
东北三省经济发展水平
及影响因素因子分析
摘要:东北三省在我国属经济欠发达地区,对于这个资源丰富、地理位置占有绝对优势的地区来讲,这是一个可悲的现象。东北三省有着太多的共同点,但又有着各自的特点,这对于东北三省发挥各自的优势以及进行经济合作都是非常有利的。作为东北土生土长的孩子,很希望能为家乡的经济发展献计献策,贡献一份自己的力量。本文通过对部分经济指标进行因子分析,判断出造成东北三省经济差距的潜在因素及三省各自的优势,并给出东北三省发挥各自优势以及共同合作的建议。
关键词:经济比较,东北三省,因子分析
(一)前言
改革开放以来,我国的经济发展取得了举世瞩目的成就,综合国力日益增强,人民生活水平也显著提高,我国各个省的经济发展水平也都随着国力的增强而提高。但是,各个省的经济发展速度并不是同步的,导致省域经济发展水平不同,而且差距有日趋扩大的趋势。区域经济发展的不平衡性是世界经济、世界各国各地区经济发展中普遍存在的现象。就全世界而言,表现为发达国家与发展中国家之间的差距;就我国,则表现为东西部差距。这种不平衡发展会影响国民经济整体素质的提高以及国民经济的协调发展,关系到整个现代化的进程。在这种情况下,比较各省域的经济发展水平,明确各省域经济在整个国民经济中的位置,分析各省域的优势与劣势,对于各省域制定其最优发展策略以及对国家制定区域经济协调发展政策都有重大的意义。
在各地区的经济蓬勃发展的同时,东北三省经济日益相对落后,已成为制约中国经济跃上新台阶、实现工业化与现代化的瓶颈。在中华人民共和国历史上,东北三省经济曾有过令人刮目相看的成就与辉煌。直到1978 年,东北三省的人均GDP 仅次于京、津、沪3 大直辖市,在全国处于领先地位。但是,从上个世纪90 年代开始,东北三省经济发展明显落后了。由于中国改革开放首先从东南沿海地区起步,各种优惠政策首先在那里实施,外国资本及先进技术与管理方法最先从那里引入,因而东南沿海地区经济快速增长。尤其是自1992 年春天起,在邓小平南巡讲话精神的鼓舞下,中国经济发展战略的重点更是明显地移向东南沿海地区,资本、技术和人才一并“东南飞”。而此时,东北三省几乎被冷落、被担负大量沉重包袱的国企所拖累、被落后且严重失衡的产业结构所困扰,发展步伐日益趋缓。可以肯定地讲,东北三省经济若不振兴,中国的工业化与现代化必然大受影响,甚至难以实现。因此,振兴东北三省经济是当今中国经济发展的大局,是全国人民的根本利益所在。
我是一名土生土长的黑龙江人,虽然对家乡充满了无限的热爱,但也深知家乡的经济水平处在全国相对落后的位置。而黑龙江作为全国位置最东北的一个省,作为东北三省这个整体的重要组成部分,对于整个东北的发展也起到至关重要的作用。因此,我通过对本文的创作,对东北三省的经济进行综合的比较和分析,得到三个省各自的优势和劣势,为其各自的发展和东北三省彼此间的合作提出合理的意见和建议,希望能够为东北三省的经济发展提供一定的帮助。
(二)东北三省的经济概况
自上个世纪80年代以来,历史上一度作为老工业基地的我国东北地区的经济地位在全国相对下降。东北三省的发展速度,特别是工业和经济总量的增长率渐渐落后于全国平均水平。
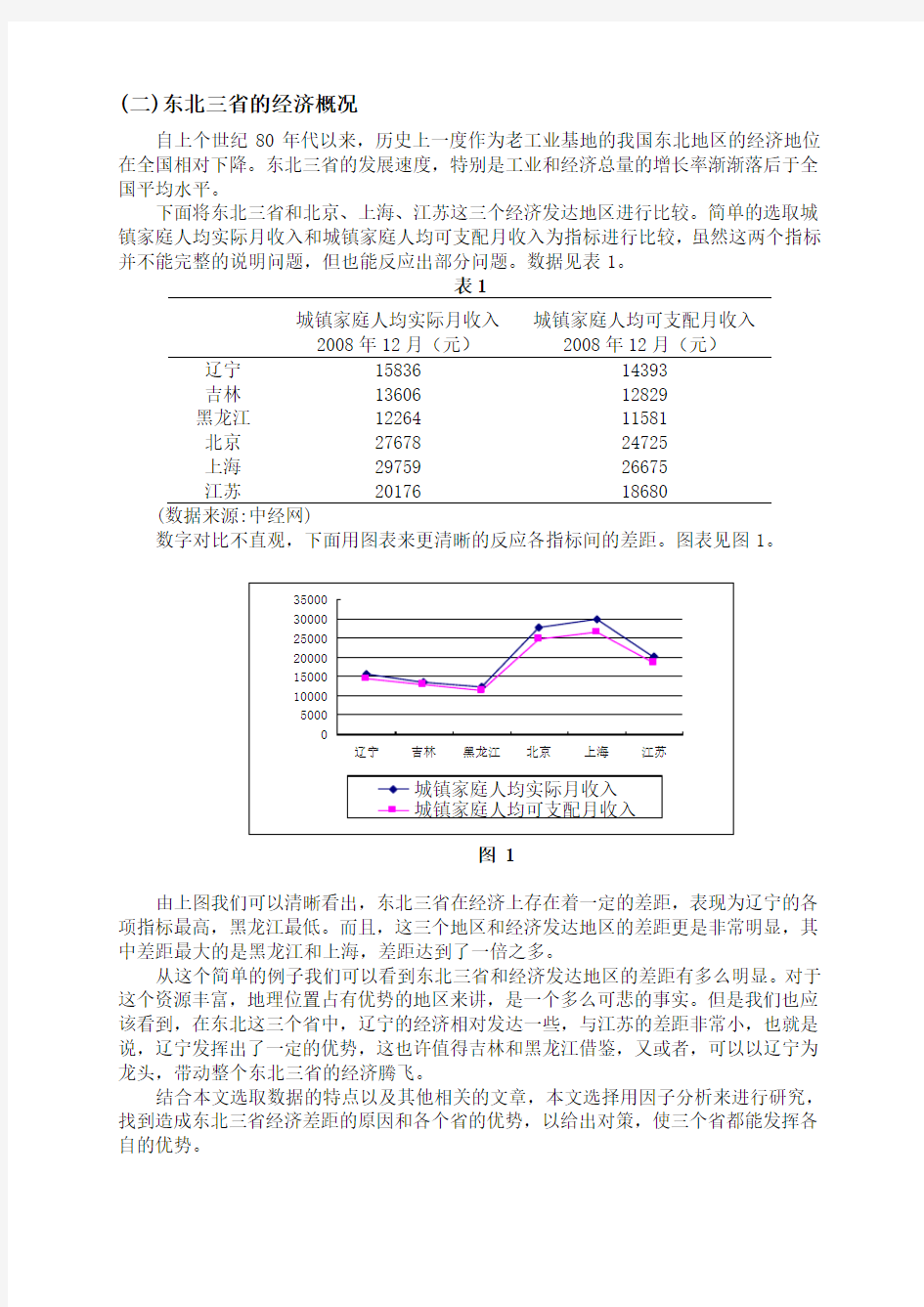
下面将东北三省和北京、上海、江苏这三个经济发达地区进行比较。简单的选取城镇家庭人均实际月收入和城镇家庭人均可支配月收入为指标进行比较,虽然这两个指标并不能完整的说明问题,但也能反应出部分问题。数据见表1。
表1
城镇家庭人均实际月收入城镇家庭人均可支配月收入
2008年12月(元)2008年12月(元)
辽宁15836 14393
吉林13606 12829
黑龙江12264 11581
北京27678 24725
上海29759 26675
江苏20176 18680
(数据来源:中经网)
数字对比不直观,下面用图表来更清晰的反应各指标间的差距。图表见图1。
图 1
由上图我们可以清晰看出,东北三省在经济上存在着一定的差距,表现为辽宁的各项指标最高,黑龙江最低。而且,这三个地区和经济发达地区的差距更是非常明显,其中差距最大的是黑龙江和上海,差距达到了一倍之多。
从这个简单的例子我们可以看到东北三省和经济发达地区的差距有多么明显。对于这个资源丰富,地理位置占有优势的地区来讲,是一个多么可悲的事实。但是我们也应该看到,在东北这三个省中,辽宁的经济相对发达一些,与江苏的差距非常小,也就是说,辽宁发挥出了一定的优势,这也许值得吉林和黑龙江借鉴,又或者,可以以辽宁为龙头,带动整个东北三省的经济腾飞。
结合本文选取数据的特点以及其他相关的文章,本文选择用因子分析来进行研究,找到造成东北三省经济差距的原因和各个省的优势,以给出对策,使三个省都能发挥各自的优势。
(三)什么是因子分析
因子分析法是将各项指标归纳为一项或多项综合指标的一种多元统计方法。多变量大样本资料无疑能为科学研究提供很多有价值的信息,但有时,有必要简化(降维)数据,即从多变量或大样本中选择少数几个综合独立的新变量或个案,用以反映原来变量的大部分信息。数据简化(降维)分析中的因子分析能实现这个目的。因子分析是从多个变量(指标)中选择出少数几个综合变量的一种降维多元统计分析方法,用以达到数据简化的目的。在分析处理多变量问题时,变量间往往相关极为密切,使得观测数据所反映的信息有重叠,因此,人们希望能找出较少的综合变量尽可能多地反映原来变量的信息,彼此之间又互不相关。这些不可观测的少数几个综合变量称为公共因子或潜在因子。因子分析可以根据用户选择的对象提取公因子方法与初始因子载荷矩阵的旋转方式,输出变量的特征值,方差百分比,累计方差百分比,旋转后的因子矩阵,碎石图,以及旋转因子空间成分图等。
(四)东北三省经济发展差距的因子分析
结合东北三省的特点以及其他相关文章的指标选取,本文选取人均国内生产总值、农业总产值、国际旅游收入、全社会固定资产投资总额、工业总产值、原煤产量、原油产量、天然气产量、钢产量共九个经济指标。以上指标体系尽管并不能覆盖东北三省经济发展的所有方面,但基本反映了东北三省的经济运行情况。由于选择了因子分析方法,所以数据选取了从1989年到2007年以保证因子分析的可行性。详细数据见表2。
表2
农业总产值工业总产值全社会固定资产投资总额年份
辽宁吉林黑龙江辽宁吉林黑龙江辽宁吉林黑龙江
109.87 86.61 111.48 1092.4 530.36 804.77 88.85 271.06 170.64 1989
146.2 135.3 178 1124.8 552.36 863.51 93.22 228.76 164.02 1990
158.3 129.4 170.9 1493.7 539.35 888.83 113.99 315.37 189.7 1991
176.1 138.9 199.9 1825.6 662.93 983.13 151.3 431.04 244.29 1992
250.3 174.63 235.36 2611.4 890.43 1233.1 248.29 710.92 330.55 1993
301.35 270.81 381.45 3221.1 1084.8 1609.8 288.61 866.49 404.94 1994
391.9 301.44 462.16 3544.3 1233.5 1951.3 320.27 865.49 517.62 1995
455.14 363.67 558.68 3354.6 1232.6 1967.7 362.99 881.67 568.64 1996
433.62 315.45 571.1 3644.9 1355.5 2141.9 361.17 986.62 669.86 1997
534.7 394.9 517.6 3147.9 1225.5 1739.7 431.8 1057.7 770.1 1998
510.9 388.4 460 3390.1 1366.9 1854.6 500 1119.5 751.7 1999
463.5 320.3 414.4 4249.5 1679.9 2460.9 603.5 1267.7 832.6 2000
503.1 405.9 450.6 4480.3 1876.7 2365.4 701.7 1421.2 963.6 2001
540.1 419.7 487.5 4888 2171.2 2487.6 834.2 1605.6 1046.2 2002
497.3 438.3 502.9 6113 2662.3 2910 969 2076.4 1166.2 2003
611.3 486.2 620.2 8463.7 3227.1 3812.5 1169.1 2979.6 1430.8 2004
640.1 518.1 718.6 10815 3792 4714.9 1741.1 4200.4 1737.3 2005
597 787.4 14168 4752.7 5440.2 2594.3 5689.6 2236 2006 715.1
837.5 641.5 971.9 18250 6486 6143.2 3651.4 7435.2 2833.5 2007
表2续1
原煤产量原油产量天然气产量
年份
辽宁吉林黑龙江辽宁吉林黑龙江辽宁吉林黑龙江1989 0.498 0.244 0.7617 1092.4 342.24 5555.6 19.98 1.02 22.49 1990 0.510 0.361 0.8263 1124.8 356.7 5562.2 20.42 0.98 22.47 1991 0.52 0.26 0.85 1493.7 342.3 5562.3 20.55 1.26 22.73 1992 0.54 0.25 0.84 1825.6 344.06 5565.8 21.1 1.68 22.87 1993 0.56 0.24 0.73 2611.4 338.43 5590.5 20.78 2.05 22.28 1994 0.55 0.25 0.77 3221.1 332 5601 21.15 2.16 23.2 1995 0.56 0.26 0.79 3544.3 342.73 5601.5 21.12 1.83 25.91 1996 0.6 0.26 0.82 3354.6 373.6 5601.7 19.62 2.1 23.33 1997 0.59 0.27 0.85 3644.9 405.1 5609.2 19.14 2.95 23.49 1998 0.58 0.21 0.71 3147.9 397.07 5593.8 15.55 2.12 23.3 1999 0.48 0.16 0.62 3390.1 358.02 5450.5 14.28 2.4 22.35 2000 0.45 0.16 0.5 4249.5 348.46 5306.7 14.7 2.05 23.04 2001 0.45 0.18 0.57 4480.3 388.83 5161.1 14.71 2.05 22.03 2002 0.52 0.17 0.59 4888 477.01 5029.4 13.31 2.41 20.22 2003 0.59 0.2 0.67 6113 476.4 4840.1 13.28 2.32 20.96 2004 0.62 0.24 0.72 8463.7 478.89 4672.2 12.68 3.66 20.5 2005 0.64 0.27 0.95 10815 550.57 4516 11.72 5.4 24.43 2006 0.74 0.3 1.03 14168 680.35 4340.5 11.94 2.41 24.65 2007 0.63 0.34 1.01 18250 623.93 4169.8 8.72 5.22 25.5
1989 54.7 3.35 5.27 2574 1635 1808 1206.8 95.72 65.22 1990 69 6 7 2698 1746 2028 1216.3 95.19 74.6 1991 86.2 8.59 8.81 2707 1718 2099 1262.5 99.65 83.64 1992 101.64 11.06 13.37 3254 2071 2433 1349.9 117.3 104.03 1993 116.55 11.1 13.09 5015 2868 2343 1413.3 125.18 117.5 1994 166.43 24.88 48 6103 3703 4427 1340 111 106 1995 189 41 61 6880 4414 5465 1335.8 93.76 115.93 1996 224 53 78 7730 5163 6468 1369.3 84.15 119.11 1997 260 59 105 8525 5504 7243 1354.9 88.41 139.01 1998 262 38 121 9333 5916 7544 1406.5 79.14 151.99 1999 304 45 148 10086 6341 7660 1492.2 77.5 169.94 2000 383 58 189 11226 6847 8562 1553.8 88.99 159.31 2001 463 76 250 12041 7640 9349 1660.7 93.64 200.56 2002 550 86 297 12986 8334 10184 1942.5 144.2 281.06 2003 454 66 244 14258 9338 11615 2227.8 165.69 381.62 2004 613 96 302 15823 11537 12449 2595.5 238.25 406.76 2005 738 120 340 18983 13348 14434 3059.1 247.73 462.01 2006 934 137 492 21788 15720 16195 3702.3 315.2 533.65 2007 1228 179 643 25729 19383 18478 4140.3 436.05 599.67 (数据来源:中经网。)
(四)数据处理过程
因选取指标较多,尺寸不一,且相互之间关系错综复杂,为尽量减少主观因素的影响,保证评价过程的客观性和科学性,采用因子分析法进行简化。其基本步骤如下:假定有m个地区,n项评价指标,则矩阵[Xij]m*n即为评价样本矩阵。
1.原始数据的标准化处理,即将统一变量减去其均值再除以标准差,以消除不同量纲的影响,记为Yij=(Xij-Xj)/Dij,其中Yij为第i个地区第j个指标的标准化数值,Xij 为第i个地区的第j个指标,Xj为m个地区第j个指标均值,Dij为第i个地区指标的标准差;
2. 给出标准化矩阵Y的相关矩阵R;
3.求R的特征值,并根据特征根确定相应的正交化特征向量;
4.计算特征根的累计贡献率,并根据过程内定特征根大于1的原则确定主因子的个数和相应的特征向量矩阵;
5.建立因子载荷矩阵,并对其实行方差最大旋转;
6.计算主因子得分值;
7.计算综合评价得分,分值越高,说明该地区经济发展的越好。
为确认上述数据能否用因子分析进行处理,首先要对数据进行KMO检验。原假设:数据不能用于因子分析,备择假设:数据可以用于因子分析。通过SPSS的输出结果见表3。
表3
从上面的结果我们可以看到SIG值为1.656018335786e-144,图表上显示的为0,在显著性水平为0.05的情况下,拒绝原假设,即:可以使用因子分子对数据进行处理。
(五)结果分析
在使用SPSS软件对数据进行处理过程中,选择特征根大于1,也就是只保留特征值大于1的变量。由输出结果我们可以看到,一共有三个特征值大于1。对数据进行转置,选择方差最大。这样做是将数据旋转到方差最大的方向上,使得同样的变量,可以解释更多的信息。从输出结果看,结果也是有三个特征值大于1。这三个变量的累计方差贡献率93.773%。这个结果是比较理想的,也就是这三个变量可以解释所有变量93.773%的信息。结果见表4。
表4
Total Variance Explained
Extraction Method: Principal Component Analysis.
因子载荷矩阵见表5。
表5
从上面的因子载荷矩阵我们可以看到,国际旅游收入、工业总产值、钢产量在第一个公共因子上有比较大的载荷,我们可以认为第一个公共因子为工业因子。原煤产量、原油产量、天然气产量在第二个公共因子上有很大的载荷,所以可以认为第二个公共因子为自然资源因子。人均国内生产总值、农业总产值、全社会固定资产投资总额在第三个公共因子上有较大的载荷,可以因为第三个公共因子为经济产值因子。
为了检验每个省在每个因子上发挥了多少,我们可以计算因子得分。因子得分高,则表示这个省在这个因子上发挥的比较出色,相反,如果因子得分低,则表示在这个因子上还有欠缺。因为本文选取的数据比较多,所以选择2007年的因子得分作为比较标准。得分见表6。
表6
因子1因子2因子3
辽宁 3.780-0.414 1.435
吉林-0.977-1.056 3.488
黑龙江0.308 1.613 2.115
我们从上表可以看到,辽宁在第一个因子上得分最高,也就是说辽宁的工业在东北三个省中是最发达的,这和大家的主观认识相一致。黑龙江在第二个因子上的载荷最大,也就是说,黑龙江的自然资源是最丰富的,或者说黑龙江的自然资源开发利用的最多。吉林在第三个公共因子上得分最高,也就是说吉林的经济产值是三个省中比较高的。
计算综合得分。构造综合评价函数:Fα=λ1*Fα1+λ2*Fα2+λ3*Fα3。其中,F α——地区的综合评分;λi——特征值; Fαi——各因子得分。综合得分高的则表示当地的综合经济发展的比较好,得分低则表示综合经济发展的比较差。
各个省的综合得分分别是:辽宁14.334878,吉林2.61985677,黑龙江10.741759。我们可以看出,辽宁的综合得分最高,也就是说在东北三个省中辽宁经济最发达,黑龙江次之,吉林最差。
(六)对东北三省经济发展的建议
1.资源共享,优势互补
根据各省的优势,实现生产要素互补,从而最大限度地发挥各区域的整体优势,即对区域内的资源进行有效整合,合理配置,打破地区封锁,强化互动,搞好产业配套,形成集群效应。
2.创造自主品牌
首先,应该营造一个良好的舆论气氛,扭转大家对东北三省产品的认识,不要一提到东北三省的产品大家就想到粗糙的原始材料。其次,加快东北三省市场化改革的步伐,全面建立现代企业制度,促进企业努力创造名牌产品。再次,发挥传统产业优势和资源优势,创造特色名品。最后,东北地区可以根据国内外的需求,不仅开发出名优的机械装备产品,也可以开发出主要服务于东北地区和东北亚地区的轻工业名牌产品。
3.充分开发旅游资源
东北地区地域相连、文化相近、历史悠久,具有丰富的旅游资源,以原始、粗犷、神奇和博大见长。东北三省应该充分利用这些旅游资源优势,打造强势东北旅游新天地,力争实现东北三省旅游资源的完美开发。
4.大力发展农业
广大农村应因地制宜发展民营企业。政府要保护好农民的正当合法权益,杜绝坑农害农事件的发生,政府还要向农民大力推广科学,引导和鼓励农民科学种田,提高产出。鼓励企业家到农村办企业,既有利于粮食转化,又可吸收农业剩余劳动力。由于农产品就地转化成本较低,农业劳动力又比较廉价,所以有利于投资者降低产品成本,获得较高收益。应出台相应的优惠政策,力度要大,大到足以让有能力的人才有决心到农村办企业。这样可以将城市的剩余资金投向资金短缺的农村,实现城乡经济同步协调发展。
5.大力发展非国有企业
政府机关要千方百计为民营等非国有企业的发展创造良好的环境,要精心呵护,要尽可能地帮助它们解决实际问题,使其做强做大。只有它们做强做大,才能帮助政府解决就业压力过大的问题,吸收大量的剩余劳动力,为国家上缴更多的税收,支持和发展社会各项事业。
参考文献
[1]林毅夫,刘培林.《振兴东北要遵循比较优势战略》.
[2]林木西,刘燕.《“振兴东北”警惕新一轮赶超》.
[3]高广志,王淮志,冯雷.《项目怪圈不破,老工业基础难兴—东北辽吉黑三省部分国企调查》.
[4] 郭明,费威.《东北三省经济发展水平比较分析》.
[5]赵朴森.《东北经济未来发展的战略思考》.
[6]朱建平.《应用多元统计分析(第二版)》.北京:科学出版社,2012.
多元统计分析课程论文 -----我国农村居民收入与支出多元统计分析 班级:统计1203 姓名:李犁 学号:1304120724 2015年7月
目录 1.引言 (3) 1.1研究问题的背景 (3) 1.2研究问题的目的 (3) 2.分析方法的简单介绍 (4) 2.1主成分分析 (4) 2.1.1主成分分析的思想 (4) 2.1.2主成分分析的几何意义 (4) 2.2聚类分析 (5) 2.2.1聚类分析的思想 (5) 2.2.2聚类分析的过程 (5) 3.农村居民收入的多元统计分析 (5) 3.1主成分分析 (5) 3.2聚类分析 (7) 4. 农村居民支出的多元统计分析 (9) 4.1 主成份分析 (9) 4.2聚类分析 (11) 5. 结论 (13)
【摘要】本文主要研究农村居民收入与支出的相关问题,利用spss软件,首先对农村居民收入进行了数据的收集和整理,数据取自中国统计年鉴网络实时数据,利用多元统计分析中的主成分分析,分析影响农村居民收入的几个重要因素。再对其进行聚类分析,按照农村居民不同的收入对30个省、自治区、直辖市进行聚类,分出几个不同的收入等级。然后对农村居民支出情况的数据进行主成分分析,分析影响收入的因素,再对其进行聚类分析,分析不同的支出等级,最后将收入与支出综合分析,大致得出结论,我国实际的居民收入与消费结构还存在一定的不合理。 【关键词】农村居民收入农村居民支出主成分分析聚类分析 1.引言 1.1研究问题的背景 我国是发展中的农业人口大国,农业的基础地位和作用比任何国家都重要,小康目标能否全面实现,重点、难点在提高人民收入,要实现农村稳定,农民小康和农业现代化,前提条件就是要保持农民收入的持续稳定的快速发展。2000年,在国家连续三年扩大内需的宏观政策作用下,我国居民消费保持了稳中有旺的运行态势。但是从城乡消费结构来看,农村消费明显不如城市消费活跃。农村消费之所以增长缓慢,主要是因为农村居民收入停滞不前以及受到农村传统消费观念的主导 1.2研究问题的目的 劳动者报酬收入和家庭主营收入已成为农民收入的主要来源,但是由于我国经济发展的不平衡,各地区的农民收入有着很大不同,另一方面,经济改革使得地区之间、农民内部之间的富裕家庭和贫穷家庭之间的收入差距越来越大。“二元思维”造就了经济发展层面上的“两个中国”-----“城市中国”和“农村中国”,“三农”问题日益突出,“三农”问题的核心是农民问题,即农民利益和平等待遇问题,“三农”是我国的根本问题,建设现代化农业、发展农村经济、增加农民收入,始终是中国政府面临的重大问题如何客观准确的分析这些差异,具有重要的理论和实际意义,因此,本文试图用多元统计分析对我国各地区农民收入来源及消费支出问题进行全面深入的分析。
应用多元统计分析论 文 Revised on November 25, 2020
山东省十一城市综合实力统计分析摘要:本文根据中国城市经济发展研究中心提出的城市综合经济实力和区域的概念,并利用2009年各城市社会经济发展状况的截面数据,就山东省11市的经济数据进行分析。首先建立了评价的指标体系,其次,分别采用主成分分析法和聚类分析法对山东省根据行政区域划分的11个市的综合经济实力进行了全面的评价和比较,并在此基础上提出了促进山东各市经济协调发展、共同进步的相关措施。 关键词:城市经济主成分分析聚类分析 一、引言 在区域经济发展中,城市处于核心和龙头的地位,提高城镇化水平、加快城市化进程是解决当前和未来一系列问题的关键。山东经济发展显示出不平衡的态势,鲁东的少数几个城市GDP几乎占据全省三分之二[1]。很显然,山东省各市的城市化水平也存在显着差异, 青岛、济南等的城市化水平始终走在全省乃至全国前列,泰安和滨州则相对落后。随着黄河三角洲经济一体化进程的加快,山东作为沿海省份必须清楚的看到发展差异并找出差异形成的原因,通过核心城市的优先发展带动区域经济和社会的快速发展,是现实提出的急需解决的问题。 为此,本文在参阅相关文献的基础上,根据中国城市经济发展研究中心提出的城市综合经济实力以及区域的概念,根据区域的行政划分,从山东省11个市出发,利用2009年各城市社会经济发展状况的截面数据,首先建立了评价指标体系,其次,分别采用主成分分析法和聚类分析法对山东省11个市的综合经济实力进行了综合的评价和排位,并在此基础上提出了促进山东省各市经济协调发展、共同进步的相关措施。
一、填空题(20分) 1、若),2,1(),,(~)(n N X p 且相互独立,则样本均值向量X 服从的分布 为 2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。 3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。 4、Q 型聚类是指对_样品_进行聚类,R 型聚类是指对_指标(变量)_进行聚类。 5、设样品),2,1(,),,(' 21n i X X X X ip i i i ,总体),(~ p N X ,对样品进行分类常用的距离 2 ()ij d M )()(1j i j i x x x x ,兰氏距离()ij d L 6、因子分析中因子载荷系数ij a 的统计意义是_第i 个变量与第j 个公因子的相关系数。 7、一元回归的数学模型是: x y 10,多元回归的数学模型是: p p x x x y 22110。 8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。 9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。 二、计算题(60分) 1、设三维随机向量),(~3 N X ,其中 200031014,问1X 与2X 是否独立?),(21 X X 和3X 是否独立?为什么? 解: 因为1),cov(21 X X ,所以1X 与2X 不独立。 把协差矩阵写成分块矩阵 22211211,),(21 X X 的协差矩阵为11 因为12321),),cov(( X X X ,而012 ,所以),(21 X X 和3X 是不相关的,而正态分布不相关与相互
统计学(数据分析方向)专业培养方案 Statistics(Data Analysis Specialty) (门类:理学;二级类:统计学;专业代码:071201) 一、专业培养目标 本专业培养德、智、体、美全面发展,在具备一定的数学、统计学和计算机科学等方面知识的基础上,较全面掌握大数据处理和分析的基本理论、基本方法和基本技术,能够运用所学知识解决实际问题,具备较高的综合业务素质、创新与实践能力,能从事大数据分析、大数据应用开发、大数据系统开发、大数据可视化以及大数据决策等工作,具有较强的专业技能和良好外语运用能力的应用型创新人才,或继续攻读本学科及其相关学科的硕士学位研究生。 二、毕业要求 本专业是一门涉及数学、统计学、计算机科学等多领域的交叉学科。学生主要学习数学、统计学、计算机科学的基本理论和基本知识,打好坚实的数学基础,受到系统而扎实的计算机编程训练,具备较强的数据分析和信息处理能力,能在大数据科学与工程技术领域从事数据分析管理、系统设计开发、大数据处理应用、科学研究等方面的工作,具备综合运用所学知识分析和解决实际问题的能力。 本专业学生培养分为两个主要阶段,第一阶段着重于数据科学理论体系的培养,即发展和完善数据科学理论体系,为数据科学人才培养提供必要的理论和知识基础;第二阶段重视实践能力的培养,即在夯实数据科学理论的基础上,重视培养学生利用大数据的方法解决具体行业应用问题的能力。 本专业毕业生在知识、能力和素质方面的具体要求: 1.具有正确的世界观、人生观和价值观;具有良好的道德品质、高度的社会责任感与职业道德;具有良好的人文社会科学素养。 2.具有良好的人际交往能力和团队协作精神;有较强的自学能力和适应能力。 3.具有良好的数学、统计学和计算机科学基础,掌握数据科学与大数据技术、统计学和计算机科学的基本知识、方法和技能。 4.具备熟练应用计算机( 包括常用语言、工具及专用软件) 的基本技能, 具有较强
HUNAN UNIVERSITY 课程论文 论文题目:有关我国居民消费因素的分析指导老师: 学生名字: 学生学号: 专业班级:经济统计 学院名称: xxx学院
目录 概述 (1) 一、引言 (2) 二、数据概述系 (2) 三、分析方法 (3) 四、数据分析 (3) (一)相关分析 (3) (二)因子分析 (10) (三)聚类分析 (15) 五、分析与建议 (18) 六、心得体会 (19) 参考文献 (20)
有关我国居民消费因素的分析 概述 生活离不开消费,随着社会发展,生活水平提高,消费也在逐渐变化,并且随着经济发展,各个地区的发展水平的差异,消费也产生了不同的变化,此篇论文主要目的是利用多元统计的方法,借助spss软件,对我国31个地区的居民消费情况进行分析。了解我国31个地区的居民消费情况与统计指标食品烟酒、衣着、居住等8个指标之间的一些联系。并且通过因子得分,计算并排列出消费因素的综合得分,最后通过聚类分析,对我国31个地区的居民消费情况做一个大致分类,进而对各个地区分类后的情况做一个分析和总结并结合文献以及资料提出一些意见和看法。
一.引言 消费在宏观经济学中,指某时期一人或一国用于消费品的总支出。与经济活动有着密不可分的关系,消费作为社会再生产的最终阶段,是生产者生产产品的目的和导向。如果没有了消费,生产的存在也会变得毫无意义,消费促进了生产,给生产带来了源动力。消费者的消费需求,也推动了生产的发展。并且消费促进了货币流通,提供了就业岗位,降低失业率,拉动了经济增长,最终有助于提高人民的生活水平。消费是国民经济保持增长的动力,只有拉动消费需求的增长,才能促进投资,促进产业结构的调整、宏观经济的增长,满足人民的物质生活的需求,实现生活水平的提高。 故消费和生活水平有着密切的关系,从而,通过对我国居民消费水平的分析,不但可以直观了解到我国总的消费趋向,各地区不同的消费主导因素,还能客观反映我国总的生活水平也就是经济发展的大致情况。统计年鉴中的八项指标:食品烟酒、衣着、居住、生活用及服务、交通通信、教育文化娱乐、医疗保健、其他用品及服务。囊括了居民消费的全部项目,居民日常消费可以清楚地从数据中了解到。再通过分析和整合,最终可以大致分析我国总体的消费倾向以及各个地区的异同点。再结合文献资料了解分析产生异同的原因,进而对我国的总体消费水平做一个最终概括。 二.数据概述 数据来源:2015年《中国统计年鉴》 指标:
22121212121 ~(,),(,),(,),, 1X N X x x x x x x ρμμμμσρ ?? ∑==∑= ??? +-1、设其中则Cov(,)=____. 10 31 2~(,),1,,10,()()_________i i i i X N i W X X μμμ=' ∑=--∑L 、设则=服从。 ()1 2 34 433,4 92, 3216___________________ X x x x R -?? ?'==-- ? ?-? ? =∑、设随机向量且协方差矩阵则它的相关矩阵 4、 __________, __________, ________________。 215,1,,16(,),(,)15[4()][4()]~___________i p p X i N X A N T X A X μμμμ-=∑∑'=--L 、设是来自多元正态总体和分别为正态总体的样本均值和样本离差矩阵,则。 12332313116421(,,)~(,),(1,0,2),441, 2142X x x x N x x x x x μμ-?? ?'=∑=-∑=-- ? ?-?? -?? + ??? 、设其中试判断与是否独立? (), 1 2 3设X=x x x 的相关系数矩阵通过因子分析分解为 211X h = 的共性方差111X σ= 的方差21X g = 1公因子f 对的贡献1213 30.93400.1280.9340.4170.8351100.4170.8940.02700.8940.44730.8350.4470.10320 13 R ? ? - ????? ? -?? ? ? ?=-=-+ ? ? ? ??? ? ? ????? ? ???
四川理工学院 《多元统计分析课程设计》报告 题目: 中国国有控股工业行业的经济效益评价 学生:雷鹏程何君李西京 曾学成白俊明 专业:统计学 指导教师:柏宏斌 四川理工学院理学院 二零一四年十二月 中国国有控股工业行业的经济效益评价 摘要 本文主要研究了中国国有控股工业行业的经济效益,对反映行业经济效益的总资产贡献率、资产负债率、流动资产周转次数、工业成本费用利润率和产品销售率等五个经济指标进行主成分分析,提取反映行业盈利能力和市场能力的两个综合指标。然后通过因子分析法分析反映经济效益的各指标的内部结构,表明行业经济效益主要由盈利能力和市场能力两个公因子决定。根据各行业在盈利能力上的得分和市场能力上的得分将工业行业分为五类,并对各行业经济效益进行综合评价。然后用聚类分析对综合评价结果进行验证,表明综合评价较为客观合理。最后,本文给出相应的政策建议。 关键字:主成分分析、因子分析、聚类分析。 一、引言 改革开放以来,工业始终是我国经济发展的主要支柱。作为社会主义国家,我国国有及国有控股工业行业掌控着国家工业发展命脉,对国民经济、社会协调发展具有巨大推动作用。因此,考核工业行业的经济效益,对挖掘重点行业和弱势行业,提高整个国有工业企业的经济效益等具有重大的现实意义。企业或行业的经济效益由众多因素来刻
画,目前反映行业经济效益主要有总资产贡献率、资产负债率、流动资产周转次数、工业成本费用利润率和产品销售率等五个经济指标1。这些众多指标虽然能从多方面对行业的经济效益进行全面考察,但也在一定程度增加了分析问题的复杂性。在损失少量信息的前提下,设计一个或少数几个综合指标,并用较少的综合指标对工业经济效益进行分析评价,能够简化问题。此外,挖掘出反映经济效益的众多指标的内在基本结构,有助于指出各行业经济效益的主要决定因素及瓶颈,也有助于对各行业经济效益进行综合评价。 二、文献综述 大量国内文献从灰色系统理论、多元统计分析方法、层次分析法、模糊综合评判法、 数据包络分析法等理论与方法,考察了中国各行业、企业或地区经济效益的研究与综合评价。华中生、梁梁等用模糊聚类方法与数据包络分析分类法考察了合肥工业行业的经济状况,将各工业行业按经济效益的状况分为高、较高、一般、较差和差等五类[1](华中生、梁梁,1995)。王树岭等人利用TOPSIS 模型,对吉林省轻工业17个主要行业的经济效益进行了综合评价与排序,确定出相应的优势行业(王树岭等,1999)。本文以2008年国有及国有控股的主要工业行业为研究对象,通过主成分分析和因子分析法,再次对各工业行业的经济效益进行分析与评价,并结合聚类分析法来验证综合评价的结果。 三、数据来源 反映经济效益的指标较多,不同文献中选取的指标不尽相同。本文采用国家统计局最新公布的五个指标:总资产贡献率、资产负债率、流动资产周转次数、工业成本费用利润率和产品销售率,分别记为1X 至5X 。总资产贡献率(1X )反映企业全部资产的获利能力。资产负债率(2X )既反映企业经营风险的大小,也反映企业利用债权人提供的资金从事经营活动的能力。流动资产周转次数(3X )反映投入工业企业流动资金的周转速度。成本费用利润率(4X )反映企业投入的生产成本及费用的经济效益。产品销售率(5X )反映工业产品已实现销售的程度。选取39个主要工业行业的数据整理如附录表1所示。 四、模型基本理论建立 主成分分析的基本理论 设对某一事物的研究涉及p 个指标,分别用1X ,2X ,…, P X 表示,这p 个指标构成的p 维随机向量为),,(21'=P X X X X Λ。设随机向量X 的均值为μ,协方差矩阵为∑。 对X 进行线性变换,可以形成新的综合变量,用Y 表示,也就是说,新的综合向量 1 《国家统计年鉴2009年》用这五大指标来反映工业行业的经济效益。
基于主成分分析的我国地区经济指标研究 09统计班徐晓旺 【摘要】 地区经济的发展对我国现代化进程形成巨大的推动作用,而经济指标是评判地区发展水平的重要标志。根据搜集的相应数据建立数据库,基于主成分分析、同时运用聚类分析以及判别分析的多元统计方法,对全国各地区的经济状况进行综合指标分析。研究各省经济发展在全国的分布特征、筛选出具备可对比性的指标,进而探究造成差异的原因,同时具有针对性地提出相关建议。 【关键词】 主成分分析;聚类分析;判别分析;地区经济指标 一、引言 随着社会的不断进步,经济发展的车轮将会继续滚动。在整体水平提升的同时不难发现:我国各地区间发展势必存留着一定的差距,了解其具体的分布特征注定会是一个非常值得深入挖掘的信息。结合对进出口总额、居民消费水平等9个经济指标的研究,致力于分析各地区硬件发展水平、人民生活状况的异同与经济发展的相关性。 本文将对中国31个省份地区的经济指标进行分析。首先,应用主成分分析的方法对众多指标做降维处理并赋予各主成分以实际意义以获取综合性指标;进而,基于主成分分析结果通过聚类分析法把我国的31个地区分类;最后,根据聚类的结果建立判别函数同时运用判别分析将新疆、广东两个省份归类。 二、主成分分析 搜集到的经济指标为:进出口总额、地区生产总值、固定资产投资、邮电业务量、客运量、货运量、公交车运营数、居民平均工资和居民消费水平这九项指标。 在运用SPSS软件对以上数据开始分析前首先进行标准化处理,接着通过SPSS的操作,得到了如下的总方差分解结果(见表一): 表一
由表一中结果可以看到保留2个主成分为宜,这2个主成分集中了原始9个变量信息的88.392%,可见效果比较好,这样原来的9个指标就可以通过这2个综合指标来反映。此时,这2个主成分就起到了降维的作用。通过SPSS进一步的操作还可以得到如下的主成分系数矩阵(见表二): 表二 由表二可以得出前2个主成分的线性组合为: Y1 = 0.852 X1 + 0.979 X2 + 0.821 X3 + 0.957 X4 + 0.885 X5 + 0.742 X6 + 0.967 X7 + 0.226 X8 + 0.513 X9 Y2 = 0.393 X1 - 0.113 X2 - 0.419 X3 - 0.032 X4 - 0.233 X5 - 0.483 X6 + 0.109 X7 + 0.915 X8 + 0.786 X9 通过对上述线性组合的观察,我们可以得出:在主成分1中进出口总额、地区生产总值、固定资产投资、邮电业务量、客运量、货运量和公交车运营数这几项指标的系数明显比主成分2的系数大,可以将Y1归类为地区经济发展中的硬件基础指标;在主成分2中平均工资和消费水平指标的系数最大,可以将Y2归类为地区经济发展中的居民生活指标。 这样就将繁冗的9个指标归结为上述2个,这两项指标相互作用,共同反映地区经济发展情况。 主成分得分如下(见表三): 表三
统计与数学学院经济统计学专业本科培养方案 一、培养目标 本专业方向培养具有良好的数学与经济学素养,系统掌握统计学的基本理论和现代统计方法以及现代市场经济理论,能熟练地运用计算机进行数据分析与开发,能在政府机关、调查机构、金融、保险等部门独立从事统计实践、管理策划、数据挖掘和经济金融数量分析的高素质应用型人才。 二、培养要求 本专业方向学生主要学习社会经济统计的基本理论和方法,具有较好的数学基础及较好的经济学素养,系统接受理论研究、应用技能及计算机能力的基本训练,具有数据处理和经济计量分析的基本能力。 毕业生应获得以下方面的知识和能力: 1.扎实的数学基础,严格的科学思维方式; 2.设计调查问卷、采集数据、处理数据的基本能力; 3.具有应用统计学理论分析、解决实际问题的初步能力; 4.了解统计学理论与方法的发展动态及其应用前景; 5.熟悉国家经济发展的方针、政策和统计法律、法规,具有利用信息资料进行综合分析和管理的能力; 6.掌握资料查询、文献检索及运用现代信息技术获取相关信息的基本方法;具有一定的科学研究和实际工作能力。 三、主干学科:数学、统计学、经济学、管理学 四、学分要求 课程类别课程 性质 最低 毕业 学分数 各学期最低学分 合计 1 2 3 4 5 6 7 8 通识教育模块 通识教育基础课1必修65 22 14 14 10 1 1 1 65 通识教育主干课2必选8 √√√8 学科基础课必修29 5 7 10 7 29 专业课 专业主干课必修15 3 3 9 15 专业方向课必修14 3 6 3 2 14 专业任选课3任选8 8 专业拓展课 (全校性选修课)4 任选8 √√√√√√√8 实践体验与创新课5必修20 1 1 2 4 9 20 累计167 22 20 22 26 17 15 7 9 167 注:1.通识教育基础课中的形势与政策学分没有统计到各学期最低学分中; 2.通识教育主干课开课学期为2—4学期,由学生自由选课,学分没有统计到各学期最低学分中; 3.专业任选课学分没有统计到各学期最低学分中; 4.专业拓展课由学生自由选课,学分没有统计到各学期最低学分中; 5.实践体验与创新课中的军训(1学分)和创业与实践(2学分)学分没有统计到各学期最低学分中。
因子分析和聚类分析在全国省会城市经济 实力分析中的应用 摘要:本文利用SPSS中的因子分析和聚类分析功能对全国26个省会城市经济实力进行分析。先用因子分析,再对因子分析的结果进行聚类分析。本文选取2012年上半年26个省会城市的9个经济指标,通过因子分析提取两个因子计算出26个省会城市的综合得分函数,再根据因子分析得出的得分函数对这些城市进行聚类分析,分类结果为: 然后再对分类后的城市进行分析说明,最后针对分类的结果进而得出经济综合实力的结论。 关键词:因子分析聚类分析 SPSS 经济实力
一、引言 城市的发展是经济发展和社会进步的重要标志。目前,我国正处于加快推进现代化的历史阶段。现代城市既要有发达的经济,也要有发达的文明。文明城市是指在全面建设小康社会、推进社会主义现代化建设新的发展阶段,物质文明、政治文明与精神文明协调发展,经济和社会事业全面进步,精神文明建设取得显著成就,市民整体素质和城市文明程度较高的城市。文明城市,是反映一个地区现代文明程度、城市综合竞争实力的重要标志。创建文明城市对经济社会发展所产生的现实意义和深远影响,已经远远超出了原来一般意义上的群众性精神文明建设活动。我们要从战略高度来看待创建文明城市的重要意义,提高对创建文明城市重要性的认识。 随着改革开放的脚步,全国各地经济都有着飞速的发展,人们越来越关注各个省会城市经济实力。经济是衡量一个地区综合实力的重要指标,而依照经济实力对城市进行分类可以看出一个地区综合实力以及发展潜力,利用经济分类,我们也可以得出该地区的发展状况,以及在哪些方面做得不够,哪些方面可以得到改进。基于以上原因,本文运用SPSS 对全国26个省会城市,合肥, 武汉, 长沙, 郑州, 南昌, 太原, 西安, 福州, 石家庄, 沈阳, 哈尔滨, 长春, 南京, 杭州, 济南, 南宁, 成都, 贵阳, 昆明, 兰州, 西宁, 银川, 海口, 广州, 乌鲁木齐, 呼和浩特2012年上半年的9类经济指标进行因子分析,聚类分析。根据这两种分析的结果,对该26个省会城市进行2012上半年的经济分类。这样能让广大人们群众更清楚的认识此26个省会城市的经济状况,上级部门也可以通过这些分类对这26个地区下达给类发展命令,让这26个城市在经济上能更进一步。 选取的这九个经济指标是地区生产总值(X1),社会消费品零售总额(X2),规模以上工业增加值(x3),出口总额(x4),固定资产投资(x5),人民币储蓄存款余额(x6),地方财政收入(x7),农民人均现金收入(x8),城镇居民人均收入(x9)。 二、模型假设 1、假设经济指标数据真实、准确; 2、假设选取的经济指标能基本上全面反映城市的经济信息; 3、假设各个经济指标信息之间存在重叠; 4、假设特殊因子),0(~2σεN 。
应用多元统计分析毕业论文已过查重-优秀毕业论文
内蒙古财经大学 应用多元统计分析 期末论文 作者李慧斌 系别统计与数学学院 专业信息与计算科学 年级2012级 学号122093118 指导教师刘勇 导师职称讲师
目录 我国地区经济发展浅析 (2) 摘要 (2) 一、引言 (2) 二、聚类分析 (2) 1.参与聚类的样本总量表 (3) 2.样品聚为3类时的样品归类表 (3) 3.所有样品的聚类树形图 (5) 三、主成分分析 (6) 1.单变量描述统计量表 (6) 2.各变量相关矩阵图 (7) 3.总方差分解图 (8) 4.旋转前的因子载荷矩阵图 (9) 5.利用因子载荷矩阵图计算出的特征向量表 (9) 三、因子分析 (10) 1.旋转后的因子载荷矩阵 (10) 2.因子得分系数矩阵 (11) 3.各样品因子得分 (11) 四、结论 (13) 附表一 (14)
我国地区经济发展浅析 摘要:以聚类分析法、主成分分析法、因子分析法三种多元统计分析方法为主,对2011年我国31个省、市、自治区的地区经济发展状况以及影响地区经济发展的主要因素(指标)相结合进行剖析。根据不同分类方法得出不同的分析结果,从不同角度分析我国各地区经济发展存在的主要差异以及导致这些差异出现的原因,并最终就三种统计分析方法的结果对我国目前地区经济发展状况进行客观的综合概述。 关键字:地区发展水平聚类分析法主成分分析法因子分析法 一、引言 在日常生活过程中,我们常常遇到一些计算量大,分析工作复杂度高的数 据分析工作,为了能够更加简便地进行数据分析,在此给大家介绍几种多元统 计分析的方法。本文主要运用了聚类分析法,主成分分析法和因子分析法对2011 年我国31个省市自治区地区经济发展水平以及影响地区经济发展的几项重要指 标进行了统计分析。 二、聚类分析 聚类分析是应用最广泛的一种分类技术,它把性质相近的个体归为一类,使得同一类中的个体具有高度的同质性,不同类之间的个体具有高度的异质性。聚类分析的职能是建立一种分类方法,它是将一批样品或变量,按照它们在性质上的相似程度进行分类。通常我们用距离来度量样品之间的相似程度,用相似系数来度量变量之间的相似程度。
多元统计分析实践论文 院系:理学院 专业:统计学 年级:2010 姓名:樊恩泽 学号:20101004005
我国城镇居民人均消费支出的多元统计分析 樊恩泽 摘要:本文本文综合了主成分因子分析与系统聚类分析,先进行主成分因子分析, 再用进行聚类分析。采用2011年我国31个省、市、自治区城镇居民人均消费支出数据,首先利用主成分因子分析的方法, 找出影响我国城镇居民人均消费支出的主成分, 计算各样本的主成分得分;其次运用系统聚类分析法,对各地区人均消费水平进行分类,结果表明,系统聚类分析法得到的结果也较好;最后对于扩大国内消费提出相关建议。 关键词:主成分分析聚类分析居民人均消费支出 1、引言 人均消费支出指居民用于满足家庭日常生活消费的全部支出,包括购买实物支出和服务性消费支出。消费支出按商品和服务的用途可分为食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住、杂项商品和服务等八大类。人均消费支出是社会消费需求的主体,是拉动经济增长的直接因素,是体现居民生活水平和质量的重要指标。 本文选取2011年我国城镇居民人均消费支出数据,主要利用三种统计方法进行分析:主成分分析法、聚类分析法。将全国31个省、市、自治区进行分类和排序,并与人们实际观察到的情况进行比较。 1.1主成分分析 主成分分析是将分量相关的原始变量, 借助于一个正交变换转化为不相关的新变量, 并以方差作为信息量的测度, 对新变量进行降维, 取累计贡献率大的若干成分作为主成分。这些主成分能够反映原始变量的绝大部分信息, 它们通常表示为原始变量的某种线性组合。
1.2聚类分析 聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类的分析技术。 在市场研究领域,聚类分析主要应用方面是帮助我们寻找目标消费群体,运用这项研究技术,我们可以划分出产品的细分市场,并且可以描述出各细分市场的人群特征,以便于客户可以有针对性的对目标消费群体施加影响,合理地开展工作 2、数据来源及处理 2.1统计思想 主成分因子分析的基本思想是通过对变量相关系数矩阵内部结构的研究,找出能控制所以变量的少数几个随机变量去描述多个变量之间的相关关系,并依据相关性的大小将变量分组,使得同组内的变量之间相关性较高,不同组的变量相关性较低。每组代表一个基本结构,这个基本结构成为公共因子。对于所研究的问题试图用最小个数的不可观测的所谓公共因子的线性函数与特殊因子之和来描述原来可观测的每一个变量。 下表是要进行处理的31个省市的城镇居民人均消费支出的相关原始数据,数据来源于《2011中国统计年鉴》。 X1:食品x2:衣着x3:居住x4:家庭用品x5:交通通信x6:文教娱乐x7:医疗保健 表1
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: )',...,,(),,,(2121P p EX EX EX EX μμμ='=Λ)')((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ
2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的),(~∑μP N X μ∑μp X X X ,,,21Λ),(~∑μP N X ) ,('A A d A N s ∑+μ)()1(,, n X X ΛX )',,,(21p X X X Λ)')(()()(1X X X X i i n i --∑=n 1X μ∑μX )1,(~∑n N X P μ),1(∑-n W p X X
U 浙江财经学院东方学院《多元统计分析》课程论文 论文题目:2011年我国农村居民生活消费分析 学生姓名徐妙学期2013年第二学期分院信息专业统计 班级10统计1班学号1020430112 教师彭武珍成绩 2013年6月17日
2011年我国农村居民生活消费分析 摘要:改革开放以来,我国广大地区农村居民生活水平普遍有所提高,价值观念也发生了许多变化,但是,他们的消费水平与城镇居民相比仍然偏低。本文综合了因子分析与聚类分析,先进行因子分析, 再用因子分析的结果进行聚类分析,本文较多运用了31个省份的因子得分,计算出单因子情况下31个省份的得分和31个省份在八项消费产生的3个因子上的综合得分, 再把该得分作为31个省份的属性, 采用离差平方和(ward)方法进行聚类, 最后将城市分为四层,对整体进行综合评价和说明。 关键词:因子分析;聚类分析;综合评价 1引言 当前我国农村居民的消费结构主要是偏重物质生活消费,精神生活消费的比例较低。商品消费主要集中于食品、居住以及日常生活物质消费等方面。而交通通讯、文教娱乐用品及服务等精神生活消费品消费比例较小。旅游休闲、家用汽车、耐用消费品等消费在绝大多数农村地区还处于未开发状态。因此,笔者就我国农村居民生活消费结构进行因子分析和聚类分析,以期对农村居民生活消费的问题作一研究,并以此寻求合理的解决思路。 2因子分析 2.1因子分析统计思想 因子分析模型是主成分分析的推广。它也是利用降维德思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。其基本思想是根据相关性大小把原始变量分组,使得同组内的变量间相关性较高,而不同组的变量的相关性则较低。因子分析不仅可以用来研究变量之间的相关关系,还可以用来研究样品之间的相关关系。 2.2因子的确定
多元统计分析论文标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]
关于各地区固定资产投资价格指数的分析 摘要:本文主要通过主成分分析、聚类分析和判别分析对全国30多个省的固定资产投资指数、建筑安装工程指数、设备工器具购置指数、其他费用指数进行分析。 关键词:主成分分析、欧氏距离、系统聚类分析、判别分析 Summary:This article mainly through the principal components analysis, the cluster analysis and the distinction analysis to the national more than 30 province investment in the fixed assets indices, construction and installation the project index, the equipment labor appliance purchase index, other expense index carries on the analysis. Keywords:Principal Components Analysis、Euclidean distance、Discriminant analysis 一、导言: 注意微量信息引起的巨变,蝴蝶效应就是微量信息在一定条件下发生作用的过程。在我们的经济活动中,每天的信息是大量的,这就要求我们从中发现那些对经济能产生最大影响的信息,有些是微量信息,有些是次级别的信息,本文的各地区固定资产投资价格指数就是一个非常值得深入发觉的信息。该指数可以准确地反映固定资产投资中涉及的各类投资品和取费项目价格变动趋势和变动幅度,消除按现价计算的固定资产投资指标中的价格变动因素,真实地反映固定资产投资的规模、速度、结构和效益,为国家科学地制定、检查固定资产投资计划并提高宏观调控水平,为完善国民经济核算体系提供科学的、可靠的依据。
盛年不重来,一日难再晨。及时宜自勉,岁月不待人。 信 息 统 计 论 文 论题:分地区农村居民消费支出 姓名:吴文洁 学号:A01214035 专业:12信息与计算科学
分地区农村居民消费支出 —SAS和MATLAB的相关应用摘要:近年来,各类真人秀节目纷纷到农村取景,这让我们了解到农村的现状。关于拉近城乡距离,首先要从经济方面着手。农村居民消费十分准确的反映了这一经济状况。消费、投资和净出口被誉为拉动经济增长的“三驾马车”,在这三驾马车中,消费的作用是最主要的,因为无论是发达国家还是发展中国家,消费在一国的国内生产总值中所占的份额均最大。已有研究表明,中国居民消费率大大低于国际水平,其主因是中国农村消费市场疲软。因此,扩大内需其实重点是要扩大农村居民消费需求。特别是在全球金融危机仍然蔓延的时候,提高农村居民的消费需求显得尤为重要。利用SAS软件对我国各分地区农村居民消费情况进行分析,进一步了解消费情况,做出重要的决策。 关键字:消费支出聚类分析 正文: 扩大国内需求,最大潜力在农村;实现经济平稳较快发展,基础支撑在农业;保障和改善民生,重点难点在农民。扩大消费尤其是扩大居民消费,无疑是中国。经济在今后相当长时期内最重要的命题之一。在中国,居民消费占GDP的比重低且不断降低,一个非常重要的原因就在于占总人口50%以上的农村居民消费严重滞后。如果农村居民消费能伴随农民收入增长而快速增长,消费占GDP的比重将稳步提升,国民经济发展必将具备更坚实的微观基础。因此有必要对各地农村居民的综合消费水平做个评价,以其为今后的经济发展提供参考。 各个地区的农村居民的消费指标主要是衣食住行支出、家庭设备及用品支出、交通通信、文教娱乐、医疗保健和其他支出等。本文通过利用SAS软件对我国31个省市消费指标进行了分析,提出了各地区的差异及相关的评价。全国31个省、自治区、直辖市附近的农村居民各消费支出作为样本,设x1为食品支出,x2为衣着支出、x3为居住支出、x4为家庭设备及用品支出、x5为交通通信支出、x6为文教娱乐支出、x7为医疗保健支出、x8为其他商品支出。相关数据来源于中国统计年鉴(2013),该表格见附件1.xls。
第一章: 多元统计分析研究的容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X均值向量: 随机向量X与Y的协方差矩阵: 当X=Y时Cov(X,Y)=D(X);当Cov(X,Y)=0 ,称X,Y不相关。 随机向量X与Y的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X,Y为随机向量,A,B 为常数矩阵 E(AX)=AE(X); E(AXB)=AE(X)B; D(AX)=AD(X)A’; )' ,..., , ( ) , , , ( 2 1 2 1P p EX EX EX EXμ μ μ = ' = )' )( ( ) , cov(EY Y EX X E Y X- - = q p ij r Y X ? =) ( ) , (ρ
Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变量之间的比较。 4、对数变换:对数变换是将各个原始数据取对数,将原始数据的对数值作为变换后的新值。它将具有指数特征的数据结构变换为线性数据结构。 三、样品间相近性的度量 研究样品或变量的亲疏程度的数量指标有两种:距离,它是将每一个样品看作p 维空),(~∑μP N X μ∑μp X X X ,,,21 ),(~∑μP N X ),('A A d A N s ∑+μ)()1(,,n X X X )',,,(21p X X X )')(()()(1X X X X i i n i --∑=n 1X μ ∑μX )1,(~∑n N X P μ),1(∑-n W p X X