
Oracle 内存内存全面全面全面分析分析
作者作者::fuyuncat
来源来源::https://www.doczj.com/doc/312326237.html,
作者简介
黄玮,男,99年开始从事DBA 工作,有多年的水利、军工、电信及航
运行业大型数据库Oracle 开发、设计和维护经验。
曾供职于南方某著名电信设备制造商——H 公司。期间,作为DB 组
长,负责设计、开发和维护彩铃业务的数据库系统。目前,H 公司的彩铃系
统是世界上终端用户最多的彩铃系统。最终用户数过亿。
目前供职于某世界著名物流公司,负责公司的电子物流系统的数据库开
发、维护工作。
msn: fuyuncat@https://www.doczj.com/doc/312326237.html,
Email :fuyuncat@https://www.doczj.com/doc/312326237.html,
Oracle 的内存配置与oracle 性能息息相关。而且关于内存的错误(如4030、4031错
误)都是十分令人头疼的问题。可以说,关于内存的配置,是最影响Oracle 性能的配
置。内存还直接影响到其他两个重要资源的消耗:CPU 和IO。
首先,看看Oracle 内存存储的主要内容是什么:
? 程序代码(PLSQL、Java);
? 关于已经连接的会话的信息,包括当前所有活动和非活动会话;
? 程序运行时必须的相关信息,例如查询计划;
? Oracle 进程之间共享的信息和相互交流的信息,例如锁;
? 那些被永久存储在外围存储介质上,被cache 在内存中的数据(如redo log 条
目,数据块)。
此外,需要记住的一点是,Oracle 的内存是与实例对应的。也就是说,一个实例就有
一个独立的内存结构。
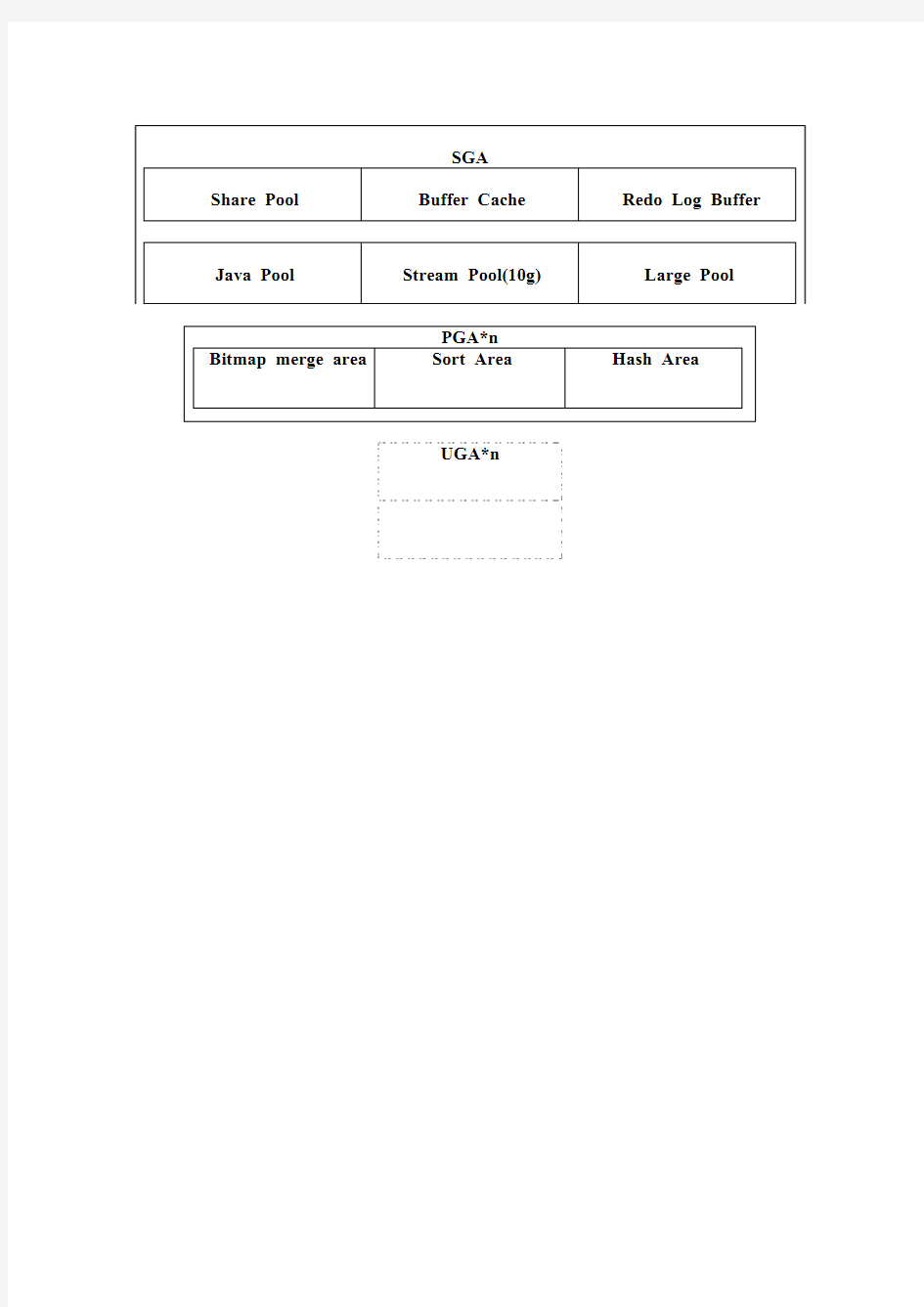
先从Oracle 内存的组成架构介绍。
1. Oracle 的内存架构组成
Oracle 的内存,从总体上讲,可以分为两大块:共享部分(主要是SGA)和进程独享
部分(主要是PGA 和UGA)。而这两部分内存里面,根据功能不同,还分为不同内存池
(Pool)和内存区(Area)。下面就是Oracle 内存构成框架图:
SGA
Share Pool Buffer Cache Redo Log Buffer Java Pool Stream Pool(10g) Large Pool
PGA*n
Bitmap merge area Sort Area Hash Area
UGA*n
Database opened.
SQL>
SGA 区是可读写的。所有登录到实例的用户都能读取SGA 中的信息,而在oracle 做执
行操作时,服务进程会将修改的信息写入SGA 区。
SGA 主要包括了以下的数据结构:
? 数据缓冲(Buffer Cache)
? 重做日志缓冲(Redo Log Buffer)
? 共享池(Shared Pool)
? Java 池(Java Pool)
? 大池(Large Pool)
? 流池(Streams Pool --- 10g 以后才有)
? 数据字典缓存(Data Dictionary Cache)
? 其他信息(如数据库和实例的状态信息)
最后的两种内存信息会被实例的后台进程所访问,它们在实例启动后就固定在SGA 中
了,而且不会改变,所以这部分又称为固定SGA(Fixed SGA)。这部分区域的大小一般小
于100K。
此外,用于并非进程控制的锁(latch)的信息也包含在SGA 区中。
Shared Pool、Java Pool、Large Pool 和Streams Pool 这几块内存区的大小是相应
系统参数设置而改变的,所以有通称为可变SGA(Variable SGA)。
1.1.1. SGA 的重要的重要参数参数参数和特性和特性
在设置SGA 时,有一些很重要的参数,它们设置正确与否,会直接影响到系统的整体
性能。下面一一介绍他们:
? SGA_MAX_SIZE
SGA 区包括了各种缓冲区和内存池,而大部分都可以通过特定的参数来指定他们的大
小。但是,作为一个昂贵的资源,一个系统的物理内存大小是有限。尽管对于CPU 的内存
寻址来说,是无需关系实际的物理内存大小的(关于这一点,后面会做详细的介绍),但
是过多的使用虚拟内存导致page in/out,会大大影响系统的性能,甚至可能会导致系统
crash。所以需要有一个参数来控制SGA 使用虚拟内存的最大大小,这个参数就是
SGA_MAX_SIZE。
当实例启动后,各个内存区只分配实例所需要的最小大小,在随后的运行过程中,再
根据需要扩展他们的大小,而他们的总和大小受到了SGA_MAX_SIZE 的限制。
当试图增加一个内存的大小,并且如果这个值导致所有内存区大小总和大于
SGA_MAX_SIZE 时,oracle 会提示错误,不允许修改。
当然,如果在设置参数时,指定区域为spfile 时(包括修改SGA_MAX_SIZE 本身),
是不会受到这个限制的。这样就可能出现这样的情况,在spfile 中,SGA 各个内存区设置
大小总和大于SGA_MAX_SIZE。这时,oracle 会如下处理:当实例再次启动时,如果发现
SGA 各个内存总和大于SGA_MAX_SIZE,它会将SGA_MAX_SIZE 的值修改为SGA 各个内存区
总和的值。
SGA 所分配的是虚拟内存,但是,在我们配置SGA 时,一定要使整个SGA 区都在物理
内存中,否则,会导致SGA 频繁的页入/页出,会极大影响系统性能。
对于OLTP 系统,我个人建议可以如下配置SGA_MAX_SIZE(一般有经验的DBA 都会有
自己的默认配置大小,你也可以通过一段时间的观察、调整自己的系统来得到适合本系统
的参数配置): 系统内存系统内存 SGA SGA_MAX_SIZE _MAX_SIZE 值
1G 400-500M
2G 1G 4G 2500M
8G 5G
SGA 的实际大小可以通过以下公式估算:
SGA 实际大小 = DB_CACHE_SIZE + DB_KEEP_CACHE_SIZE + DB_RECYCLE_CACHE_SIZE +
DB_nk_CACHE_SIZE + SHARED_POOL_SIZE + LARGE_POOL_SIZE + JAVA_POOL_SIZE +
STREAMS_POOL_SIZE(10g 中的新内存池) + LOG_BUFFERS+11K(Redo Log Buffer 的保护
页) + 1MB + 16M(SGA 内部内存消耗,适合于9i 及之前版本)
公式种涉及到的参数在下面的内容种会一一介绍。
? PRE_PAGE_SGA
我们前面提到,oracle 实例启动时,会只载入各个内存区最小的大小。而其他SGA 内
存只作为虚拟内存分配,只有当进程touch 到相应的页时,才会置换到物理内存中。但我
们也许希望实例一启动后,所有SGA 都分配到物理内存。这时就可以通过设置
PRE_PAGE_SGA 参数来达到目的了。
这个参数的默认值为FALSE,即不将全部SGA 置入物理内存中。当设置为TRUE 时,实
例启动会将全部SGA 置入物理内存中。它可以使实例启动达到它的最大性能状态,但是,
启动时间也会更长(因为为了使所有SGA 都置入物理内存中,oracle 进程需要touch 所有
的SGA 页)。
我们可以通过TopShow 工具(本站原创工具,可在
https://www.doczj.com/doc/312326237.html,/Download/TopShow.html 中下载)来观察windows(Unix 下的
内存监控比较复杂,这里暂不举例)下参数修改前后的对比。
PRE_PAGE_SGA 为FALSE:
SQL> show parameter sga
NAME TYPE VALUE ------------------------------------ ----------- ------------------------
--
lock_sga boolean FALSE
pre_page_sga boolean FALSE sga_max_size big integer 276M
sga_target big integer 276M
SQL> startup force ORACLE instance started.
Total System Global Area 289406976 bytes
Fixed Size 1248576 bytes Variable Size 117441216 bytes
Database Buffers 163577856 bytes
Redo Buffers 7139328 bytes
Database mounted. Database opened.
SQL>
启动后,Oracle 的内存情况
可以看到,实例启动后,oracle占用的物理内存只有168M,远小于SGA的最大值288M(实际上,这部分物理内存中还有一部分进程的PGA和Oracle Service占用的内存),而虚拟内存则为340M。
将PRE_PAGE_SGA修改为TRUE,重启实例:
SQL> alter system set pre_page_sga=true scope=spfile;
System altered.
SQL> startup force
ORACLE instance started.
Total System Global Area 289406976 bytes
Fixed Size 1248576 bytes
Variable Size 117441216 bytes
Database Buffers 163577856 bytes
Redo Buffers 7139328 bytes
Database mounted.
Database opened.
再观察启动后Oracle的内存分配情况:
这时看到,实例启动后物理内存达到了最大343M,于虚拟内存相当。这时,oracle实例已经将所有SGA分配到物理内存。
当参数设置为TRUE时,不仅在实例启动时,需要touch所有的SGA页,并且由于每个oracle进程都会访问SGA区,所以每当一个新进程启动时(在Dedicated Server方式中,每个会话都会启动一个Oracle进程),都会touch一遍该进程需要访问的所有页。因此,每个进程的启动时间页增长了。所以,这个参数的设置需要根据系统的应用情况来设定。
在这种情况下,进程启动时间的长短就由系统内存的页的大小来决定了。例如,SGA
大小为100M,当页的大小为4K时,进程启动时需要访问100000/4=25000个页,而如果页大小为4M时,进程只需要访问100/4=25个页。页的大小是由操作系统指定的,并且是无法修改的。
但是,要记住一点:PRE_PAGA_SGA只是在启动时将物理内存分配给SGA,但并不能保证系统在以后的运行过程不会将SGA中的某些页置换到虚拟内存中,也就是说,尽管设置了这个参数,还是可能出现Page In/Out。如果需要保障SGA不被换出,就需要由另外一个参数LOCK_SGA来控制了。
?LOCK_SGA
上面提到,为了保证SGA都被锁定在物理内存中,而不必页入/页出,可以通过参数LOCK_SGA来控制。这个参数默认值为FALSE,当指定为TRUE时,可以将全部SGA都锁定在物理内存中。当然,有些系统不支持内存锁定,这个参数也就无效了。
?SGA_TARGET
这里要介绍的时Oracle10g中引入的一个非常重要的参数。在10g之前,SGA的各个内存区的大小都需要通过各自的参数指定,并且都无法超过参数指定大小的值,尽管他们之和可能并没有达到SGA的最大限制。此外,一旦分配后,各个区的内存只能给本区使用,相互之间是不能共享的。拿SGA中两个最重要的内存区Buffer Cache和Shared Pool 来说,它们两个对实例的性能影响最大,但是就有这样的矛盾存在:在内存资源有限的情况下,某些时候数据被cache的需求非常大,为了提高buffer hit,就需要增加Buffer Cache,但由于SGA有限,只能从其他区“抢”过来——如缩小Shared Pool,增加Buffer Cache;而有时又有大块的PLSQL代码被解析驻入内存中,导致Shared Pool不足,甚至出现4031错误,又需要扩大Shared Pool,这时可能又需要人为干预,从Buffer Cache中将内存夺回来。
有了这个新的特性后,SGA中的这种内存矛盾就迎刃而解了。这一特性被称为自动共享内存管理(Automatic Shared Memory Management ASMM)。而控制这一特性的,也就仅仅是这一个参数SGA_TARGE。设置这个参数后,你就不需要为每个内存区来指定大小了。SGA_TARGET指定了SGA可以使用的最大内存大小,而SGA中各个内存的大小由Oracle自行控制,不需要人为指定。Oracle可以随时调节各个区域的大小,使之达到系统性能最佳状态的个最合理大小,并且控制他们之和在SGA_TARGET指定的值之内。一旦给SGA_TARGET指定值后(默认为0,即没有启动ASMM),就自动启动了ASMM特性。
设置了SGA_TARGET后,以下的SGA内存区就可以由ASMM来自动调整:
?共享池(Shared Pool)
?Java池(Java Pool)
?大池(Large Pool)
?数据缓存区(Buffer Cache)
?流池(Streams Pool)
对于SGA_TARGET的限制,它的大小是不能超过SGA_MAX_SIZE的大小的。
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------
------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 276M
sga_target big integer 276M
SQL>
SQL>
SQL>
SQL> alter system set sga_target=280M;
alter system set sga_target=280M
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is
invalid
ORA-00823: Specified value of sga_target greater than sga_max_size
另外,当指定SGA_TARGET小于SGA_MAX_SIZE,实例重启后,SGA_MAX_SIZE就自动变为和SGA_TARGET一样的值了。
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------
------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 276M
sga_target big integer 276M
SQL> alter system set sga_target=252M;
System altered.
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------
------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 276M
sga_target big integer 252M
SQL> startup force
ORACLE instance started.
Total System Global Area 264241152 bytes
Fixed Size 1248428 bytes
Variable Size 117441364 bytes
Database Buffers 138412032 bytes
Redo Buffers 7139328 bytes
Database mounted.
Database opened.
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------
------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 252M
sga_target big integer 252M
SQL>
对于SGA_TARGET,还有重要一点就是,它的值可以动态修改(在SGA_MAX_SIZE范围内)。在10g之前,如果需要修改SGA的大小(即修改SGA_MAX_SIZE的值)需要重启实例才能生效。当然,在10g中,修改SGA_MAX_SIZE的值还是需要重启的。但是有了SGA_TARGET后,可以将SGA_MAX_SIZE设置偏大,再根据实际需要调整SGA_TARGET的值(我个人不推荐频繁修改SGA的大小,SGA_TARGET在实例启动时设置好,以后不要再修改)。
SGA_TARGET带来一个重要的好处就是,能使SGA的利用率达到最佳,从而节省内存成本。因为ASMM启动后,Oracle会自动根据需要调整各个区域的大小,大大减少了某些区域内存紧张,而某些区域又有内存空闲的矛盾情况出现。这也同时大大降低了出现4031错误的几率。
? use_indirect_data_buffers
这个参数使32位平台使用扩展缓冲缓存基址,以支持支持4GB 多物理内存。设置此参
数,可以使SGA 突破在32位系统中的2G 最大限制。64位平台中,这个参数被忽略。
1.1.
2. 关于SGA 的重要的重要视图视图
要了解和观察SGA 的使用情况,并且根据统计数据来处理问题和调整性能,主要有以
下的几个系统视图。
? v$sga
这个视图包括了SGA 的的总体情况,只包含两个字段:name(SGA 内存区名字)和
value(内存区的值,单位为字节)。它的结果和show sga 的结果一致,显示了SGA 各个区的大小:
SQL> select * from v$sga;
NAME VALUE
-------------------- ----------
Fixed Size 1248428 Variable Size 117441364 Database Buffers 138412032
Redo Buffers 7139328
4 rows selected.
SQL> show sga
Total System Global Area 264241152 bytes
Fixed Size 1248428 bytes
Variable Size 117441364 bytes Database Buffers 138412032 bytes
Redo Buffers 7139328 bytes
SQL>
? v$sgastat
这个视图比较重要。它记录了关于sga 的统计信息。包含三个字段:Name(SGA 内存
区的名字);Bytes(内存区的大小,单位为字节);Pool(这段内存所属的内存池)。
这个视图尤其重要的是,它详细记录了个各个池(Pool)内存分配情况,对于定位
4031错误有重要参考价值。
以下语句可以查询Shared Pool 空闲率:
SQL> select to_number(v$parameter.value) value, v$sgastat.BYTES, 2 (v$sgastat.bytes/v$parameter.value)*100 "percent free"
3 from v$sgastat, v$parameter
4 where v$https://www.doczj.com/doc/312326237.html,= 'free memory'
5 and v$https://www.doczj.com/doc/312326237.html, = 'shared_pool_size'
6 and v$sgastat.pool='shared pool'
7 ;
VALUE BYTES percent free
---------- ---------- ------------
503316480 141096368 28.033329645 SQL>
?v$sga_dynamic_components
这个视图记录了SGA各个动态内存区的情况,它的统计信息是基于已经完成了的,针对SGA动态内存区大小调整的操作,字段组成如下:
字段数据类型描述
COMPONENT VARCHAR2(64)内存区名称
CURRENT_SIZE NUMBER当前大小
MIN_SIZE NUMBER自从实例启动后的最小值
MAX_SIZE NUMBER自从实例启动后的最大值
OPER_COUNT NUMBER自从实例启动后的调整次数
LAST_OPER_TYPE VARCHAR2(6)最后一次完成的调整动作,值包括:
?GROW(增加)
?SHRINK(缩小)
LAST_OPER_MODE VARCHAR2(6)最后一次完成的调整动作的模式,包括:
?MANUAL(手动)
?AUTO(自动)
LAST_OPER_TIME DATE最后一次完成的调整动作的开始时间GRANULE_SIZE NUMBER GRANULE大小(关于granule后面详细介绍)
?V$SGA_DYNAMIC_FREE_MEMORY
这个视图只有一个字段,一条记录:当前SGA可用于动态调整SGA内存区的空闲区域大小。它的值相当于(SGA_MAX_SIZE – SGA各个区域设置大小的总和)。当设置了SGA_TARGET后,它的值一定为0(为什么就不需要我再讲了吧^_^)。
下面的例子可以很清楚的看到这个视图的作用:
SQL> select * from v$sga_dynamic_free_memory;
CURRENT_SIZE
--------------
SQL> show parameter shared_pool
NAME TYPE VALUE
----------------------------------- ----------- ----------
shared_pool_size big integer 50331648
SQL> alter system set shared_pool_size=38M;
system altered.
SQL> show parameter shared_pool
NAME TYPE VALUE
----------------------------------- ----------- ----------
shared_pool_size big integer 41943040
SQL> select * from v$sga_dynamic_free_memory;
CURRENT_SIZE
--------------
8388608
数据库缓冲区((Database Buffers)
1.1.3. 数据库缓冲区
Buffer Cache是SGA区中专门用于存放从数据文件中读取的的数据块拷贝的区域。Oracle进程如果发现需要访问的数据块已经在buffer cache中,就直接读写内存中的相应区域,而无需读取数据文件,从而大大提高性能(要知道,内存的读取效率是磁盘读取效率的14000倍)。Buffer cache对于所有oracle进程都是共享的,即能被所有oracle 进程访问。
和Shared Pool一样,buffer cache被分为多个集合,这样能够大大降低多CPU系统中的争用问题。
1.1.1.1.Buffer cache的管理
Oracle对于buffer cache的管理,是通过两个重要的链表实现的:写链表和最近最少使用链表(the Least Recently Used LRU)。写链表所指向的是所有脏数据块缓存(即被进程修改过,但还没有被回写到数据文件中去的数据块,此时缓冲中的数据和数据文件中的数据不一致)。而LRU链表指向的是所有空闲的缓存、pin住的缓存以及还没有来的及移入写链表的脏缓存。空闲缓存中没有任何有用的数据,随时可以使用。而pin住的缓存是当前正在被访问的缓存。LRU链表的两端就分别叫做最近使用端(the Most Recently Used MRU)和最近最少使用端(LRU)。
?Buffer cache的数据块访问
当一个Oracle进程访问一个缓存是,这个进程会将这块缓存移到LRU链表中的MRU。而当越来越多的缓冲块被移到MRU端,那些已经过时的脏缓冲(即数据改动已经被写入数据文件中,此时缓冲中的数据和数据文件中的数据已经一致)则被移到LRU链表中LRU 端。
当一个Oracle用户进程第一次访问一个数据块时,它会先查找buffer cache中是否存在这个数据块的拷贝。如果发现这个数据块已经存在于buffer cache(即命中cache hit),它就直接读从内存中取该数据块。如果在buffer cache中没有发现该数据块(即未命中cache miss),它就需要先从数据文件中读取该数据块到buffer cache中,然后才访问该数据块。命中次数与进程读取次数之比就是我们一个衡量数据库性能的重要指标:buffer hit ratio(buffer命中率),可以通过以下语句获得自实例启动至今的buffer命中率:
SQL> select 1-(sum(decode(name, 'physical reads', value, 0))/
2 (sum(decode(name, 'db block gets', value, 0))+
3 (sum(decode(name, 'consistent gets', value, 0))))) "Buffer
Hit Ratio"
4 from v$sysstat;
Buffer Hit Ratio
----------------
.926185625
1 row selected.
SQL>
根据经验,一个良好性能的系统,这一值一般保持在95%左右。
上面提到,如果未命中(missed),则需要先将数据块读取到缓存中去。这时,oracle进程需要从空闲列表种找到一个适合大小的空闲缓存。如果空闲列表中没有适合大小的空闲buffer,它就会从LRU端开始查找LRU链表,直到找到一个可重用的缓存块或者达到最大查找块数限制。在查找过程中,如果进程找到一个脏缓存块,它将这个缓存块移到写链表中去,然后继续查找。当它找到一个空闲块后,就从磁盘中读取数据块到缓存块中,并将这个缓存块移到LRU链表的MRU端。
当有新的对象需要请求分配buffer时,会通过内存管理模块请求分配空闲的或者可重用的buffer。“free buffer requested”就是产生这种请求的次数;
当请求分配buffer时,已经没有适合大小的空闲buffer时,需要从LRU链表上获取到可重用的buffer。但是,LRU链表上的buffer并非都是立即可重用的,还会存在一些块正在被读写或者已经被别的用户所等待。根据LRU算法,查找可重用的buffer是从链表的LRU端开始查找的,如果这一段的前面存在这种不能理解被重用的buffer,则需要跳过去,查找链表中的下一个buffer。“free buffer inspected”就是被跳过去的buffer的数目。
如果Oracle用户进程达到查找块数限制后还没有找到空闲缓存,它就停止查找LRU链表,并且通过信号同志DBW0进程将脏缓存写入磁盘去。
下面就是oracle用户进程访问一个数据块的伪代码:
user_process_access_block(block)
{
if (search_lru(block))
{
g_cache_hit++;
return read_block_from_buffer_cache(block);
}
else
{
g_cache_missed++;
search_count = 1;
searched = FALSE;
set_lru_latch_context();
buffer_block = get_lru_from_lru();
do
{
if (block == buffer_block)
{
set_buffer_block(buffer_block,
read_block_from_datafile(block);
move_buffer_block_to_mru(buffer_block);
searched = TRUE;
}
search_count++;
buffer_block = get_next_from_lru(buffer_block);
}while(!searched && search_count < BUFFER_SEARCH_THRESHOLD)
free_lru_latch_context();
if (!searched)
{
buffer_block = signal_dbw0_write_dirty_buffer();
set_buffer_block(buffer_block,
read_block_from_datafile(block);
move_buffer_block_to_mru(buffer_block);
}
return buffer_block;
}
}
?全表扫描
当发生全表扫描(Full Table Scan)时,用户进程读取表的数据块,并将他们放在LRU链表的LRU端(和上面不同,不是放在MRU端)。这样做的目的是为了使全表扫描的数据尽快被移出。因为全表扫描一般发生的频率较低,并且全表扫描的数据块大部分在以后都不会被经常使用到。
而如果你希望全表扫描的数据能被cache住,使之在扫描时放在MRU端,可以通过在创建或修改表(或簇)时,指定CACHE参数。
?Flush Buffer
回顾一下前面一个用户进程访问一个数据块的过程,如果访问的数据块不在buffer cache中,就需要扫描LRU链表,当达到扫描块数限制后还没有找到空闲buffer,就需要通知DBW0将脏缓存回写到磁盘。分析一下伪代码,在这种情况下,用户进程访问一个数据块的过程是最长的,也就是效率最低的。如果一个系统中存在大量的脏缓冲,那么就可能导致用户进程访问数据性能下降。
我们可以通过人工干预将所有脏缓冲回写到磁盘去,这就是flush buffer。
在9i,可以用以下语句:
alter system set events = 'immediate trace name flush_cache'; --9i 在10g,可以用以下方式(9i的方式在10g仍然有效):
alter system flush buffer_cache; -- 10g
另外,9i的设置事件的方式可以是针对系统全部的,也可以是对会话的(即将该会话造成的脏缓冲回写)。
1.1.3.1.Buffer Cache的重要参数配置
Oracle提供了一些参数用于控制Buffer Cache的大小等特性。下面介绍一下这些参数。
?Buffer Cache的大小配置
由于Buffer Cache中存放的是从数据文件中来的数据块的拷贝,因此,它的大小的计算也是以块的尺寸为基数的。而数据块的大小是由参数db_block_size指定的。9i以后,块的大小默认是8K,它的值一般设置为和操作系统的块尺寸相同或者它的倍数。
而参数db_block_buffers则指定了Buffer Cache中缓存块数。因此,buffer cache 的大小就等于db_block_buffers * db_block_size。
在9i以后,Oracle引入了一个新参数:db_cache_size。这个参数可以直接指定Buffer Cache的大小,而不需要通过上面的方式计算出。它的默认值48M,这个数对于一个系统来说一般是不够用的。
注意:db_cache_size和db_block_buffers是不能同时设置的,否则实例启动时会报错。
SQL> alter system set db_block_buffers=16384 scope=spfile;
system altered.
SQL> alter system set db_cache_size=128M scope=spfile;
system altered.
SQL> startup force
ORA-00381: cannot use both new and old parameters for buffer cache size specification
9i以后,推荐使用db_cache_size来指定buffer cache的大小。
在OLTP系统中,对于DB_CACHE_SIZE的设置,我的推荐配置是:
DB_CACHE_SIZE = SGA_MAX_SIZE/2 ~ SGA_MAX_SIZE*2/3
最后,DB_CACHE_SIZE是可以联机修改的,即实例无需重启,除非增大Buffer Cache 导致SGA实际大小大于SGA_MAX_SIZE。
?多种块尺寸系统中的Buffer Cache的配置
从9i开始,Oracle支持创建不同块尺寸的表空间,并且可以为不同块尺寸的数据块
指定不同大小的buffer cache。
9i以后,除了SYSTEM表空间和TEMPORARY表空间必须使用标准块尺寸外,所有其他
表空间都可以最多指定四种不同的块尺寸。而标准块尺寸还是由上面的所说的参数
db_block_size来指定。而db_cache_size则是标致块尺寸的buffer cache的大小。
非标准块尺寸的块大小可以在创建表空间(CREATE TABLESPACE)是通过BLOCKSIZE参数指定。而不同块尺寸的buffer cache的大小就由相应参数DB_nK_CACHE_SZIE来指定,其中n可以是2,4,8,16或者32。例如,你创建了一个块大小为16K的非标准块尺寸的表空间,你就可以通过设置DB_16K_CACHE_SIZE为来指定缓存这个表空间数据块的buffer cache的大小。
任何一个尺寸的Buffer Cache都是不可以缓存其他尺寸的数据块的。因此,如果你打算使用多种块尺寸用于你的数据库的存储,你必须最少设置DB_CACHE_SIZE和
DB_nK_CACHE_SIZE中的一个参数(10g后,指定了SGA_TARGET就可以不需要指定Buffer Cache的大小)。并且,你需要给你要用到的非标准块尺寸的数据块指定相应的Buffer Cache大小。这些参数使你可以为系统指定多达4种不同块尺寸的Buffer Cache。
另外,请注意一点,DB_nK_CACHE_SIZE 参数不能设定标准块尺寸的缓冲区大小。举例来说,如果 DB_BLOCK_SIZE 设定为 4K,就不能再设定 DB_4K_CACHE_SIZE 参数。
?多缓冲池
你可以配置不同的buffer cache,可以达到不同的cache数据的目的。比如,可以设置一部分buffer cache缓存过的数据在使用后后马上释放,使后来的数据可以立即使用
缓冲池;还可以设置数据进入缓冲池后就被keep住不再释放。部分数据库对象(表、
簇、索引以及分区)可以控制他们的数据缓存的行为,而这些不同的缓存行为就使用不同缓冲池。
o保持缓冲池(Keep Buffer Pool)用于缓存那些永久驻入内存的数据块。它的大小由参数DB_KEEP_CACHE_SZIE控制;
o回收缓冲池(Recycle Buffer Pool)会立即清除那些不在使用的数据缓存块。
它的大小由参数DB_RECYLE_CACHE_SIZE指定;
o 默认的标准缓存池,也就是上面所说的DB_CACHE_SIZE 指定。
这三个参数相互之间是独立的。并且他们都只适用于标准块尺寸的数据块。与8i 兼容
参数DB_BLOCK_BUFFERS 相应的,DB_KEEP_CACHE_SIZE 对应有BUFFER_POOL_KEEP、
DB_RECYLE_CACHE_SIZE 对应有BUFFER_POOL_RECYCLE。同样,这些参数之间是互斥的,即
DB_KEEP_CACHE_SIZE 和BUFFER_POOL_KEEP 之间只能设置一个。
? 缓冲池建议器
从9i 开始,Oracle 提供了一些自动优化工具,用于调整系统配置,提高系统性能。
建议器就是其中一种。建议器的作用就是在系统运行过程中,通过监视相关统计数据,给
相关配置在不同情况下的性能效果,提供给DBA 做决策,以选取最佳的配置。
9i 中,Buffer Cache 就有了相应的建议器。参数db_cache_advice 用于该建议器的开
关,默认值为FALSE(即关)。当设置它为TRUE 后,在系统运行一段时间后,就可以查询
视图v$db_cache_advice 来决定如何使之DB_CACHE_SIZE 了。关于这个建议器和视图,我
们会在下面的内容中介绍。
? 其他其他相关相关相关参数参数
DB_BLOCK_LRU_LATCHES
LRU 链表作为一个内存对象,对它的访问是需要进行锁(latch)控制的,以防止多个用
户进程同时使用一个空闲缓存块。DB_BLOCK_LRU_LATCHES 设置了LUR latch 的数量范围。
Oracle 通过一系列的内部检测来决定是否使用这个参数值。如果这个参数没有设置,
Oracle 会自动为它计算出一个值。一般来说,oracle 计算出来的值是比较合理,无需再
去修改。
9i 以后这个参数是隐含参数。对于隐含参数,我建议在没有得到Oracle 支持的情况
下不要做修改,否则,如果修改了,Oracle 是可以拒绝为你做支持的。
DB_WRITER_PROCESSES
在前面分析Oracle 读取Buffer Cache 时,提到一个Oracle 重要的后台进程DBW0,
这个(或这些)进程负责将脏缓存块写回到数据文件种去,称为数据库书写器进程
(Database Writer Process)。DB_WRITER_PROCESSES 参数配置写进程的个数,各个进程
以DBWn 区分,其中n>=0,是进程序号。一般情况下,DB_WRITER_PROCESSES = MAX(1,
TRUNC(CPU 数/8))。也就是说,CPU 数小于8时,DB_WRITER_PROCESSES 为1,即只有一个
写进程DBW0。这对于一般的系统来说也是足够用。当你的系统的修改数据的任务很重,并
且已经影响到性能时,可以调整这个参数。这个参数不要超过CPU 数,否则多出的进程也
不会起作用,另外,它的最大值不能超过20。
DBWn 进程除了上面提到的在用户进程读取buffer cache 时会被触发,还能被
Checkpoint 触发(Checkpoint 是实例从redo log 中做恢复的起始点)。
1.1.3.
2. Buffer Cache 的重要的重要视图视图
关于Buffer Cache,oracle 提供一些重要视图,用于查询关于Buffer Cache 的重要
信息,为调整Buffer Cache、提高性能提供参考。下面一一介绍它们
? v$db_cache_advice
上面我们提到了Oracle 的建议器,其中有一个针对Buffer Cache 的建议器。在我们
设置了参数db_cache_advice 为TRUE 后,经过一段时间的系统运行,Oracle 收集到相关
统计数据,并根据一定的数学模型,预测出DB_CACHE_SIZE在不同大小情况的性能数据。我们就可以由视图V$DB_CACHE_ADVICE查出这些数据,并根据这些数据调整
DB_CACHE_SZIE,使系统性能最优。
下面是关于这个视图的结构描述:
字段数据类型描述
ID NUMBER 缓冲池标识号(从1到8,1-6对应于
DB_nK_CACHE_SIZE,DB_CACHE_SIZE与系统标准块尺
寸的序号相关,如DB_BLOCK_SIZE为8K,则
DB_CACHE_SIZE的标识号为3(2,4,8…)。7是
DB_KEEP_CACHE_SIZE,8是DB_RECYCLE_CACHE_SIZE) NAME VARCHAR2(20) 缓冲池名称
BLOCK_SIZE NUMBER 缓冲池块尺寸(字节为单位)
ADVICE_STATUS VARCHAR2(3) 建议器状态:ON表示建议器在运行;OFF表示建议器
已经关闭。当建议器关闭了,视图中的数据是上一次
打开所统计得出的。
SIZE_FOR_ESTIMATE NUMBER 预测性能数据的Cache大小(M为单位)
SIZE_FACTOR NUMBER 预测的Cache大小因子(即与当前大小的比例) BUFFERS_FOR_ESTIMATE NUMBER 预测性能数据的Cache大小(缓冲块数)
ESTD_PHYSICAL_READ_FACTOR NUMBER 这一缓冲大小时,物理读因子,它是如果缓冲大小为
SIZE_FOR_ESTIMATE时,建议器预测物理读数与当前
实际物理读数的比率值。如果当前物理读数为0,这
个值为空。
ESTD_PHYSICAL_READS NUMBER 如果缓冲大小为SIZE_FOR_ESTIMATE时,建议器预测
物理读数。
下面是从这个视图中查询出来的数据:
SQL> select size_for_estimate, estd_physical_read_factor,
estd_physical_reads
2 from v$db_cache_advice
3 where name = 'DEFAULT';
SIZE_FOR_ESTIMATE ESTD_PHYSICAL_READ_FACTOR ESTD_PHYSICAL_READS
----------------- ------------------------- -------------------
16 2.0176 6514226
32 1.7403 5619048
48 1.5232 4917909
64 1.3528 4367839
80 1.2698 4099816
96 1.1933 3852847
112 1.1443 3694709
128 1.1007 3553685
144 1.0694 3452805
160 1.0416 *******
176 1.0175 3285085
192 1 3228693
208 0.9802 3164754
224 0.9632 3109920
240 0.9395 3033427
256 0.8383 2706631
272 0.7363 2377209
288 0.682 2202116
304 0.6714 2167888
320 0.6516 2103876
20 rows selected
当前我们的DB_CACHE_SIZE为192M,可以看到,它的物理读因子为1,物理读数为3228693。那么如何根据这些数据调整DB_CACHE_SIZE呢?给出一个方法,找到变化率较平缓的点作为采用值。因为建议器做预测是,DB_CACHE_SIZE的预测值的增长步长是相同的,是16M。我们按照这一步长增加DB_CACHE_SIZE,如果每次增加物理读降低都很明显,就可以继续增加,直到物理读降低不明显,说明继续增加DB_CACHE_SIZE没有太大作用。当然,性能和可用资源是天平的两端,你需要根据自己系统的实际情况调整。
上面的例子中,我们可以考虑将DB_CACHE_SIZE调整到288M。因为在288M之前,物理读因子变化都比较大,而从288M到304M以后,这个因子变化趋缓。用一个二维图可以更容易看出这个变化来:
这一视图作为调整DB_CACHE_SIZE以提高性能有很大参考价值。但衡量Buffer Cache 是否合适的重要指标还是我们前面提到的缓存命中率(Buffer Hit),而影响缓存命中率往往还有其他因素,如性能极差的SQL语句。
?V$BUFFER_POOL
这一视图显示了当前实例中所有缓冲池的信息。它的结构如下:
字段数据类型描述
ID NUMBER缓冲池ID,和上面视图描述相同。
NAME VARCHAR2(20)缓冲池名称
字段数据类型描述
BLOCK_SIZE NUMBER缓冲池块尺寸(字节为单位)
RESIZE_STATE VARCHAR2(10)缓冲池当前状态。
STATIC:没有被正在调整大小
ALLOCATING:正在分配内存给缓冲池(不能被用户取消)
ACTIVATING:正在创建新的缓存块(不能被用户取消)
SHRINKING:正在删除缓存块(能被用户取消) CURRENT_SIZE NUMBER缓冲池大小(M为单位)
BUFFERS NUMBER当前缓存块数
TARGET_SIZE NUMBER如果正在调整缓冲池大小(即状态不为STATIC),这记录了
调整后的大小(M为单位)。如果状态为STATIC,这个值和
当前大小值相同。
TARGET_BUFFERS NUMBER如果正在调整缓冲池大小(即状态不为STATIC),这记录了
调整后的缓存块数。否则,这个值和当前缓存块数相同。 PREV_SIZE NUMBER前一次调整的缓冲池大小。如果从来没有调整过,则为0。 PREV_BUFFERS NUMBER前一次调整的缓存块数。如果从来没有调整过,则为0。 LO_BNUM NUMBER9i后已经废弃字段
HI_BNUM NUMBER9i后已经废弃字段
LO_SETID NUMBER9i后已经废弃字段
HI_SETID NUMBER9i后已经废弃字段
SET_COUNT NUMBER9i后已经废弃字段
?v$buffer_pool_statistics
V$BUFFER_POOL_STATISTICS视图记录了所有缓冲池的统计数据。它的结构如下:
字段数据类型描述
ID NUMBER 缓冲池ID,和上面视图描述相同。
NAME VARCHAR2(20) 缓冲池名称
SET_MSIZE NUMBER 缓冲池中缓存块的最大数
CNUM_REPL NUMBER 在置换列表中的缓存块数
CNUM_WRITE NUMBER 在写列表中的缓存块数
CNUM_SET NUMBER 当前的缓存块数
BUF_GOT NUMBER 读取过的缓存块数
SUM_WRITE NUMBER 被写过的缓存块数
SUM_SCAN NUMBER 被扫描过的缓存块数
FREE_BUFFER_WAIT NUMBER 等待空闲块统计数
字段数据类型描述
WRITE_COMPLETE_WAIT NUMBER 等待完成写统计数
BUFFER_BUSY_WAIT NUMBER 忙(正在被使用)等待统计数
FREE_BUFFER_INSPECTED NUMBER 确认了的空闲缓存块数(即可用的) DIRTY_BUFFERS_INSPECTED NUMBER 确认了的脏缓存块数
DB_BLOCK_CHANGE NUMBER 被修改过的数据块数
DB_BLOCK_GETS NUMBER 读取过的数据块数
CONSISTENT_GETS NUMBER 一致性读统计数
PHYSICAL_READS NUMBER 物理读统计数
PHYSICAL_WRITES NUMBER 物理写统计数
查看当前的Buffer Cache命中率:
SQL> select 1-(physical_reads)/(consistent_gets+db_block_gets)
2 from v$buffer_pool_statistics;
1-(PHYSICAL_READS)/(CONSISTENT
------------------------------
0.967658520581074
SQL>
?v$bh
这一视图在深入定位缓冲区问题时很有用。它记录了缓冲区中所有数据块对象。粒度非常细。这个视图最初的目的是用于OPS(Oracle Parallel Server Oracle平行服务器,9i后称为RAC)的,是用于保证RAC中各个节点的数据一致性的。但是,我们可以通过它来查询Buffer Cache的使用情况,找出大量消耗Buffer Cache的对象。下面的语句就可以完成这一工作:
SQL> column c0 heading 'Owner' format a15
SQL> column c1 heading 'Object|Name' format a30
SQL> column c2 heading 'Number|of|Buffers' format 999,999
SQL> column c3 heading 'Percentage|ofData|Buffer' format 999,999,999
SQL> select
2 owner c0,
3 object_name c1,
4 count(1) c2,
5 (count(1)/(select count(*) from v$bh)) *100 c3
6 from
7 dba_objects o,
8 v$bh bh
9 where
10 o.object_id = bh.objd
11 and
12 o.owner not in ('SYS','SYSTEM')
13 group by
14 owner,
15 object_name
16 order by
17 count(1) desc
18 ;
C0 C1 C2 C3
--------------- ------------------------------ ---------- ----------
PLSQLDEV STANDARD_CITY 17290 72.5860621 DBOWNER MSG_LOG 2 0.00839630 DBOWNER COUNTRY_PK 1 0.00419815 DBOWNER PARAMETER 1 0.00419815 DBOWNER PARAMETER_PK 1 0.00419815 DBOWNER MSG_LOG_IDX1 1 0.00419815
6 rows selected
SQL>
更重要的是,这个视图记录的粒度非常细,一条记录对应了一个数据块。这对于我们做内存问题分析或分析Oracle行为时很有帮助。
下面是这个视图的结构:
字段数据类型说明
FILE# NUMBER 缓存块对应的数据块所在的数据文件号。可以通过视图
DBA_DATA_FILES或V$DBFILES查询
BLOCK# NUMBER 缓存块对应的数据块编号
CLASS# NUMBER 分类编号
STATUS VARCHAR2(1) 缓存块的状态
FREE:空闲,没有被使用
XCUR:排斥(正在被使用)
SCUR:可被共享
CR:一致性读
READ:正在从磁盘读入
MREC:处于从存储介质恢复状态
IREC:处于实例恢复状态
XNC NUMBER 缓存块上由于和其他实例争用导致的PCM(Parallel Cache
Management并行缓存管理)x to null锁的数量。这一字段已
经被废弃。
LOCK_ELEMENT_ADDR RAW(4 | 8) 缓存块上PCM锁的地址。如果多个缓存块的PCM锁地址相同,
说明他们被同一锁锁住。
LOCK_ELEMENT_NAME NUMBER 缓存块上PCM锁的地址。如果多个缓存块的PCM锁地址相同,
说明他们被同一锁锁住。
LOCK_ELEMENT_CLASS NUMBER 缓存块上PCM锁的地址。如果多个缓存块的PCM锁地址相同,
说明他们被同一锁锁住。
FORCED_READS NUMBER 由于其他实例的PCM锁锁住了该缓存块,导致当前实例尝试重
新请求读该缓冲块的次数。
FORCED_WRITES NUMBER 由于其他实例的PCM锁锁住了该缓存块,导致当前实例尝试重
新请求写该缓冲块的次数。
DIRTY VARCHAR2(1) 脏标志:Y – 块被修改过,是脏块;N – 不是脏块
TEMP VARCHAR2(1) 是否为临时块:Y – 是;N – 否。
PING VARCHAR2(1) 是否被ping住:Y – 是;N – 否。
STALE VARCHAR2(1) 是否是陈旧块:Y – 是;N – 否。
一、名词解释 (1)SGA:System Global Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。 (2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Library cache(共享SQL区)和Data dictionary cache(数据字典缓冲区)。共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。 (3)缓冲区高速缓存:Database Buffer Cache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。 (4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。 (5)Java池:Java Pool为Java命令的语法分析提供服务。 (6)PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。 二、分析与调整 (1)系统全局域: SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/3到1/2。 a.共享池Shared Pool: 查看共享池大小Sql代码 SQL>show parameter shared_pool_size 查看共享SQL区的使用率: Sql代码 select(sum(pins-reloads))/sum(pins)"Library cache"from v$librarycache; --动态性能表 LIBRARY命中率应该在90%以上,否则需要增加共享池的大小。
Oracle数据库实例及其相关概念2010-11-24 00:00 出处:中国IT实验室作者:佚名 完整的Oracle数据库通常由两部分组成:Oracle数据库实例和数据库。 用数据库安全策略防止权限升级攻击 C++虚函数的显式声明 完整的Oracle数据库通常由两部分组成:Oracle数据库实例和数据库。 1)数据库是一系列物理文件的集合(数据文件,控制文件,联机日志,参数文件等); 2)Oracle数据库实例则是一组Oracle后台进程/线程以及在服务器分配的共享内存区。 在启动Oracle数据库服务器时,实际上是在服务器的内存中创建一个Oracle实例(即在服务器内存中分配共享内存并创建相关的后台内存),然后由这个Oracle数据库实例来访问和控制磁盘中的数据文件。Oracle有一个很大的内存快,成为全局区(SGA)。 一、数据库、表空间、数据文件 1.数据库 数据库是数据集合。Oracle是一种数据库管理系统,是一种关系型的数据库管理系统。 通常情况了我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据、数据库管理系统。也即物理数据、内存、操作系统进程的组合体。 数据库的数据存储在表中。数据的关系由列来定义,即通常我们讲的字段,每个列都有一个列名。数据以行(我们通常称为记录)的方式存储在表中。表之间可以相互关联。以上就是关系模型数据库的一个最简单的描述。
当然,Oracle也是提供对面象对象型的结构数据库的最强大支持,对象既可以与其它对象建立关系,也可以包含其它对象。关于OO型数据库,以后利用专门的篇幅来讨论。一般情况下我们的讨论都基于关系模型。 2.表空间、文件 无论关系结构还是OO结构,Oracle数据库都将其数据存储在文件中。数据库结构提供对数据文件的逻辑映射,允许不同类型的数据分开存储。这些逻辑划分称作表空间。 表空间(tablespace)是数据库的逻辑划分,每个数据库至少有一个表空间(称作SYSTEM表空间)。为了便于管理和提高运行效率,可以使用一些附加表空间来划分用户和应用程序。例如:USER表空间供一般用户使用,RBS表空间供回滚段使用。一个表空间只能属于一个数据库。 每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。在Oracle7.2以后,数据文件创建可以改变大小。创建新的表空间需要创建新的数据文件。数据文件一旦加入到表空间中,就不能从这个表空间中移走,也不能与其它表空间发生联系。 如果数据库存储在多个表空间中,可以将它们各自的数据文件存放在不同磁盘上来对其进行物理分割。在规划和协调数据库I/O请求的方法中,上述的数据分割是一种很重要的方法。 3.Oracle数据库的存储结构分为逻辑存储结构和物理存储结构: 1)逻辑存储结构:用于描述Oracle内部组织和管理数据的方式; 2)物理存储结构:用于描述Oracle外部即操作系统中组织和管理数据的方式。 二、Oracle数据库实例
Oracle 内存内存全面全面全面分析分析 作者作者::fuyuncat 来源来源::https://www.doczj.com/doc/312326237.html, 作者简介 黄玮,男,99年开始从事DBA 工作,有多年的水利、军工、电信及航 运行业大型数据库Oracle 开发、设计和维护经验。 曾供职于南方某著名电信设备制造商——H 公司。期间,作为DB 组 长,负责设计、开发和维护彩铃业务的数据库系统。目前,H 公司的彩铃系 统是世界上终端用户最多的彩铃系统。最终用户数过亿。 目前供职于某世界著名物流公司,负责公司的电子物流系统的数据库开 发、维护工作。 msn: fuyuncat@https://www.doczj.com/doc/312326237.html, Email :fuyuncat@https://www.doczj.com/doc/312326237.html, Oracle 的内存配置与oracle 性能息息相关。而且关于内存的错误(如4030、4031错 误)都是十分令人头疼的问题。可以说,关于内存的配置,是最影响Oracle 性能的配 置。内存还直接影响到其他两个重要资源的消耗:CPU 和IO。 首先,看看Oracle 内存存储的主要内容是什么: ? 程序代码(PLSQL、Java); ? 关于已经连接的会话的信息,包括当前所有活动和非活动会话; ? 程序运行时必须的相关信息,例如查询计划; ? Oracle 进程之间共享的信息和相互交流的信息,例如锁; ? 那些被永久存储在外围存储介质上,被cache 在内存中的数据(如redo log 条 目,数据块)。 此外,需要记住的一点是,Oracle 的内存是与实例对应的。也就是说,一个实例就有 一个独立的内存结构。 先从Oracle 内存的组成架构介绍。 1. Oracle 的内存架构组成 Oracle 的内存,从总体上讲,可以分为两大块:共享部分(主要是SGA)和进程独享 部分(主要是PGA 和UGA)。而这两部分内存里面,根据功能不同,还分为不同内存池 (Pool)和内存区(Area)。下面就是Oracle 内存构成框架图:
一、名词解释 (1)SGA:SystemGlobal Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。 (2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Librarycache(共享SQL区)和Datadictionarycache(数据字典缓冲区)。共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。 (3)缓冲区高速缓存:DatabaseBufferCache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。 (4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。 (5)Java池:Java Pool为Java命令的语法分析提供服务。 (6)PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。 二、分析与调整 (1)系统全局域: SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/3到1/2。 a.共享池Shared Pool: 查看共享池大小Sql代码 SQL>show parameter shared_pool_size 查看共享SQL区的使用率: Sql代码 select(sum(pins-reloads))/sum(pins)"Library cache"from v$librarycache; --动态性能表 LIBRARY命中率应该在90%以上,否则需要增加共享池的大小。 查看数据字典缓冲区的使用率:
Oracle 内存分配与调整 一、前言 对于oracle 的内存的管理,截止到9iR2,都是相当重要的环节,管理不善,将可能给数据库带来严重的性能问题。下面我们将一步一步就内存管理的各个方面进行探讨。 二、概述 oracle 的内存可以按照共享和私有的角度分为系统全局区和进程全局区,也就是SGA 和PGA(process global area or private global area 。对于SGA 区域内的内存来说,是共享的全局的,在UNIX 上,必须为oracle 设置共享内存段(可以是一个或者多个,因为oracle 在UNIX 上是多进程;而在WINDOWS 上oracle 是单进程(多个线程,所以不用设置共享内存段。PGA 是属于进程(线程私有的区域。在oracle 使用共享服务器模式下(MTS,PGA 中的一部分,也就是UGA 会被放入共享内存 large_pool_size 中。对于SGA 部分,我们通过sqlplus 中查询可以看到: SQL> select * from v$sga; NAME V ALUE Fixed Size 454032 Variable Size 109051904 Database Buffers 385875968 Redo Buffers 667648 其中: Fixed Size:
oracle 的不同平台和不同版本下可能不一样,但对于确定环境是一个固定的值,里面存储了SGA 各部分组件的信息,可以看作引导建立SGA 的区域。Variable Size: 包含了shared_pool_size 、java_pool_size 、large_pool_size 等内存设置Database Buffers: 指数据缓冲区,在8i 中包含db_block_buffer*db_block_size 、 buffer_pool_keep 、buffer_pool_recycle 三部分内存。在9i 中包含db_cache_size 、 db_keep_cache_size 、db_recycle_cache_size 、db_nk_cache_size 。 Redo Buffers: 指日志缓冲区,log_buffer 。在这里要额外说明一点的是,对于v$parameter 、 v$sgastat 、v$sga 查询值可能不一样。v$parameter 里面的值,是指用户在初始化参 数文件里面设置的值,v$sgastat 是oracle 实际分配的日志缓冲区大小(因为缓冲区的分配值实际上是离散的,也不是以block 为最小单位进行分配的, v$sga 里面查询的值,是在oracle 分配了日志缓冲区后,为了保护日志缓冲区,设置了一些保护页,通常我们会发现保护页大小大约是11k(不同环境可能不一样。参考如下内容 SQL> select substr(name,1,10 name,substr(value,1,10 value 2 from v$parameter where name = 'log_buffer'; NAME V ALUE log_buffer 524288 SQL> select * from v$sgastat ; POOL NAME BYTES fixed_sga 454032
ABC公司Oracle数据库参数调整建议 1.Oracle参数initdb.ora (修改建议) 目前系统现在分析: (1)Windows 2003可以显示50G内存,但操作系统是32位,最多默认支持4G,用户进程支持2G,Oracle可能支持1.7G内存; (2)不清楚是否对操作系统做过支持大内存的调整;从下表的参数分析,可能没有修改; (3)不清楚此系统Windows是否允许在虚拟环境(Virtual Machine),故保守起见,我们的建议是:把内存往小里调整。 根据我们的经验,对Oracle数据库调整如下: 总内存控制在1.5G SGA控制在800M PGA使用700M testdb.__db_cache_size=469762048 testdb.__java_pool_size=8388608 testdb.__large_pool_size=8388608 testdb.__oracle_base='D:\app\Administrator'#ORACLE_BASE set from environment testdb.__pga_aggregate_target= 734003200 #700M #671088640 testdb.__sga_target=838860800 #800M #1249902592 testdb.__shared_io_pool_size=0 testdb.__shared_pool_size= 335544320 #320M #738197504 testdb.__streams_pool_size=8388608 *.audit_file_dest='D:\app\Administrator\admin\xbrldb\adump' *.audit_trail='db' *.compatible='11.2.0.0.0' *.control_files='E:\data\xbrldb\control01.ctl','D:\app\Administrator\flash_recovery_ area\xbrldb\control02.ctl' *.db_block_size=8192 *.db_domain='' *.db_name='xbrldb' *.db_recovery_file_dest='D:\app\Administrator\flash_recovery_area' *.db_recovery_file_dest_size=21474836480 *.diagnostic_dest='D:\app\Administrator' *.dispatchers='(PROTOCOL=TCP) (SERVICE=xbrldbXDB)' *.fast_start_mttr_target=30 *.job_queue_processes=1000 testdb.local_listener='(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(H OST=10.24.58.100)(PORT=1531))))' *.log_archive_format='ARC%S_%R.%T' *.memory_target= 1610612736 #1.5G#1916796928
一分钟查一个案例带你看看Oracle数据库到底有多牛逼 性能难题 问题来了 电话响了,是一位证券客户 DBA 的来电,看来,问题没过两天,又出现了。 接起电话,果不其然。 “小y,前天那个问题又重现了。重启后恢复正常,这次抓到了hangAnalyze,不过领导在身后一直催,所以没来得及抓取 systemstate dump 就重启了。你尽快帮忙分析下吧,hanganalyze 的 trace 文件 已经转到你邮箱了。” 就在 2 天前,该客户找到小 y, 他们有一套比较重要的系统出现了数据库无法登陆的情况,导致业务中断,重启后业务恢复,但原因未明,搞的他们压力很大。 可惜的是,他们是事后找过来,由于客户现场保护意识不足,最后也只能是巧妇难为无米之炊了… 总的来说,小 y 还算是比较熟悉证券行业的。 毕竟,小 y 多年来一直在银行、证券、航空等客户提供数据库专家支持服务,这其中就包括了北京 排名前 6 的所有证券公司。 简而言之,证券行业的要求就是快速恢复,快速恢复业务大于一切。 原因很简单,股价瞬息万变,作为股民,如果当时无法出售或者购买股票,甚至可能引发官司。所以,证券核心交易系统如果中断时间超过 5 分钟,则可以算得上是严重故障了,一旦被投诉,则可能会 被证监会通报,届时业务可能被降级,影响到证券公司的经营和收益。 结合这个特点,小 y 为客户制定了应急预案,看来收集 systemstate dump 是来不及了,只能先 收集 hangAnalyze, 时间来得及的话则可以继续收集 systemstate dump。收集 hangAnalyze 的命令 很简单,照敲就是了,没什么技术含量。 $sqlplus –prelim “/as sysdba” SQL>oradebug setmypid SQL>oradebug hanganalyze 3 .. 此处等上一会 .. SQL>oradebug hanganalyze 3 SQL>oradebug tracefile_name
Oracle数据库实例的内存和进程结构 更新: 2010-04-27来源: 互联网字体:【大中小】 内存结构 在Oracle数据库系统中内存结构主要分为系统全局区(SGA)和程序全局区(PGA)。 SGA随着数据库实例的启动向操作系统申请分配一块内存结构,随着数据库实例的关闭释放,每一个Oracle数据库实例有且只有一个SGA。 PGA随着Oracle服务进程启动的时候申请分配的一块内存结构。如果在共享服务结构中PGA存在SGA 中。 下图展示Oracle的内存结构,在后面我们将用文字详细的表述各个部件。 系统全局区(SGA) 重要提示,提高SGA的大小可以在一定程度上提高Oracle数据库系统的性能,但你设置SGA的值如果不能锁定在内存物理页上,有些部分可能被交换到系统的交换文件中。这样你的Oracle数据库系统将变慢。 系统全局区是一组包含数据和控制信息的共享内存结构,允许Oracle服务的众多后台进程同时访问或修改其中的数据,所以有些时候也被称为―全局共享区‖,参数文件中的SGA_MAX_SIZE指定SGA动态大小。※共享池SharedPool ※数据高速缓存DatabaseBufferCache ※重做日志缓存RedoLogBufferCache ※ Java池(可选)JavaPool ※大缓冲池(可选)LagerPool 共享池 共享池存储了最近多数使用的执行SQL语句和最近使用的数据定义。它包含库高速缓存器和数据字典缓存器这两个与性能相关的内存结构。共享池的大小可以通过初始化参数文件(通常为init.ora)中的SHARED_POOL_SIZE决定。共享池是活动非常频繁的内存结构,会产生大量的内存碎片,所以你要确保它尽可能足够大。 库高速缓存器,他又包含共享SQL区和共享PL/SQL区两个组件区。为了提高SQL语句的性能,在提交SQL语句或PL/SQL程序块时Oracle服务器将先利用最近最少使用(LRU)算法检查库高速缓存中是否存在相同的SQL语句或PL/SQL程序块,若有则使用原有的分析树和执行路径。 数据字典缓存器,它收集最近使用的数据库中的数据定义信息。它包含数据文件、表、索引、列、用户、访问权限、其他数据库对象等信息。在分析阶段决定数据库对象的可访问信息。利用数据字典缓存器有效的改善了响应时间。它的大小由共享池的大小决定。 数据高速缓存 它存储数据文件中数据块的拷贝。利用这种结构使数据的更新操作性能大大的提高。数据高速缓存中的数据交换同样采用最近最少使用算法(LRU)。它的大小主要受到DB_BLOCK_SIZE决定。数据高速缓存它由DB_CACHE_SIZE、DB_KEEP_CACHE_SIZE、 DB_RECYCLE_CACHE_SIZE这些独立的子缓存器构成,同时它能动态的增长或收缩。 重做日志缓存
启动Oracle数据库12c的第1版(12.1.0.2),在内存中的列存储(IM列存储)是存储表和分区的副本进行快速扫描优化的特殊柱状格式可选,静态SGA池。在IM列存储不更换缓存,但作为一个补充,使这两个存储区可存储不同格式相同的数据。默认情况下,仅使用DDL 对象指定的inmemory的候选人将填充在IM列存储。 柱状格式只存在于内存中。图14-8显示了存储在IM列存储SH模式三个表:客户,产品和销售。在IM列存储通过柱,而不是行存储数据。该数据库保持柱状数据缓冲区高速缓存事务一致性。 本节包含了以下主题: 在IM列存储的好处 双存储格式:纵栏和行 在内存中的列存储的人口 在内存列压缩 扫描优化的IM列存储 在IM列存储的好处 在IM列存储使得数据库进行扫描,联接和聚合时相比,它使用的磁盘格式完全快得多。特别是,对于IM列存储是很有用的: 扫描行数和应用使用运营商,如=过滤器,<,>,和IN 查询列的子集在表中,例如,选择5 100的列 加快加入通过将小维表谓词到过滤器上的一个大的事实表 业务应用,即席分析查询和数据仓库工作负载受益最大。执行使用索引查找短事务纯OLTP 数据库中受益较少. 在IM列存储还具有以下优点: 所有现有的数据库功能都支持,包括高可用性功能(参见“高可用性概述”)。 没有应用程序的改变是必需的。 优化器会自动柱状格式的优势。 配置简单。 该INMEMORY_SIZE初始化参数指定的内存预留供IM列存储的使用量。DDL语句指定表空间,表,分区或列被读入IM列存储。 压缩优化的查询性能。 这些压缩技术通过使会话读取更多的数据到内存中增加有效的内存带宽。 更少的索引,物化视图和OLAP多维数据集是必需的。
Oracle内存全面分析(1) 作者:fuyuncat 来源:https://www.doczj.com/doc/312326237.html, Oracle的内存配置与oracle性能息息相关。而且关于内存的错误(如4030、4031错误)都是十分令人头疼的问题。可以说,关于内存的配置,是最影响Oracle性能的配置。内存还直接影响到其他两个重要资源的消耗:CPU 和IO。 首先,看看Oracle内存存储的主要内容是什么: ?程序代码(PLSQL、Java); ?关于已经连接的会话的信息,包括当前所有活动和非活动会话; ?程序运行时必须的相关信息,例如查询计划; ?Oracle进程之间共享的信息和相互交流的信息,例如锁; ?那些被永久存储在外围存储介质上,被cache在内存中的数据(如redo log条目,数据块)。 此外,需要记住的一点是,Oracle的内存是与实例对应的。也就是说,一个实例就有一个独立的内存结构。 先从Oracle内存的组成架构介绍。
1.Oracle的内存架构组成 Oracle的内存,从总体上讲,可以分为两大块:共享部分(主要是SGA)和进程独享部分(主要是PGA 和UGA)。而这两部分内存里面,根据功能不同,还分为不同内存池(Pool)和内存区(Area)。下面就是Oracle内存构成框架图: SGA Share Pool Buffer Cache Redo Log Buffer Java Pool Stream Pool(10g)Large Pool PGA*n Bitmap merge area Sort Area Hash Area UGA*n CUA*n 下面分别介绍这两块内存区。 1.1.SGA(System Global Area) SGA(System Global Area 系统全局区域)是一组包含一个Oracle实例的数据和控制信息的共享内存结构。这句话可以说是SGA的定义。虽然简单,但其中阐述了SGA几个很重要的特性:1、SGA的构成——数据和控制信息,我们下面会详细介绍;2、SGA是共享的,即当有多个用户同时登录了这个实例,SGA中的信息可以被它们同时访问(当涉及到互斥的问题时,由latch和enquence控制);3、一个SGA只服务于一个实例,也就是说,当一台机器上有多个实例运行时,每个实例都有一个自己的SGA,尽管SGA来自
详解:oracle10G 数据库名、实例名、ORACLE_SID 【转载】 数据库名、实例名、数据库域名、全局数据库名、服务名, 这是几个令很多初学者容易混淆的概念。相信很多初学者都与我一样被标题上这些个概念搞得一头雾水。我们现在就来把它们弄个明白。 一、数据库名 什么是数据库名? 数据库名就是一个数据库的标识,就像人的身份证号一样。他用参数DB_NAME表示,如果一台机器上装了多全数据库,那么每一个数据库都有一个数据库名。在数据库安装或创建完成之后,参数DB_NAME被写入参数文件之中。格式如下: DB_NAME=myorcl ... 在创建数据库时就应考虑好数据库名,并且在创建完数据库之后,数据库名不宜修改,即使要修改也会很麻烦。因为,数据库名还被写入控制文件中,控制文件是以二进制型式存储的,用户无法修改控制文件的内容。假设用户修改了参数文件中的数据库名,即修改DB_NAME 的值。但是在Oracle启动时,由于参数文件中的DB_NAME与控制文件中的数据库名不一致,导致数据库启动失败,将返回ORA-01103错误。 数据库名的作用 数据库名是在安装数据库、创建新的数据库、创建数据库控制文件、修改数据结构、备份与恢复数据库时都需要使用到的。 有很多Oracle安装文件目录是与数据库名相关的,如: winnt: d:\oracle\product\10.1.0\oradata\DB_NAME\... Unix: /home/app/oracle/product/10.1.0/oradata/DB_NAME/... pfile: winnt: d:\oracle\product\10.1.0\admin\DB_NAME\pfile\ini.ora Unix: /home/app/oracle/product/10.1.0/admin/DB_NAME/pfile/init$ORACLE_SID.ora 跟踪文件目录: winnt: /home/app/oracle/product/10.1.0/admin/DB_NAME/bdump/... 另外,在创建数据时,careate database命令中的数据库名也要与参数文件中DB_NAME参数的值一致,否则将产生错误。 同样,修改数据库结构的语句alter database,当然也要指出要修改的数据库的名称。 如果控制文件损坏或丢失,数据库将不能加载,这时要重新创建控制文件,方法是以nomount 方式启动实例,然后以create controlfile命令创建控制文件,当然这个命令中也是指指DB_NAME。 还有在备份或恢复数据库时,都需要用到数据库名。 总之,数据库名很重要,要准确理解它的作用。 查询当前数据名 方法一:select name from v$database; 方法二:show parameter db 方法三:查看参数文件。 修改数据库名 前面建议:应在创建数据库时就确定好数据库名,数据库名不应作修改,因为修改数据库名是一件比较复杂的事情。那么现在就来说明一下,如何在已创建数据之后,修改数据库名。步骤如下:
对oracle实例的内存(SGA和PGA)进行调整,优化数 据库性 一、示例: SGA: 共享池:200MB 缓冲区高速缓存:24MB 大型池:9MB Java池:32MB SAG总容量:264.933 SAG的最大大小:305.069 PGA: 总记PGA目标:240MB 分配的当前PGA:8914KB 分配的最大PGA(自启动以来)9081KB 高速缓存命中百分比:100% PGA和SGA的和应小于系统内存总量前去操作系统和其他应用程序所需内存后得到的值。 二、名词解释: SGA:System Global Area是Oracle Instance的基本组成部分,在实例启动时分配; 系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。 共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义, 主要包括:Library cache(共享SQL区)和Data dictionary cache(数据字典缓冲区) 共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息 缓冲区高速缓存:Database Buffer Cache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能 大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server 环境 Java池:ava Pool为Java命令的语法分析提供服务
PGA:Program Global Area是为每个连接到Oracle database的用户进程保留的内存。 三、分析与调整: 1、系统全局域: SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/2到1/3,当然,如果服务器上只有oracle的话, 可以分配的更大一些,如果还有其他服务,如IIS等,那就要分的小一些。 1、共享池: 修改共享池的大小,ALTER SYSTEM SET SHARED_POOL_SIZE = 64M; 查看共享SQL区的使用率: select(sum(pins-reloads))/sum(pins) "Library cache" from v$librarycache;--动态性能表 这个使用率应该在90%以上,否则需要增加共享池的大小。 查看数据字典缓冲区的使用率: select (sum(gets-getmisses-usage-fixed))/sum(gets) "Data dictionary cache" from v$rowcache;--动态性能表 这个使用率也应该在90%以上,否则需要增加共享池的大小。 2、缓冲区高速缓存: 它的大小要根据数据量来决定: SGA=((db_block_buffers * block size)+(shared_pool_size+large_pool_size+java_pool_size+log_buffers)+1MB 查看数据库数据缓冲区的使用情况: SELECT name,value FROM v$sysstat order by name WHERE name IN(''DB BLOCK GETS'',''CONSISTENT GETS'',''PHYSICAL READS''); 计算出来数据缓冲区的使用命中率=1-(physical reads/(db block gets+consistent gets)),这个命中率应该在90%以上,否则需要 增加数据缓冲区的大小。 select sum(pins) "请求存取数",sum(reloads) "不命中数 ",sum(reloads)/sum(pins) from v$librarycache 其中,pins,显示在库高速缓存中执行的次数;reload,显示在执行阶段库高速缓存不命中的数目,一般 sum(reloads)/sum(pins)的 值应接近于零.如果大于1%就应该增加shared_pool_size的值, 来提高数据字典高速缓存可用的内存数量,减少不命中数.
Oracle内存参数调优技术详解 前言 近来公司技术,研发都在问我关于内存参数如何设置可以优化oracle的性能,所以抽时间整理了这篇文档,以做参考. 目的 希望通过整理此文档,使大家对oracle内存结构有一个全面的了解,并在实际的工作中灵活应用,使oracle的内存性能达到最优配置,提升应用程序反应速度,并进行合理的内存使用. 内容 实例结构 oracle实例=内存结构+进程结构 oracle实例启动的过程,其实就是oracle内存参数设置的值加载到内存中,并启动相应的后台进程进行相关的服务过程。 进程结构 oracle进程=服务器进程+用户进程 几个重要的后台进程: DBWR:数据写入进程. LGWR:日志写入进程. ARCH:归档进程. CKPT:检查点进程(日志切换;上一个检查点之后,又超过了指定的时间;预定义的日志块写入磁盘;例程关闭,DBA强制产生,表空间offline) LCKn(0-9):封锁进程. Dnnn:调度进程.
内存结构(我们重点讲解的) 内存结构=SGA(系统全局区)+PGA(程序全局区) SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写 我们重点就是设置SGA,理论上SGA可占OS系统物理内存的1/2——1/3 原则:SGA+PGA+OS使用内存<总物理RAM SGA=((db_block_buffers*blocksize)+(shared_pool_size+large_pool_size+jav a_pool_size+log_buffers)+1MB 1、SGA系统全局区.(包括以下五个区) A、数据缓冲区:(db_block_buffers)存储由磁盘数据文件读入的数据。 大小: db_block_buffers*db_block_size Oracle9i设置数据缓冲区为:Db_cache_size 原则:SGA中主要设置对象,一般为可用内存40%。 B、共享池:(shared_pool_size):数据字典,sql缓冲,pl/sql语法分析.加大可提速度。原则:SGA中主要设置对象,一般为可用内存10% C、日志缓冲区:(log_buffer)存储数据库的修改信息. 原则:128K ---- 1M 之间,不应该太大 D 、JAVA池(Java_pool_size)主要用于JAVA语言的开发.
1:实例(Instance) 在一个服务器中,每一个运行的数据库都与一个数据库实例相联系,实例是我们 访问数据库的手段。 实例在操作系统中用ORACLE_SID来标识,在中用参数INSTANCE_NAME来标识, 它们两个的值是相同的。数据库启动时,系统首先在服务器内存中分配系统全局区(SGA),构成了Oracle的内存结构,然后启动若干个常驻内存的操作系统进程,即组成了的 进程结构,内存区域和后台进程合称为一个实例。 数据库与实例之间是1对1/n的关系,在非并行的数据库系统中每个数据库与一个 实例相对应;在并行的数据库系统中,一个数据库会对应多个实例,同一时间用户只与一个
实例相联系,当某一个实例出现故障时,其他实例自动服务,保证数据库正常运行。在任何情况下,每个实例都只可以对应一个数据库。 2:10g动态内存管理 内存是影响数据库性能的重要因素,Oracle8i使用静态内存管理,10g使用动态 内存管理。所谓静态内存管理,就是在数据库系统中,无论是否有用户连接,也无论并发用量大小,只要数据库服务在运行,就会分配固定大小的内存;动态内存管理允许在数据库服务运行时对内存的大小进行修改,读取大数据块时使用大内存,小数据块时使用小内存,读取标准内存块时使用标准内存设置。 按照系统对内存使用方法的不同,数据库的内存可以分为以下几个部分: ?系统全局区:SGA(System Global Area) ?程序全局区:PGA(Programe Global Area) ?排序池:(Sort Area) ?大池:(Large Pool) ?Java池:(Pool) 2-1:系统全局区SGA(System Global Area) SGA是一组为系统分配的共享的内存结构,可以包含一个数据库实例的数据或控制信 息。如果多个用户连接到同一个数据库实例,在实例的SGA中,数据可以被多个用户共享。当数据库实例启动时,SGA的内存被自动分配;当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。 SGA的有关信息可以通过下面的语句查询,sga_max_size的大小是不可以动态调整的。 ===================================== > show parameter sga NAME TYPE VALUE ------------------------------------ ----------- -------- loc 您正在看的Oracle是:Oracle的内存结构和进程结构。 k_sga boolean FALSE pre_page_sga boolean FALSE sga_max_size big integer 164M sga_target big integer 0
Oracle内存分配与调整 者 l 作者介绍 冯春培,毕业于北京信息工程学院。曾做电信计费后台程序开发,从事过开发DBA工作,目前公司主要做数据库优化产品开发。热爱ORACLE,在https://www.doczj.com/doc/312326237.html,任数据库管理版块版主(biti_rainy),个人兴趣主要在oracle internal、performance tuning。对数据库管理、备份与恢复、数据库应用开发、SQL优化均有广泛理解。希望大家一起探讨oracle及相关技术。 l 前言 对于oracle的内存的管理,截止到9iR2,都是相当重要的环节,管理不善,将可能给数据库带来严重的性能问题。下面我们将一步一步就内存管理的各个方面进行探讨。 l 概述 oracle的内存可以按照共享和私有的角度分为系统全局区和进程全局区,也就是SGA 和PGA(process global area or private global area)。对于SGA区域内的内存来说,是共享的全局的,在UNIX上,必须为oracle设置共享内存段(可以是一个或者多个),因为oracle在UNIX上是多进程;而在WINDOWS上oracle是单进程(多个线程),所以不用设置共享内存段。PGA是属于进程(线程)私有的区域。在oracle使用共享服务器模式下(MTS),PGA 中的一部分,也就是UGA会被放入共享内存large_pool_size中。 对于SGA部分,我们通过sqlplus中查询可以看到: SQL> select * from v$sga; NAME VALUE -------------------- ---------- Fixed Size 454032 Variable Size 109051904 Database Buffers 385875968 Redo Buffers 667648 Fixed Size oracle 的不同平台和不同版本下可能不一样,但对于确定环境是一个固定的值,里面存储了SGA各部分组件的信息,可以看作引导建立SGA的区域。 Variable Size 包含了shared_pool_size、java_pool_size、large_pool_size等内存设置和用于管理数据缓冲区等内存结构的hash table、块头信息(比如x$bh消耗内存)等 Database Buffers 指数据缓冲区,在8i中包含default pool、buffer_pool_keep、buffer_pool_recycle三部分内存。在9i中包含db_cache_size、db_keep_cache_size、db_recycle_cache_size、
1:Oracle实例(Instance) 在一个服务器中,每一个运行的Oracle数据库都与一个数据库实例相联系,实例是我们 访问数据库的手段。 实例在操作系统中用ORACLE_SID来标识,在Oracle中用参数INSTANCE_NAME来标识, 它们两个的值是相同的。数据库启动时,系统首先在服务器内存中分配系统全局区(SGA), 构成了Oracle的内存结构,然后启动若干个常驻内存的操作系统进程,即组成了O racle的 进程结构,内存区域和后台进程合称为一个Oracle实例。
数据库与实例之间是1对1/n的关系,在非并行的数据库系统中每个Oracle数据库与一个 实例相对应;在并行的数据库系统中,一个数据库会对应多个实例,同一时刻用户只与一个 实例相联系,当某一个实例出现故障时,其他实例自动服务,保证数据库正常运行。在任何 情况下,每个实例都只能够对应一个数据库。 2:Oracle 10g动态内存治理 内存是阻碍数据库性能的重要因素,Oracle8i使用静态内存治理,Oracle 10g使用动态 内存治理。所谓静态内存治理,确实是在数据库系统中,不管是否有用户连接,也不管并发用 量大小,只要数据库服务在运行,就会分配固定大小的内存;动态内存治理同意在数据库服 务运行时对内存的大小进行修改,读取大数据块时使用大内存,小数据块时使用小
内存,读 取标准内存块时使用标准内存设置。 按照系统对内存使用方法的不同,Oracle数据库的内存能够分为以下几个部分:?系统全局区:SGA(System Global Area) ?程序全局区:PGA(Programe Global Area) ?排序池:(Sort Area) ?大池:(Large Pool) ?Java池:(Java Pool) 2-1:系统全局区SGA(System Global Area) SGA是一组为系统分配的共享的内存结构,能够包含一个数据库实例的数据或操纵信 息。假如多个用户连接到同一个数据库实例,在实例的SGA中,数据能够被多个用户共享。 当数据库实例启动时,SGA的内存被自动分配;当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是阻碍数据库性能的重要因素。 SGA的有关信息能够通过下面的语句查询,sga_max_size的大小是不能够动态调整的。 ===================================== SQL> show parameter sga NAM