘贴”按钮或编辑菜单中的“粘贴”命令,图片被粘贴到该软件编辑窗口中(画布上),编辑图片,保存文件。 或打开(切换到)图文编辑软件(如“Word”、“Powerpoint”等),点击该软件工具栏上的“粘贴”按钮或编辑菜单中的“粘贴”命令,图片被粘贴到编辑窗口中,也可以使用该类软件的图片工具进行编辑。 注意,当粘贴到“画图”中时,可能会弹出一个“剪贴板中的图像比位图大,是否扩大位图?”对话框,此时点击“是”即可。 2、抓取当前活动窗口 我们经常不需要整个屏幕,而只要屏幕中的一个窗口,比如我们要“Word”窗口的图片。按下Alt键,同时按Print Screen即可。 ①将所要截取的窗口处于windows窗口的最前方(即当前编辑窗口); ②同时按下Alt键和“Print Screen”键,系统将会截取当前窗口画面并保存到“剪贴板”中; ③粘贴到图像处理软件中或图文编辑软件中。 二、直接点击Ctrl+Alt+A键,然后可见鼠标的箭头变成彩色的,按住左键移动鼠标选择截图范围,然后在截图内右键鼠标另存为即可,可方便了. 三、用第三方软件如QQ截图:点击聊天框截图---显示彩色鼠标---用其圈定所选目标(右键取消)----双击(单击左键为重新选择)---进入QQ聊天框--右键另存为---到达所到地址 如果想上传则:右键点击图片---编辑---另存为---把保存类型改为JPEG格式即可。 方法1.1 屏幕截图 登陆QQ—→按下“Ctrl+Alt+A”组合键—→按下鼠标左键不放选择截取范围—→用鼠标左键调整截取范围的大小和位置—→截取范围内双击鼠标左键。所截图像保存在系统剪贴板。
实训报告 ------------------------------------------------------------------------------------------------------ 实训项目号及名称:网络工程$002--抓图软件的安装和使用 网络工程$002--抓图软件的安装和使用 §1应用需求问题背景: 抓图软件种类繁多,流行的主要有: 1.hyper snap 2.SuperCapture 是一款非常强大的专业图像捕捉软件。它是中国首届共享软件大赛优秀软件. 3.红蜻蜓抓图精灵(RdfSnap)2005是一款完全免费的专业级屏幕捕捉软件 4.SnagIt:可以抓取七种类型的画面和文本、视频并能从图形文件,剪贴板中抓取; 允许自定义抓图... 5.PicaLoader 是网络抓图软件,全自动化、支持多线程、连结追踪、自动取回图片,并且内建缩图检视浏览器 6.UltarSnap,是一款时下比较流行的抓图软件之一,其体积较小,能满足用户对截图的要求,或许这便是它能成为众人之选的原故。2:详细描述、记录抓图软件的使用规则、方法、技巧和常用指令、热键等。 §2实训目的: 2.1 了解各种抓图软件的功能和区别。 2.2 由于windows7自带抓图软件,所以我学习的是windows7自带的抓图软件。了解其主要功能和使用方法。 §3实训元器件物料:(名称+数量,不论大小,逐一陈列) 笔记本电脑一台(windows系统),windows7自带抓图工具,CamStudio屏幕录像软件 §4实训操作步骤和结果观察:(步骤功能说明+屏幕截图,图文并茂) 1点击开始,选择抓图软件Snipping
https://www.doczj.com/doc/723015110.html, 阿里巴巴图片抓取教程 阿里巴巴网站上有大量质量非常高的商品图片,对我们做市场调研、竞品分析有很大的作用,那么如何才能批量的将他们采集保存下来? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【阿里巴巴】为例,教大家如何使用八爪鱼采集软件采集阿里巴巴商品图片的方法。 采集网站: 使用功能点: ●分页列表及详细信息提取 https://www.doczj.com/doc/723015110.html,/tutorialdetail-1/fylbxq7.html ●AJAX滚动教程 https://www.doczj.com/doc/723015110.html,/tutorialdetail-1/ajgd_7.html
https://www.doczj.com/doc/723015110.html, 步骤1:创建阿里巴巴图片采集任务 1)进入主界面,选择“自定义模式”,点击“立即使用” 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/723015110.html, 步骤2:创建翻页循环 1)系统自动打开网页,进入阿里巴巴“衣服”商品列表页。观察网页结构,当把页面下拉至底部的时候,会加载出一批新的数据,随着我们的下拉,页面会有新的数据加载出来。经过2次下拉加载,此页面达到最底部,出现“下一页”按钮。 所以涉及 Ajax 下拉加载,需要对其进行一些高级选项的设置。点击右上角的“流程“按钮,选中左侧的“打开网页”,打开“高级选项”,勾选“页面加载完成
https://www.doczj.com/doc/723015110.html, 后向下滚动”,设置滚动次数为“5次”,每次间隔“2秒”,滚动方式为“直接滚动到底部”,最后点击“确定” 注意:这里的滚动次数及间隔时间,需要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载很慢,还需根据具体情况进行调整。 具体请看:八爪鱼 7.0教程——AJAX 滚动教程 https://www.doczj.com/doc/723015110.html,/tutorialdetail-1/ajgd_7.html
提取PPT中漂亮背景图片的三种方法 自己制作PPT课件过程中,经常需要用到一些比较好的背景图片,作为教师有必要随时储备一些精美的图片素材备用。网络中的图片虽然很多,但是要找到适合做课件背景的却不容易,一种可行的办法就是从现成课件里提取背景,那么如何提取呢?下面介绍三种可行的方法,与大家共享。 第一种: 最简单省事,就是直接提取人家PPT课件中的背景。 1.启动PowerPoint,打开相应的演示文稿文档。 2.在非文本框和组合内容外的空白处,单击右键选择“保存背景”,选择适当保存位置和对应背景图片名称,即完成背景图片的保存。 说明:此方法对有些PPT文件是不适用的,在非文本框和组合内容外的空白处,单击右键时不出现“保存背景”命令。 第二种: 制作者需要将某个PowerPoint演示文稿中的图片单独提取出来,只要将其另存为网页格式即可。
1.启动PowerPoint,打开相应的演示文稿文档。 2.执行“文件→另存为网页”命令,打开“另存为网页”对话框。 3.将“保存类型”设置为“网页(*.htm*.html)” ,然后取名(如123)保存返回。 4.我们在上述网页文件保存的文件夹中,会找到一个名为“123.files”的文件夹,PPT文件所用的所有图片都是单独保存了文件夹中,包括背景图片。 第三种: 1.先打开课件,找到你喜欢那张背景的幻灯片,然后把它上面的所有文本框等删去,再按幻灯片放映,放到那张背景时,按CTRL+PRINT SCREEN(全屏截取)。 2.找开“画图”(开始---附件)或者其它图片处理程序,按CTRL+V(粘贴)调出截图,另存为JPEG或GIF文件(记住位置)。 3.打开新的幻灯片,右键单击空白处---背景---填充效果---图片---选择图片(找到刚刚保存的那张图片)---确定---应用。
java抓取网页内容三种方式 2011-12-05 11:23 一、GetURL.java import java.io.*; import https://www.doczj.com/doc/723015110.html,.*; public class GetURL { public static void main(String[] args) { InputStream in = null; OutputStream out = null; try { // 检查命令行参数 if ((args.length != 1)&& (args.length != 2)) throw new IllegalArgumentException("Wrong number of args"); URL url = new URL(args[0]); //创建 URL in = url.openStream(); // 打开到这个URL的流 if (args.length == 2) // 创建一个适当的输出流 out = new FileOutputStream(args[1]); else out = System.out; // 复制字节到输出流 byte[] buffer = new byte[4096]; int bytes_read; while((bytes_read = in.read(buffer)) != -1) out.write(buffer, 0, bytes_read); } catch (Exception e) { System.err.println(e); System.err.println("Usage: java GetURL
https://www.doczj.com/doc/723015110.html, 淘宝商品抓取工具使用教程 现在从事电商、微商的人越来越多,竞争越来越激烈,如何才能脱颖而出,无非是做到知己知彼,百战百胜。如何了解你的竞争对手,这里将教您使用一款非常好用的电子商品采集数据工具。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝网】为例,教大家如何使用八爪鱼采集软件采集淘宝网商品信息的方法。 采集网站: https://https://www.doczj.com/doc/723015110.html,/search?q=%E6%89%8B%E8%A1%A8 使用功能点: ●商品Url采集提取 ●创建url循环采集任务 ●商品信息采集 步骤1:创建采集任务 1)进入主界面,选择自定义模式
https://www.doczj.com/doc/723015110.html, 淘宝商品抓取步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/723015110.html, 淘宝商品抓取步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url 是这次演示采集的信息 淘 宝商品抓取步骤3 步骤2:创建翻页循环 找到翻页按钮,设置翻页循环 1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”
https://www.doczj.com/doc/723015110.html, 步骤3:商品url采集 ●选中需要采集的字段信息,创建采集列表 ●编辑采集字段名称 1)如图,移动鼠标选中列表中商品的名称,右键点击,需采集的内容会变成绿色,然后点击“选中全部”
https://www.doczj.com/doc/723015110.html, 淘宝商品抓取步骤5 2)选择“采集以下链接地址” 淘宝商品抓取步骤6
把图片变成文字—图文转换工具方法 第一种方法:用SnagIt工具进行文字提取。 首先使用SnagIt的文字捕捉功能将文字提取出来。SnagIt当前版本为7.02,大小为8903KB,下载地址可以在https://www.doczj.com/doc/723015110.html,/soft/2290.html,汉化补丁可以在https://www.doczj.com/doc/723015110.html,/soft/2291.html。启动SnagIt,选择菜单“输入/区域”,选择菜单“工具/文字捕获”,然后我们打开要捕捉的文件窗口,按下捕捉快捷键,选定捕捉区域即可捕捉到文字。 接着用相应工具重排文字。此时我们发现提取的文字可能会有很多空格或段落错乱等现象,而且字号、字体等不合自己的心意。这时我们可以用熟悉的WPS或Word软件进行重新编排。我们以WPSOffice2003为例看看如何对付提取后文章的编排。 用WPSOffice2003打开提取文章;然后选择“工具”菜单下的“文字”/“段落重排”,这时你会看到提取文章重新进行排版;接下来选择“工具”菜单下的“文字”/“删除段首空格”命令,使得文章的每段参差不齐的行首空格被删除;再选择“工具”菜单下的“文字”/“增加段首空格”,文章变为正常的书写格式;提取文章一般都留有空段,为删除这些空段,继续选择“工具”菜单下的“文字”/“删除空段”命令,这时文
章完全变为我们所要的形式;用你熟悉的界面任意编辑文章吧。 第二种方法:用屏幕截图然后让OCR软件识别。 打开带有文字的图片或电子书籍,翻到你希望提取的页面,点击键盘上的打印屏幕键(PrintScreen)进行屏幕捕获;打开Windows自带的画图工具,将刚才捕获的屏幕截图,粘贴进去,保存为一个.bmp文件;接着打开刚才保存的文件,在编辑器中进行修正,根据你所要提取的文字进行裁剪,尽量去除不要的部分;最后启动OCR软件,在OCR中打开刚才保存的修改文件,进行文字识别,然后可随心所欲进行编辑 https://www.doczj.com/doc/723015110.html,/soft/27951.htm 一个mini OCR软件
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Mvc; using https://www.doczj.com/doc/723015110.html,; using System.IO; using System.Text; using System.Text.RegularExpressions; namespace Syccw.Controllers { public class Get_Url { ///
屏幕截取-教你十种“屏幕图文”抓取方法(图)
屏幕截取招招看!教你十种“屏幕图文”抓取方法(图) 分类:电脑应用| 评论:0 | 引用:0 | 浏览:1750 说起屏幕截图,相信大家都不会陌生:随意翻翻每期的《电脑报》,哪篇不是图文并茂?但是对于刚刚接触电脑的朋友来说,对如何进行抓图还摸不着头脑,以为需要什么高深的技术或什么专业的软件,甚至还以为需要动用DC来帮忙呢。其实抓图的方法有很多种,但种种都很简单,看了下面的介绍,相信你也能抓出“美”图来! 一、PrintScreen按键+画图工具 不论你使用的是台式机还是笔记本电脑,在键盘上都有一个PrintScreen按键,但是很多用户不知道它是干什么用的,其实它就是屏幕抓图的“快门”!当按下它以后,系统会自动将当前全屏画面保存到剪贴板中,只要打开任意一个图形处理软件并粘贴后就可以看到了,当然还可以另存或编辑。 提示:PrintScreen键一般位于F12的右侧。
二、抓取全屏 抓取全屏幕的画面是最简单的操作:直接按一下PrintScreen键,然后打开系统自带的“画图”(也可以使用PS),再按下Ctrl+V即可。该处没有什么技术含量,只是要记住防止某些“不速之客”污染了画面,比如输入法的状态条、“豪杰超级解霸”的窗口控制按钮等等。 提示:提醒想投稿的朋友:这样的画面比较大,一般的报纸或杂志要求300像素×300像素,最大不超过500像素×500像素(当然特殊需要除外),这就需要到PS或ACDSee中进行调整。 三、抓取当前窗口 有时由于某种需要,只想抓取当前的活动窗口,使用全屏抓图的方法显然不合适了。此时可以按住Alt键再按下PrintScreen键就可只将当前的活动窗口抓下了。
https://www.doczj.com/doc/723015110.html, 图片抓取工具使用方法 我们日常工作中经常遇到需要大量提取图片的工作,但一张张的图片保存效率太低,有没有便捷的方法或工具能让我们事半功倍呢? 其实掌握这三大要素:明确图片网站类型、学会使用图片批量下载工具、明确能够/不能够实现的功能,图片采集不再是难事。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,教大家如何使用八爪鱼采集软件抓取图片的方法。 一、明确图片网站的几大类型 1、非瀑布流网站的图片采集 示例网站:豆瓣网 https://https://www.doczj.com/doc/723015110.html,/photos/album/1620960735/?start=0
https://www.doczj.com/doc/723015110.html, 八爪鱼可以对网页中图片的URL进行采集,然后通过专用的图片批量下载工具将URL转化为图片,下载并保存到本地电脑。 2、瀑布流网站的图片采集:直接采集图片地址 示例网站:百度图片网 https://https://www.doczj.com/doc/723015110.html,/search/index?tn=baiduimage&ipn=r&ct=201326592&cl =2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0 &width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word= %E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90 此类网站,需要按下面的步骤对采集规则进行Ajax滚动设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动;
如何导出WORD里面的图片(保持原有的分辨率) 提取图片 如何将WORD里面的图片保存或者导出来,有许多方法。分析了各个方法的优缺点: 方法一:WORD导出。WORD——另存——网页(我的WORD是2007版),将会新产生一个.files文件,里面有原来的两倍图,即保留了原有分辨率及大小的始图及只有72分辨率(WORD固有分辨率)的在WORD里面显示的图。一般情况下,第二份图要小,相当于WORD经过分辨率转化快照出来的图,图片的大小正如在WORD里面放置的大小一样,一般情况与本身图片的大小及分辨率无关。此法能提取原始分辨率图,且可以一次性全部导出。 注若WORD——另存——筛选过的网页,提取的相当于为此法的WORD里面放置的图片大小与分辨率图片。 优点:快捷方便、分辨率高 推荐指数:★★★★★ 方法二:WORD复制。直接在WORD里面,选中后,复制,然后在画版工具或者PS中或者其它WORD或者PPT中。在PS中很明显的发现,默认的图片的分辨率为72(象素丢失明显),且大小与原图的大小一致。与在WORD里面显示大小无关。如果仅仅是为了实现WORD里面图片的再利用,从一个WORD中复制到另一个WORD里面,此方法不失为最快捷方便之法,运用的十分广泛。 优点:快捷方便 推荐指数:★★★★ 方法三、转化到PDF中复制。使用PdfWriter打印机生成PDF文件,然后再Acrobat中用快照或者复制工具都可。提取效果不错,是经常喜欢用PDF人的选择。 优点:图片清晰 推荐指数:★★★ 方法四、截图。用QQ截图或者PRINTSCREAM工具可以将图片截下来,当然想获得好的效果可以先将WORD里面的图片放大到容在整个屏幕上。用QQ聊天时,或者没有办法另存的方法时可以选择此法。 优点:图片清晰、快捷 推荐指数:★★★
EXE格式视频专用加密器提取教程(图)-之一 【目标程序】:PE文件格式.exe 【工具】:EXE格式视频专用加密器 4.0.0323、WinHex14.1SR-3H 【查壳】:Borland Delphi 6.0 - 7.0 [Overlay] 【作者】:liaoyl 当前,互联网上许多教学视频,处于商业目的或作者版权方面原因,一般都进行了加密,本文就EXE格式视频专用加密器加密的视频文件进行解密,仅为象我一样的菜鸟们提供一种破解加密视频的一种方法,算是抛砖引玉,高手掠过。 一、做加密视频: 首先,我们用EXE格式视频专用加密器 4.0.0323工具来制作一个加密视频 创建播放密码
二、下面我们来对EXE格式视频专用加密器提取视频,用下面两种方法得到的视频教程,不需要播放密码。 今天讲解第一种方法:用WinHex14.1SR-3H工具加载加密文件,将鼠标向下拖到最后面,然后向上找到乱码与数字处,按一下数字9,选中前面的4B C7 87 02字节, 右键->编辑->复制选块->16进制数值,这样就将4BC78102复制到剪贴板。然后,把鼠标拖动垂直滚动条到代码的最上面一行的4D5A 50 00,按快捷工具栏上的“查找16进制数值”按钮,并在查找16进制数值窗口的文本框里粘贴上4BC78102代码。
按“确定”按钮后,光标停在0011BA00的4B上,这一行是4组4B C7 87 02代码就是我们前面复制的代码,将02代码选中,右键->选块结尾 把光标拖到最上面一行,选中4D,右键->选块开始 然后,将选中的部分右键->编辑->删除。 再一次“查找16进制数值”按钮,并在查找16进制数值窗口的文本框里粘贴上4BC78102代码。光标停在我们复制4BC78102代码的4B处,右键->选块开始