
Revman软件二分类变量meta分析方法(图示法)
丁香园ID:木一羊
目录
一、打开软件 .......................................... 错误!未定义书签。
二、创建一个新的系统评价 .............................. 错误!未定义书签。
三、添加纳入研究 ...................................... 错误!未定义书签。
四、添加比较和结局 .................................... 错误!未定义书签。
五、数据分析: ........................................ 错误!未定义书签。
六、亚组分析: ........................................ 错误!未定义书签。
七、敏感性分析: ...................................... 错误!未定义书签。
实例参考文献来源:《依帕司他治疗糖尿病周围神经病变疗效的Meta分析》
&CurRec=29&recid=&filename=CQYX6&dbname=CJFD2011&dbcode=CJFQ&pr=&urlid=&yx=& v=MjQzNzBETXA0OUZZb1I4ZVgxTHV4WVM3RGgxVDNxVHJXTTFGckNVUkwrZlkrWnJGQ3JtVUxyTU pqelNkckc0SDk=
RevMan5下载地址,,下载安装好后,出现这个图标。
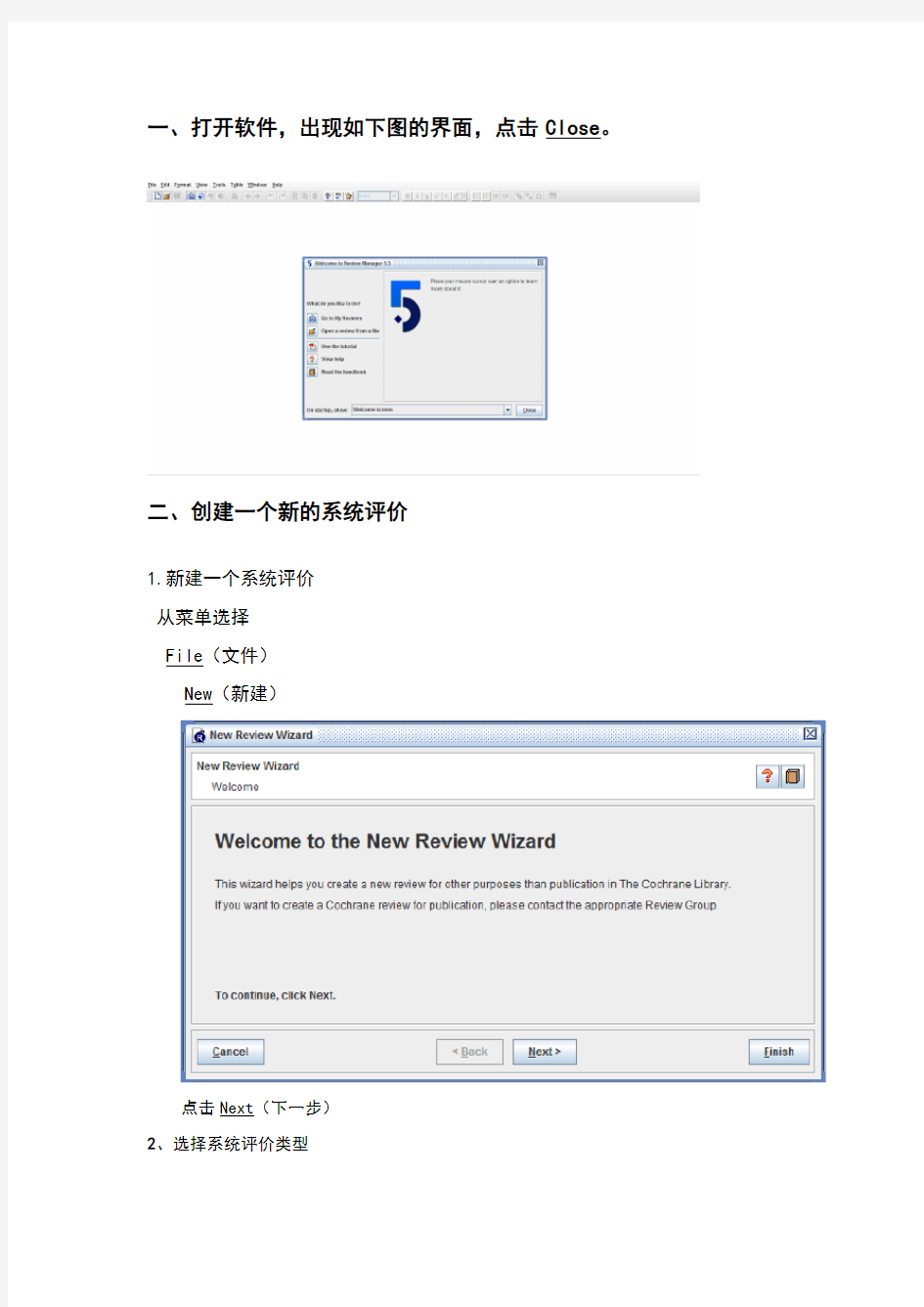
一、打开软件,出现如下图的界面,点击Close。
二、创建一个新的系统评价
1.新建一个系统评价
从菜单选择
File(文件)
New(新建)
点击Next(下一步)
2、选择系统评价类型
在此我选择Intervention review(干预评价)
点击Next(下一步)
3、输入系统评价的标题
以“依帕司他治疗糖尿病周围神经病变疗效的Meta分析”为例:
4、选择系统评价的类型
在此我选择Full review(全文)
点击Finish(完成)弹出界面如下:
三、添加纳入研究
1、展开面板
点击大纲面板中Studies and reference(研究和参考文献)旁的钥匙图标,再次点击References to studies(研究的参考文献)旁的钥匙图标,如下图:
2、添加纳入研究
右键点击Include studies(纳入研究)
选择Add Study(添加研究)
要此我用“谷明军2008”,注:研究名称通常为“作者+发表年份”
4、选择研究来源
点击Next(下一步)接受默认选项,,
注:可以选择四种来源:
①已发表研究(未检索未发表研究)
②已发表研究和未发表研究
③未发表研究
④已发表研究(检索但未包含未发表研究)
5、输入研究发表年份
点击Next(下一步),添加发表年份:
6、添加研究识别码
点击Next(下一步),添加研究识别码,本研究不添加。
7、添加下一个纳入研究
点击Next(下一步),选择Add another study in the same section(继续添加下一个研究)
点击Continue(继续)
重复上述步骤,完成所有文献的纳入8、展开面板
点击Included studies旁的钥匙图标,展开Included studies,可查看10项纳入研究已添加进RevMan中。
四、添加比较和结局
1、添加比较
右击Data and analysises(数据和分析)
选择Add Comparison(添加比较)
2、输入比较名称
在此我输入“依帕司他”
点击Next(下一步)
3、添加结局
选择Add an outcome under the new comparison(在该比较下添加结局)
4、选择数据类型
点击Continue(继续),选择Dichotomous(二分类变量),点击Next
5、输入结局名称
在此我输入“治疗DPN”
点击Next
6、选择分析方法
接受默认选项,点击Next
注:研究中常用的效应量指标包括:
①连续型变量资料有WMD(加权均数,weighted mean difference)和SMD(标准化均差standardized mean difference)。
②二分类资料的效应值指标有相对危险度(relativerisk,RR)、比值比(OddsRatio,
OR)、危险度差值(Risk difference,RD)。
③若为等级资料或多分类资料,由于受方法学限制,数据需要转化成上述两种类型。
④生存资料的效应指标是危险比(hazardratio,HR)有时候也可当作二分类变量处理,采用RR、OR或RD。
接受默认选项,点击Next
7、为结局添加相关研究
选择Add study data for the new outcome(为该结局添加研究数据)
点击Next(下一步)
8、选择纳入研究
按Ctrl,用鼠标左键点击纳入文献,选择全部10个纳入研究,点击Finish(完成)
9、录入数据:
(参考原文献)
实验组(EXperimental)对照组(Control)
纳入研究
有效数(Events)总例数(Total)有效数(Events)总例数(Total)刘海君20073340940
五、数据分析:
1、
I2=44%,存在中度异质性,所以用(随机效应模型),
点击(固定效应模型),变为(随机效应模型),
2.森林图,点击
但大家要注意红框内坐标的改变,点击,如下图
点击OK,点击,如下图:
参考文献中的左右坐标弄错了,为什么,大家参考文献《Meta分析的森林图及临床意义》
&CurRec=1&recid=&filename=ZZXZ0&dbname=CJFD2004&dbcode=CJFQ&pr=&urlid=&yx=&v =MjYzMDg3RGgxVDNxVHJXTTFGckNVUkwrZlkrWnFGaW5uVmJ6TFB6ZlRkTEc0SHRYTXJJOUVaSVI 4ZVgxTHV4WVM=
这个是保存图片(森林图也是一样),是保存在电硬盘里,保存为*.eps格式的可以在AI软件中进一步修图。得到的图片质量更高,这个根据编辑的要求,发SCI一般就要精修图。
粘贴复制,保存在本文件的中,如下图。
3、调整图像
点击
一般选项卡:
分析方法选项卡:
分析细节选项卡:
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率\回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。 列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的
技能训练十一属性数据分析 一、训练目的与要求 1.掌握属性数据分析方法。 2.掌握属性数据分析图表与原图形的组合。 二、训练准备 1.训练数据:本训练数据保存于文件夹Exercise-11中。 2.预备知识:属性分析的方法。 三、训练步骤与内容 1.数据准备 将训练数据复制,粘贴至各自文件夹内。 启动MAPGIS主程序。在主菜单界面中,点击参数按钮,在弹出的对话框中,设置工作目录最终指向Exercise-14(盘符依据各人具体情况设置)。 2.属性分析 执行如下命令:空间分析?空间分析?文件?装载区文件,加载要进行属性分析的数据文件。 Step1: 加载数据文件中所提供 的REGION.WP区文件 执行如下命令:属性分析?单属性分类统计?立体饼图,选择属性分析类型。
Step2: 属性 Step3: 选择分类属性字段为小麦,保留属性字段为乡名、水稻、玉米Step4: 设置分类方式为分段方式 Step5: 确定,退出设置 分类值域按图中所示输 入
分类统计结果图 3.保存文件 执行如下命令:文件?保存当前文件,换名保存属性分析所生成的图形文件,系统生成的表格文件(*.WB)不需要保存。 Step: 将缺省文件名改为“属性分析”,点 击保存按钮。按此方法依次将线、区 文件名均改为“属性分析” 4.文件组合 执行如下命令:图形处理?输入编辑?打开已有工程文件,打开所提供的Exercise-14.MPJ,在工程文件管理窗口,点击鼠标右键,选择“添加项目”选项,将前面生成的属性分析.WT、属性分析.WL、属性分析.WP添加进此工程文件。 关闭REGION.WP、POINT.WT、RIVER.WL和LINE.WL四个文件。 执行如下命令:其它?整块移动,调整属性分析.WT、属性分析.WL、属性分析.WP三个图形文件的位置,使与主图位置相适应。若此三个图形与主图相比过大的话,执行如下命令:其它?整图变换?键盘输入参数,来进行调整(注意应确定REGION.WP、POINT.WT、RIVER.WL 和LINE.WL四个文件处于关闭状态)。
数据分析中的变量分类 数据分析工作每天要面对各种各样的数据,每种数据都有其特定的含义、使用范围和分析方法,同一个数据在不同环境下的意义也不一样,因此我们想要选择正确的分析方法,得出正确的结论,首先要明确分析目的,并准确理解当前的数据类型及含义。统计学中的变量指的是研究对象的特征,我们有时也称为属性,例如身高、性别等。每个变量都有变量值,变量值就是我们分析的内容,它是没有含义的,只是一个参与计算的数字,所以我们主要关注变量的类型,不同的变量类型有不同的分析方法。 变量主要是用来描述事物特征,那么按照描述的粗劣,有以下两种划分方法: 按基本描述划分 【定性变量】:也称为名称变量、品质变量、分类变量,总之就是描述事物特性的变量,目的是将事物区分成互不相容的不同组别,变量值多为文字或符号,在分析时,需要转化为特定含义的数字。 定性变量可以再细分为: 有序分类变量:描述事物等级或顺序,变量值可以是数值型或字符型,可以进而比较优劣,如喜欢的程度:很喜欢、一般、不喜欢 无序分类变量:取值之间没有顺序差别,仅做分类,又可分为二分类变量和多分类变量二分类变量是指将全部数据分成两个类别,如男、女,对、错,阴、阳等,二分类变量是一种特殊的分类变量,有其特有的分析方法。多分类变量是指两个以上类别,如血型分为A、B、AB、O 【定量变量】:也称为数值型变量,是描述事物数字信息的变量,变量值就是数字,如长度、重量、产量、人口、速度和温度。 定量变量可以再细分 连续型变量:在一定区间内可以任意取值,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如身高、绳子的长度等。 离散型变量:值只能用自然数或整数单位计算,其数值是间断的,相邻两个数值之间不再有其他数值,这种变量的取值一般使用计数方法取得。 按照精确描述划分 【定类变量】
Meta分析的完整步骤 根据个人的体会,结合战友的经验总结而成,meta的精髓就是对文献的二次加工和定量合成,所以这个总结也算是对战友经验的meta分析吧。 —、选题和立题 (一)形成需要解决的临床问题: 系统评价可以解决下列临床问题: 1?病因学和危险因素研究; 2.治疗手段的有效性研究; 3.诊断方法评价; 4.预后估计; 5.病人费用和效益分析等。 进行系统评价的最初阶段就应对要解决的问题进行精确描述,包括人群类型(疾病确切分 型、分期)、治疗手段或暴露因素的种类、预期结果等,合理选择进行评价的指标。 (二)指标的选择直接影响文献检索的准确性和敏感性,关系到制定检索策略。 (三)制定纳入排除标准。 二、文献检索 (一)检索策略的制定 这是关键,要求查全和查准。推荐Mesh联合free word 检索。 (二)文献检索,获取摘要和全文 国内的有维普全文VIP, CNKI,万方数据库,外文的有medline ,SD ,OVID等。 (三)文献管理 强烈推荐使用endnote ,procite ,noteexpress 等文献管理软件进行检索和管理文献。 查找文献全文的途径: 在这里,讲一下找文献的过程,以请后来的战友们参考(不包括网上有电子全文的): 1.查找免费全文: (1 )在pubmed center 中看有无免费全文。有的时候虽然没有显示free full text ,但是 点击进去看全文链接也有提供免费全文的。我就碰到几次。
(2 )在google 中搜一下。 少数情况下,NCBI没有提供全文的,google 有可能会找到,使用“学术搜索”。本人虽然没能在google 中找到一篇所需的文献,但发现了一篇非常重要的综述,里面包含了所有我需要的文献(当然不是数据),但起码提供了一个信息,所需要的文献也就这么多了,因为老外的综述也只包含了这么多的内容。这样,至U底找多少文献,找什么文献,心里就更有底了。 (3)免费医学全文杂志网站。Www.freemedicaljournals. 。提供很过超过收费期的免费 全文。 2.图书馆查馆藏目录: 包括到本校的,当然方便,使用pubmed 的linkout看文献收录的数据库,就知道本校的 是否有全文。其它国内高校象复旦、北大、清华等医学院的全文数据库都很全,基本上都 有权限。上海的就有华东地区联目、查国内各医学院校的图书馆联目。这里给出几个: (1)中国高等院校医药图书馆协会的地址: server14.library.imicams.ac.c n/xiehui/che ngyua n. htm ,进入左侧的“现干刊联目”, 可以看到有“现刊联目查询”和“过刊联目查询”,当然,查询结果不可全信,里面有许多错误。本人最难找的两篇文章全部给出了错误的信息(后来电话联系证实的)。 (2)再给出两个比较好的图书馆索要文献的email地址(有偿服务),但可以先提供文献, 后汇钱,当然做为我们,一定要讲信誉吆。一是解放军医学图书馆信息部: xxbmlplas ina. ,:; (3)二是复旦大学医科图书馆(原上医):https://www.doczj.com/doc/ad9233276.html, ,联系人,周月琴,王蔚之, 郑荣,,2,需下载文献传递申请表(202.120.76.225/ill.doc )。其他的图书馆要么要求 先交开户费,比如协和(500元),要么嫌麻烦,虽然网上讲过可提供有偿服务,在这里我就不一一列出了。 3.请DXY战友帮忙,在馆藏文献互助站中发帖,注意格式正确,最好提供linkout的多个 数据库的全文链接,此时为帮助的人着想,就是帮助自己。自己也同时帮助别人查文献,一来互相帮助,我为人人,人人为我。二则通过帮助别人可以积分,同时学会如何发帖和下载全文,我就感觉通过帮助别人收获很大,自己积分越高,获助的速度和机会也就相应增加。现在不少免费的网络空间(我常用爱存www.isload..c n ),比发邮件简便
Meta分析的完整步骤 Meta分析的完整步骤,根据个人的体会,结合战友的经验总结而成,meta的精髓就是对文献的二次加工和定量合成,所以这个总结也算是对战友经验的meta分析吧。 一、选题和立题 (一)形成需要解决的临床问题: 系统评价可以解决下列临床问题: 1.病因学和危险因素研究; 2.治疗手段的有效性研究; 3.诊断方法评价; 4.预后估计; 5.病人费用和效益分析等。 进行系统评价的最初阶段就应对要解决的问题进行精确描述,包括人群类型(疾病确切分型、分期) 、治疗手段或暴露因素的种类、预期结果等,合理选择进行评价的指标。 (二)指标的选择直接影响文献检索的准确性和敏感性,关系到制定检索策略。 (三)制定纳入排除标准。 二、文献检索 (一)检索策略的制定 这是关键,要求查全和查准。推荐Mesh联合free word检索。 (二)文献检索,获取摘要和全文 国内的有维普全文VIP,CNKI,万方数据库,外文的有medline ,SD,OVID等。 (三)文献管理 强烈推荐使用endnote,procite,noteexpress等文献管理软件进行检索和管理文献。 查找文献全文的途径: 在这里,讲一下找文献的过程,以请后来的战友们参考(不包括网上有电子全文的): 1.查找免费全文: (1)在pubmed center中看有无免费全文。有的时候虽然没有显示free full text,但是点击进去看全文链接也有提供免费全文的。我就碰到几次。 (2)在google中搜一下。 少数情况下,NCBI没有提供全文的,google有可能会找到,使用“学术搜索”。本人虽然没能在google中找到一篇所需的文献,但发现了一篇非常重要的综述,里面包含了所有我需要的文献(当然不是数据),但起码提供了一个信息,所需要的文献也就这么多了,因为老外的综述也只包含了这么多的内容。这样,到底找多少文献,找什么文献,心里就更有底了。(3)免费医学全文杂志网站。。提供很过超过收费期的免费全文。 2.图书馆查馆藏目录: 包括到本校的,当然方便,使用pubmed的linkout看文献收录的数据库,就知道本校的是否有全文。其它国内高校象复旦、北大、清华等医学院的全文数据库都很全,基本上都有权限。上海的就有华东地区联目、查国内各医学院校的图书馆联目。这里给出几个: (1)中国高等院校医药图书馆协会的地址:,进入左侧的“现刊联目”,可以看到有“现刊联目查询”和“过刊联目查询”,当然,查询结果不可全信,里面有许多错误。本人最难找的两篇文章全部给出了错误的信息(后来电话联系证实的)。 (2)再给出两个比较好的图书馆索要文献的email地址(有偿服务),但可以先提供文献,后汇钱,当然做为我们,一定要讲信誉吆。一是解放军医学图书馆信息部:,电话:;
各种分布 泊松分布 Poisson分布,是一种统计与概率学里常见到的离散概率分布。 泊松分布的概率函数为: 泊松分布的参数λ是单位时间(或单位面积、单位体积)内随机事件的平均发生率。泊松分布适合于描述单位时间内随机事件发生的次数。 泊松分布的期望和方差均为 特征函数为: 泊松分布与二项分布 当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似,其中λ为np。通常当n≧10,p≦0.1时,就可以用泊松公式近似得计算。 事实上,泊松分布正是由二项分布推导而来的。 泊松分布可作为二项分布的极限而得到。一般的说,若 ,其中n很大, p很小,因而不太大时,X的分布接近于泊松分布。这个事实有时可将较难计算的二项分布转化为泊松分布去计算。 应用示例 泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,某放射性物质发射出的粒子,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。 卡方分布 卡方分布( 分布)是概率论与统计学中常用的一种概率分布。n 个独立的标准
正态分布变量的平方和服从自由度为n 的卡方分布。卡方分布常用于假设检验和置信区间的计算。 若n个相互独立的随机变量ξ?、ξ?、……、ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成 一新的随机变量,其分布规律称为卡方分布(chi-square distribution),即分布(chi-square distribution),其中参数n称为自由度。正如正态分布中均值或方差不同就是另一个正态分布一样,自由度不同就是另一个分布。记为或者。 卡方分布与正态分布 卡方分布是由正态分布构造而成的一个新的分布,当自由度n很大时,分布 近似为正态分布。对于任意正整数x,自由度为 k的卡方分布是一个随机变量X 的机率分布。 期望和方差 分布的均值为自由度n,记为E( ) = n。分布的方差为2倍的自由度(2n),记为D( ) = 2n。 均匀分布 均匀分布(Uniform Distribution)是概率统计中的重要分布之一。 顾名思义,均匀,表示可能性相等的含义。 (1) 如果,则称X服从离散的均匀分布。 (2) 设连续型随机变量X的概率密度函数为,则称随机变
实验十四属性数据分析 一、实验目的 1.掌握属性数据分析方法。 2.掌握属性数据分析图表与原图形的组合。 二、实验准备 1.实验数据:本实验数据保存于文件夹Exercise-14中。 2.预备知识:属性分析的方法。 三、实验步骤与内容 1.数据准备 将实验数据复制,粘贴至各自文件夹内。 启动MAPGIS主程序。在主菜单界面中,点击参数按钮,在弹出的对话框中,设置工作目录最终指向Exercise-14(盘符依据各人具体情况设置)。 2.属性分析 执行如下命令:空间分析?空间分析?文件?装载区文件,加载要进行属性分析的数据文件。 Step1: 加载数据文件中所提供 的REGION.WP区文件执行如下命令:属性分析?单属性分类统计?立体饼图,选择属性分析类型。
Step2: 属性 Step4: 设置分类方 式为分段方 式 Step3: 选择分类属 性字段为小 麦,保留属 性字段为乡 名、水稻、 玉米 Step5: 确定,退出 设置 分类值域按图中所示输 入
分类统计结果图 3.保存文件 执行如下命令:文件?保存当前文件,换名保存属性分析所生成的图形文件,系统生成的表格文件(*.WB)不需要保存。 Step: 将缺省文件名改为“属性分析”,点 击保存按钮。按此方法依次将线、区 文件名均改为“属性分析” 4.文件组合 执行如下命令:图形处理?输入编辑?打开已有工程文件,打开所提供的Exercise-14.MPJ,在工程文件管理窗口,点击鼠标右键,选择“添加项目”选项,将前面生成的属性分析.WT、属性分析.WL、属性分析.WP添加进此工程文件。 关闭REGION.WP、POINT.WT、RIVER.WL和LINE.WL四个文件。 执行如下命令:其它?整块移动,调整属性分析.WT、属性分析.WL、属性分析.WP三个图形文件的位置,使与主图位置相适应。若此三个图形与主图相比过大的话,执行如下命令:其它?整图变换?键盘输入参数,来进行调整(注意应确定REGION.WP、POINT.WT、RIVER.WL和LINE.WL四个文件处于关闭状态)。 完成后,保存此工程文件。
数据挖掘中客户的特征化及其划分(一) 摘要]良好客户关系已成为电子商务时代制胜的关键。在激烈的市场竞争中,客户关系管理逐渐成为企业关注的焦点。深入研究客户和潜在客户是在市场中保持竞争力的关键。本文通过对客户行为的特征化分析,以数据挖掘为分析工具,对客户关系管理进行了讨论,给出了相应的划分方法,使用这些划分方法,对客户进行分析是有意义的。 关键词]客户关系管理数据挖掘聚类分析 一、引言 在激烈的市场竞争中,客户关系管理(CustomerRelationshipManagement)逐渐成为各企业关注的焦点。一个成熟的CRM系统要能够有效地获取客户的各种信息,识别客户与企业间的关系及所有交互操作,寻找其中的规律,为客户提供个性化的服务,为企业决策提供支持。 在企业与客户的交互操作中,“二八原则”是值得借鉴的,即20%的客户对企业做出80%的利润贡献。但究竟谁是那20%的客户?又如何确定特定消费群体的消费习惯与消费倾向,进而推断出相应消费群体或个体下一步的消费行为?这都是企业需要认真研究的问题。 二、客户的特征化及其划分 企业认识客户和潜在客户是在市场保持竞争力的关键。特征分析是了解客户和潜在客户的极好方法,包括对感兴趣对象范围进行一般特征的度量。一旦知道带来最大利润客户的特征和行为,就可以直接将其应用到寻找潜在客户之中。有效寻找客户,认识哪些人群像自己的客户。因此,在争取客户的活动中,对感兴趣对象进行特征化及其划分是很有意义的。 对客户的特征化,顾名思义就是用数据来描述或给出客户(潜在客户)特征的活动。特征化可以在数据库(或数据库的不同部分)上进行。这些不同部分也称为划分,通常他们互不包含。 划分分析(SegmentationAnalysis)通常用于根据利润和市场潜力划分客户。如:零售商按客户在所有零售商店的总体购买行为,将客户划分为若干描述他们各自购买行为的区域,这样零售商可以评估哪些客户有最大利润。划分是把数据库分成互不相交部分或分区的活动。一般有两种方法:市场驱动法和数据驱动法。市场驱动法需要决定那些对业务有重要影响的特征,即需要预先选择一些特征变量(属性),以最终定义得到划分。数据驱动法是利用数据挖掘中的聚类技术或要素分析技术寻找同质群体。 三、数据挖掘的概念 数据挖掘(DataMining)是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的、事先未知的潜在有用信息。通过数据挖掘提取的知识表示为概念、规则、规律、模式等,它对企业的趋势预测和行为决策提供支持。 1.分类分析 分类是指将数据映射到预先定义好的群组或类。分类要求基于数据属性值来定义类别,通过数据特征来描述类别。根据它与预先定义好的类别相似度,划分到某一类中去。分类的主要应用是导出数据的分类模型,然后使用模型预测。 2.聚类分析 聚类是对抽象样本集合分组的过程。与分类不同之处在于聚类操作要划分的类是事先未知。按照同一类中对象之间较高相似度原则进行划分,目的是使同一类别个体之间距离尽可能小,不同类别中个体间距离尽可能大。类的形成是由数据驱动的。 3.关联规则 关联规则是从大量的数据中挖掘出有价值的描述数据项之间相互关联的知识。关联规则中有两个重要概念:支持度(Support)和信任度(Confidence)。它们是两个度量有关规则的方法,描述了被挖掘出规则的有用性和确定性。关联规则挖掘,希望发现事务数据库中数据项之间的关联,这些规则往往能反映客户的购买行为模式。
第九章 列联分析 一、填空题 1、设R 为列联表的行数,C 为列联表的列数,则进行拟合优度检验时所用统计量2χ的自由度为 。 2、设0f 为列联表中观察值频数,e f 为期望值频数,则进行拟合优度检验时所用统计量2χ= 。 3、在列联分析中,观察值总数为n ,RT 为列联表中给定单元的行合计,CT 为给定单元列合计,则该给定单元频数期望值为 。 4、在列联分析中,观察值总数为500,列联表中给定单元的行合计数为140,列合计数为162,则该给定单元频数期望值为 。 5、在3×4列联分析中,统计量2 2 0()e e f f f χ-=∑(其中0f 为观测值频数,e f 为期望值频数)的自由度为____________。 6、对来自三个地区的原料质量进行检验时,先把它们分成三个等级,在随机抽取400间进行检验,经分析得知原料质量与地区之间的关系实现著的,现计算得2300χ=,则?相关系数等于 。 7、?相关系数是描述两个分类变量之间相关程度的统计量,它主要用于描述 的列联表数据。 8、若两个分类变量之间完全相关。则?相关系数的取值为 。 9、当列联表中两个变量相互独立时,计算的列联相关系数C= 。 10、利用2 χ分布进行独立性检验,要求样本容量必须足够大,特别是每个单元中的期望频数e f 不能过小,如果只有两个单元,则每个单元的期望频数必须 。 二、单项选择题 1、列联分析是利用列联表来研究( ) A 、两个分类变量的关系 B 、两个数值型变量的关系 C 、一个分类变量和一个数值型变量的关系 D 、连个数值型变量的分布 2、设R 为列联表的行数,C 为列联表的列数,则进行拟合优度检验时所用统计量2χ的自由度为( ) A 、R B 、 C C 、R ×C D 、(R-1)×(C-1) 3、若两个分类变量之间完全相关。则?相关系数的取值为( ) A 、0 B 、小于1 C 、大于1 D 、1=? 4、当列联表中两个变量相互独立时,计算的列联相关系数C ( ) A 、等于1 B 、大于1 C 、等于0 D 、小于0 5、利用2χ分布进行独立性检验,要求样本容量必须足够大,特别是每个单元中的期望频数e f 不能过小,如果只有两个单元,则每个单元的期望频数必须( ) A 、等于或大于1 B 、 C 值等于?值 C 、等于或大于5 D 、等于或大于10 6、一所大学准备采取一项学生上网收费的措施,为了解男女学生对这一措施的看法,分别抽取了150名男生和120名女生进行调查,得到结果如下: A 、48和39 B 、102和81 C 、15和14 D 、25和19 7、一所大学准备采取一项学生上网收费的措施,为了解男女学生对这一措施的看法,分别抽取了150名
Meta分析方法及其医学科研价值与评价 在医学科研中,针对同一问题常常同时或者先后有许多类似的研究。由于研究对象数量的限制、各种干扰因数的影响以及研究本身的或然性等原因,许多研究结果可能不一致甚至相反。解决这个问题的方法有两种,一是通过严格设计的大规模随机试验进行验证;二是通过对这些研究及其结果的综合分析和再评价,即越来越受到重视的Meta分析。目前,Meta分析是循证医学(Evidence base Medicine)大量文献分析的核心方法,几乎成了循证医学的代名词。 有关Meta分析方法的介绍和研究零星见于一些统计学和临床流行病学专业文献。为正确认识和合理应用Meta分析方法,就Meta分析的基本步骤、统计分析方法及其在医学科研中的作用和存在问题予以论述。 一、Meta分析的基本思想和方法 Meta分析的基本思想产生于20世纪30年代,20世纪60年代开始应用于教育学和心理学等社会科学领域,70年代初Ligh和Smith正式提出可以对不同研究结果汇总数据进行综合分析,1976年由Glass首次命名为Meta analysis,其意思是“more comprehensivem”,即更加全面或超常规的综合,国内一般译为元分析或荟萃分析,但文献中多使用“Meta分析”一词。Glass对Meta分析的定义是:以综合已有的发现为目的,对单个研究结果进行综合的统计学分析方法;Sacks等的定义是:对以往的究所研究结果进行统计学的合并和严谨的系统综述方法。 Meta分析的基本方法是依靠搜集已有或未发表的具有某一可比特性的文献,应
用特定的设计和统计学方法进行分析与综合评价,对具有不同设计方法及不同病例数的研究结果进行综合比较。其基本步骤是: (1)提出需要并可能解决的问题;(2)确定检索策略,检索有关文献;(3)评价文献质量,剔除不满足要求的文献;(4)综合分析文献资料;(5)总结报告研究结果。文献资料综合分析是Meta分析的关键部分,包括定性分析和定量分析,其基本步骤是1)确定研究效应的统计指标,如计量资料检验统计量t值、u值、F值、相关系数r和计数资料的率、比值比(OR)、相对危险度(RR)、χ2值等;(2)对多个独立研究进行同质性检验(常用方法总结见表1);(3)对具有一致性的统计量进行加权合并,综合估计出平均统计量,对综合估计的统计量进行统计检验和统计判断,最后计算某些统计指标的95%可信区间(表2)。来自多个研究的2×2表的资料,通常采用Mantel Haenszel加权统计分析。多个研究的两组均数比较的统计结果,常用逆正态法和累计t值法等非参数Meta分析方法,这些方法只能给出P值而不能估计两组均数的差及其95%可信区间,并且只是将各个研究结果(单侧检验的P值)通过逆正态变换后相加而忽略了各研究样本量不同的影响。 二、Meta分析方法在医学中的应用及其作用 Meta分析方法于1955年首次被应用到医学研究,作者分析了15份单独研究结果,对1000余名不同疾病患者服用安慰剂的疗效进行综合分析,结果发现安慰剂竟具有35%“疗效”,即安慰剂效应。近年来, Meta分析在医学领域应用范围日益广泛,在诊断、治疗、危险度评价、干预措施、预防对策以及卫生决策等方面起着独特的作用。 Meta分析在临床科研中的应用最为广泛,特别是在心血管疾病药物防治研究方面应用较多。如1989年公布的心律失常抑制实验(Cardic Arrhythmia
中国循证心血管医学杂志2017年11月第9卷第11期 Chin J Evid Based Cardiovasc Med,November,2017,Vol.9,No.11? 1300 ?? 循证理论与实践 ? 中文期刊发表的剂量-反应Meta分析方法学质量及报告质量现状张维欣1,熊莺1,徐畅2,贾鹏丽2,刘玉3,张超4,李胜5 基金项目:武汉大学“351人才计划”珞珈青年学者科研基金 作者单位:1 610041 成都,四川大学华西公共卫生学院(华西 第四医院);2 610041 成都,四川大学华西医院中国循证医学中心; 3 730000 兰州,兰州大学循证医学中心; 4 442000 十堰,十堰市太和医 院(湖北医药学院附属)循证医学中心;5 442000 十堰,武汉大学中【摘要】目的 利用Meta分析方法学质量评价工具AMSTAR和报告质量评价工具PRISMA,对近年来在中文期刊发表的剂量反应Meta分析(DRMA)的方法学质量和报告质量进行评价。方法 计算机检索CNKI、WanFang Data、维普中文期刊服务平台以及CBM数据库,筛选中国作者发表的DRMA研究,检索时限为2010年1月1日~2016年12月31日。对纳入的DRMA研究,提取以下信息:第一作者学历、检索的数据库及数目、报告规范使用情况、是否有基金支持等。并对这些DRMA的方法学、报告质量进行评价,通过回归分析的方法探讨影响这些DRMA质量的潜在因素。结果 共纳入28篇DRMA。AMSTAR 的整体依从率为(45.5±0.11)%。其中有3个条目被所有研究报告(依从率:100%);2个条目未被任何一篇纳入的DRMA报告(依从率:0%)。PRISMA的依从率为(77.4±0.75)%。其中有7个条目的被所有研究报告(依从率100%);3个条目未被任何一篇纳入的DRMA报告(依从率:0%)。线性回归分析结果表明:AMSTAR依从率与第一作者学历(β=0.567,95%CI :-5.941~7.075)、作者数目(β=0.072,95%CI :-2.865~3.008)、是否有方法学家(β=-5.091,95%CI :-17.366~7.185)、发表年份(β=0.494,95%CI :-2.898~3.886)、是否有基金资助(β=-7.103,95%CI :-20.073~6.866)的关系无统计学意义。PRISMA依从率与第一作者学历(β=2.206,95%CI :-1.885~6.296)、作者数目(β=-1.065,95%CI :-2.910~0.781)、是否有方法学家(β=-0.735,95%CI :-8.451~0.981)发表年份(β=0.796,95%CI :-1.337~2.928)、是否有基金资助(β=-2.894,95%CI :-11.675~5.886)的关系无统计学意义。结论 发表在中文期刊的DRMA的方法学质量整体依从率较差,报告质量整体依从率适中。第一作者学历、发表年份、作者数目、有无方法学家、有无基金资助与DRMA方法学质量及报告质量无明显相关性。今后的DRMA应重视报告质量量表或规范的使用。 【关键词】剂量-反应Meta分析;方法学质量;报告质量 【中图分类号】R4 【文献标志码】 A 【文章编号】1674-4055(2017)11-1300-05 Methodological and reporting quality of dose-response meta-analyses published in Chinese journals Zhang Weixin *, Xiong Ying, Xu Chang, Jia Pengli, Liu Yu, Zhang Chao, Li Sheng. *West China School of Public Health, Sichuan University, Chengdu 610041, China. Corresponding author: LI Sheng, E-mail: 2010lisheng@https://www.doczj.com/doc/ad9233276.html, [Abstract ] Objective To assess the methodological and reporting quality of dose-response meta-analyses (DRMAs) published in Chinese journals by AMSTAR and PRISMA. Method CNKI, WanFang data, VIP and CBM were searched to collect DRMAs published in Chinese journals during 1st Jan, 2010 to 30th Dec, 2016. The following data including: education background of first author, database that being searched, the number of databases that being searched, whether reporting guidelines were used, whether being funded were extracted. The adherence of AMSTAR and PRISMA was assessed. Results A total of 28 DRMAs were included. The adherence of AMSTAR was 45.5%±0.11. The highest (100%) items were: providing the characteristics of the included studies, using appropriate methods to combine the findings of studies, assessing the likelihood of publication bias. The lowest items were: providing a priori design; stating the conflicts of interests. The adherence of PRISMA was 77.4%±0.75. The highest (100%) items were: describing the rationale, listing and define all variables, stating the principal summary measures, presenting characteristics of each study and results of each meta-analysis done, presenting results of the assessment of publication bias. The results of regression analyses showed that the relations between the adherence of AMSTAR and the education background of first author (β=0.57, 95%CI : -5.94~7.08); the number of authors (β=0.07, 95%CI : -2.87~3.01); whether there are methodologists (β=-5.09, 95%CI : -17.37~7.19), the year of publication (β=0.49, 95%CI : -2.90~3.89); whether there is funding (β=-7.10, 95%CI : -20.07~6.87) were not statistically significant. The relations between the adherence of PRISMA and the education background of first author (β=2.21, 95%CI : -1.89~6.30); the number of authors (β=-1.07, 95%CI : -2.91~0.78), whether 南医院生物样本库共同第一作者:熊莺通讯作者:李胜,E-mail:2010lisheng@https://www.doczj.com/doc/ad9233276.html, doi:10.3969/j.issn.1674-4055.2017.11.04
属性数据分析复习题 一、 填空(每题4分,共20分) 1. 按数据取值分类,人的身高,性别,受教育程度分别属于计量数据,名义数据,有序数据 2. 度量定性数据离散程度的量有离异比率, G-S 指数,熵 3. 分类数据的检验方法主要有2χ检验和似然比检验 4. 二值逻辑斯蒂线性回归模型的一般形式是011ln 1k k p x x p βββ=+++- 5. 二维列联表的对数线性非饱和模型有 3 种 二、 案例分析题(每题20分,共60分) 1.P40习题二1,给出上分位数20.05(5)11.07χ= 0123456:0.3,0.2,0.2,0.1,0.1,0.1H p p p p p p ====== 220.0518.0567(5)11.07χχ=>=,落入拒绝域,故拒绝原假设,即认为这些数据与 消费者对糖果颜色的偏好分布不相符 2.P42表 3.1独立性检验,给出上分位数2 0.05(1) 3.84χ= 012:H p p =(即认为肺癌患者中吸烟比例与对照组中吸烟比例相等) 112:H p p ≠
未连续性修正的: 22 2 2112212210.051212()106(6011332)9.6636(1) 3.8463439214n n n n n n n n n χχ++++-?-?===>=??? 带连续性修正的: 22 11221221220.051212(||)106(|6011332|53)27.9327(1) 3.8463439214 n n n n n n n n n n χχ++++--?-?-===>=??? 均落入拒绝域,故拒绝原假设,即认为肺癌患者中吸烟比例与对照组中吸烟比例不等 3.P83表 4.3 独立性检验,给出上分位数2 0.05(2) 5.99χ= 0:ij i j H p p p ++=(即认为男性和女性对啤酒的偏好无显著性差异) 220.0590.685(2) 5.99χχ=>=,落入拒绝域,故拒绝原假设,即认为男性和女性对 啤酒的偏好有显著性差异 三、简答(每题10分) 1.谈谈你对p 值的认识 P 值是: 1) 一种概率,一种在原假设为真的前提下出现观察样本以及更极端情况的概率。 2) 拒绝原假设的最小显著性水平。 3) 观察到的(实例的)显著性水平。 4) 表示对原假设的支持程度,是用于确定是否应该拒绝原假设的另一种方法。 P 值(P value )就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果P 值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P 值越小,我们拒绝原假设的理由越充分。总之,P 值越小,表明结果越显著。 统计学根据显著性检验方法所得到的P 值,一般以P < 0.05 为显著, P<0.01 为非常显著 2.写出三维列联表各种独立性之间的关系
M e t a分析的完整步骤内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)
Meta分析的完整步骤 Meta分析的完整步骤,根据个人的体会,结合战友的经验总结而成,meta的精髓就是对文献的二次加工和定量合成,所以这个总结也算是对战友经验的meta分析吧。 一、选题和立题 (一)形成需要解决的临床问题: 系统评价可以解决下列临床问题: 1.病因学和危险因素研究; 2.治疗手段的有效性研究; 3.诊断方法评价; 4.预后估计; 5.病人费用和效益分析等。 进行系统评价的最初阶段就应对要解决的问题进行精确描述,包括人群类型(疾病确切分型、分期)、治疗手段或暴露因素的种类、预期结果等,合理选择进行评价的指标。 (二)指标的选择直接影响文献检索的准确性和敏感性,关系到制定检索策略。(三)制定纳入排除标准。 二、文献检索 (一)检索策略的制定
这是关键,要求查全和查准。推荐Mesh联合freeword检索。 (二)文献检索,获取摘要和全文 国内的有维普全文VIP,CNKI,万方数据库,外文的有medline,SD,OVID等。(三)文献管理 强烈推荐使用endnote,procite,noteexpress等文献管理软件进行检索和管理文献。 查找文献全文的途径: 在这里,讲一下找文献的过程,以请后来的战友们参考(不包括网上有电子全文的): 1.查找免费全文: (1)在pubmedcenter中看有无免费全文。有的时候虽然没有显示 freefulltext,但是点击进去看全文链接也有提供免费全文的。我就碰到几次。(2)在google中搜一下。 少数情况下,NCBI没有提供全文的,google有可能会找到,使用“学术搜索”,进入左侧的“现刊联目”,可以看到有“现刊联目查询”和“过刊联目查询”“我的论坛”中查看帖子,有的很快就把下载链接发过来了,不要一味只看邮箱。 4.实在不行,给作者发email。这里给出一个查作者email的方法,先在NCBI中查出原文献作者的所有文章,注意不要只限于第一作者,display,abstract,并尽可能显示多的篇数,100,200,500。然后在网页内查找“@”,一般在@前的
Meta分析基本步骤 (一)提出问题,拟定研究计划。 选择临床热点问题:注意时效性 (二)检索相关文献。 (三)根据纳入、排除标准筛选文献 (四)提取纳入文献的数据信息 a)一般要求2人进行 b)事先设计表格 (五)纳入研究的质量评价 a)达不到分值标准可以排除 (六)资料的统计学处理 (七)敏感性分析 (八)结果分析和讨论 一、选题与立题 a)形成需要解决的临床问题 i.疾病的病因学探讨: ii.治疗方法效果评价:某方法是否优于另一种方法; iii.诊断方法评价:某因子在某肿瘤方面的预测作用; iv.生存预后分析 进行系统评价的最初阶段就应对要解决的问题进行精确描述,包括人群特征 (疾病分型、分期)、治疗手段或暴露因素的种类、预期结果等,合理选择进 行评价的指标。 b)结合自己的研究方向、平时阅读文献、科研讨论、参加学术会议等获得好的选题; 及时去Pubmed检索他人是否已发表 i.注意有无类似分析发表 ii.已发表结果评价,是否有再次分析的意义:(1)结果有无重大变化;(2)已发表结果有无缺陷 iii.对已发表2周内的文献进行评价(Letter) 二、文献检索 (一)检索策略的制定 要求查全和查准。推荐自由词(text word search)或医学主题词(medical subject headings(Me SH))检索 (二)文献检索,获取全文 国内的有维普全文VIP、CNKI、万方数据库
外文的有Pubmed、OVID、Embase(Scopus可能包含,可以替代)等 获取全文途径: Pubmed Goole学术搜索 给通讯作者发email 向国外朋友求助 零点花园(https://www.doczj.com/doc/ad9233276.html,/bbs/)、丁香园等文献求助版块 (三)文献管理 推荐使用endnot、noteexpress和医学文献王等文献管理软件进行检索和管理文 献 三、纳入和排除标准 1、制定标准考虑四个方面 a)研究对象:疾病类型、年龄、性别、病情严重程度等作出明确规定; b)研究设计类型:明确规定哪些类型的设计可以纳入: c)暴露或干预措施:暴露或处理的程度、一致性;干预措施的剂量、强度、病例 依从性等; d)研究结局:量化的、可比的研究结局、随访年限。 另外:类似文献的标准可作参考 2、筛选文献严格按照标准筛选文献。两名研究人员完成。 四、文献质量评价和数据收集 (一)研究的质量评价 RCT研究:包括改良版Jadad量表(1-3分视为低质量,4-7分视为高质量)和Cochrane Handbook 5.0 RCT 质量评价等。 改良版Jadad量表: 1.随机序列的产生: a)恰当:计算机产生的随机数字或类似方法(2分) b)不清楚:随机实验但未描述随机分配的方法(1分) c)不恰当:采用交替分配的方法如单双号(0分) 2.随机化隐藏: a)恰当:中心或药房控制分配方案,或用序列编号一致的容器,现场计算机 控制,密封不透光的信封或其他使临床医生和受试者无法得知分配序列的 方法(2分) b)不清楚:只表明使用随机数字表或其他随机分配方案(1分) c)不恰当:交替分配、病例号、星期日数、开放式随机号码表、系列编码信 封以及任何不能防止分组的可预测性的措施(0分) d)不使用(0分) 3.盲法: