
X2检验
X2检验是用途广泛的假设检验方法,它的原理是检验实际分布和理论分布的吻合程度。主要用途有:两个及以上样本率(或构成比)之间差异比较,推断两变量间有无相关关系,检验频数分布的拟合优度。X2检验类型有:四格表资料X2检验(用于两样本率的检验),行×列表X2检验(用于两个及两个以上样本率或构成比的检验), 行×列列联表X2检验(用于计数资料的相关分析)。在SPSS中,所有X2检验均用Crosstabs完成。
Crosstabls过程用于对计数资料和有序分类资料进行统计描述和统计推断。在分析时可以产生二维至n维列联表,并计算相应的百分数指标。统计推断则包括了我们常用的X2检验、Kappa值,分层X2(X2M-H)。如果安装了相应模块,还可计算n维列联表的确切概率(Fisher's Exact Test)值。Crosstabs过程不能产生一维频数表(单变量频数表),该功能由Frequencies 过程实现。
界面说明
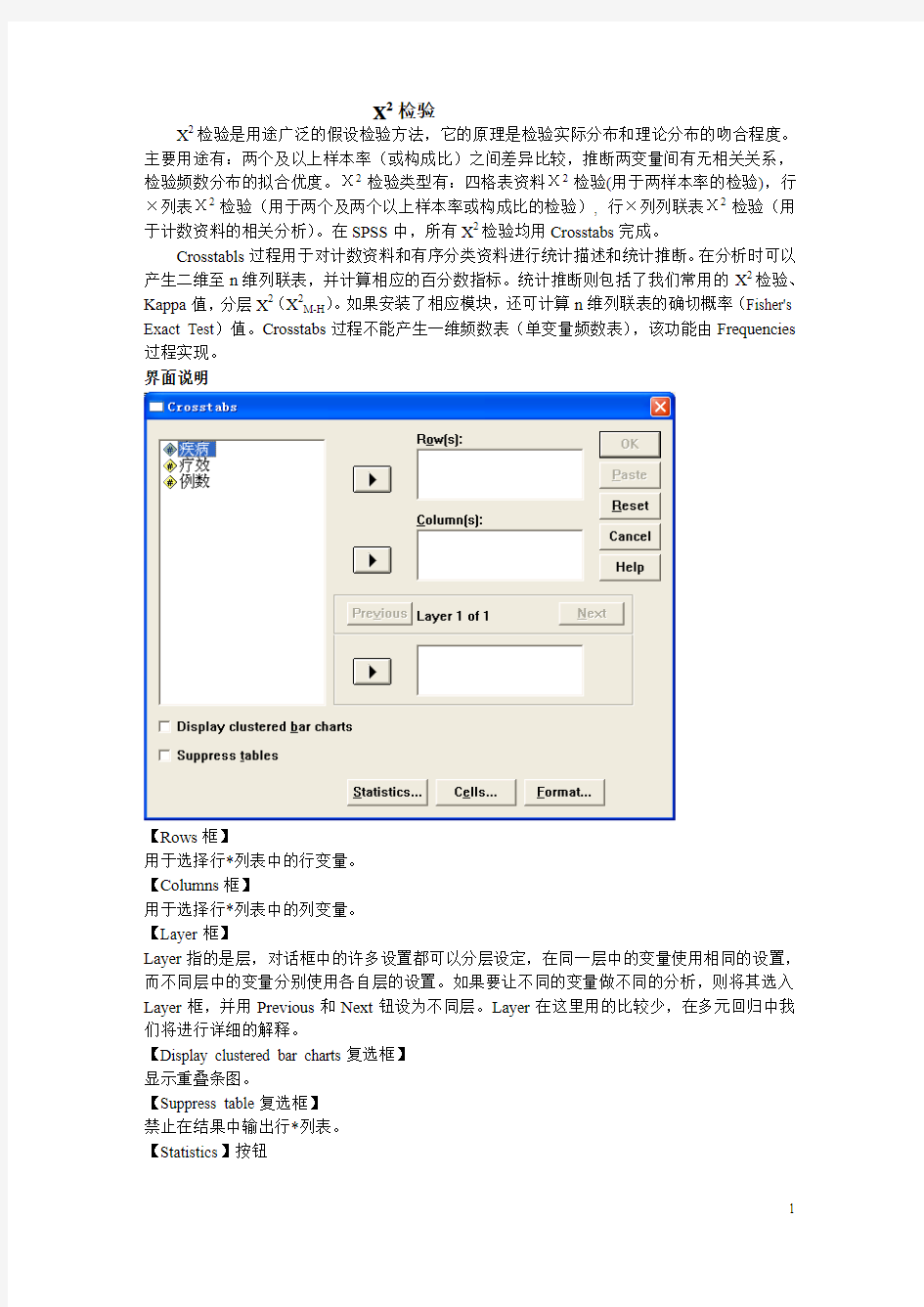
【Rows框】
用于选择行*列表中的行变量。
【Columns框】
用于选择行*列表中的列变量。
【Layer框】
Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。Layer在这里用的比较少,在多元回归中我们将进行详细的解释。
【Display clustered bar charts复选框】
显示重叠条图。
【Suppress table复选框】
禁止在结果中输出行*列表。
【Statistics】按钮
弹出Statistics对话框,用于定义所需计算的统计量。
Chi-square复选框:计算X2值。
Correlations复选框:计算行、列两变量的Pearson相关系数和Spearman等级相关系数。Norminal复选框组:选择是否输出反映分类资料相关性的指标,很少使用。
Contingency coefficient复选框:即列联系数,其值界于0~1之间;
Phi and Cramer's V复选框:这两者也是基于X2值的,Phi在四格表X2检验中界于-1~1之间,在R*C表X2检验中界于0~1之间;Cramer's V 则界于0~1之间;
Lambda复选框:在自变量预测中用于反映比例缩减误差,其值为1时表明自变量预测应变量好,为0时表明自变量预测应变量差;
Uncertainty coefficient复选框:不确定系数,以熵为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变量,其值接近0时表明后一变量的信息与前一变量无关。Ordinal复选框组:选择是否输出反映有序分类资料相关性的指标,很少使用。
Gamma复选框:界于0~1之间,所有观察实际数集中于左上角和右下角时,其值为1;Somers'd复选框:为独立变量上不存在同分的偶对中,同序对子数超过异序对子数的比例;Kendall's tau-b复选框:界于-1~1之间;
Kendall's tau-c复选框:界于-1~1之间;
Eta复选框:计算Eta值,其平方值可认为是应变量受不同因素影响所致方差的比例;Kappa复选框:计算Kappa值,即内部一致性系数;
Risk复选框:计算比数比OR值;
McNemanr复选框:进行McNemanr检验,即常用的配对计数资料的X2检验(一种非参检验);Cochran's and Mantel-Haenszel statistics复选框:计算X2M-H统计量(分层X2,也有写为X2CMH 的),可在下方输出H0假设的OR值,默认为1。
【Cells】按钮
弹出Cells对话框,用于定义列联表单元格中需要计算的指标:
Counts复选框组:是否输出实际观察数(Observed)和理论数(Expected);
Percentages复选框组:是否输出行百分数(Row)、列百分数(Column)以及合计百分数(Total);Residuals复选框组:选择残差的显示方式,可以是实际数与理论数的差值(Unstandardized)、标化后的差值(Standardized,实际数与理论数的差值除理论数),或者由标准误确立的单元
格残差(Adj. Standardized);
【Format钮】
用于选择行变量是升序还是降序排列。
分析实例
一、四格表资料的X2检验
例6.1 某医生用呋喃硝胺和甲氰咪胍治疗十二指肠溃疡,结果如下表,问两种药物治疗效果有无差别?
组别愈合未愈合合计有效率(%)
呋喃硝胺54 8 62 87.09
甲氰咪胍44 20 64 68.75
合计98 28 126 77.78
【建立数据文件】
由于此处给出的是频数表(大部分资料都以这种形式给出),因此在建立数据集时可以直接输入三个变量:
行变量(分组变量):变量名取“R”,变量值为1=“呋喃硝胺组”,2=“甲氰咪胍组”
列变量(疗效变量):变量名取“C”,变量值为1=“愈合”,2=“未愈合”
指示每个格子中频数的变量:变量名取“F”,直接输入各个格子的频数。
所建立的数据集如下表。
然后用Weight Cases Crosstabs过程进行X2检验。
【操作过程】
Data==>Weight Cases (对数据按频数进行加权)
Weight Cases by单选框:选中
Freqency Variable:选入F
单击OK钮
Analyze==>Descriptive Statistics==>Crosstabs
Rows框:选入R
Columns框:C
Statistics按钮:选中Chi-square复选框,单击Continue钮
Cells...按钮:选中Row 复选框,单击Continue钮
单击OK钮
【结果解释】
上题分析结果如下:
首先是有效记录数和处理记录缺失值情况报告,可见126例均为有效值。
上表为列出的四格表,其中加入变量值和变量值标签,看起来很清楚。
上表给出了一堆检验结果,从左到右为:检验统计量值(Value)、自由度(df)、双侧近似概率(Asymp.Sig.2-sided)、双侧精确概率(Exact Sig.2-sided)、单侧精确概率(Exact Sig.1-sided);从
上到下为:Pearson卡方(Pearson Chi-Square即常用的卡方检验)、连续性校正的卡方值(Continuity Correction)、对数似然比方法计算的卡方(Likelihood Ratio)、Fisher's确切概率法(Fisher's Exact Test)、线性相关的卡方值(Linear by Linear Association)、有效记录数(N of V alid Cases)。另外,Continuity Correction和Pearson卡方值处分别标注有a和b,表格下方为相应的注解:a.只为2*2表计算。b.0%个格子的期望频数小于5,最小的期望频数为13.78。因此,这里无须校正,直接采用第一行的检验结果,即X2=6.133,P=0.013。
因P=0.013,可以认为两种药物疗效有差异,结合样本率,可以认为呋喃硝胺有效率高于甲氰米胍。
如何选用上面众多的统计结果令许多初学者头痛,实际上我们只需要在未校正卡方、校正卡方和确切概率法三种方法之间选择即可,其余的对我们而言用处不大,可以视而不见。
二、配对计数资料X2检验
例6.2 有28份痰液标本,每份分别接种在甲、乙两种培养基中,观察结核杆菌生长情况,结果如下表,试检验甲、乙培养基生长率有无差别。
甲乙两种结核杆菌培养基的培养结果
乙培养基
甲培养基+ —合计
+ 11 9 20
— 1 7 8
合计12 16 28
【建立数据文件】
输入三个变量:
行变量(代表甲培养基):变量名取“R”,变量值为1=“生长”,2=“未生长”
列变量(代表甲培养基):变量名取“C”,变量值为1=“生长”,2=“未生长”
指示每个格子中频数的变量:变量名取“F”,直接输入各个格子的频数。
所建立的数据集如下表。
然后用Weight Cases对话框指定频数变量进行加权,最后调用Crosstabs过程进行X2检验。
【操作过程】
1. Data==>Weight Cases (对数据按频数进行加权)
Weight Cases by单选框:选中
Freqency Variable:选入F
2. Analyze==>Descriptive Statistics==>Crosstabs
Rows框:选入R
Columns框:C
Chi-square复选框(做成组X2检验,分析甲乙两培养基分析结果有无相关)
,分析甲乙培养基阳性率有无差异)
选中McNemanr复选框:(做配对X2检验
Cells...按钮:选中
【结果解释】
上表为有效例数, 缺失例数和总例数的情况, 28例均有效.
上表输出配对四格表数据。
上表为X2检验的结果。首先是成组X2检验,X2=4.21,P=0.040,可以认为甲乙两培养基的结果有相关性(即甲阳性,乙可能也阳性)。下面做了配对X2检验(McNemar Test),用精确概率法计算,P=0.021(双侧),可以认为甲乙两培养基阳性率差异有统计学意义。
三、R×C表X2检验
例6.3 某市三个地区出生婴儿的畸形发生情况如下表,试比较这三个地区出生婴儿畸形率有无差异。
地区畸形数无畸形数合计发生率(‰)
重污染区114 3278 3392 33.61
一般市区444 40103 40547 10.95
农村67 8275 8342 8.03
合计625 5165 52281 11.95
这是3×2表资料,要进行3个样本率的比较。
【建立数据文件】
直接输入三个变量:
行变量(分组变量):变量名取“R”,变量值为1=“重污染区”,2=“一般市区”,“农村”。列变量(疗效变量):变量名取“C”,变量值为1=“畸形”,2=“非畸形”
指示每个格子中频数的变量:变量名取“F”,直接输入各个格子的频数。
所建立的数据集如下表。
【操作过程】
1. Data==>Weight Cases (对数据按频数进行加权)
Weight Cases by单选框:选中
Freqency Variable:选入F
2. Analyze==>Descriptive Statistics==>Crosstabs
Rows框:选入R
Columns框:C
Statistics按钮:选中Chi-square复选框
Row 复选框单击Continue钮
【结果解释】
上表为有效例数, 缺失例数和总例数的情况, 52281例均有效。
上表输出原始数据,并计算行百分数,重污染区畸形率为3.4%,一般市区为1.1%,农村为0.8%。
上上表为X2检验的结果,X2=148.984,自由度=2 ,P=0.000,
可以认为这三个区新生儿畸形率差异有统计学意义,畸形率不同或不全相同。至于哪些地区有差别,那些地区没有差别,或都有差别,可进行X2分割。
四、R×C列联表资料X2检验
列联表是指每个观察对象按两种属性交叉分组归类,而且每种属性的分类都是有序的,这样整理出的资料称双向有序列联表。配对计数资料就是一个2×2列联表。
例6.4 下表资料是492名不同期次矽肺患者其肺门密度级别的资料,试分析矽肺期次和肺门密度级别有无关系。
不同期次矽肺患者肺门密度级别分布
━━━━━━━━━━━━━━━━━━━━━━━
肺门密度级别
矽肺期次──────────合计
+ ++ +++
───────────────────────
Ⅰ43 188 14 245
Ⅱ 1 96 72 169
Ⅲ 6 17 55 78
───────────────────
合计50 301 141 492
━━━━━━━━━━━━━━━━━━━━━━━
该资料是一个3×3列联表。每个矽肺病人按矽肺的期次和胸片肺门密度的级别进行交叉分类归组。使用x2检验可以分析这两个属性之间有无相关性。
【建立数据文件】
直接输入三个变量:
行变量(分组变量):变量名取“R”,代表矽肺期次,变量值为1=“Ⅰ期”,2=“Ⅱ期”,3=“Ⅲ期”。
列变量(疗效变量):变量名取“C”,代表肺门密度,变量值为1=“+”,2=“++”,3=“+++”。指示每个格子中频数的变量:变量名取“F”,直接输入各个格子的频数。
所建立的数据集如下表。
【操作过程】
1. Data==>Weight Cases (对数据按频数进行加权)
Weight Cases by单选框:选中
Freqency Variable:选入F
2. Analyze==>Descriptive Statistics==>Crosstabs Rows框:选入R
Columns框:
C
选中Chi-square复选框(做X2检验)
选种Kendall’s tau-b 复选框(计算列联系数)
选种Kappa 复选框(计算Kappa值,分析一致性)
Row 复选框(计算行百分数)
单击Continue钮
【结果解释】
上表为有效例数, 缺失例数和总例数的情况, 492例均有效。
上表输出原始数据,并计算行百分数。
上表结果为X2检验的结果,X2=163.007,自由度=4,P=0.000,可以认为矽肺期次和肺门密度有关,结合下表的列联系数(Kendall’s tau-b)为0.498,两者呈正相关的关系,即矽肺期别越高,肺门密度级别也越高。
上表输出Kendall’s tau-b列联系数,其值为0.498,标准误为0.034,对列联系数检验的统计量为13.680,P=0.000。Kappa=0.127,其标准误=0.028,对Kappa值检验的统计量为5.070,P=0.000,可认为两者有一致性。根据经验Kappa≥0.75,表明两者一致性好;0.75>Kappa≥0.4,表明一致性一般;Kappa<0.4 表明一致性差。矽肺期次和肺门密度有一致性,但一致性差。
习题
1、某卫生防疫站对屠宰场及肉食零售点的猪肉,检查其表层沙门氏菌带菌情况,如下表,问两者带菌率有无差别?
采样地点检查例数阳性例数带菌率(%)
屠宰场28 2 7.14
零售点14 5 35.71
合计42 7 16.67
2.以眼为单位观察20岁以上居民眼睛的晶状体点状混浊程度与年龄间的关系得资料如下,分析两者之间有无关系。
──────────────────────
晶状体混浊程度
年龄(岁)───────────合计
+ ++ +++
──────────────────────
20-2256744336
30-141 101 63 305
40-158 128 132 418
──────────────────────
合计524 296 239 1059
──────────────────────
3、某医院比较急性黄疸型肝炎与正常人在超声波肝波波型上的表现,结果如下。问两组病人肝波波型的密度构成有无差别?
波型密度
组别正常较密很密合计
黄疸型肝炎组12 43 232 287
正常人组277 39 11 327
合计289 82 243 614
4、为研究血型与胃溃疡、胃癌的关系,得下表资料,因AB型例数少而省略,问各组血型构成有无差别?
血型
──────────合计
O A B
────────────────────
胃溃疡993679134 1806
胃癌393 416 84 893
对照2902 2652 570 6097
────────────────────
4288 3720 788 8796
────────────────────
5、有21例急性心肌梗塞并发休克患者,分别采用西药和中西药结合的方法,疗效如下。问两组疗效有无差别?
两种疗法对心肌梗塞的疗效比较
治疗组康复死亡合计
西药组 6 5 11
中西药组9 1 10
合计15 5 21
6、现有170例已确诊的乳癌患者,用两种方法对其进行诊断,问:这两种诊断方法的诊断结果是否有关系?两种方法何者为优?两者的一致性如何?
────────────────
临床诊断
X线诊断─────────
乳癌非乳癌
────────────────
乳癌24 30
非乳癌70 46
────────────────
7、比较某市三个地区出生婴儿的畸形率有无差异。
某市三个地区出生婴儿的畸形率
地区畸形数无畸形数合计畸形率(‰)重污染区114 3278 3392 33.61
一般市区444 40103 40547 10.95
农村67 8275 8342 8.03
合计625 51656 52281 11.95
第七章 假设检验 Ⅰ.学习目的 假设检验包括参数检验与非参数检验,是一种最能体现统计推断思想和特点的方法。通过本章学习,要求:1.掌握统计检验的基本原理,理解该检验的规则及犯两类错误的性质;2.熟练掌握总体均值、总体成数及总体方差指标的各种检验方法,包括:z 检验、t 检验和p 值检验;3.掌握2 检验、符号检验、秩和检验及游程检验四种基本的非参数检验方法。 Ⅱ.课程内容要点 第一节 假设检验的基本原理 一、假设检验的基本原理 “小概率原理”:小概率事件在一次试验中几乎是不会发生的。 事先所做的假设,是假设检验中关键的一项工作。它包括原假设和备选假设两部分。原假设是建立在假定原来总体参数没有发生变化的基础之上的。备选假设是原假设的对立,是在否认原假设之后所要接受的,通常这是我们真正感兴趣的一个判断。 二、假设检验的规则与两类错误 1、假设检验的规则 假设检验的步骤: (1)首先根据实际应用问题确定合适的原假设0H 和备选假设1H ; (2)确定检验统计量,通过数理统计分析确定该统计量的抽样分布;
(3)给定检验的显著性水平α。在原假设成立的条件下,结合备选假设的定义,由检验统计量的抽样分布情况求出相应的临界值,该临界值为原假设的接受域与拒绝域的分界值; (4)从样本资料计算检验的样本统计量,并将其与临界值进行比较,判断是否接受或拒绝原假设。 从检验程序我们可以看出,统计量的取值范围可以分为接受域和拒绝域两个区域。拒绝域正是统计量取值的小概率区域。按照我们将这个拒绝域安排在所检验统计量的抽样分布的某一侧还是两端,可以将检验分为单侧检验或双侧检验。双侧检验中,又可以根据拒绝域,是在左侧还是在右侧而分为左侧检验和右侧检验。对于这些双侧、左、右单侧检验,我们要结合备选假设来考虑。 在检验规则中,我们经常碰到两种重要的检验方法:z检验与t检验。 p值检验的原理:给出原假设后,在假定原假设正确的情况下,参照备选假设,可以计算出检验统计量超过或者小于(还要依照分布的不同、单侧检验、双侧检验的差异而定)由样本所计算的检验统计量的数值的概率,这便是p值;而后将此概率值跟事先给出的显著性水平值α进行比较。如果该值小于α,否定原假设,取对应的备选假设。如果该值大于α,我们不就能否定原假设。 2、两类错误 H实际为真,但我们却依据样本信息,做出拒绝的错误结论当原假设 时,称为“弃真”错误;当原假设实际为假,而我们却错误接受时,称为“纳伪”错误。通常记显著性水平α为犯“弃真”错误的可能性大小,β为犯“纳伪”错误的可能性大小。由于两类错误是一对矛盾,在其他条件不变得情况下,减少犯“弃真”错误的可能性大小(α),势必增大犯“纳伪”错误的可能性大小(β),也就是说,β的大小和显著性水平α的大小成相反方向变化。 三、检验功效 -可以用来表明所做假设检验工作好坏的一个指标,我们称之为检1β
检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量<30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈分布。 检验是用分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。检验分为单总体检验和双总体检验。 1.单总体检验 单总体检验是检验一个样本平均数与一已知的总体平均数的差异是否显著。当总体分布是正态分布,如总体标准差未知且样本容量<30,那么样本平均数与总体平均数的离差统计量呈分布。检验统计量为: 。 如果样本是属于大样本(>30)也可写成: 。 在这里,为样本平均数与总体平均数的离差统计量; 为样本平均数; 为总体平均数; 为样本标准差; 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步建立原假设=73 第二步计算值 第三步判断
因为,以0.05为显著性水平,,查值表,临界值,而样本离差的 1.63小与临界值2.093。所以,接受原假设,即进步不显著。 2.双总体检验 双总体检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过。 相关样本的检验公式为: 。 在这里,,分别为两样本平均数; ,分别为两样本方差; 为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为79.5和72分,标准差分别为9.124,9.940。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步建立原假设= 第二步计算值 = =3.459。 第三步判断
第七章质量保证体系和质量控制措施 为贯彻我公司“质量第一、信誉至上、文明施工、优质服务”的质量管理方针,确保本工程施工质量全优的实现,根据该工程施工图纸设计,现行施工规程、规范和质量检查验收的有关要求,特制定本质量保证措施。 第一节质量目标 质量目标:全部工程的使用功能符合设计图纸要求,工程一次性验收全部合格。 第二节质量保证体系 我公司按照国际标准化组织颁布的ISO9002质量标准,建立起一套行之有效的文件化的质量保证体系。该体系囊括了从工程项目的投标。签订合同到竣工交付使用,直到交工后保修与回访的全过程,充分体现了ISO9002中19个要素的要求。该体系以质量手册为核心和指导,以程序文件为日常工作准则,以作业指导书为操作的具体指导,所有质量活动都有质量计划并具体反映到质量记录中,使得施工过程标准化、规范化、有章可循、责任分明。 一、质量标准的要素及其在保证体系中的具体反映 下文是ISO9002 中19 个要素。各要素4.n 具体表现见相应的程序文件COPn.*(COP 为程序文件的代号,n 为要素的编号)。 4.1 管理评审 质量体系应定期评审,以保证其符合ISO9002 标准及实现企业的质量方
针。质量评审采用现场评审或会议形式。详见COP1.1《管理评审程序》。 4.2 质量体系 公司必须建立并维持行之有效的文件化的质量体系,以保证工程质量稳定。连续并不断提高。详见COP2.1《质量计划编制与实施控制程序》。 4.3 合同评审 通过对招标文件和合同草案的评审,确保合同条款的明确完善和正确理解,正式合同签订前及执行期间都应对合同进行评审。详见COP3.1《合同评审程序》及COP3.2《工程招标管理程序》。 4.5 文件控制 通过对公司所有质量体系文件和工程技术文件从产生到回收的全过程进行控制,使其处于受控状态并能及时修改或换版。详见COP5.1《质量体系文件控制程序》、COP5.2《工程技术文件控制程序》、COP5.3《设计变更控制程序》。 4.6 采购 通过对供应商和分包商的选择及对产品的质量关的严格控制,保证所采购的材料符合要求。公司建立合格供应商和合格分包商的名单,并定期进行评审。采购产品时必须有完整的计划。合同和相应的规范、标准等,并严格进行验证。详见COP6.1《供应商的评价程序》、COP6.2《工程材料采购控制程序》、COP6.3《工程分包管理程序》。 4.7 建设单位提供的物资 通过对建设单位提供的物资进行有效的控制,使其能满足施工的需要。必须在合同中规定双方的责任,将建设单位提供的物资列入采购计划,按规定进行验证、检验,贮存和保管,出现问题加以记录。详见COP7.1《建设单位供料控
当总体呈正态分布,如果总体标准差未知,而且样本容量n v30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈 t分布。 t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t检验分为单总体t检验和双总体t检验。 1.单总体t检验 单总体t检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差未知且样本容量n v30,那么样本平均数与总体平均数的离差统计量呈t分布。检验统计量为: 如果样本是属于大样本(n>30)也可写成: 在这里,t为样本平均数与总体平均数的离差统计量; X为样本平均数; 为总体平均数; X为样本标准差; n为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步建立原假设H0:=73 第二步计算t值
17 厂1 .19 第三步 判断 因为,以为显著性水平,df n 1 19,查t 值表,临界值t(19)0.05 2.093 , 而样本离差的t 小与临界值。所以,接受原假设,即进步不显著。 2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显 著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用 于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据 的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性 检验。各实验处理组之间毫无相关存在, 即为独立样本。该检验用于检验两组非 相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验 完全类似,只不过r 0。 相关样本的t 检验公式为: X 1 X 2 在这里,X 1, X 2分别为两样本平均数; 为相关样本的相关系数 例:在小学三年级学生中随机抽取 10名学生,在学期初和学期末分别进行 了两次推理能力测验,成绩分别为和72分,标准差分别为,。问两次测验成绩是 否有显著地差异? 检验步骤为: 第一步 建立原假设H 。: 1= 2 1.63 X 1 X 2 2 X 1 , 2 X 2 分别为两样本方差; 2 X 2
x2检验练习题
2χ检验 练 习 题 一、单项选择题 1. 利用2χ检验公式不适合解决的实际问题是 A. 比较两种药物的有效率 B. 检验某种疾病与基因多态性的关系 C. 两组有序试验结果的药物疗效 D. 药物三种不同剂量显效率有无差别 E. 两组病情“轻、中、重”的构成比例 2.欲比较两组阳性反应率, 在样本量非常小的情况下(如1210,10n n <<), 应采用 A. 四格表2χ检验 B. 校正四格表2χ检验 C. Fisher 确切概率法 D. 配对2χ检验 E. 校正配对2χ检验 3.进行四组样本率比较的2χ检验,如220.01,3χχ>,可认为 A. 四组样本率均不相同 B. 四组总体率均不相同 C. 四组样本率相差较大 D. 至少有两组样本率不相同 E. 至少有两组总体率不相同 4. 从甲、乙两文中,查到同类研究的两个率比较的2χ检验,甲文 220.01,1 χχ>,乙文220.05,1χχ>,可认为 A. 两文结果有矛盾 B. 两文结果完全相同 C. 甲文结果更为可信 D. 乙文结果更为可信 E. 甲文说明总体的差异较大 5. 两组有效率比较检验功效的相关因素是
A. 检验水准和样本率 B. 总体率差别和样本含量 C. 样本含量和样本率 D. 总体率差别和理论频数 E. 容许误差和检验水准 答案:C C E C B 二、计算与分析 1.某神经内科医师观察291例脑梗塞病人,其中102例病人用西医疗法,其它189 例病人采用西医疗法加中医疗法,观察一年后,单纯用西医疗法组的病人死亡13例,采用中西医疗法组的病人死亡9例,请分析两组病人的死亡率差异是否有统计学意义? 2.某医院研究中药治疗急性心肌梗死的疗效,临床观察结果见下表。问接受两种不同疗法的患者病死率是否不同? 两种药治疗急性心肌梗死的疗效 组别存活死亡合计病死率 (%)中药组65 3 68 4.41 非中药组12 2 14 14.29 合计77 5 82 6.10 3.某医师观察三种降血脂药A,B,C的临床疗效,观察3个月后,按照患者的血脂下降程度分为有效与无效,结果如下表,问三种药物的降血脂效果是否不同? 三种药物降血脂的疗效 药物有效无效合计
第七章 假设检验与方差分析 习题答案 一、名词解释 用规范性的语言解释统计学中的名词。 1. 假设检验:对总体分布或参数做出某种假设,然后再依据抽取的样本信息,对假设是否正确做出统计判断,即是否拒绝这种假设。 2. 原假设:又叫零假设或无效假设,进行统计检验时预先建立的假设,表示为 H 0,总是含有等号。 3. 备择假设:是零假设的对立,表示为 H 1,总是含有不等号。 4. 单侧检验:备择假设符号为大于或小于时的假设检验。 5. 显著性水平:原假设为真时,拒绝原假设的概率。 6. 方差分析:通过对数据总变异进行分解,来检验多个总体均值是否相等的一种统计分析方法。 二、填空题 根据下面提示的内容,将适宜的名词、词组或短语填入相应的空格之中。 1. u ,n x σμ0-,标准正态; ),(),(2/2/+∞--∞n z n z σσ αα 2. 参数检验,非参数检验 3. 弃真,存伪 4. 方差 5. 卡方, F 6. 方差分析 7. t ,u 8. n s x 0 μ-,不拒绝 9. 单侧,双侧 10.新产品的废品率为5% ,0.01 11.相关,总变异,组间变异,组内变异 12.总变差平方和=组间变差平方和+组内变差平方和 13.连续,离散 14.总体均值 15.因子,水平 16.组间,组内 17.r-1,n-r
18. 正态,独立,方差齐
三、单项选择 从各题给出的四个备选答案中,选择一个最佳答案,填入相应的括号中。 1.B 2.B 3. B 4.A 5. C 6. B 7. C 8. A 9. D 10. A 11. D 12. C 四、多项选择 从各题给出的四个备选答案中,选择一个或多个正确的答案,填入相应的括号中。 1.AC 2.A 3.B 4.BD 5. AD 五、判断改错 对下列命题进行判断,在正确命题的括号内打“√”;在错误命题的括号内打“×”,并在错误的地方下划一横线,将改正后的内容写入题下空白处。 1. 在任何情况下,假设检验中的两类错误都不可能同时降低。 ( × ) 样本量一定时 2. 对于两样本的均值检验问题,若方差均未知,则方差分析和t 检验均可使用,且两者检验结果一致。 ( √ ) 3. 方差分析中,组间离差平方和总是大于组内离差平方和。( × ) 不一定 4. 在假设检验中,如果在显著性水平0.05下拒绝了 00:μμ≤H ,则在同一水平一定可以拒绝假设00:μμ=H 。( × ) 不一定 5. 为检验k 个总体均值是否显著不同,也可以用t 检验,且与方差分析相比,犯第一类错误的概率不变。( × ) 会增加 6. 方差分析中,若拒绝了零假设,则认为各个总体均值均有显著性差异。( × ) 不完全相等 六、简答题 根据题意,用简明扼要的语言回答问题。 1. 假设检验与统计估计有何区别与联系? 【答题要点】 假设检验是在给定显著性水平下,计算出拒绝域,并根据样本统计量信息来做出是否拒
第七章焊接质量检验 焊接质量检验是保证焊接产品质量优良、防止废品出厂的重耍措施。通过检验可以发现制造过程中发生的质量问题,找出原因,消除缺陷,使新产品或新工艺得到应用,质量得到保证;在正常生产中,通过完善的质量检验制度,可以及时消除生产过程中的缺陷,防止类似的缺陷重复出现,减少返修次数,节约工时、材料,从而降低成本。所以说焊接质量检验是焊接生产必不可少的重要工序。7.1 焊接接头质量检验的内容和方法 焊接质量检验贯穿整个焊接过程,包括焊前、焊接过程中和焊后成品检验三个阶段。 7.1.1 焊接质量检验的内容和要求 (1)焊前检验 焊前检验是指焊件投产前应进行的检验工作,是焊接检验的第一阶段,其目的是预先防止和减少焊接时产生缺陷的可能性。包括的项目有: ①检验焊接基本金属、焊丝、焊条的型号和材质是否符合设计或规定的要求; ②检验其他焊接材料,如埋弧自动焊剂的牌号、气体保护焊保护气体的纯度和配比等是否符合工艺规程的要求 ③对焊接工艺措施进行检验,以保证焊接能顺利进行; ④检验焊接坡口的加工质量和焊接接头的装配质量是否符合图样要求; ⑤检验焊接设备及其辅助工具是否完好,接线和管道联接是否合乎要求; ⑥检验焊接材料是否按照工艺要求进行去锈、烘干、预热等; ⑦对焊工操作技术水平进行鉴定; ⑧检验焊接产品图样和焊接工艺规程等技术文件是否齐备。 (2)焊接生产过程中的检验 焊接过程中的检验是焊接检验的第二阶段,由焊工在操作过程中,其目的是为了防止由于操作原因或其他特殊因索的影响而产生的焊接缺陷,便于及时发现问题并加以解决。包括: ①检验在焊接过程中焊接设备的运行情况是否正常; ②对焊接工艺规程和规范规定的执行情况; ③焊接夹具在焊接过程中的夹紧情况是否牢固; ④操作过程中可能出现的未焊透、夹渣、气孔、烧穿等焊接缺陷等; ⑤焊接接头质量的中间检验,如厚壁焊件的中间检验等。 焊前检验和焊接过程中检验,是防止产生缺陷、避免返修的重要环节。尽管
t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用 t 分布理论来推论差异发生的概率,从而比较两个平均数的差异 是否显著。 t 检验分为单总体 t 检验和双总体 t 检验。 1.单总体 t 检验 单总体 t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显著。当总体分布是正态分布,如总体标准差未知且样本容量 n <30,那么样本平均数与总体平均数的离差统计量呈 t 分布。检验统计量为: X t。 X n 1 如果样本是属于大样本(n >30)也可写成: X t。 X n 在这里, t 为样本平均数与总体平均数的离差统计量; X为样本平均数; 为总体平均数; X为样本标准差; n为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73 分,标准差为 17 分,期末考试后,随机抽取 20 人的英语成绩,其平均分数为 79.2 分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步建立原假设 H 0∶=73 第二步计算 t 值 X 79.2 73 t 17 1.63 X n 119 第三步判断 因为,以 0.05 为显著性水平, df n 1 19 ,查t值表,临界值 t (19)0.05 2.093 ,而样本离差的t 1.63 小与临界值 2.093 。所以,接受原假设,即进步不显著。
2.双总体 t 检验 双总体 t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显 著。双总体 t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用 于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据 的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过 r 0 。 相关样本的 t 检验公式为: t X1 X2 。 2 2 2 X1X2 X1 X 2 n 1 在这里, X1 , X 2 分别为两样本平均数; X 2 1 , X2 2 分别为两样本方差;为相关样本的相关系数。 例:在小学三年级学生中随机抽取 10 名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为 79.5 和 72 分,标准差分别为 9.124,9.940 。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步建立原假设 H0∶1= 2 第二步计算 t 值 t X1 X 2 2 2 2 X1X2 X1 X 2 n 1 = 79.571 9.12429.9402 2 0.704 9.124 9.940 10 1 =3.459 。 第三步判断 根据自由度 df n 1 9 ,查t值表 t (9)0.05 2.262 , t(9) 0.01 3.250 。由于实 际计算出来的 t =3.495>3.250= t(9) 0.01 ,则 P ,故拒绝原假设。 0.01 结论为:两次测验成绩有及其显著地差异。 由以上可以看出,对平均数差异显著性检验比较复杂,究竟使用 Z 检验还是使用 t 检验必须根据具体情况而定,为了便于掌握各种情况下的 Z 检验或 t 检验,
x2检验或卡方检验和校正卡方检验的计算 x2检验(chi-square test)或称卡方检验 x2检验(chi-square test)或称卡方检验,是一种用途较广的假设检验方法。可以分为成组比较(不配对资料)和个别比较(配对,或同一对象两种处理的比较)两类。 一、四格表资料的x2检验 例20.7某医院分别用化学疗法和化疗结合放射治疗卵巢癌肿患者,结果如表 20-11,问两种疗法有无差别? 表20-11 两种疗法治疗卵巢癌的疗效比较 表内用虚线隔开的这四个数据是整个表中的基本资料,其余数据均由此推算出来;这四格资料表就专称四格表(fourfold table),或称2行2列表(2×2 contingency table)从该资料算出的两种疗法有效率分别为44.2%和77.3%,两者的差别可能是抽样误差所致,亦可能是两种治疗有效率(总体率)确有所不同。这里可通过x2检验来区别其差异有无统计学意义,检验的基本公式为: 式中A为实际数,以上四格表的四个数据就是实际数。T为理论数,是根据检验假设推断出来的;即假设这两种卵巢癌治疗的有效率本无不同,差别仅是由抽样误差所致。这里可将两种疗法合计有效率作为理论上的有效率,即53/87=60.9%,以此为依据便可推算出四格表中相应的四格的理论数。兹以表20-11资料为例检验如下。
检验步骤: 1.建立检验假设: H0:π1=π2 H1:π1≠π2 α=0.05 2.计算理论数(TRC),计算公式为: TRC=nR.nc/n 公式(20.13) 式中TRC是表示第R行C列格子的理论数,nR为理论数同行的合计数,nC为与理论数同列的合计数,n为总例数。 第1行1列: 43×53/87=26.2 第1行2列: 43×34/87=16.8 第2行1列: 44×53/87=26.8 第2行2列: 4×34/87=17.2 以推算结果,可与原四项实际数并列成表20-12: 表20-12 两种疗法治疗卵巢癌的疗效比较
惠城区七年级地理质量检测 第七章我们邻近的国家和地区 一、单项选择题(请把正确答案填写在表格里,每小题2分,共 46分) 1.下列有关日本火山地震的叙述不正确的是 A.日本位于环太平洋火山地震带,所以多火山地震 B.日本处于两大海洋板块的交界处,使日本多火山地震 C.日本的富士山是座活火山 D.由于火山活动频繁,所以日本地热资源丰富 2.有关日本与英国的叙述不正确的是 A.都是岛国 B.所有著名的工业中心都是沿海的港口城市C.海上运输都很发达 D.气候具有较强的海洋性 3.每年的9月1日是日本全国的防灾日,中小学生要进行防震演习。我国也是一个多地震的国家,我们也应掌握一些防震知识,下列做法不正确的是 A.应迅速撤到空旷地 B.当来不及离开房屋时应两手抱头躲到墙角 C.就坐在教室内做作业,毫不惊慌 D.如果被埋在废墟中不能自行脱险时,要高声呼救,直到有人发现为止;同时要挪开脸、胸前的杂物,清除口鼻的灰土,保持呼吸通畅。
4.关于日本的下列叙述,错误的是 A.近年来日本太平洋沿岸地带污染严重,地面下沉,用地用水紧张 B.日本的森林覆盖率居世界前列,也是世界上出口木材最多的国家之一 C.日本是渔业大国,捕鱼量居世界首位,是使世界渔业资源走向枯竭的主要国家之一 D.日本已加快扩大海外投资,将一些工业包括污染较多的工业移往海外 5.近年,日本加速扩大海外投资,投资建厂的主要对象是 A.美国、西欧、东亚和东南亚 B.中国、西欧、东亚和东南亚C.亚洲、非洲、拉丁美洲 D.美国、中国、东亚和东南亚6.有关日本文化的叙述,不正确的是 A.受中国文化的影响源远流长 B.有着浓厚的大和民族传统文化色彩 C.具有东西方文化交融的特点 D.日本的茶道和花道都是从西方传入的 7.与中国陆地相邻且是内陆国的东南亚国家是 A.老挝 B.缅甸 C.泰国 D.越南 8.你知道东南亚的华人和华侨祖先大多来自我国的哪些省吗? A.广东、广西 B.广东、福建 C.福建、海南 D.广西、福建 9.关于东南亚旅游资源的叙述,正确的是
t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ σ-=。 如果样本是属于大样本(n >30)也可写成: X t μ σ-=。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数; X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.63X t μ σ--=== 第三步 判断 因为,以0.05为显著性水平,119df n =-=,查t 值表,临界值0.05(19) 2.093t =,而样本离差的t =1.63小与临界值2.093。所以,接受原假设,即进步不显著。
2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过0r =。 相关样本的t 检验公式为: t = 在这里,1X ,2X 分别为两样本平均数; 12X σ,2 2X σ分别为两样本方差; γ为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为79.5和72分,标准差分别为9.124,9.940。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设0H ∶1μ=2μ 第二步 计算t 值 t = =3.459。 第三步 判断 根据自由度19df n =-=,查t 值表0.05(9) 2.262t =,0.01(9) 3.250t =。由于实际计算出来的t =3.495>3.250=0.01(9)t ,则0.01P <,故拒绝原假设。 结论为:两次测验成绩有及其显著地差异。 检验。
SPSS最适用的统计学方法(X2检验和T检验) 1.SPSS的启动 (1)在windows[开始]→[程序]→[spss20],进入SPSS for Windows对话框, 2.创建一个数据文件 三个步骤: (1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。 (2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。 (3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。3.读取外部数据 当前版本的SPSS可以很容易地读取Excel数据,步骤如下: (1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图所示。
图 Open File对话框 (2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图所示。对话框中各选项的意义如下: 工作表下拉列表:选择被读取数据所在的Excel工作表。 范围输入框:用于限制被读取数据在Excel工作表中的位置。 图 Open Excel Data Source对话框 4.数据编辑 在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
5.SPSS数据的保存 SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框(如图所示)中根据不同要求进行SPSS数据保存。 图 SPSS数据的保存 5. 数据分析 在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下 6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文 第六章:描述性统计分析(X2检验) 完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 6.1.1界面说明 界面如下所示:分析—描述统计—频率
2χ检验 练 习 题 一、单项选择题 1. 利用2χ检验公式不适合解决的实际问题是 A. 比较两种药物的有效率 B. 检验某种疾病与基因多态性的关系 C. 两组有序试验结果的药物疗效 D. 药物三种不同剂量显效率有无差别 E. 两组病情“轻、中、重”的构成比例 2.欲比较两组阳性反应率, 在样本量非常小的情况下(如1210,10n n <<), 应采用 A. 四格表2χ检验 B. 校正四格表2χ检验 C. Fisher 确切概率法 D. 配对2χ检验 E. 校正配对2χ检验 3.进行四组样本率比较的2χ检验,如22 0.01,3χχ>,可认为 A. 四组样本率均不相同 B. 四组总体率均不相同 C. 四组样本率相差较大 D. 至少有两组样本率不相同 E. 至少有两组总体率不相同 4. 从甲、乙两文中,查到同类研究的两个率比较的2χ检验,甲文22 0.01,1χχ>,乙文22 0.05,1χχ>,可认为 A. 两文结果有矛盾 B. 两文结果完全相同 C. 甲文结果更为可信 D. 乙文结果更为可信 E. 甲文说明总体的差异较大 5. 两组有效率比较检验功效的相关因素是 A. 检验水准和样本率 B. 总体率差别和样本含量 C. 样本含量和样本率 D. 总体率差别和理论频数 E. 容许误差和检验水准
答案:C C E C B 二、计算与分析 1.某神经内科医师观察291例脑梗塞病人,其中102例病人用西医疗法,其它189 例病人采用西医疗法加中医疗法,观察一年后,单纯用西医疗法组的病人死亡13例,采用中西医疗法组的病人死亡9例,请分析两组病人的死亡率差异是否有统计学意义? 2.某医院研究中药治疗急性心肌梗死的疗效,临床观察结果见下表。问接受两种不同疗法的患者病死率是否不同? 两种药治疗急性心肌梗死的疗效 组别存活死亡合计病死率(%) 中药组65 3 68 4.41 非中药组12 2 14 14.29 合计77 5 82 6.10 3.某医师观察三种降血脂药A,B,C的临床疗效,观察3个月后,按照患者的血脂下降程度分为有效与无效,结果如下表,问三种药物的降血脂效果是否不同? 三种药物降血脂的疗效 药物有效无效合计 A 120 25 145 B 60 27 87 C 40 22 62 4.为研究某补钙制剂的临床效果,观察56例儿童,其中一组给与这种新药,另一组给与钙片,观察结果如表,问两种药物预防儿童的佝偻病患病率是否不同? 表两组儿童的佝偻病患病情况 组别病例数非病例数合计患病率(%)
页脚内容1 t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为 单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ σ-= 。 如果样本是属于大样本(n >30)也可写成: X t μ σ-= 。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数;
页脚内容2 X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.6317X t μ σ--= = = 第三步 判断 因为,以0.05为显著性水平,119df n =-=,查t 值表,临界值0.05(19) 2.093t =,而样本离差的t =1.63 小与临界值2.093。所以,接受原假设,即进步不显著。 2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过
---------------------------------------------------------------最新资料推荐------------------------------------------------------ t检验和x2检验doc 实验一 t-检验实验目的及要求掌握利用Excel 数据分析中提供t-检验工具进行假设检验的方法,并能够解释实验结果。 实验内容及步骤例1-7: 双样本等均值检验是在一定置信水平之下, 在两个总体方差相等的假设之下,检验两个总体均值的差值等于指定平均差的假设是否成立的检验。 假设某工厂为了比较两种装配方法的效率,分别组织了两组员工,每组9 人,一组采用新的装配方法,另外一组采用旧的装配方法。 18个员工的设备装配时间图1-18 中表格所示。 根据以下数据,是否有理由认为新的装配方法更节约时间?图1-18 操作步骤: STEP1: 选择工具菜单的数据分析子菜单,双击t-检验: 双样本等方差假设选项,则弹出图1-19 所示对话框。 (注: 如果没有数据分析,则请加载分析工具库加载宏。 操作方法: 在工具菜单上,单击加载宏。 在可用加载宏列表中,选中分析工具库框,再单击确定。 如果必要,请按安装程序中的指示进行操作。 1 / 5
) 2)在数据分析对话框中,单击t-检验,再单击确定。 3)在出现的对话框中,设置所需的参数。 图1-19 STEP2: 分别填写变量1 的区域: $B$1: $B$10,变量2 的区域: $D$1: $D$10,由于我们进行的是等均值的检验,填写假设平均差为0,由于数据的首行包括标志项选择标志选项,所以选择标志选项,再填写显著水平为0. 05, 然后点击确定按扭。 则可以得到图1-20所示的结果。 图1-20 结果分析: 如图1-20中所示,表中分别给出了两组装配时间的平均值、方差和样本个数。 其中,合并方差是样本方差加权之后的平均值, Df 是假设检验的自由度它等于样本总个数减2, t 统计量是两个样本差值减去假设平均差之后再除于标准误差的结果, P(T=t) 单尾是单尾检验的显著水平, t 单尾临界是单尾检验t 的临界值, P(T=t) 双尾是双尾检验的显著水平, t 双尾临界是双尾检验t 的临界值。 由下表的结果可以看出t 统计量均小于两个临界值,所以,在5%显著水平下,不能拒绝两个总体均值相等的假设,即两种装配方法所耗时间没有显著的不同。 Excel 中还提供了以下类似的假设检验的数据分析工具,它们的名称和作用如下:
第七章假设检验 第一节二项分布 二项分布的数学形式·二项分布的性质 第二节统计检验的基本步骤 建立假设·求抽样分布·选择显著性水平和否定域·计算检验统计量·判定第三节正态分布 正态分布的数学形式·标准正态分布·正态分布下的面积·二项分布的正态近似法 第四节中心极限定理 抽样分布·总体参数与统计量·样本均值的抽样分布·中心极限定理 第五节总体均值和成数的单样本检验 σ已知,对总体均值的检验·学生t分布(小样本总体均值的检验)·关于总体成数的检验 一、填空 1.不论总体是否服从正态分布,只要样本容量n足够大,样本平均数的抽样分布就趋于(正态)分布。 2.统计检验时,被我们事先选定的可以犯第一类错误的概率,叫做检验的( 显著性水平),它决定了否定域的大小。 3.假设检验中若其他条件不变,显著性水平的取值越小,接受原假设的可能性越(大),原假设为真而被拒绝的概率越(小)。 4.二项分布的正态近似法,即以将B(x;n,p)视为N( np ,npq) 查表进行计算。 二、单项选择 1.关于学生t分布,下面哪种说法不正确( B )。 A要求随机样本 B 适用于任何形式的总体分布 C 可用于小样本 D 可用样本标准差S代替总体标准差 2.二项分布的数学期望为( C )。 A n(1-n)p B np(1- p) C np D n(1- p)。 3.处于正态分布概率密度函数与横轴之间、并且大于均值部分的面积为( D )。 A大于0.5 B -0.5 C 1 D 0.5。 4.假设检验的基本思想可用( C )来解释。 A中心极限定理 B 置信区间 C 小概率事件 D 正态分布的性质 5.成数与成数方差的关系是(D)。 A成数的数值越接近0,成数的方差越大
t检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n<30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t分布。 t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t检验分为单总体t检验和双总体t检验。 1.单总体t检验 单总体t检验是检验一个样本平均数与一已知的总体平均数的差异是否显著。当总体分布是正态分布,如总体标准差σ未知且样本容量n<30,那么样本平均数与总体平均数的离差统计量呈t分布。检验统计量为: t=X-μ σ X n-1 。 如果样本是属于大样本(n>30)也可写成: t=X-μ σ X n 。 在这里,t为样本平均数与总体平均数的离差统计量; X为样本平均数; μ为总体平均数; σ为样本标准差; X n为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步建立原假设H∶μ=73 第二步计算t值 t=X-μ σ X n-1= 79.2-73 =1.63 17 19 第三步判断 因为,以0.05为显著性水平,df=n-1=19,查t值表,临界值t(19) 0.05 =2.093,而样本离差的t=1.63小与临界值2.093。所以,接受原假设,即进步不显著。
n - 1 n - 1 2.双总体 t 检验 双总体 t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显 著。双总体 t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用 于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据 的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性 检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非 相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验 完全类似,只不过 r = 0 。 相关样本的 t 检验公式为: t = X 1 - X 2 σ 2 + σ 2 - 2γσ σ X X X 1 2 1 X 2 。 在这里, X , X 分别为两样本平均数; 1 2 σ 2 , σ 2 分别为两样本方差; X 1 X 2 γ 为相关样本的相关系数。 例:在小学三年级学生中随机抽取 10 名学生,在学期初和学期末分别进行 了两次推理能力测验,成绩分别为 79.5 和 72 分,标准差分别为 9.124,9.940。 问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设 H ∶ μ = μ 1 第二步 计算 t 值 2 t = X 1 - X 2 σ 2 + σ 2 - 2γσ σ X X X 1 2 1 X 2 = 79.5 - 71 9.1242 + 9.9402 - 2 ? 0.704 ? 9.124 ? 9.940 10 -1 =3.459。 第三步 判断 根据自由度 df = n - 1 = 9 ,查 t 值表 t (9) 0.05 = 2.262 , t (9) 0.01 = 3.250 。由于实 际计算出来的 t =3.495>3.250= t (9) 0.01 ,则 P < 0.01,故拒绝原假设。 结论为:两次测验成绩有及其显著地差异。 由以上可以看出,对平均数差异显著性检验比较复杂,究竟使用 Z 检验还是 使用 t 检验必须根据具体情况而定,为了便于掌握各种情况下的 Z 检验或 t 检验,
第七章商品检验、索赔、不可抗力和仲裁练习题
第七章商品检验、索赔、不可抗力和仲裁 一、填空题 1.根据《中华人民共和国进出口商品检验法》和《中华人民共和国进出口商品检验法实施条例》的规定,出入境检验检疫机构的基本任务主要有:对重要商品实施;对所有进出口商品实施和办理对外贸易。 2.在我国,__________________________主管全国进出口商品检验工作,各地的__________________________管理所负责地区的进出口商品检验工作。 3. 是指对进出口商品的质量、数量、包装等进行检验的做法,包括抽样的数量及方法;是指检验机构从事检验工作中所遵循的尺度和准则。 4. 是指买卖双方之中任何一方违反合同义务的行为。《英国货物买卖法》将违约的形式划分为______________和______________两种。美国法把违约划分为______________和______________两类。《联合国国际货物销售公约》将违约划分为
______________ 和______________。 5.《联合国国际货物销售公约》是根据违约后果的严重性进行判断。是指一方当事人违反合同的结果,如使另一方当事人蒙受损害,以致于实际上剥夺了他根据合同规定有权期待得到的东西。 6.纵观各国法律,国际货物买卖中一方当事人违反合同时使对方的权利受到损害,守约方的救济方法主要有:、和三种。 7. 是指合同中规定如一方未履约或未完全履约,应向对方支付一定数量的金钱,以补偿对方损失。从性质上讲,违约金具有和双重性质。我国《合同法》认为违约金的支付并不解除违约方继续履行合同的义务。 8. 是合同中的一项免责条款。合同中对其范围的规定通常采取、和。 9.在国际贸易业务中,不可抗力事件所引起的法律后果,可能是,也可能