
贝叶斯网络 贝叶斯网络是一系列变量的联合概率分布的图形表示。 一般包含两个部分,一个就是贝叶斯网络结构图,这是一个有向无环图(DAG),其中图中的每个节点代表相应的变量,节点之间的连接关系代表了贝叶斯网络的条件独立语义。另一部分,就是节点和节点之间的条件概率表(CPT),也就是一系列的概率值。如果一个贝叶斯网络提供了足够的条件概率值,足以计算任何给定的联合概率,我们就称,它是可计算的,即可推理的。 3.5.1 贝叶斯网络基础 首先从一个具体的实例(医疗诊断的例子)来说明贝叶斯网络的构造。 假设: 命题S(moker):该患者是一个吸烟者 命题C(oal Miner):该患者是一个煤矿矿井工人 命题L(ung Cancer):他患了肺癌 命题E(mphysema):他患了肺气肿 命题S对命题L和命题E有因果影响,而C对E也有因果影响。 命题之间的关系可以描绘成如右图所示的因果关系网。 因此,贝叶斯网有时也叫因果网,因为可以将连接结点的弧认为是表达了直接的因果关系。 图3-5 贝叶斯网络的实例 图中表达了贝叶斯网的两个要素:其一为贝叶斯网的结构,也就是各节点的继承关系,其二就是条件概率表CPT。若一个贝叶斯网可计算,则这两个条件缺一不可。 贝叶斯网由一个有向无环图(DAG)及描述顶点之间的概率表组成。其中每个顶点对应一个随机变量。这个图表达了分布的一系列有条件独立属性:在给定了父亲节点的状态后,每个变量与它在图中的非继承节点在概率上是独立的。该图抓住了概率分布的定性结构,并被开发来做高效推理和决策。 贝叶斯网络能表示任意概率分布的同时,它们为这些能用简单结构表示的分布提供了可计算优势。 假设对于顶点xi,其双亲节点集为Pai,每个变量xi的条件概率P(xi|Pai)。则顶点集合X={x1,x2,…,xn}的联合概率分布可如下计算: 。 双亲结点。该结点得上一代结点。
五种贝叶斯网分类器的分析与比较 摘要:对五种典型的贝叶斯网分类器进行了分析与比较。在总结各种分类器的基础上,对它们进行了实验比较,讨论了各自的特点,提出了一种针对不同应用对象挑选贝叶斯网分类器的方法。 关键词:贝叶斯网;分类器;数据挖掘;机器学习 故障诊断、模式识别、预测、文本分类、文本过滤等许多工作均可看作是分类问题,即对一给定的对象(这一对象往往可由一组特征描述),识别其所属的类别。完成这种分类工作的系统,称之为分类器。如何从已分类的样本数据中学习构造出一个合适的分类器是机器学习、数据挖掘研究中的一个重要课题,研究得较多的分类器有基于决策树和基于人工神经元网络等方法。贝叶斯网(Bayesiannetworks,BNs)在AI应用中一直作为一种不确定知识表达和推理的工具,从九十年代开始也作为一种分类器得到研究。 本文先简单介绍了贝叶斯网的基本概念,然后对五种典型的贝叶斯网分类器进行了总结分析,并进行了实验比较,讨论了它们的特点,并提出了一种针对不同应用对象挑选贝叶斯分类器的方法。 1贝叶斯网和贝叶斯网分类器 贝叶斯网是一种表达了概率分布的有向无环图,在该图中的每一节点表示一随机变量,图中两节点间若存在着一条弧,则表示这两节点相对应的随机变量是概率相依的,两节点间若没有弧,则说明这两个随机变量是相对独立的。按照贝叶斯网的这种结构,显然网中的任一节点x均和非x的父节点的后裔节点的各节点相对独立。网中任一节点X均有一相应的条件概率表(ConditionalProbabilityTable,CPT),用以表示节点x在其父节点取各可能值时的条件概率。若节点x无父节点,则x的CPT为其先验概率分布。贝叶斯网的结构及各节点的CPT定义了网中各变量的概率分布。 贝叶斯网分类器即是用于分类工作的贝叶斯网。该网中应包含一表示分类的节点C,变量C的取值来自于类别集合{C,C,....,C}。另外还有一组节点x=(x,x,....,x)反映用于分类的特征,一个贝叶斯网分类器的结构可如图1所示。 对于这样的一贝叶斯网分类器,若某一待分类的样本D,其分类特征值为x=(x,x,....,x),则样本D属于类别C的概率为P(C=C|X=x),因而样本D属于类别C的条件是满足(1)式: P(C=C|X=x)=Max{P(C=C|X=x),P(C=C|X=x),...,P(C=C|X=x)}(1) 而由贝叶斯公式 P(C=C|X=x)=(2) 其中P(C=Ck)可由领域专家的经验得到,而P(X=x|C=Ck)和P(X=x)的计算则较困难。应用贝叶斯网分类器分成两阶段。一是贝叶斯网分类器的学习(训练),即从样本数据中构造分类器,包括结构(特征间的依赖关系)学习和CPT表的学习。二是贝叶斯网分类器的推理,即计算类结点的条件概率,对待分类数据进行分类。这两者的时间复杂性均取决于特征间的依赖程度,甚至可以是NP完全问题。因而在实际应用中,往往需
用于运动识别的聚类特征融合方法和装置 提供了一种用于运动识别的聚类特征融合方法和装置,所述方法包括:将从被采集者的加速度信号 中提取的时频域特征集的子集内的时频域特征表示成以聚类中心为基向量的线性方程组;通过求解线性方程组来确定每组聚类中心基向量的系数;使用聚类中心基向量的系数计算聚类中心基向量对子集的方差贡献率;基于方差贡献率计算子集的聚类中心的融合权重;以及基于融合权重来获得融合后的时频域特征集。 加速度信号 →时频域特征 →以聚类中心为基向量的线性方程组 →基向量的系数 →方差贡献率 →融合权重 基于特征组合的步态行为识别方法 本发明公开了一种基于特征组合的步态行为识别方法,包括以下步骤:通过加速度传感器获取用户在行为状态下身体的运动加速度信息;从上述运动加速度信息中计算各轴的峰值、频率、步态周期和四分位差及不同轴之间的互相关系数;采用聚合法选取参数组成特征向量;以样本集和步态加速度信号的特征向量作为训练集,对分类器进行训练,使的分类器具有分类步态行为的能力;将待识别的步态加速度信号的所有特征向量输入到训练后的分类器中,并分别赋予所属类别,统计所有特征向量的所属类别,并将出现次数最多的类别赋予待识别的步态加速度信号。实现简化计算过程,降低特征向量的维数并具有良好的有效性的目的。 传感器 →样本及和步态加速度信号的特征向量作为训练集 →分类器具有分类步态行为的能力 基于贝叶斯网络的核心网故障诊断方法及系统 本发明公开了一种基于贝叶斯网络的核心网故障诊断方法及系统,该方法从核心网的故障受理中心采集包含有告警信息和故障类型的原始数据并生成样本数据,之后存储到后备训练数据集中进行积累,达到设定的阈值后放入训练数据集中;运用贝叶斯网络算法对训练数据集中的样本数据进行计算,构造贝叶斯网络分类器;从核心网的网络管理系统采集含有告警信息的原始数据,经贝叶斯网络分类器计算获得告警信息对应的故障类型。本发明,利用贝叶斯网络分类器构建故障诊断系统,实现了对错综复杂的核心网故障进行智能化的系统诊断功能,提高了诊断的准确性和灵活性,并且该系统构建于网络管理系统之上,易于实施,对核心网综合信息处理具有广泛的适应性。 告警信息和故障类型 →训练集 —>贝叶斯网络分类器
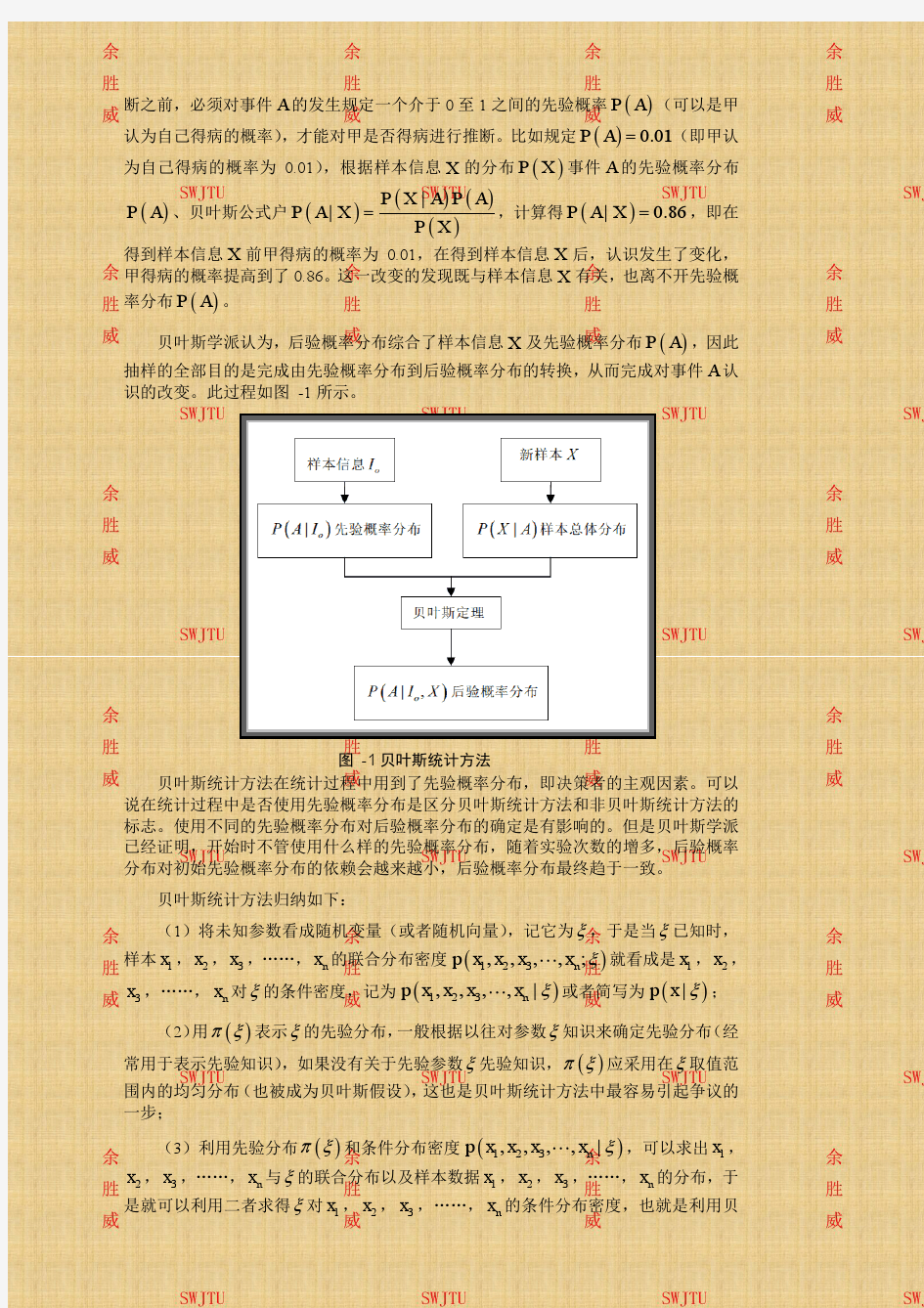
第五章贝叶斯统计 5.1 简介 到目前为止,我们已经知道了大量的不同的概率模型,并且我们前面已经讨论了如何用它们去拟合数据等等。前面我们讨论了如何利用各种先验知识,计算MAP参数来估计θ=argmax p(θ|D)。同样的,对于某种特定的请况,我们讨论了如何计算后验的全概率p(θ|D)和后验的预测概率密度p(x|D)。当然在以后的章节我们会讨论一般请况下的算法。 5.2 总结后验分布 后验分布总结关于未知变量θ的一切数值。在这一部分,我们讨论简单的数,这些数是可以通过一个概率分布得到的,比如通过一个后验概率分布得到的数。与全面联接相比,这些统计汇总常常是比较容易理解和可视化。 5.2.1最大后验估计 通过计算后验的均值、中值、或者模型可以轻松地得到未知参数的点估计。在5.7节,我们将讨 论如何利用决策理论从这些模型中做出选择。典型的后验概率均值或者中值是估计真实值的恰当选择,并且后验边缘分布向量最适合离散数值。然而,由于简化了优化问题,算法更加高效,后验概率模型,又名最大后验概率估计成为最受欢迎的模型。另外,通过对先验知识的取对数来正 则化后,最大后验概率可能被非贝叶斯方法解释(详情参考6.5节)。 最大后验概率估计模型在计算方面该方法虽然很诱人,但是他有很多缺点,下面简答介绍一下。在这一章我们将更加全面的学习贝叶斯方法。 图5.1(a)由双峰演示得到的非典型分布的双峰分布,其中瘦高蓝色竖线代表均值,因为他接近 大概率,所以对分布有个比较好的概括。(b)由伽马绘图演示生成偏态分布,它与均值模型完全不同。 5.2.1.1 无法衡量不确定性 最大后验估计的最大的缺点是对后验分布的均值或者中值的任何点估计都不能够提供一个不确定性的衡量方法。在许多应用中,知道给定估计值的置信度非常重要。我们在5.22节将讨论给出后验估计置信度的衡量方法。 5.2.1.2 深耕最大后验估计可能产生过拟合
1.选题:本课题国内外研究现状述评,提出选题的背景及意义。 2.目标与内容: 本课题研究拟完成的研究目标和主要研究内容,研究内容要对?拟解决的问题进行具体化。3、研究思路与方法:本课题研究的技术路线、方法和计划。4.预期价值:本课题理论创新程度和实践应用价值。(课题设计论证限3000字以内) 一直以来如何有效的提高学生的学习效率和教师的教学效率不断的得到大量的研究,近二十年以来,随着计算机信息技术和互联网应用的飞速发展,在教育心理学中正在发生着一场革命,应用建构主义的学习理论(Slavin, 1994)来指导改革教学成为一大趋势。建构主义学习理论从“学习的含义”(即关于“什么是学习”)与“学习的方法”(即关于“如何进行学习”)这两个角度说明学习的影响因素及提高学习效率的方法,建构主义学习理论认为学习是在一定的基础知识之上,在一定的情境即社会文化背景下,借助其他人的帮助即通过人际间的协作活动而实现的意义建构过程。“情境”、“协作”、“会话”和“意义建构”是学习环境中的四大要素或四大属性。所谓“情境”即是学习的综合环境;“协作”: 指学习中与他人的沟通与合作;“会话”:学习小组成员之间通过会话商讨如何完成规定的学习任务的计划;“意义建构”:建构事物的性质、规律以及事物之间的内在联系,是整个学习过程的最终目标。建构主义的学生观、教师观和知识观和以往的学习理论有了很大的变化,应用建构主义学习理论来提高教学效率正成为当前的研究热点,但目前的研究多从学习的方法论和学习技术本身入手,考虑学生的具体群体的学习特点较少,不能很好的有的放矢,在分析学生的学习影响因素时多直接用常规的数理统计理论进行分析与讨论,而实际上影响学生的学习因素是相当复杂与繁多的,而且学习因素之间W能存在相互的因果关系,而这种因果关系有时往往不知道,因素之间的影响到底多大,定量的关系不明确,甚至可能有很多隐藏的因素在起作用,发现学习的各种影响因素及其因果关系与比重,以及它们的变化分布规律对我们找出主要因素从而正确指导教学以及设计调查问卷摸查学生的学习基础与学习特点对教师的教学设计和提高教学效率具有重要意义,目前对此的研究还比较少。 贝叶斯网络又称信度网络,是Bayes方法的扩展,是目前不确定知识表达和推理领域最有效的理论模型之一。自1988年由Pearl提出后,己知成为近几年来研究的热点一般的贝叶斯网络结构是一个有向无环图(Directed Acyclic Graph,DAG),如图1所示,由代表变量节点及连接这些节点有向边构成。节点代表随机变量,节点间的有向边代表了节点间的互相关系(由父节点指向其后代节点),用条件概率进行表达关系强度,没有父节点的用先验概率进行信息表达, 节点变量可以是任何问题的抽象(如知识表达),适用于表达和分析不确定性和概率性的事件,可以从不完全、不精确或不确定的知识或信息中做出推理。贝叶斯网络本身是一种不确定性因果关联模型,贝叶斯网络与其他决策模型不同,它本身是将多元知识图解可视化为一种概率知识表近与推理模型,更为贴切地蕴含了网络节点,变量之间的因果关系及条件相关关系,如果节点表达为学习因素,
哈尔滨学院本科毕业论文(设计)题目:贝叶斯公式公式在数学模型中的应用 院(系)理学院 专业数学与应用数学 年级2009级 姓名鲁威学号09031213 指导教师张俊超职称讲师 2013 年6月1 日
目录 摘要 (1) Abstract (2) 前言 (3) 第一章贝叶斯公式及全概率公式的推广概述..................................... 错误!未定义书签。 1.1贝叶斯公式与证明 (5) 1.1贝叶斯公式及其与全概率公式的联系 (5) 1.3贝叶斯公式公式推广与证明 (6) 1.3.1贝叶斯公式的推广 (6) 1.4贝叶斯公式的推广总结 (7) 第二章贝叶斯公式在数学模型中的应用 (8) 2.1数学建模的过程 (8) 2.2贝叶斯中常见的数学模型问题 (9) 2.2.1 全概率公式在医疗诊断中的应用 (9) 2.2.2全概率公式在市场预测中的应用 (11) 2.2.3全概率公式在信号估计中的应用. ...................................... 错误!未定义书签。 2.2.4全概率公式在概率推理中的应用 (15) 2.2.5全概率公式在工厂产品检查中的应用 ................................ 错误!未定义书签。 2.3全概率公式的推广在风险决策中的应用 (17) 2.3.1背景简介 (17) 2.3.2风险模型 (18) 2.3.3实例分析 (18) 第三章总结 (21) 3.1贝叶斯公式的概括 (21) 3.2贝叶斯公式的实际应用 (21) 结束语 (23) 参考文献 (24) 后记 (25)
贝叶斯决策模型及实例分析 一、贝叶斯决策的概念 贝叶斯决策,是先利用科学试验修正自然状态发生的概率,在采用期望效用最大等准则来确定最优方案的决策方法。 风险型决策是根据历史资料或主观判断所确定的各种自然状态概率(称为先验概率),然后采用期望效用最大等准则来确定最优决策方案。这种决策方法具有较大的风险,因为根据历史资料或主观判断所确定的各种自然状态概率没有经过试验验证。为了降低决策风险,可通过科学试验(如市场调查、统计分析等)等方法获得更多关于自然状态发生概率的信息,以进一步确定或修正自然状态发生的概率;然后在利用期望效用最大等准则来确定最优决策方案,这种先利用科学试验修正自然状态发生的概率,在采用期望效用最大等准则来确定最优方案的决策方法称为贝叶斯决策方法。 二、贝叶斯决策模型的定义 贝叶斯决策应具有如下内容 贝叶斯决策模型中的组成部分: ) ( ,θ θP S A a及 ∈ ∈。概率分布S P∈ θ θ) (表示决策 者在观察试验结果前对自然θ发生可能的估计。这一概率称为先验分布。 一个可能的试验集合E,E e∈,无情报试验e0通常包括在集合E之内。 一个试验结果Z取决于试验e的选择以Z0表示的结果只能是无情报试验e0的结果。 概率分布P(Z/e,θ),Z z∈表示在自然状态θ的条件下,进行e试验后发生z结果的概
率。这一概率分布称为似然分布。 c 以及定义在后果集合C的效用函数u(e,Z,a,θ)。 一个可能的后果集合C,C 每一后果c=c(e,z,a,θ)取决于e,z,a和θ。.故用u(c)形成一个复合函数u{(e,z,a,θ)},并可写成u(e,z,a,θ)。 三、贝叶斯决策的常用方法 3.1层次分析法(AHP) 在社会、经济和科学管理领域中,人们所面临的常常是由相互关联,相互制约的众多因素组成的复杂问题时,需要把所研究的问题层次化。所谓层次化就是根据所研究问题的性质和要达到的目标,将问题分解为不同的组成因素,并按照各因素之间的相互关联影响和隶属关系将所有因素按若干层次聚集组合,形成一个多层次的分析结构模型。 3.1.1层次分析模型 最高层:表示解决问题的目的,即层次分析要达到的目标。 中间层:表示为实现目标所涉及的因素,准则和策略等中间层可分为若干子层,如准则层,约束层和策略层等。 最低层:表示事项目标而供选择的各种措施,方案和政策等。 3.1.2层次分析法的基本步骤 (l) 建立层次结构模型 在深入分析研究的问题后,将问题中所包括的因素分为不同层次,如目标层、指标层和措施层等并画出层次结构图表示层次的递阶结构和相邻两层因素的从属关系。 (2) 构造判断矩阵 判断矩阵元素的值表示人们对各因素关于目标的相对重要性的认识。在相邻的两个层次中,高层次为目标,低层次为因素。 (3) 层次单排序及其一致性检验 判断矩阵的特征向量W经过归一化后即为各因素关于目标的相对重要性的排序权值。利用判断矩阵的最大特征根,可求CI和CR值,当CR<0.1时,认为层次单排序的结果有满意的一致性;否则,需要调整判断矩阵的各元素的取值。 (4) 层次总排序 计算某一层次各因素相对上一层次所有因素的相对重要性的排序权值称为层次总排序。由于层次总排序过程是从最高层到最低层逐层进行的,而最高层是总目标,所以,层次总排序也是计算某一层次各因素相对最高层(总目标)的相对重要性的排序权值。 设上一层次A包含m个因素A1,A2,…,A m其层次总排序的权值分别为a1,a2,…,a m;下一层次B包含n个因素B1,B2,…,B n,它们对于因素A j(j=1,2,…,m)的层次单排序权值分别为:b1j,b2j,…,b nj(当B k与A j无联系时,b kj=0),则B层次总排序权值可按下表计算。 层次总排序权值计算表
贝叶斯网络预测信用卡欺诈行为 ——贝叶斯网络应用(1) 一、理论说明 1.贝叶斯网络的应用 使用贝叶斯网络,可以通过将观察到并记录下的数据与实际常识结合起来构建概率模型,以通过使用表面看上去不相关的属性确定发生的可能性,找出一个结果到底与哪些影响变量相关,或者说,究竟是什么因素影响了结果。 贝叶斯分类模型继承了贝叶斯网络的优点并具有良好的分类精度,正受到越来越多的关注,并广泛的应用在欺诈识别、客户管理、医学诊断上、互联网搜索上,比如,利用贝叶斯分类模型建立客户的等级分类,如信用等级、忠诚等级,当新客户出现时,即可以按该分类模型对其等级情况做出分类预测。又比如本文所例举的,根据信用卡用户的信用记录及相关信息建立用户的信用模型,并监测哪些用户会做出贷款拖欠的行为。 2.贝叶斯网络模型 (1)贝叶斯原理 统计学分成两派,一派是传统的频率学派,一派是贝叶斯派,能够在统计学界自成一派,可见其影响。贝叶斯的核心思想在于一个公式 P(A|X)=P(X|A)·P(A)/P(X) 其中A是随机变量,X是数据,P(X|A)是似然,P(A)是先验分布,P(A|X)是后验分布,P(X)是一个数。 这个公式的意义在于,我们可以通过一个经验的概率,加上数据的实践,来得出一个后验的概率,也就是说“经验+数据=结果”。那么将这个原理用在贝叶斯网络上,即将先验贝叶斯网络和数据相结合而得到一个后验贝叶斯网络。那么什么是贝叶斯网络? (2)贝叶斯网络模型概述 贝叶斯网络(Bayesian network),又叫概率因果网络、信任网络、知识图等,是一种有向无环图。一个贝叶斯网络由两个部分构成,一个是具有K个节点的有向无环图,图中有节点和连接节点的有向边,节点代表随机变量,有向边代表了节点间的相互关联关系。 另一个是与每个节点相关的条件概率表(Conditional Probabilities Table,CPT)P,它表示了节点和父节点之前的相关关系,这个关系就是条件概率。那么由这个图G和概率表P构成的网络就是贝叶斯网络,贝叶斯网络有如下假设(或者规定): 给定一个父节点,那么它的子节点独立于任何非这个子节点的后代节点和其构成的任何节点子集。即如果用A(V i)表示非V i后代节点构成的任何节点子集,用∏(V i)表示V i的直接双亲节点,则 p(Vi|A(Vi),∏(V i))=p(Vi|∏(Vi)) 在这个假定下,变量Vi的联合概率就是:给定每个节点的父节点情况下,每个节点条件概率只积,如图中的联合概率为 p(V1,V2,...,V6)=p(V6|V5)·p(V5|V2,V3)·p(V4|V2)·p(V3|V1)·p(V2|V1)·p(V1) 这就是贝叶斯网络和其网络的概率。我们可以让贝叶斯网络通过数据不断的学习修正,上次修正的贝叶斯网络又是下次学习的先验贝叶斯网络,持续的学习使得网络更能体现数据的意义,即,让数据来说话! (2)树增强朴素贝叶斯网络模型概述 尽管贝叶斯网络有良好的逻辑性、预测性、并在处理复杂问题上有很大的优势,但它的假
Computer Science and Application 计算机科学与应用, 2020, 10(3), 493-504 Published Online March 2020 in Hans. https://www.doczj.com/doc/e67387063.html,/journal/csa https://https://www.doczj.com/doc/e67387063.html,/10.12677/csa.2020.103052 The Bibliometric Analysis of Current Studies and Developing Trends on Bayesian Network Research Zhongzheng Xiao1, Nurbol2, Hongyang Liu3 1College of Information Science and Engineering, Xinjiang University, Urumqi Xinjiang 2Network Center, Xinjiang University, Urumqi Xinjiang 3Xichang Satellite Launch Center, Xichang Sichuan Received: Feb. 26th, 2020; accepted: Mar. 12th, 2020; published: Mar. 19th, 2020 Abstract In this paper, 2,930 literatures related to Bayesian network in the recent 10 years in the web of science were taken as the research object. Based on the literature metrological content analysis method, the focus, development rules of research context, existing commonalities and differences, and research status at home and abroad were systematically reviewed. The study found that, as of now, especially in the prevalence of neural networks, Bayesian networks can be deepened and have great potential because of their strong mathematical interpretability. The analysis results are helpful to provide reference for the research status and progress of scholars in the field of Bayesian network research in China. Keywords Bayesian Network, Map Analysis, Citespace, Research Context 贝叶斯网络研究现状与发展趋势的文献计量 分析 肖中正1,努尔布力2,刘宏阳3 1新疆大学信息科学与工程学院,新疆乌鲁木齐 2新疆大学网络中心,新疆乌鲁木齐 3西昌卫星发射中心,四川西昌 收稿日期:2020年2月26日;录用日期:2020年3月12日;发布日期:2020年3月19日
贝叶斯预测模型 贝叶斯预测模型的概述 贝叶斯预测模型是运用贝叶斯统计进行的一种预测.贝叶斯统计不同于一般的统计方法,其不仅利用模型信息和数据信息,而且充分利用先验信息。 托马斯·贝叶斯(Thomas Bayes)的统计预测方法是一种以动态模型为研究对象的时间序列预测方法。在做统计推断时,一般模式是: 先验信息+总体分布信息+样本信息→后验分布信息 可以看出贝叶斯模型不仅利用了前期的数据信息,还加入了决策者的经验和判断等信息,并将客观因素和主观因素结合起来,对异常情况的发生具有较多的灵活性。这里以美国1960—2005年的出口额数据为例,探讨贝叶斯统计预测方法的应用。 [编辑] Bayes预测模型及其计算步骤 此处使用常均值折扣模型,这种模型应用广泛而且简单,它体现了动态现行模型的许多基本概念和分析特性。 常均值折扣模型 对每一时刻t常均值折模型记为DLM{1,1,V,δ},折扣因子δ,O<δ 推论2:μt的后验分布()~N [m t,C t],其中m t = m t? 1 + A t e t,C t = A T v t,A t = R t / Q t,e t = y t? f t 由于Rt=Ct-1+Wt=Ct-1/δ,故有W? t = C t? 1(δ? 1? 1) 其计算步骤为: (1)R t = C? t/ δ;(2)Q t = R t + V; (3)A t = R t / Q t;(4)f t? 1 = m t? 1; (5)e t? y t? f t? 1;(6)C t = A t V; (7)m t? m t? 1 + A t e t [编辑] 计算实例 根据The SAS System for Windows 9.0所编程序,对美国出口额(单位:十亿元)变化进行了预测。选取常均值折扣模型和抛物线回归模型。 美国出口额的预测,预测模型的初始信息为m0=304,Co=72,V=0.Ol,δ=0.8得到的1960—2006年的预测结果。见表2中给出了预测的部分信息(1980—2006年的预测信息)。 算法杂货铺——分类算法之贝叶斯网络(Bayesian networks) 2010-09-18 22:50 by EricZhang(T2噬菌体), 2561 visits, 网摘, 收藏, 编辑 2.1、摘要 在上一篇文章中我们讨论了朴素贝叶斯分类。朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。 2.2、重新考虑上一篇的例子 上一篇文章我们使用朴素贝叶斯分类实现了SNS社区中不真实账号的检测。在那个解决方案中,我做了如下假设: i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。 ii、日志密度、好友密度和是否使用真实头像在账号真实性给定的条件下是独立的。 但是,上述第二条假设很可能并不成立。一般来说,好友密度除了与账号是否真实有关,还与是否有真实头像有关,因为真实的头像会吸引更多人加其为好友。因此,我们为了获取更准确的分类,可以将假设修改如下: i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。 ii、日志密度与好友密度、日志密度与是否使用真实头像在账号真实性给定的条件下是独立的。 iii、使用真实头像的用户比使用非真实头像的用户平均有更大的好友密度。 Microcomputer Applications Vol. 25, No.11, 2009 技术交流 微型电脑应用 2009年第25卷第11期 ·31· 文章编号:1007-757X(2009)11-0031-03 基于贝叶斯网络技术的软件缺陷预测与故障诊断 王科欣,王胜利 摘 要:如何进一步地提高软件的可靠性和质量是我们十分关注的问题,而前期软件缺陷和后期软件故障的诊断都是控制质量的关键手段,由此我们提出了基于贝叶斯的神经网络。基于对贝叶斯网络和神经网络理论的分析,发现贝叶斯网络和神经网络各自的优点与不足,利用贝叶斯具有前向推理的优势进行故障诊断,利用神经网络学习算法能够处理更复杂网络结构的优势来积累专家知识,最后提出了贝叶斯网络与概率神经网络相结合的模型,该模型可以更好地兼顾软件缺陷与故障诊断两个方面。 关键词:贝叶斯;神经网络;测试;缺陷预测;故障诊断 中图分类号:TP311.5 文献标志码:A 0 引言 如何进一步提高软件的可靠性和质量是我们十分关注的问题,软件可能存在缺陷,我们在软件的整个生命周期中始终期望能及早发现重要错误,并及时诊断。这就告诉我们,在进行软件前期预测时,就应该重视和记录重要缺陷,以便在故障发生时能通过早期预测的记录表找到故障原因。这就说明软件缺陷预测和故障诊断不应该是两个独立的过程,而应该有所联系。本文就通过贝叶斯网络和模糊神经网络对两项工作进行了整合。通过贝叶斯的在推理规则上的优势,尤其是前向推理的特点进行故障诊断,利用神经网络学习和训练函数的复杂多样性,可以更好地拟合复杂情况。 1 软件缺陷预测与故障诊断 1.1 软件缺陷预测的两个方面 1.1.1 对于软件可靠性早期预测 对于开发者而言,在开发软件之前或者设计软件中,主要作用是进行风险控制,验证其设计可行性。由于贝叶斯网络可以在信息不完全的情形下进行不确定性和概率性事件的推理,所以对于复杂软件的早期预测具有先天的优势。软件缺陷数量属于动态度量元素,需要通过对软件产品进行完整的测试后才能获得。针对特定模块进行完整测试成本比较高,并且必须在软件开发完成之后才能进行集成测试,这样在前期很难控制软件产品缺陷数量。为了更好地提高软件质量,对软件模块中包含的缺陷进行预测是一个可行的方法。软件缺陷预测方法的前提假设是软件的复杂度和软件的缺陷数量有密切关联。复杂度高的软件模块产生的缺陷比复杂度低的模块产生的缺陷多。软件缺陷预测的思路是使用静态度量元素表征软件的复杂度,然后预测软件模块可能的缺陷数量或者发生缺陷的可能性。通过进行软件缺陷预测,能够以较低的成本在项目开发的早期预测产品的缺陷分布状况,可以更好的调整有限的资源,集中处理可能出现较多缺陷的高风险模块,从而从整体上提高软件产品的质量。 1.1.2 对于软件残留缺陷的预测 对于测试者而言,通过质量预测,可将软件的各个组成部分按预测的质量水平进行分类,明确测试的重点,避免在进行测试时同等对待,而是有所侧重,这对节约有限资源和缩短开发周期都有着十分重要的意义。软件的测试和修改是一个螺旋式上升的过程。由于资源和时间的有限投入,什么时候软件达到了要求的质量水平从而能够投入实际使用是一个十分关键的问题。对残留缺陷进行预测,目的就是为了确保代码中的缺陷数量维持在一个安全水平。对测试经理来说,估计目前软件的测试到了哪个阶段、还应该继续做到什么样水平,这都是尤其重要的。从软件经济学的观点上来看,它关系到产业界的投入产出比、测试过度,不能再检查出太 多错误,或者说检查耗费很长的时间和很多的人力,但最终是一个细微的错误,这是不经济的;但是如果残留缺陷还比较多,就停止测试工作,那么会使得这些缺陷在未排除的情 况下交付给用户,等到用户发现错误时,维护的成本就会更 高。因此,正确预测软件残留缺陷对于交付使用后的软件维护也具有重要意义。 1.2 软件故障诊断技术 软件故障诊断是根据软件的静态表现形式和动态信息查找故障源,并进行分析,给出相应的决策。其中静态形式包括程序、数据和文档,动态信息包括程序运行过程中的一系列状态,人在参与软件生存周期的各个阶段工作时,都有可能由于各种疏忽和不可预料的因素,出现各种各样的错误。因而,从广义上说,软件故障诊断的工作涉及到软件的整个生命周期——需求分析、设计、编码、测试、使用、维护等各阶段所造成的缺陷。 软件故障诊断,“诊”的主要工作是对状态检测,包括使用各种度量和分析方法;“断”的工作则更为具体,它需要确定:(1)软件故障特性;(2)软件故障模式;(3)软件故障发生的模块和部位;(4)说明软件故障产生的原因,并且提出相应的纠正措施和避免下一次再发生该类错误的措——————————— 作者简介:王科欣(1982-) ,男,湖南长沙人,暨南大学计算机科学系,硕士研究生,软件设计师,广东体育职业技术学院助教,主要研究方向为软件工程、数据库与知识工程,广东 广州,510632;王胜利(1984-),男,湖南衡阳人,暨南大学计算机科学系,硕士 研究生,研究方向为软件工程、数据挖掘,广东 广州,510632 Promedas—贝叶斯网络在医学诊断中的应用1. 综述 现代的医学诊断是一个非常复杂的过程,要求具备患者准确的资料,以及对医学著作深刻的理解,还有多年的临床经验。这样的情况尤其适用在内科诊断中,因为它涵盖了一个巨大范围的诊断门类。而且也因此使得内科诊断成为了一个需要专攻的学科。 诊断是一个过程。通过这个过程,医生为病人的症状寻找拥有最佳解释的病因。这个研究的过程是一个连续的过程,即病人的症状会指示医生对其进行一些初步的检查。基于这些初步检查的结果,一个关于可能的病因的试探性的假设形成了。这个过程可能会在若干个循环中推进,直到病人被以充分的确定性来做了诊断,而且其症状的病因也被建立起来。 诊断过程的一个很重要的部分是标准化诊断的形式。这里有若干的规则来限制:依据病人的症状以及检验的结果,什么样的检查应该被执行,它们的顺序应该是什么样的。这些规则形成了一个决策树,其节点是诊断的中间过程;依据当前诊断的结果,其枝干指向额外的检查。这些规则是由每个国家的一个医学专家委员会制定的。 在平时遇到的大部分诊断里,上面提到的指南已经足以准确的指导我们做出正确的诊断。对于这种“一般”的情形,一个“决策支持系统”是没有必要的。在10%~20%的案例中,进行诊断的过程是很困难的。因为对于正确的诊断结果的不确定性,以及对下一步进行什么检查的不确定性,不同的医生在不同的诊断过程中做出的决策是不一样的,而且缺乏“推理”。在这些案例中,通常一个专攻此类疾病的专家或者详细描述此类疾病的著作将会被咨询。对于这种困难的情形,基于计算机的决策支持系统可以作为一个可供选择的信息来源。而且,这样一个由计算机提供帮助的决策支持系统在指出其他一些原来可能被忽略的疾病方面是有帮助的。它可能就此导致一个被提高的,更加理性的诊断过程,并且更见高效和廉价。 朴素贝叶斯分类算法 一.贝叶斯分类的原理 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。 贝叶斯分类器是用于分类的贝叶斯网络。该网络中应包含类结点C,其中C 的取值来自于类集合( c1 , c2 , ... , cm),还包含一组结点X = ( X1 , X2 , ... , Xn),表示用于分类的特征。对于贝叶斯网络分类器,若某一待分类的样本D,其分类特征值为x = ( x1 , x2 , ... , x n) ,则样本D 属于类别ci 的概率P( C = ci | X1 = x1 , X2 = x 2 , ... , Xn = x n) ,( i = 1 ,2 , ... , m) 应满足下式: P( C = ci | X = x) = Max{ P( C = c1 | X = x) , P( C = c2 | X = x ) , ... , P( C = cm | X = x ) } 贝叶斯公式: P( C = ci | X = x) = P( X = x | C = ci) * P( C = ci) / P( X = x) 其中,P( C = ci) 可由领域专家的经验得到,而P( X = x | C = ci) 和P( X = x) 的计算则较困难。 二.贝叶斯伪代码 整个算法可以分为两个部分,“建立模型”与“进行预测”,其建立模型的伪代码如下: numAttrValues 等简单的数据从本地数据结构中直接读取 构建几个关键的计数表 for(为每一个实例) { for( 每个属性 ){ 为 numClassAndAttr 中当前类,当前属性,当前取值的单元加 1 为 attFrequencies 中当前取值单元加 1 } } 预测的伪代码如下: for(每一个类别){ for(对每个属性 xj){ for(对每个属性 xi){ 学院本科毕业论文(设计) 题目:贝叶斯公式公式在数学模型中的应用 院(系)理学院 专业数学与应用数学 年级2009级 姓名鲁威学号09031213 指导教师俊超职称讲师 2013 年6月1 日 目录 摘要 (1) Abstract (2) 前言 (2) 第一章贝叶斯公式及全概率公式的推广概述........................................ 错误!未定义书签。 1.1贝叶斯公式与证明 (5) 1.1贝叶斯公式及其与全概率公式的联系 (5) 1.3贝叶斯公式公式推广与证明 (6) 1.3.1贝叶斯公式的推广 (6) 1.4贝叶斯公式的推广总结 (7) 第二章贝叶斯公式在数学模型中的应用 (8) 2.1数学建模的过程 (8) 2.2贝叶斯中常见的数学模型问题 (9) 2.2.1 全概率公式在医疗诊断中的应用 (9) 2.2.2全概率公式在市场预测中的应用 (11) 2.2.3全概率公式在信号估计中的应用. ......................................... 错误!未定义书签。 2.2.4全概率公式在概率推理中的应用 (15) 2.2.5全概率公式在工厂产品检查中的应用 ................................... 错误!未定义书签。 2.3全概率公式的推广在风险决策中的应用 (17) 2.3.1背景简介 (17) 2.3.2风险模型 (18) 2.3.3实例分析 (18) 第三章总结 (21) 3.1贝叶斯公式的概括 (21) 3.2贝叶斯公式的实际应用 (21) 结束语 (23) 参考文献 (24) 后记 (25) https://www.doczj.com/doc/e67387063.html, 分类算法之贝叶斯网络(Bayesian networks)_光环大数据培训 2.1、摘要 在上一篇文章中我们讨论了朴素贝叶斯分类。朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。 2.2、重新考虑上一篇的例子 上一篇文章我们使用朴素贝叶斯分类实现了SNS社区中不真实账号的检测。在那个解决方案中,我做了如下假设: i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。 ii、日志密度、好友密度和是否使用真实头像在账号真实性给定的条件下是独立的。 但是,上述第二条假设很可能并不成立。一般来说,好友密度除了与账号是否真实有关,还与是否有真实头像有关,因为真实的头像会吸引更多人加其为好友。因此,我们为了获取更准确的分类,可以将假设修改如下: https://www.doczj.com/doc/e67387063.html, 及更多的使用真实头像。 ii、日志密度与好友密度、日志密度与是否使用真实头像在账号真实性给定的条件下是独立的。 iii、使用真实头像的用户比使用非真实头像的用户平均有更大的好友密度。 上述假设更接近实际情况,但问题随之也来了,由于特征属性间存在依赖关系,使得朴素贝叶斯分类不适用了。既然这样,我去寻找另外的解决方案。 下图表示特征属性之间的关联: 上图是一个有向无环图,其中每个节点代表一个随机变量,而弧则表示两个随机变量之间的联系,表示指向结点影响被指向结点。不过仅有这个图的话,只能定性给出随机变量间的关系,如果要定量,还需要一些数据,这些数据就是每个节点对其直接前驱节点的条件概率,而没有前驱节点的节点则使用先验概率表示。 例如,通过对训练数据集的统计,得到下表(R表示账号真实性,H表示头像真实性): 纵向表头表示条件变量,横向表头表示随机变量。上表为真实账号和非真实账号的概率,而下表为头像真实性对于账号真实性的概率。这两张表分别为“账号是否真实”和“头像是否真实”的条件概率表。有了这些数据,不但能顺向推断,还能通过贝叶斯定理进行逆向推断。例如,现随机抽取一个账户,已知其头像为假,求其账号也为假的概率: 1 算法介绍 1.1 贝叶斯方法的基本观点 托马斯·贝叶斯(ThomasBayes)是英国数学家,他对贝叶斯方法奠基性的工作是他的论文“关于几率性问题求解的评论”。由于当时贝叶斯方法在理论和应用中还存在很多不完善的地方,因此在很长一段时间并未被普遍接受。后来随着统计决策理论、信息论和经验贝叶斯方法等理论和方法的创立和应用,贝叶斯方法很快显示出它的优点,成为十分活跃的一个方向。随着人工智能的发展尤其是机器学习、数据挖掘的兴起,贝叶斯理论的发展和应用也获得了更为广阔的空间。近年来,贝叶斯学习理论方面的文章更是层出不穷,内容涉及到人工智能的大部分领域,如因果推理、不确定性知识表达、模式识别和聚类分析等,同时出现了专门研究贝叶斯理论的组织ISBA(IntemationalSoeietyofBayesianAnalysis)。 贝叶斯方法的特点是使用概率去表示所有形式的不确定性,学习或其他形式的推理都用概率规则来实现。贝叶斯理论在数据挖掘中的应用主要包括贝叶斯方法用于分类及回归分析、因果推理和不确定知识表达以及聚类模式发现等。贝叶斯方法正在以其独特的不确定性知识表达形式、丰富的概率表达能力、综合先验知识的增量学习特性等成为当前数据挖掘众多方法中最为引人注目的焦点之一。 贝叶斯统计是贝叶斯理论和方法的应用之一,其基本思想是:假定对所研究的对象在抽样前已有一定的认识,常用先验分布来描述这种认识,然后基于抽取的样本再对先验认识作修正,得到后验分布,而各种统计推断都基于后验分布进行。经典统计学的出发点是根据样本,在一定的统计模型下做出统计推断。在取得样本观测值X 之前,往往对参数统计模型中的参数θ有某些先验知识,关于θ的先验知识的数学描述就是先验分布。贝叶斯统计的主要特点是使用先验分布,而在得到样本观测值T n x x x X ),...,,(21 后,由X 与先验分布提供的信息, 经过计算和处理,组成较完整的后验信息。这一后验分布是贝叶斯统计推断的基础。 1.2 贝叶斯统计模型 1.2.1 概率论中的贝叶斯公式 设事件A 1,A 2,…,A k 构成互不相容的完备事件组,则Bayes 公式是 (1) 在上式中,先验信息以{P(A j ), j=1,2,…,k }这一概率分布的形式给出,即先验分布。由于事件B 的发生,可以对A 1,A 2,…,A k 发生的概率提供新的信息。根据这些信息以及先验分布,可得出后验分布{P (A i |B ), i=1,2,..,k }.可以看出,Bayes 公式反映了从先验分布向后验分布的转化。 1.2.2 数据挖掘中常用的贝叶斯公式 将(1)式中的随机变量的形式改写,引入随机变量θ,它的取值是θ1,θ2,…,θk ,其中θj =θ(A j ),即当A j 发生时,θ取值θj ,θ是离散型的(取有限值),具有算法杂货铺——分类算法之贝叶斯网络(Bayesian networks)
基于贝叶斯网络技术的软件缺陷预测与故障诊断
Promedas—贝叶斯网络在医学诊断中的应用
朴素贝叶斯分类算法代码实现
贝叶斯公式公式在数学模型中的应用
分类算法之贝叶斯网络(Bayesian networks)_光环大数据培训
贝叶斯方法在聚类中的应用
相关主题
文本预览