3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下:
B E
C C A
D C B A E
D A C B C D
E C E E
A D
B
C C A E
D C B
B A
C
D
E A B D D C
C B C E
D B C C B C
D A C B C D
E C E B
B E
C C A
D C B A E
B A
C E E A B
D D C
A D
B
C C A E
D C B
C B C E
D B C C B C
要求:
(1)指出上面的数据属于什么类型。
顺序数据
(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:
接收频率
E16
D17
C32
B21
A14
(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:
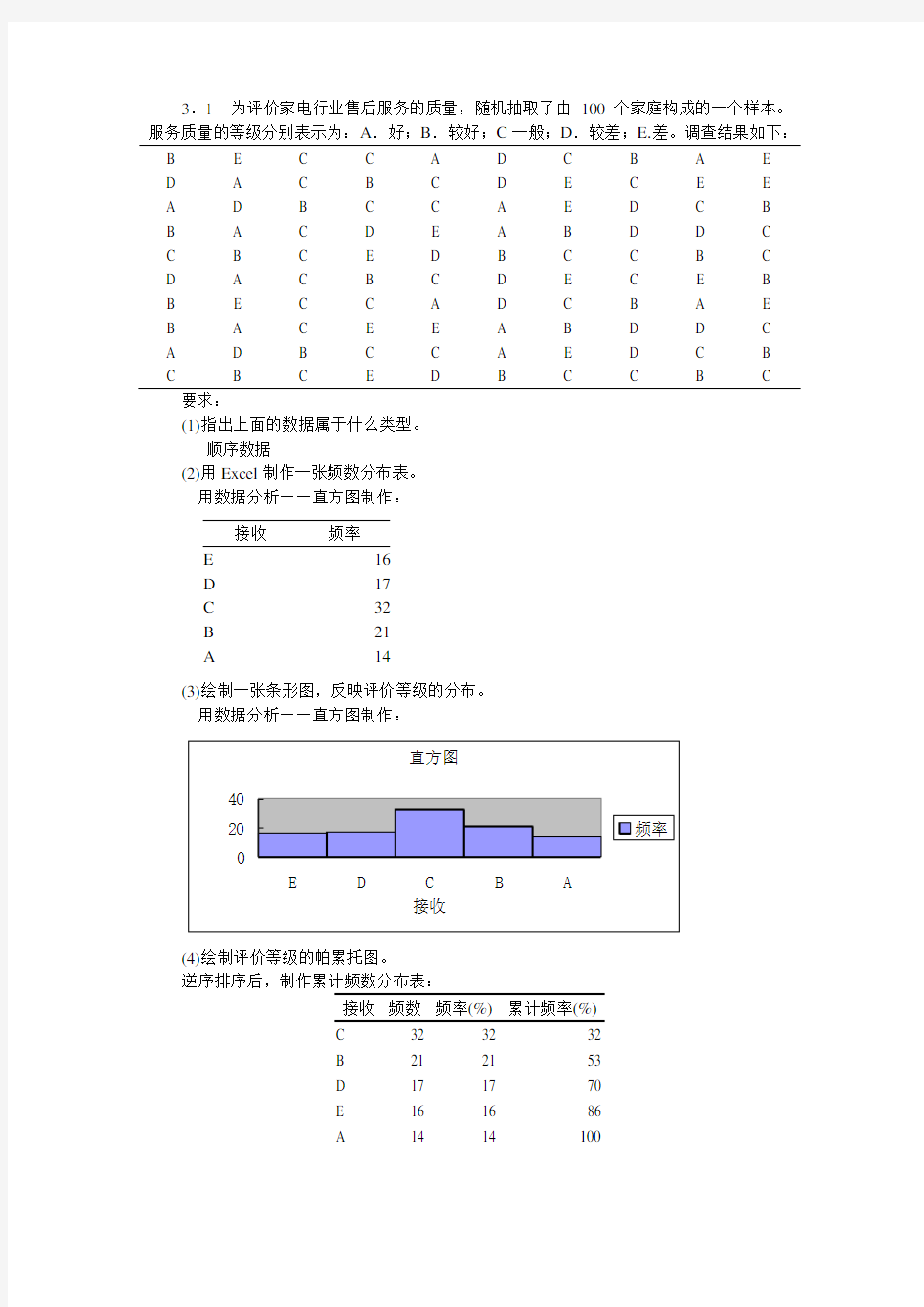
(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:
接收频数频率(%)累计频率(%)
C 32 32 32
B 21 21 53
D 17 17 70
E 16 16 86
A 14 14 100
5101520253035C
D
B
A
E
20406080100120
3.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97
88
123
115
119
138
112
146
113
126
要求:
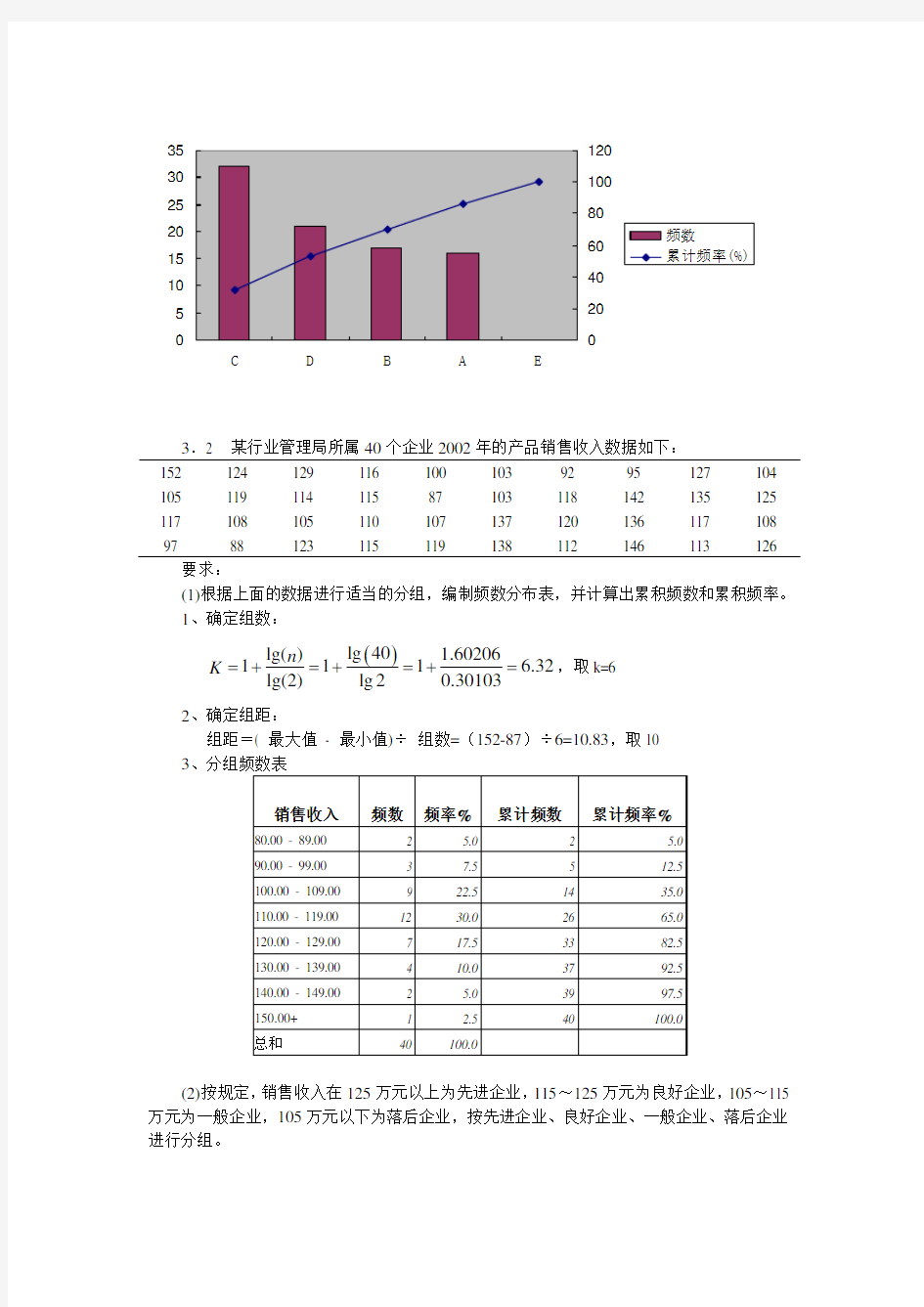
(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。 1、确定组数:
()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103
n K =+
=+=+=,取k=6 2、确定组距:
组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取10 3
(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
3.3 某百货公司连续40天的商品销售额如下:
单位:万元
41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42
36
37
37
49
39
42
32
36
35
要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。 1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103
n K =+
=+=+=,取k=6 2、确定组距:
组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5
3.4 利用下面的数据构建茎叶图和箱线图。
57 29 29 36 31
23 47 23 28 28
35 51 39 18 46
18 26 50 29 33
21 46 41 52 28
21 43 19 42 20
data Stem-and-Leaf Plot
Frequency Stem & Leaf
3.00 1 . 889
5.00 2 . 01133
7.00 2 . 6888999
2.00 3 . 13
3.00 3 . 569
3.00 4 . 123
3.00 4 . 667
3.00 5 . 012
1.00 5 . 7
Stem width: 10 Each leaf: 1 case(s)
3.6一种袋装食品用生产线自动装填,每袋重量大约为50g ,但由于某些原因,每袋重量不会恰好是50g 。下面是随机抽取的100袋食品,测得的重量数据如下:
单位:g
57 46 49 54 55 58 49 61 51 49 51 60 52 54 51 55 60 56 47 47 53 51 48 53 50 52 40 45 57 53 52 51 46 48 47 53 47 53 44 47 50 52 53 47 45 48 54 52 48 46 49 52 59 53 50 43 53 46 57 49 49 44 57 52 42 49 43 47 46 48 51 59 45 45 46 52 55 47 49 50 54 47 48 44 57 47 53 58 52 48 55 53 57 49 56 56 57 53 41 48 要求:
(1)构建这些数据的频数分布表。 (2)绘制频数分布的直方图。 (3)说明数据分布的特征。
解:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数:
()lg 100lg()2111 6.64lg(2)lg 20.30103
n K =+
=+=+=,取k=6或7 2、确定组距:
组距=( 最大值 - 最小值)÷ 组数=(61-40)÷6=3.5,取3或者4、5 组距=( 最大值 - 最小值)÷ 组数=(61-40)÷7=3, 3、分组频数表
组距3,上限为小于
直方图:
组距4,上限为小于等于
直方图:
组距5,上限为小于等于
直方图:
分布特征:左偏钟型。
3.8 下面是北方某城市1——2月份各天气温的记录数据:
-3 2 -4 -7 -11 -1 7 8 9 -6 14 -18 -15 -9 -6 -1 0 5 -4 -9 6 -8 -12 -16 -19 -15 -22 -25 -24 -19 -8 -6 -15 -11 -12 -19 -25 -24 -18 -17 -14
-22
-13
-9
-6
0 -1 5 -4 -9 -3 2 -4 -4 -16 -1
7
5
-6
-5
要求:
(1)指出上面的数据属于什么类型。 数值型数据
(2)对上面的数据进行适当的分组。
1、确定组数:
()lg 60lg() 1.778151111 6.90989lg(2)lg 20.30103
n K =+
=+=+=,取k=7 2、确定组距:
组距=( 最大值 - 最小值)÷ 组数=(14-(-25))÷7=5.57,取5
3
(3)绘制直方图,说明该城市气温分布的特点。
解:
(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
第三章节:数据的图表展示 (1) 第四章节:数据的概括性度量 (15) 第六章节:统计量及其抽样分布 (26) 第七章节:参数估计....................................................... (28) 第八章节:假设检验........................................................ (38) 第九章节:列联分析........................................................ (41) 第十章节:方差分析........................................................ (43) 3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C 要求: (1)指出上面的数据属于什么类型。 顺序数据 (2)用Excel制作一张频数分布表。 用数据分析——直方图制作: 接收频率 E16 D17 C32 B21 A14 (3)绘制一张条形图,反映评价等级的分布。 用数据分析——直方图制作: (4)绘制评价等级的帕累托图。 逆序排序后,制作累计频数分布表:
1. 一家调查公司进行一项调查,其目的是为了了解某市电信营业厅大客户对该 电信的服务的满意情况。调查人员随机访问了30名去该电信营业厅办理业务 的大客户,发现受访的大客户中有9名认为营业厅现在的服务质量较两年前 好。试在95%的置信水平下对大客户中认为营业厅现在的服务质量较两年前 好的比率进行区间估计。 4.据某市场调查公司对某市80名随机受访的购房者的调查得到了该市购房 者中本地人购房比率p 的区间估计,在置信水平为10%下,其允许误差E = 0.08。则: (1)这80名受访者样本中为本地购房者的比率是多少? (2)若显著性水平为95%,则要保持同样的精度进行区间估计,需要调查 多少名购房者。 解:这是一个求某一属性所占比率的区间估计的问题。根据已知n =30,2 /αz =1.96,根据抽样结果计算出的样本比率为%30309?==p 。 总体比率置信区间的计算公式为: ()n p p z p ?1??2/-±α 计算得: ()n p p z p ?1??2/-±α=30%()30 %301%3096.1-??± =(13.60%,46.40%) 5、某大学生记录了他一个月31天所花的伙食费,经计算得出了这个月平均每天 花费10.2元,标准差为2.4元。显著性水平为在5%,试估计该学生每天平 均伙食费的置信区间。 解:由已知:=x 10.2,s =2.4,96.1025.0=z ,则其置信区间为: 314 .296.12.10025.0?±=±n s z x =〔9.36,11.04〕。 该学生每天平均伙食费的95%的置信区间为9.36元到11.04元。
6、据一次抽样调查表明居民每日平均读报时间的95%的置信区间为〔2.2,3.4〕 小时,问该次抽样样本平均读报时间t 是多少?若样本量为100,则样本标准 差是多少?若我想将允许误差降为0.4小时,那么在相同的置信水平下,样 本容量应该为多少? 解:样本平均读报时间为:t = 24.32.2+=2.8 由()96 .121002.24.322.24.305.0?-=?-==s n s z E =3.06 2254 .006.396.122 22205.02=?=?=E s z n 7、某电子邮箱用户一周内共收到邮件56封,其中有若干封是属于广告邮件,并 且根据这一周数据估计广告邮件所占比率的95%的置信区间为〔8.9%, 16.1%〕。问这一周内收到了多少封广告邮件。若计算出了20周平均每周收 到48封邮件,标准差为9封,则其每周平均收到邮件数的95%的置信区间 是多少?(设每周收到的邮件数服从正态分布) 解:本周收到广告邮件比率为:p =2 161.0089.0+=0.125 收到广告邮件数为:n ×p =56×0.125=7封 根据已知:x =48,n =20,s =9,093.2)19(025.0=t ()199 093.24819025.0?±=±n s t x =[43.68,52.32] 8、为了解某银行营业厅办理某业务的办事效率,调查人员观察了该银行营业厅 办理该业务的柜台办理每笔业务的时间,随机记录了15名客户办理业务的时间,测得平均办理时间为t =12分钟,样本标准差为s =4.1分钟,则: (1)其95%的置信区间是多少? (2)若样本容量为40,而观测的数据不变,则95%的置信区间又是多少? 解:(1)根据已知有()145.214025.0=t ,n =15,t =12,s =4.1。 置信区间为:()151 .4145.21214025.0?±=±n s t t =〔9.73,14.27〕
统计学原理第二次作业及答案 题目 总指数的基本形式是() 选择一项: a. 个体指数 b. 平均指数 c. 综合指数 d. 平均指标指数 正确答案是:综合指数 题目 重点调查所选的重点单位,必须是在调查对象中() 选择一项: a. 具有较大标志值的那一部分调查单位 b. 具有代表性的调查单位 c. 按随机原则选出的调查单位 d. 填报调查数据的填报单位 正确答案是:具有较大标志值的那一部分调查单位 题目 连续变量数列、其末组为开口组,下限为1000,其相邻组的组中值为950,则末组的组中值为()(单选) 选择一项: a. 1025 b. 1050 c. 1100 d. 1150 正确答案是:1050
题目 零售物价指数为103%,商品零售量指数为106%,则商品零售额指数为()(单选)选择一项: a. 109% b. 110% c. 103% d. 109.18% 正确答案是:109.18% 题目 下列不属于强度相对指标的指标有() 选择一项: a. 平均单位成本 b. 人口出生率 c. 人口死亡率 d. 人口密度 正确答案是:平均单位成本 题目 时间序列由两个基本要素构成()(多选) 选择一项或多项: a. 时间,即现象所属的时间 b. 指标数值,即表现现象特点的各项指标数值 c. 指标名称 d. 计量单位 e. 计算公式 正确答案是:时间,即现象所属的时间, 指标数值,即表现现象特点的各项指标数值
题目 以下分组标志中属于品质标志的是()(多选) 选择一项或多项: a. 性别 b. 年龄 c. 职业 d. 月收入 e. 职称 正确答案是:性别, 职业, 职称 题目 在时间序列中,各指标值相加后无意义的有()(多选)选择一项或多项: a. 时期数列 b. 时点数列 c. 绝对数时间序列 d. 相对数时间序列 e. 平均数时间序列 正确答案是:时点数列, 相对数时间序列, 平均数时间序列 题目 我国财政收入,比上年增加2787亿元,这是()(单选)选择一项: a. 发展水平 b. 增长量 c. 发展速度 d. 增长速度
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
《统计学》第二次作业 注:本次作业主要针对4、6、8章相关知识点。 一、单选题(共11个) 1. 直接反映总体规模大小的指标是( C )。 A、平均指标 B、相对指标 C、总量指标 D、变异指标 2.计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和( C )。 A、小于100% B、大于100% C、等于100% D、小于或大于100% 3.下列相对数中,属于不同时期对比的指标有( B )。 A、结构相对数 B、动态相对数 C、比较相对数 D、强度相对数 4. 2010年某市下岗职工已安置了13.7万人,安置率达80.6%,安置率是( D )。 A、总量指标 B、变异指标 C、平均指标 D、相对指标 5.根据同一资料计算的数值平均数通常是各不相同的,他们之间的关系是( D )。 A. 算术平均数≥几何平均数≥调和平均数 B. 几何平均数≥调和平均数≥算术平均数 C. 调和平均数≥算术平均数≥几何平均数 D. 没有关系 6.指数是表明现象变动的( B ) A. 绝对数 B. 相对数 C. 平均数 D. 抽样数 7.编制数量指标指数一般是采用( A )作为同度量因素。 A. 基期质量指标 B. 报告期质量指标 C. 基期数量指标 D. 报告期数量指标 8.价格下降后,花同样多的钱可以多购买基期商品的10%,则物价指数为( B ) A. 90% B. 90.9% C. 110% D. 111.1% 9.消费价格指数反映了( D ) A. 城乡商品零售价格的变动趋势 B. 城乡居民购买生活消费品价格的变动趋势 C. 城乡居民购买服务项目价格的变动趋势 D. 城乡居民购买生活消费品和服务项目价格的变动趋势 10.变量x与y之间的负相关是指( C ) A. x数值增大时y也随之增大 B. x数值减少时y也随之减少 C. x数值增大(或减少)y随之减少(或增大) D. y的取值几乎不受x取值的影响 11.如果相关系数为0,表明两个变量之间( C ) A. 相关程度很低 B. 不存在任何关系 C. 不存在线性相关关系 D. 存在非线性相关关系 二、多选题(共7个) 1.时期指标的特点是指标的数值( ADE )。
288 Chapter 8: Confidence Interval Estimation CHAPTER 8 8.1 X ±Z ?σ n = 85±1.96? 864 83.04 ≤μ≤ 86.96 8.2 X ±Z ? σ n = 125±2.58?24 36 114.68 ≤μ≤ 135.32 8.3 If all possible samples of the same size n are taken, 95% of them include the true population average monthly sales of the product within the interval developed. Thus you are 95 percent confident that this sample is one that does correctly estimate the true average amount. 8.4 Since the results of only one sample are used to indicate whether something has gone wrong in the production process, the manufacturer can never know with 100% certainty that the specific interval obtained from the sample includes the true population mean. In order to have 100% confidence, the entire population (sample size N ) would have to be selected. 8.5 To the extent that the sampling distribution of sample means is approximately normal, it is true that approximately 95% of all possible sample means taken from samples of that same size will fall within 1.96 times the standard error away from the true population mean. But the population mean is not known with certainty. Since the manufacturer estimated the mean would fall between 10.99408 and 11.00192 inches based on a single sample, it is not necessarily true that 95% of all sample means will fall within those same bounds. 8.6 Approximately 5% of the intervals will not include the true population. Since the true population mean is not known, we do not know for certain whether it is contained in the interval (between 10.99408 and 11.00192 inches) that we have developed. 8.7 (a) X ±Z ?σ n =0.995±2.58? 0.02 50 0.9877≤μ≤1.0023 (b) Since the value of 1.0 is included in the interval, there is no reason to believe that the mean is different from 1.0 gallon. (c) No. Since σ is known and n = 50, from the Central Limit Theorem, we may assume that the sampling distribution of X is approximately normal. (d) The reduced confidence level narrows the width of the confidence interval. X ±Z ? σ n =0.995±1.96? 0.02 50 0.9895≤μ≤1.0005 (b) Since the value of 1.0 is still included in the interval, there is no reason to believe that the mean is different from 1.0 gallon.
1中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学 考试科目:统计思想综述 课程代码:123201 考题卷号:1
除不能导致SSE显著减小为止。 逐步回归:结合向前选择和向后剔除,从没有自变量开始,不停向模型中增加自变量,每增加一个自变量就对所有现有的自变量进行考察,若某个自变量对模型的贡献变得不显著就剔除。如此反复, 直到增加变量不能导致SSE显著减少为止。 五、(20分)如果一个时间序列包含趋势、季节成分、随机波动, 适用的预测方法有哪些?对这些方法做检验说明。 可以使用Winter指数平滑模型、引入季节哑变量的多元回归和分解 法等进行预测。 (1)Winter指数平滑模型 包含三个平滑参数,即(取值均在0~1),以及平滑值、趋势项更新、季节项更新、未来第k期的预测值。 L为季节周期的长度,对于季度数据,L=4,对于月份数据,L=12;I为季节调节因子。平滑值消除季节变动,趋势项更新是对趋势值得修正,季节项更新是t期的季节调整因子, 是用于预测的模型。 使用Winter 模型进行预测,要求数据至少是按季度或月份收集的,而且需要有四个以上的季节周期(4年以上的数据)。 使用Winter 模型进行预测,要求数据至少是按季度或月份收集的,
而且需要有四个以上的季节周期(4年以上的数据)。 (2)引入季节哑变量的多元回归 对于以季度记录的数据,引入3个哑变量 ,其中=1(第1季度)或0(其他季度),以此类推,则季节性多元回归模型表示为: 其中b0是常数项,b1是趋势成分的系数,表示趋势给时间序列带来的影响,b2、b3、b4表示每一季度与参照的第1季度的平均差值。(3)分解预测 第1步,确定并分离季节成分。计算季节指数,然后将季节成分从 时间序列中分离出去,即用每一个时间序列观测值除以相应的季节指数以消除季节性。 第2步,建立预测模型并进行预测。对消除了季节成分的时间序列建立适当的预测模型,并根据这一模型进行预测。 第3步,计算出最后的预测值。用预测值乘以相应的季节指数,得到最终的预测值。
附录:教材各章习题答案 第1章统计与统计数据 1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5) 分类数据。 1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家庭”; (2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。 1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物者 的月平均花费;(4)统计量;(5)推断统计方法。 1.5(略)。 1.6(略)。 第2章数据的图表展示 2.1(1)属于顺序数据。 (2)频数分布表如下 (4)帕累托图(略)。 2.2(1)频数分布表如下
2.3 2.5(1)排序略。 (2)频数分布表如下 (4)茎叶图如下
2.6 (3)食品重量的分布基本上是对称的。 2.7 2.8(1)属于数值型数据。
2.9 (1)直方图(略)。 (2)自学考试人员年龄的分布为右偏。 布比A 班分散, 且平均成绩较A 班低。 2.11 (略)。 2.12 (略)。 2.13 (略)。 2.14 (略)。 2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量 3.1 (1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。 (3)2.4=s 。 (4)左偏分布。 3.2 (1)190=M ;23=e M 。 (2)5.5=L Q ;12=U Q 。 (3)24=x ;65.6=s 。 (4)08.1=SK ;77.0=K 。 (5)略。 3.3 (1)略。 (2)7=x ;71.0=s 。 (3)102.01=v ;274.02=v 。 (4)选方法一,因为离散程度小。 3.4 (1)x =274.1(万元);M e=272.5 。 (2)Q L =260.25;Q U =291.25。 (3)17.21=s (万元)。 3.5 甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原 因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。 3.6 (1)x =426.67(万元);48.116=s (万元)。 (2)203.0=SK ;688.0-=K 。 3.7 (1)(2)两位调查人员所得到的平均身高和标准差应该差不多相 同,因为均值和标准差的大小基本上不受样本大小的影响。 (3)具有较大样本的调查人员有更大的机会取到最高或最低者,因为样本越大,变化的范围就可能越大。 3.8 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于男生 体重的离散系数0.08。 (2) 男生:x =27.27(磅),27.2=s (磅); 女生:x =22.73(磅),27.2=s (磅); (3)68%; (4)95%。 3.9 通过计算标准化值来判断,1=A z ,5.0=B z ,说明在A项测试中 该应试者比平均分数高 出1个标准差,而在B 项测试中只高出平均分数0.5个标准差,由于A 项测试的标准化值高于B 项测试,所以A 项测试比较理想。 3.10 通过标准化值来判断,各天的标准化值如下表 日期 周一 周二 周三 周四 周五 周六 周日 标准化值Z 3 -0.6 -0.2 0.4 -1.8 -2.2 0 周一和周六两天失去了控制。
习题 2.1 (1)简单频数分布表: > load("D:\\工作总结\\人大\\R语言\\《统计学—基于R》(第3版)—例题和习题数据(公开资源)\\exercis e\\ch2\\exercise2_1.RData") > summary(exercise2_1) 行业性别满意度 电信业:38 男:58 不满意:75 航空业:19 女:62 满意 :45 金融业:26 旅游业:37 二维列联表: > mytable1<-table(exercise2_1$行业,exercise2_1$满意度) > addmargins(mytable1) # 增加边界和 不满意满意 Sum 电信业 25 13 38 航空业 12 7 19 金融业 11 15 26 旅游业 27 10 37 Sum 75 45 120 三维列联表: > mytable1<-ftable(exercise2_1, row.vars = c("性别","满意度"), col.var="行业");mytable1 行业电信业航空业金融业旅游业 性别满意度 男不满意 11 7 7 11 满意 6 3 7 6 女不满意 14 5 4 16 满意 7 4 8 4 (2) 条形图: > count1<-table(exercise2_1$行业) > count2<-table(exercise2_1$性别) > count3<-table(exercise2_1$满意度) > par(mfrow=c(1,3),mai=c(0.7,0.7,0.6,0.1),cex=0.7,cex.main=0.8) > barplot(count1,xlab="行业",ylab="频数") > barplot(count2,xlab="性别",ylab="频数") > barplot(count3,xlab="满意度",ylab="频数")
统计学作业2 单项选择题 第1题某地区有10万人口,共有80个医院。平均每个医院要服务1250人,这个指标是()。 A、平均指标 B、强度相对指标 C、总量指标 D、发展水平指标 答案:B 第2题某企业2002年工业总产值比1992年增长了3倍,则该公司1992-2002年间工业总产值平均增长速度为() A、11.61% B、14.87% C、13.43% D、16.65% 答案:A 第3题某工业企业的某种产品成本,第一季度是连续下降的。1月份产量750件,单位成本20元;2月份产量1000件,单位成本18元;3月份产量1500件,单位成本15元。则第一季度的平均成本为()。 A、17.67 B、17.54 C、17.08 D、16.83 答案:C 第4题已知4个水果商店苹果的单价和销售额,要求计算4个商店苹果的平均单价,应该采用()。 A、简单算术平均数 B、加权算术平均数 C、加权调和平均数 D、几何平均数 答案:C
第5题如果分配数列把频数换成频率,那么方差()。 A、不变 B、增大 C、减小 D、无法预期变化 答案:A 第6题某厂5年的销售收入如下:200万、220万、250万、300万、320万,则平均增长量为()。 A、120/5 B、120/4 C、320/200的开5次方 D、320/200的开4次方 答案:B 第7题直接反映总体规模大小的指标是()。 A、平均指标 B、相对指标 C、总量指标 D、变异指标 答案:C 第8题计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和()。 A、小于100% B、大于100% C、等于100% D、小于或大于100% 答案:C 多项选择题 第9题下列统计指标属于总量指标的是()。 A、工资总额
第3章 概率与概率分布——练习题(全免) 1 .解:设A =女性,B =工程师,AB =女工程师,A+B =女性或工程师 (1)P(A)=4/12=1/3 (2)P(B)=4/12=1/3 (3)P(AB)=2/12=1/6 (4)P(A+B)=P(A)+P(B)-P(AB)=1/3+1/3-1/6=1/2 4. 某项飞碟射击比赛规定一个碟靶有两次命中机会(即允许在第一次脱靶后进行第二次射击)。某射击选手第一发命中的可能性是80%,第二发命中的可能性为50%。求该选手两发都脱靶的概率。 解:设A =第1发命中。B =命中碟靶。求命中概率是一个全概率的计算问题。再利用对立事件的概率即可求得脱靶的概率。 )|()()|()()(A B P A P A B P A P B P += =0.8×1+0.2×0.5=0.9 脱靶的概率=1-0.9=0.1 或(解法二):P (脱靶)=P (第1次脱靶)×P(第2次脱靶)=0.2×0.5=0.1 8.已知某地区男子寿命超过55岁的概率为84%,超过70岁以上的概率为63%。试求任一刚过55岁生日的男子将会活到70岁以上的概率为多少? 解: 设A =活到55岁,B =活到70岁。所求概率为: ()()0.63(|)0.75()()0.84 P AB P B P B A P A P A ==== 9.某企业决策人考虑是否采用一种新的生产管理流程。据对同行的调查得知,采用新生产管理流程后产品优质率达95%的占四成,优质率维持在原来水平(即80%)的占六成。该企业利用新的生产管理流程进行一次试验,所生产5件产品全部达到优质。问该企业决策者会倾向于如何决策? 解:这是一个计算后验概率的问题。 设A =优质率达95%,A =优质率为80%,B =试验所生产的5件全部优质。 P(A)=0.4,P (A )=0.6,P (B|A )=0.955, P(B |A )=0.85,所求概率为: 6115.050612 .030951.0)|()()|()()|()()|(===A B P A P A B P A P A B P A P B A P + 决策者会倾向于采用新的生产管理流程。 10. 某公司从甲、乙、丙三个企业采购了同一种产品,采购数量分别占总采购量的25%、30%和45%。这三个企业产品的次品率分别为4%、5%、3%。如果从这些产品中随机抽出一件,试问:(1)抽出次品的概率是多少?(2)若发现抽出的产品是次品,问该产品来自丙厂的概率是多少? 解:令A 1、A 2、A 3分别代表从甲、乙、丙企业采购产品,B 表示次品。由题意得:P (A 1)=0.25,P (A 2)=0.30, P (A 3)=0.45;P (B |A 1)=0.04,P (B |A 2)=0.05,P (B |A 3)=0.03;因此,所求概率分别为:
教育统计学课后练习参考答案 第一章 1、教育统计学,就是应用数理统计学的一般原理和方法,对教育调查和教育实验等途径所获得的数据资料进行整理、分析,并以此为依据,进行科学推断,从而揭示蕴含在教育现象中的客观规律的一门科学。 教育统计学既是统计科学中的一个分支学科,又是教育科学中的一个分支学科,是两种科学相互结合、相互渗透而形成的一门交叉学科。从学科体系来看,教育统计学属于教育科学体系的一个方法论分支;从学科性质来看,教育统计学又属于统计学的一个应用分支。 2、描述统计主要是通过对数据资料进行整理,计算出简单明白的统计量数来描述庞大的资料,以显示其分布特征的统计方法。 推断统计又叫分析统计,它根据统计学的原理和方法,从我们所研究的全体对象(即总体)中,按照等可能性原则采取随机抽样的方法,抽出总体中具有代表性的部分个体组成样本,在样本所提供的数据的基础上,运用概率理论进行分析、论证,在一定可靠程度上对总体的情况进行科学推断的一种统计方法。 3、在自然界或教育研究中,一种事物常存在几种可能出现的情况或获得几种可能的结果,这类现象称为随机现象。 随机现象具的特点: (1)一次条件完全相同的实验有多种可能的结果(这样的实验称为随机实验); (2)在实验之前不能确切知道哪种结果会发生; (3)在相同的条件下可以重复进行这样的实验。 4、总体,也叫做母体或全域,是指具有某种共同特征的个体的总和。 当所研究的总体数量非常大时,可以从总体中抽取其中一部分个体来观测,由此来推断总体的信息,从总体中抽出的这部分个体就称为样本,它是用以表征总体的个体的集合。 通常将样本中样本个数大于或等于30个的样本称为大样本,小于30个的称为小样本。 5、复置抽样指每次抽出的个体经观测后,仍放回原总体,然后再从总体中抽取下一个个体。 6、反映总体特征的量数叫做总体参数,简称参数。反映样本特征的量数叫做样本统计量,简称统计量。 参数是总体的真正数值,是固定的常量,理论上应该通过计算总体中全部个体的数值而获得,但由于总体中个体的数量通常很大,总体参数往往很难获得,在统计分析中一般通过样本的数值来估计。在进行推断统计时,就是根据样本统计量来推断总体相应的参数。 第二章 1、按照数据的来源,可分为计数数据和度量数据;按照数据的取值情况,可分为间断性数据和连续性数据;按照数据的测量水平,可分为称名数据、顺序数据、等距数据和比率数据。 2、数据整理的基本方法包括对数据进行排序、统计分组、绘制统计图表等。 3、表的结构要简洁明了;表的层次要清晰;主谓分明。 4、连续性数据:(2),(3);间断性数据:(1),(4)。 5、略 6、(1)50;(2)75;(3)34;(4)5;(5)45
统计课后思考题答案 第一章思考题 1.1什么是统计学 统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。 1.2解释描述统计和推断统计 描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。 推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。 1.3统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 1.4解释分类数据,顺序数据和数值型数据 答案同1.3 1.5举例说明总体,样本,参数,统计量,变量这几个概念 对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 1.6变量的分类
《统计学原理》作业(三) (第五~第七章) 一、判断题 1、抽样推断是利用样本资料对总体的数量特征进行估计的一种统计分析方法,因此不可避免的会产生误差,这种误差的大小是不能进行控制的。(×) 2、从全部总体单位中按照随机原则抽取部分单位组成样本,只可能组成一个样本。(×) 3、抽样估计的置信度就是表明抽样指标和总体指标的误差不超过一定范围的概率保证程度。(√) 4、在其它条件不变的情况下,提高抽样估计的可靠程度,可以提高抽样估计的精确度。(×) 5、抽样极限误差总是大于抽样平均误差。(×) 6、相关系数是测定变量之间相关关系的唯一方法(×) 7、甲产品产量与单位成本的相关系数是-0.8,乙产品单位成本与利润率的相关系数是-0.95,则乙比甲的相关程度高(√)。 8、利用一个回归方程,两个变量可以互相推算(×)。 9、估计标准误指的就是实际值y与估计值y c的平均误差程度(√)。 10、抽样误差即代表性误差和登记性误差,这两种误差都是不可避免的。(×) 11、总体参数区间估计必须具备的三个要素是估计值、抽样误差范围、概率保证程度。(√) 12、在一定条件下,施肥量与收获率是正相关关系。(√) 二、单项选择题 1、在一定的抽样平均误差条件下(A)。 A、扩大极限误差范围,可以提高推断的可靠程度 B、扩大极限误差范围,会降低推断的可靠程度 C、缩小极限误差范围,可以提高推断的可靠程度 D、缩小极限误差范围,不改变推断的可靠程度 2、反映样本指标与总体指标之间的平均误差程度的指标是(C)。 A、抽样误差系数 B、概率度 C、抽样平均误差 D、抽样极限误差 3、抽样平均误差是(C)。 A、全及总体的标准差 B、样本的标准差 C、抽样指标的标准差 D、抽样误差的平均差 4、当成数等于(C)时,成数的方差最大。 A、1 B、0 c、0.5 D、-1 5、对某行业职工收入情况进行抽样调查,得知其中80%的职工收入在800元以下,抽样平均误差为2%,当概率为95.45%时,该行业职工收入在800元以下所占比重是(C)。 A、等于78% B、大于84% c、在此76%与84%之间D、小于76% 6、对甲乙两个工厂工人平均工资进行纯随机不重复抽样调查,调查的工人数一样,两工厂工资方差相同,但甲厂工人总数比乙厂工人总数多一倍,则抽样平均误差(A)。 A、甲厂比乙厂大 B、乙厂比甲厂大 C、两个工厂一样大 D、无法确定
《统计学》第二次作业 注:本次作业主要针对4、6、8章相关知识点。 一、单选题(共11个) 1、直接反映总体规模大小得指标就是( C )。 A、平均指标 B、相对指标 C、总量指标 D、变异指标 2、计算结构相对指标时,总体各部分数值与总体数值对比求得得比重之与( C )。 A、小于100% B、大于100% C、等于100% D、小于或大于100% 3、下列相对数中,属于不同时期对比得指标有( B )。 A、结构相对数 B、动态相对数 C、比较相对数 D、强度相对数 4、 2010年某市下岗职工已安置了13、7万人,安置率达80、6%,安置率就是( D )。 A、总量指标 B、变异指标 C、平均指标 D、相对指标 5、根据同一资料计算得数值平均数通常就是各不相同得,她们之间得关系就是( D )。 A、算术平均数≥几何平均数≥调与平均数 B、几何平均数≥调与平均数≥算术平均数 C、调与平均数≥算术平均数≥几何平均数 D、没有关系 6、指数就是表明现象变动得( B ) A、绝对数 B、相对数 C、平均数 D、抽样数 7、编制数量指标指数一般就是采用( A )作为同度量因素。 A、基期质量指标 B、报告期质量指标 C、基期数量指标 D、报告期数量指标 8、价格下降后,花同样多得钱可以多购买基期商品得10%,则物价指数为( B ) A、 90% B、 90、9% C、 110% D、 111、1% 9、消费价格指数反映了( D ) A、城乡商品零售价格得变动趋势 B、城乡居民购买生活消费品价格得变动趋势 C、城乡居民购买服务项目价格得变动趋势 D、城乡居民购买生活消费品与服务项目价格得变动趋势 10、变量x与y之间得负相关就是指( C ) A、 x数值增大时y也随之增大 B、 x数值减少时y也随之减少 C、 x数值增大(或减少)y随之减少(或增大) D、 y得取值几乎不受x取值得影响 11、如果相关系数为0,表明两个变量之间( C ) A、相关程度很低 B、不存在任何关系 C、不存在线性相关关系 D、存在非线性相关关系 二、多选题(共7个) 1、时期指标得特点就是指标得数值( ADE )。
第1章统计和统计数据 1.1 指出下面的变量类型。(1)年龄。(2)性别。(3)汽车产量。 (4)员工对企业某项改革措施的态度(赞成、中立、反对)。(5)购买商品时的支付方式(现金、信用卡、支票)。详细答案:(1)数值变量。(2)分类变量。(3)数值变量。(4)顺序变量。(5)分类变量。 1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。 (1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案: (1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。(2)数值变量。 (3)分类变量。 1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。 (1)这一研究的总体是什么? (2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。(2)分类变量。 1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。 (1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。(2)100。
第3章用统计量描述数据
偏度 1.08 极差26 最小值15 最大值41 从集中度来看,网民平均年龄为24岁,中位数为23岁。从离散度来看,标准差在为6.65岁,极差达到26岁,说明离散程度较大。从分布的形状上看,年龄呈现右偏,而且偏斜程度较大。 3.2 某银行为缩短顾客到银行办理业务等待的时间,准备采用两种排队方式进行试验。一种是所有顾客都进入一个等待队列;另一种是顾客在3个业务窗口处列队3排等待。为比较哪种排队方式使顾客等待的时间更短,两种排队方式各随机抽取9名顾客,得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下: 5.5 6.6 6.7 6.8 7.1 7.3 7.4 7.8 7.8 (1)计算第二种排队时间的平均数和标准差。 (2)比两种排队方式等待时间的离散程度。 (3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。 详细答案: (1)(岁);(岁)。 (2);。第一中排队方式的离散程度大。 (3)选方法二,因为平均等待时间短,且离散程度小。
(0282)《教育统计学》网上作业题及答 案 1:第一批次 2:第二批次 3:第三批次 4:第四批次 5:第五批次 1:[判断题] 要了解一组数据的离散程度,需计算该组数据的差异量。 参考答案:正确 一、名词解释题 1、自学辅导模式是在教师指导下,学生自己独立进行学习的模式。 2、教学过程就是以师生相互作用的形式进行的,以教科书为主要认识对象的,实现教学、发展和教育三大功能和谐统一的特殊认识和实践活动过程。 3、个别化教学是为满足每个学生的需要、兴趣和能力而设计的一种教学组织形式。 4、微型课程是一种容量很小的课程,它一般是作为短期的选修课程,是建立在教师和学生兴趣的基础上,强调深度而不强调广度的课程。 二、简答题 1、在“教”和“学”这一主要矛盾中,矛盾的主要方面是“学”,即学生的学是教学中的关键问题,教师的教应围绕学生的学展开。在教学过程中,只有通过学生自身的学习活动才能达到教学目标,其他任何人无法替代学生的认知活动和情感体验。学生唯有通过自己的独立思考才能认识客观世界、认识社会,把课程、教材中的知识结构转化、纳入到自身的认知结构中去;学生唯有发挥主观积极性,才能在主动探究的学习中锻炼自己,发挥自己的才能;学生唯有经过自己的体验,才能树立正确的世界观、人生观、价值观。 2、班级教学的不足: 由于学生人数众多,教学活动往往需要教师加强控制,因此学生的独立性、创新精神和创新能力的发展受到限制。 教学面向全班学生,步调一致,难以照顾学生的个别差异,不利于因材施教,不利于发展学生的个性 由于班级教学常常采用教师讲授、学生接受的教学方法,虽然对学生掌握系统的科学文化知识有利,但对于实践能力的培养不利。 3、教学环境具有导向功能、凝聚功能、陶冶功能、激励功能、健康功能、美育功能。 4、布置有意义的学习任务。学习任务应该与学生的知识水平、理解水平、经验水平相适应;学习任务应该与训练目标相关,学生完成学习任务的过程应该是巩固新知识的过程;学习任务应该是积极有效的。 布置学习任务应该注意新旧知识的联系。 学习任务的内容与形式应该多样化。 针对学生不同的能力水平,布置不同的学习任务 三、判断说理题