时间序列分析预测EXCEL操作
一、长期趋势(T)的测定预测方法
线性趋势→:: 用回归法
非线性趋势中的“指数曲线”:用指数函数LOGEST、增长函数GROWTH(针对指数曲线)
多阶曲线(多项式):用回归法
(一)回归模型法-------长期趋势(线性或非线性)模型法:
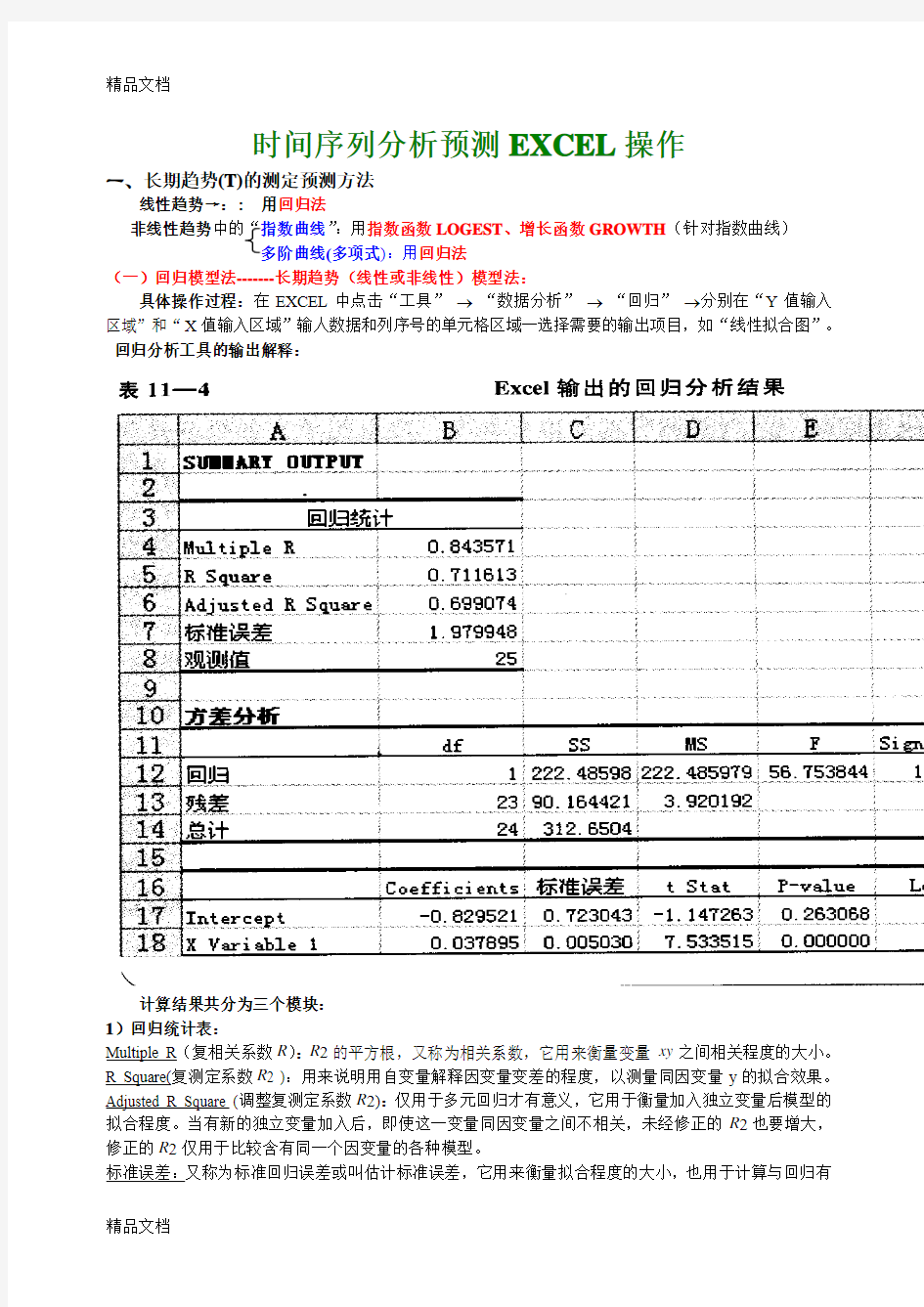
具体操作过程:在EXCEL中点击“工具”→“数据分析”→“回归”→分别在“Y值输入区域”和“X值输入区域”输人数据和列序号的单元格区域一选择需要的输出项目,如“线性拟合图”。回归分析工具的输出解释:
计算结果共分为三个模块:
1)回归统计表:
Multiple R(复相关系数R):R2的平方根,又称为相关系数,它用来衡量变量xy之间相关程度的大小。R Square(复测定系数R2 ):用来说明用自变量解释因变量变差的程度,以测量同因变量y的拟合效果。Adjusted R Square (调整复测定系数R2):仅用于多元回归才有意义,它用于衡量加入独立变量后模型的拟合程度。当有新的独立变量加入后,即使这一变量同因变量之间不相关,未经修正的R2也要增大,修正的R2仅用于比较含有同一个因变量的各种模型。
标准误差:又称为标准回归误差或叫估计标准误差,它用来衡量拟合程度的大小,也用于计算与回归有
关的其他统计量,此值越小,说明拟合程度越好。
2)方差分析表:方差分析表的主要作用是通过F检验来判断回归模型的回归效果。
3)回归参数:回归参数表是表中最后一个部分:
?Intercept:截距a
?第二、三行:a (截距) 和b (斜率)的各项指标。
?第二列:回归系数a (截距)和b (斜率)的值。
?第三列:回归系数的标准误差
?第四列:根据原假设Ho:a=b=0计算的样本统计量t的值。
第五列:各个回归系数的p值(双侧)
第六列:a和b 95%的置信区间的上下限。
(二)使用指数函数LOGEST和增长函数GROWTH进行非线性预测
在Excel中,有一个专用于指数曲线回归分析的LOGEST函数,其线性化的全部计算过程都是自动完成的。如果因变量随自变量的增加而相应增加,且增加的幅度逐渐加大;或者因变量随自变量的增加而相应减少,且减少的幅度逐渐缩小,就可以断定其为指数曲线类型。
具体操作过程:
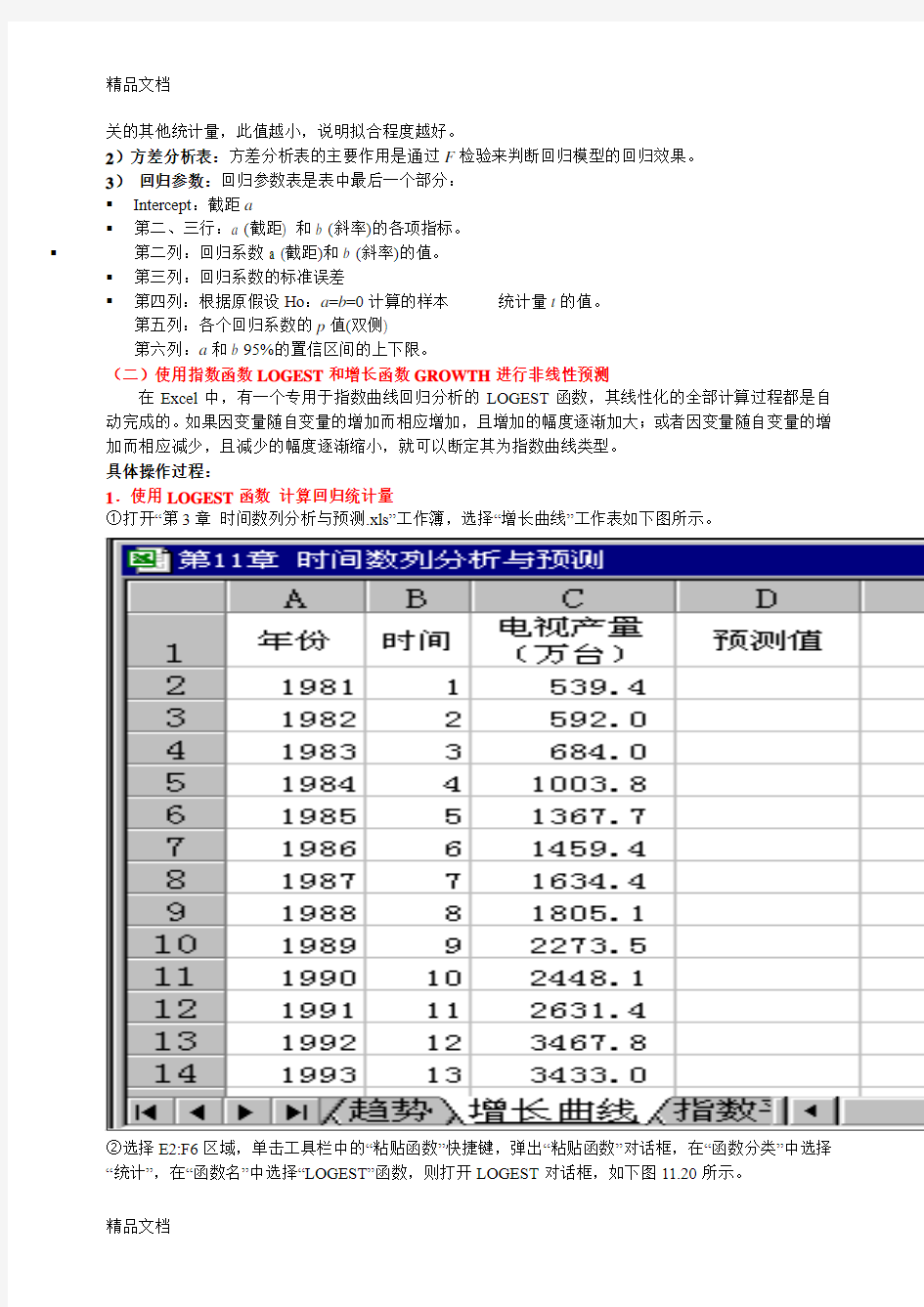
1.使用LOGEST函数计算回归统计量
①打开“第3章时间数列分析与预测.xls”工作簿,选择“增长曲线”工作表如下图所示。
②选择E2:F6区域,单击工具栏中的“粘贴函数”快捷键,弹出“粘贴函数”对话框,在“函数分类”中选择
“统计”,在“函数名”中选择“LOGEST”函数,则打开LOGEST对话框,如下图11.20所示。
③在Known_y’s、Known_x’s和Stats后分别输入C2:C16、B2:B16和1。按住Ctrl+Shift组合键,再按回车键或“确定”按钮,得到计算结果如下图中E2:F6单元格所示。
函数输出结果
x
④根据单元格E2,F2中的计算结果可以写出如下估计方程:
⑤可以根据上面的指数曲线方程计算预测值:在D2单元格中输入公式“=$F$2*$E$2^B2” ,将D2单元格中的公式复制到D3:D20元格,各年的预测值便一目了然了。但使用增长函数可以直接得到预测结果。
2. 使用增长函数GROWTH计算预测值
①选择D2:D20单元格,在工具栏单击“粘贴函数”快捷键,弹出“粘贴函数”对话框,在“函数分类”中选择“统计”,在“函数名”中选择“GROWTH”函数,打开GROWTH对话框,如下图所示。
②在Known_y’s、Known_x’s、New_x’s和Const后分别输入C2:C16、B2:B16、B2:B20和1。按住Ctrl+Shift 组合键,同时按回车键或“确定”按钮,计算结果如下图所示。
3. 绘制实际值与预测值的折线图
季节变动的测定与预测分析
季节变动的趋势—循环剔除法
长期趋势剔除法是在移动平均法的基础上,以乘法模型(Y=T×S×C×I )为理论基础的
测定季节变动的方法,它能避免长期趋势与周期波动的影响,净化季节变动的规律性,从而实现较为准确的预测。
Excel操作过程:
①打开“第3章时间数列分析与预测.XLS”工作簿,选择“长期趋势剔除”工作表,如下图所示。
②在单元格E1中,点击“工具”菜单中选择“数据分析”选项,打开“移动平均”对话框,对D列“销售额”进行4项移动平均。
③在单元格F3中,点击“工具”菜单中选择“数据分析”选项,打开“移动平均”对话框,对E列进行2项移动平均。
④把单元格E4:F4中的公式复制到E19:F19,调整其小数部分使显示1位小数,结果如下图所示。
⑤在单元格G4中输入公式“=D4/F4”,并把它复制到G5:G19。
⑥在单元格H2中输入公式“=A VERAGE(H6,H10,H14,H18)”, 并把它复制到单元格H3中。
分别计算第一、第二季度的季节比率。
⑦在单元格H4中输入公式“=A VERAGE(H4,H8,H12,H16)”,并把它复制到单元格H5中。
分别计算第三、第四季度的季节比率。
时间序列分析作业 1、数据收集 通过长江证券金长江网上交易软件收集中信证券(600030)股价数据(2010-7-1~2011-5-9,共200组),保存文件,命名为“股价数据”。 2、工作表建立 打开eviews,点击file下拉菜单中的new项选择workfile项,弹出窗口如下: (1)、在datespecification中选择integer date。 (2)、在start和end中分别输入“1”“200” (3)、在wf项后面的框中输入工作表名称hr,点击ok。 窗口如下: 3、数据导入 在hr工作文件的菜单选项中选择pro,在弹出的下拉菜单中选择import,然后再下拉二级菜单中选择read text-lotus-excell,找到数据,双击弹出如下对话框:
默认date order,选择右边upper-left data cell下面的空格填写,输入excel中第一个有效数据单元格地址B6,在names for series or number if named in file 中输入序列名称,不妨设为s,点击ok,导入数据。 4、平稳性检验 点击s序列,选择菜单view/correlogram,弹出correlogram specification对话框,如下图,在对话框中默认level,lags to include 改为20(200/10),可得下图:
序列的自相关系数没有很快的趋近0,说明原序列是非平稳的序列。 5、对原序列做对数差分处理 A、在主窗口输入smpl 2 200,对样本数据进行选取, B、在主命令窗口输入series is=log(s)-log(s(-1)) 可以得到新的序列is 对is序列做同上的平稳性检验可以得到如下图:
利用Excel 进行时间序列的谱分析(I ) 在频域分析中,功率谱是揭示时间序列周期特性的最为有力的工具之一。下面列举几个例子,分别从不同的角度识别时间序列的周期。 1 时间序列的周期图 【例1】某水文观测站测得一条河流从1979年6月到1980年5月共计12月份的断面平均流量。试判断该河流的径流量变化是否具有周期性,周期长度大约为多少? 分析:假定将时间序列x t 展开为Fourier 级数,则可表示为 ∑=++=k i t i i i i t t f b t f a x 1 )2sin 2cos (εππ (1) 式中f i 为频率,t 为时间序号,k 为周期分量的个数即主周期(基波)及其谐波的个数,εt 为标准误差(白噪声序列)。当频率f i 给定时,式(1)可以视为多元线性回归模型,可以证明,待定系数a i 、b i 的最小二乘估计为 ∑∑====N t i t i N t i t i t f x N b t f x N a 1 12sin 2?2cos 2?ππ (2) 这里N 为观测值的个数。定义时间序列的周期图为 )(2 )(22 i i i b a N f I += ,k i ,,2,1 = (3) 式中I (f i )为频率f i 处的强度。以f i 为横轴,以I (f i )为纵轴,绘制时间序列的周期图,可以在最大值处找到时间序列的周期。对于本例,N =12,t =1,2,…,N ,f i =i /N ,下面借助Excel ,利用上述公式,计算有关参数并分析时间序列的周期特性。 第一步,录入数据,并将数据标准化或中心化(图1)。 图1 录入的数据及其中心化结果
《时间序列分析》案例案例名 称:时间序列分析在经济预测中的应用内容要 求:确定性与随机性时间序列之比较设计作 者:许启发,王艳明 设计时 间:2003年8月
案例四:时间序列分析在经济预测中的应用 一、案例简介 为了配合《统计学》课程时间序列分析部分的课堂教学,提高学生运用统计分析方法解决实际问题的能力,我们组织了一次案例教学,其内容是:对烟台市的未来经济发展状况作一预测分析,数据取烟台市1949—1998年国内生产总值(GDP)的年度数据,并以此为依据建立预测模型,对1999年和2000年的国内生产总值作出预测并检验其预测效果。国内生产总值是指一个国家或地区所有常住单位在一定时期内生产活动的最终成果,是反映国民经济活动最重要的经济指标之一,科学地预测该指标,对制定经济发展目标以及与之相配套的方针政策具有重要的理论与实际意义。在组织实施时,我们首先将数据资料印发给学生,并讲清本案例的教学目的与要求,明确案例所涉及的教学内容;然后给学生一段时间,由学生根据资料,运用不同的方法进行预测分析,并确定具体的讨论日期;在课堂讨论时让学生自由发言,阐述自己的观点;最后,由主持教师作点评发言,取得了良好的教学效果。 经济预测是研究客观经济过程未来一定时期的发展变化趋势,其目的在于通过对客观经济现象历史规律的探讨和现状的研究,求得对未来经济活动的了解,以确定社会经济活动的发展水平,为决策提供依据。 时间序列分析预测法,首先将预测目标的历史数据按照时间的先后顺序排列,然后分析它随时间的变化趋势及自身的统计规律,外推得到预测目标的未来取值。它与回归分析预测法的最大区别在于:该方法可以根据单个变量的取值对其自身的变动进行预测,无须添加任何的辅助信息。 本案例的最大特色在于:它汇集了统计学原理中的时间序列分析这一章节的所有知识点,通过本案例的教学,可以把不同的时间序列分析方法进行综合的比较,便于学生更好地掌握本章的内容。 二、案例的目的与要求 (一)教学目的 1.通过本案例的教学,使学生认识到时间序列分析方法在实际工作中应用的必要性和可能性; 2.本案例将时间序列分析中的水平指标、速度指标、长期趋势的测定等内容有机的结合在一起,以巩固学生所学的课本知识,深化学生对课本知识的理解; 3.本案例是对烟台市的国内生产总值数据进行预测,通过对实证结果的比较和分析,使学生认识到对同一问题的解决,可以采取不同的方法,根据约束条件,从中选择一种合适的预测方法; 4.通过本案例的教学,让学生掌握EXCEL软件在时间序列分析中的应用,对统计、计量分析软件SPSS或Eviews等有一个初步的了解; 5.通过本案例的教学,有助于提高学生运用所学知识和方法分析解决问题的能力、合作共事的能力和沟通交流的能力。 (二)教学要求 1.学生必须具备相应的时间序列分析的基本理论知识; 2.学生必须熟悉相应的预测方法和具备一定的数据处理能力; 3.学生以主角身份积极地参与到案例分析中来,主动地分析和解决案例中的问题; 4.在提出解决问题的方案之前,学生可以根据提供的样本数据,自己选择不同的统计分析方法,对这一案例进行预测,比较不同预测方法的异同,提出若干可供选择的方案; 5.学生必须提交完整的分析报告。分析报告的内容应包括:选题的目的及意义、使用数据的特征及其说明、采用的预测方法及其优劣、预测结果及其评价、有待于进一步改进的思路或需要进一步研究的问题。 三、数据搜集与处理 时间序列数据按照不同的分类标准可以划分为不同的类型,最常见的有:年度数据、季度数据、月度数据。本案例主要讨论对年度数据如何进行预测分析。考虑到案例设计时的侧重点,本案例只是对烟
3-17 解:(1)判断该序列的平稳性与纯随机性。 1)根据题中所列数据,绘制该序列的时序图,如图3-17-1所示。 图3-17-1:某城市过去63年中每年降雪量时序图 其中x表示每年降雪量。 时序图显示某城市过去每年降雪量始终围绕在80.3mm附近随机波动,没有明显的趋势或周期性,基本可视为平稳序列。 2)自相关图检验。如图3-17-2所示。 图3-17-2:样本自相关图 样本自相关图显示延迟2阶之后,该序列的自相关系数都落入2倍标准误之内,而且自相关系数在零值附近波动,是典型的短期相关自相关图。 由时序图和样本自相关图的性质,可以认为该序列为平稳序列。 α=,检验结果见表3-17-1。 3)纯随机性检验(0.05) 表3-17-1:纯随机性检验结果 <,认为该序列为检验结果显示,在6阶延迟下LB检验统计量的P值0.05 非白噪声序列。 (2)拟合模型 1)模型识别。
根据样本自相关图、偏自相关图对模型进行直接识别。由(1)可知,该序列在6阶延迟下平稳且非白噪声,已知样本自相关图,即图3-17-2所示,偏自相关图如下图所示。 图3-17-3:样本偏自相关图 而该序列的图像并不能直接识别出较为准确的模型,因此进一步利用SAS对模型进行最优模型定阶,结果如图3-17-4所示: 图3-17-4:最小信息量结果 最后一条信息显示,在自相关延迟系数小于等于5,移动平均延迟系数也小于等于5的所有ARMA(p,q)模型中,BIC信息量相对最小的是ARMA(1,0)模型,即AR(1)模型。 2)参数估计。 先利用SAS输出未知参数估计结果,如下表所示。 表3-17-2:未知参数估计结果 3)模型检验。 利用SAS,残差序列白噪声检验结果如下表所示。 表3-17-3:残差自相关检验结果
时间序列作业 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
3-17 解:(1)判断该序列的平稳性与纯随机性。 1)根据题中所列数据,绘制该序列的时序图,如图3-17-1所示。 图3-17-1:某城市过去63年中每年降雪量时序图 其中x表示每年降雪量。 时序图显示某城市过去每年降雪量始终围绕在80.3mm附近随机波动,没有明显的趋势或周期性,基本可视为平稳序列。 2)自相关图检验。如图3-17-2所示。 图3-17-2:样本自相关图 样本自相关图显示延迟2阶之后,该序列的自相关系数都落入2倍标准误之内,而且自相关系数在零值附近波动,是典型的短期相关自相关图。 由时序图和样本自相关图的性质,可以认为该序列为平稳序列。 α=,检验结果见表3-17-1。 3)纯随机性检验(0.05)
表3-17-1:纯随机性检验结果 检验结果显示,在6阶延迟下LB检验统计量的P值0.05 ,认为该序列为非白噪声序列。 (2)拟合模型 1)模型识别。 根据样本自相关图、偏自相关图对模型进行直接识别。由(1)可知,该序列在6阶延迟下平稳且非白噪声,已知样本自相关图,即图3-17-2所示,偏自相关图如下图所示。 图3-17-3:样本偏自相关图 而该序列的图像并不能直接识别出较为准确的模型,因此进一步利用SAS对模型进行最优模型定阶,结果如图3-17-4所示: 图3-17-4:最小信息量结果
最后一条信息显示,在自相关延迟系数小于等于5,移动平均延迟系数也小于等于5的所有ARMA(p,q)模型中,BIC信息量相对最小的是ARMA(1,0)模型,即AR(1)模型。 2)参数估计。 先利用SAS输出未知参数估计结果,如下表所示。 表3-17-2:未知参数估计结果 3)模型检验。 利用SAS,残差序列白噪声检验结果如下表所示。 表3-17-3:残差自相关检验结果 残差白噪声检验显示延迟6阶、12阶、18阶、24阶LB检验统计量的P值均显著大于0.05,所以该AR(1)模型显著有效。 参数显著性检验结果(见表3-17-2)显示两个参数t统计量的P值均小于 0.05,即两个参数均显著。 因此AR(1)模型是该序列的有效拟合模型。 拟合模型的具体形式。 利用SAS,拟合模型的具体形式如下图所示。
7 平稳时间序列预测法 7.1 概述 7.2 时间序列的自相关分析 7.3 单位根检验和协整检验 7.4 ARMA模型的建模 回总目录 7.1 概述 时间序列取自某一个随机过程,则称: 一、平稳时间序列 过程是平稳的――随机过程的随机特征不随时间变化而变化过程是非平稳的――随机过程的随机特征随时间变化而变化回总目录 回本章目录 宽平稳时间序列的定义: 设时间序列 ,对于任意的t,k和m,满足: 则称宽平稳。 回总目录
回本章目录 Box-Jenkins方法是一种理论较为完善的统计预测方法。 他们的工作为实际工作者提供了对时间序列进行分析、预测,以及对ARMA模型识别、估计和诊断的系统方 法。使ARMA模型的建立有了一套完整、正规、结构 化的建模方法,并且具有统计上的完善性和牢固的理 论基础。 ARMA模型是描述平稳随机序列的最常用的一种模型; 回总目录 回本章目录 ARMA模型三种基本形式: 自回归模型(AR:Auto-regressive); 移动平均模型(MA:Moving-Average); 混合模型(ARMA:Auto-regressive Moving-Average)。回总目录 回本章目录 如果时间序列满足 其中是独立同分布的随机变量序列,且满足:
则称时间序列服从p阶自回归模型。 二、自回归模型 回总目录 回本章目录 自回归模型的平稳条件: 滞后算子多项式 的根均在单位圆外,即 的根大于1。 回总目录 回本章目录 如果时间序列满足 则称时间序列服从q阶移动平均模型。或者记为。 平稳条件:任何条件下都平稳。
三、移动平均模型MA(q) 回总目录 回本章目录 四、ARMA(p,q)模型 如果时间序列 满足: 则称时间序列服从(p,q)阶自回归移动平均模型。 或者记为: 回总目录 回本章目录 q=0,模型即为AR(p); p=0,模型即为MA(q)。 ARMA(p,q)模型特殊情况: 回总目录 回本章目录 例题分析 设 ,其中A与B 为两个独立的零均值随机变量,方差为1;
第六章动态数列 一、判断题 1.若将某地区社会商品库存额按时间先后顺序排列,此种动态数列属于时期数列。 () 2.定基发展速度反映了现象在一定时期内发展的总速度,环比发展速度反映了现象 比前一期的增长程度。() 3.平均增长速度不是根据各期环比增长速度直接求得的,而是根据平均发展速度计 算的。() 4.用水平法计算的平均发展速度只取决于最初发展水平和最末发展水平,与中间各 期发展水平无关。() 5.平均发展速度是环比发展速度的平均数,也是一种序时平均数。() 1、× 2、× 3、√ 4、√ 5、√。 二、单项选择题 1.根据时期数列计算序时平均数应采用()。 A.几何平均法 B.加权算术平均法 C.简单算术平均法 D.首末 折半法 2.下列数列中哪一个属于动态数列()。 A.学生按学习成绩分组形成的数列 B.工业企业按地区分组形成的数 列 C.职工按工资水平高低排列形成的数列 D.出口额按时间先后顺序排列形成 的数列 3.已知某企业1月、2月、3月、4月的平均职工人数分别为190人、195人、193 人和201人。则该企业一季度的平均职工人数的计算方法为()。 4.说明现象在较长时期内发展的总速度的指标是()。 A、环比发展速度 B.平均发展速度 C.定基发展速度 D.环比增 长速度 5.已知各期环比增长速度为2%、5%、8%和7%,则相应的定基增长速度的计算方法为 ()。 A.(102%×105%×108%×107%)-100% B.102%×105%×108%×107% C.2%×5%×8%×7% D.(2%×5%×8%×7%)-100% 6.定基增长速度与环比增长速度的关系是()。 A、定基增长速度是环比增长速度的连乘积 B、定基增长速度是环比增长速度之和 C、各环比增长速度加1后的连乘积减1 D、各环比增长速度减1后的连乘积减1 7.间隔不等的时点数列求序时平均数的公式是()。
实验五 用E X C E L 进行时间序列分析 一、实验目的 利用Excel 进行时间序列分析 二、实验内容 1.测定发展水平和平均发展水平 2. 测定增长量和平均增长量 3. 测定发展速度、增长速度和平均发展速度 4. 计算长期趋势 5. 计算季节变动 三、实验指导 时间序列分析常用的方法有两种:指标分析法和构成因素分析法。 指标分析法,通过计算一系列时间序列分析指标,包含发展水平、平均发展水平、增长量、平均增长量、发展速度、平均发展速度等来揭示现象的发展状况和发展变化程度。 构成因素分析法,是将时间序列看做由长期趋势、季节变动、循环变动、不规则变动四种因素构成,将各影响因素分别从时间序列中分离出去并加以测定、对未来发展做出预测的过程。 发展水平: 发展水平是指某一经济现象在各个时期达到的实际水平。 在时间序列中,各指标数值就是该指标所反映的社会经济现象在所属时间的发展水平。在时间序列中,我们用y 表示指标值,t 表示时间,则t y (t=0,1,2,3,…,n)表示各个时期的指标值。 平均发展水平: 平均发展水平又称“序时平均数”、“动态平均数”,是时间序列中各项发展水平的平均数,反映现象在一段时期中发展的一般水平。 增长量: 增长量是指某一经济现象在一定时期增长或减少的绝对量。它是报告期发展水平减基期发展水平之差。 平均增长量:平均增长量是时间序列中的逐期增长量的序时平均数,它表明现象在一定时段内平均每期增加(减少)的数量。公式表示如下: 发展速度:发展速度是说明事物发展快慢程度的动态相对数。它等于报告期水平对基期水平之比。发展速度有两种:分为环比发展速度和定基发展速度。 1.环比发展速度:也称逐期发展速度,是报告期发展水平与前一期发展水平之比。 2.定基发展速度:是报告期水平与固定基期水平之比。 平均发展速度:平均发展速度是动态数列中各期环比发展速度或各期定基发展速度中的环比发展速度的序时平均数。它说明在一定时期内发展速度的一般水平。 平均发展速度的计算方法有几何法和方程法。 1.几何法计算平均发展速度:实际动态数列各期环比发展速度连乘积等于理论动态数列中各期平均发展速度的连乘积 2.方程法计算平均发展速度:方程法平均发展速度的特点是实际动态数列各项之和等于理论动态数列各项之和,所以称为“累积法” (1)测定发展水平和平均发展水平 在时间i t 上的观察值i Y ,就是该时间点的发展水平。 平均发展水平是现象在时间i t (i=1,2,…,n )上各期观察值i Y 的平均数。 ①时期序列的序时平均数计算
第二章习题 第一题 代码如下 data example2; input freq@@; time=intnx('year','1',_n_-1); format year year4; cards; 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ; proc gplot data =example2; plot freq*time; symbol c=black v=star i=join; run; 结果如下 平稳序列的时序图应该显示该序列始终在一个常数值附近波动,而且波动范围有界的特点。可是上述时序图是一次函数递增趋势的,所以该序列是非平稳序列。
从图中我们发现序列的自相关系数递减到零的速度相当缓慢,在很长的时间延迟时期里,自相关系数一直为正,而后又一直为负,在子相关图上显示出明显的三角对称性,这是具有单调趋势的非平稳序列的一种典型自相关图形式,这和该序列时序图的单调递增是一致的。 各个延迟阶数下的自相关系数如下 K=1 ρ=0.85 K=2 ρ=0.7015 K=3 ρ=0.55602 K=4 ρ=0.41504 K=5 ρ=0.28008 K=6 ρ=0.152635 SPSS
第二题 代码如下 data example2; input ppm@@; time=intnx('month','01jan1975'd,_n_-1); format time monyy.; cards; 330.45 330.97 331.64 332.87 333.61 333.55 331.90 330.05 328.58 328.31 329.41 330.63
一案例分析的目的 本案例选取2001年1月,到2013年我国铁路运输客运量月度数据来构建ARMA模型,并利用该模型进行外推预测分析。 二、实验数据 数据来自中经网统计数据库
数据来源:中经网数据库 三、ARMA 模型的平稳性 首先绘制出N 的折线图,如图 从图中可以看出,N 序列具有较强的非线性趋势性,因此从图形可以初步判断该序列是非平
稳的。此外,N在每年同期出现相同的变动方式,表明N还存在季节性特征。下面对N 的平稳性和季节季节性进行进一步检验。 四、单位根检验 为了减少N 的变动趋势以及异方差性,先对N进行对数处理,记为LN其曲线图如下:GENR LN = LOG(N) 对数后的N趋势性也很强。下面观察N 的自相关表,选择滞后期数为36,如下: 从上图可以看出,LN的PACF只在滞后一期是显著的ACF随着阶数的增加慢慢衰减至0,因此从偏/自相关系数可以看出该序列表现一定的平稳性。进一步进行单位根检验,打开LN选择存在趋势性的形式,并根据AIC自动选择滞后阶数,单位根检验结果如下:
T统计值的值小于临界值,且相伴概率为0.0001,因此该序列不存在单位根,即该序列是平稳序列。 五、季节性分析 趋势性往往会掩盖季节性特征,从LN的图形可以看出,该序列具有较强的趋势性,为了分析季节性,可以对LN进行差分处理来分析季节性: Genr = DLN = LN – LN (-1) 观察DLN的自相关表,如下:
DLN在之后期为6、12、18、24、30、36处的自相关系数均显著异于0,因此,该序列是以周期6呈现季节性,而且季节自相关系数并没有衰减至0,因此,为了考虑这种季节性,进行季节性差分: GENR SDLN = DLN –DLN(-6) 再做关于SDLN的自相关表,如下: SDLN在滞后期36之后的季节ACF和PACF已经衰减至0,下面对SDLN建立SARMA模型。 六、滞后阶数的初步确定 观察SDLN的自相关、偏自相关图,ACF 和PACF在滞后期1和滞后期6还有滞后期12异于0,其余均与0无异,因此,SARMA(p,q)(k,m)s中p和q均不超过1,k和m均不超过2.6考虑到高洁移动平均模型估计较为困难,而且自回归模型的检验可以表示无穷的移动平均过程,因此q尽可能取较小的取值。本例拟选择SARMA(1,0)(1,0)6、SARMA(1,0)(1,1)6、SARMA(1,0)(1,2)6、SARMA(1,0)(2,1)6、SARMA(1,1)(1,0)6、SARMA(1,1)(1,1)6、SARMA(1,1)(1,2)6、SARMA(1,1)(0,1)6八个模型来拟合SDLN。
时间序列分析预测EXCEL操作 一、长期趋势(T)的测定预测方法 线性趋势→:: 用回归法 非线性趋势中的“指数曲线”:用指数函数LOGEST、增长函数GROWTH(针对指数曲线) 多阶曲线(多项式):用回归法 (一)回归模型法-------长期趋势(线性或非线性)模型法: 具体操作过程:在EXCEL中点击“工具”→“数据分析”→“回归”→分别在“Y值输入区域”和“X值输入区域”输人数据和列序号的单元格区域一选择需要的输出项目,如“线性拟合图”。回归分析工具的输出解释: 计算结果共分为三个模块: 1)回归统计表: Multiple R(复相关系数R):R2的平方根,又称为相关系数,它用来衡量变量xy之间相关程度的大小。R Square(复测定系数R2 ):用来说明用自变量解释因变量变差的程度,以测量同因变量y的拟合效果。Adjusted R Square (调整复测定系数R2):仅用于多元回归才有意义,它用于衡量加入独立变量后模型的拟合程度。当有新的独立变量加入后,即使这一变量同因变量之间不相关,未经修正的R2也要增大,修正的R2仅用于比较含有同一个因变量的各种模型。 标准误差:又称为标准回归误差或叫估计标准误差,它用来衡量拟合程度的大小,也用于计算与回归有
关的其他统计量,此值越小,说明拟合程度越好。 2)方差分析表:方差分析表的主要作用是通过F检验来判断回归模型的回归效果。 3)回归参数:回归参数表是表中最后一个部分: ?Intercept:截距a ?第二、三行:a (截距) 和b (斜率)的各项指标。 ?第二列:回归系数a (截距)和b (斜率)的值。 ?第三列:回归系数的标准误差 ?第四列:根据原假设Ho:a=b=0计算的样本统计量t的值。 第五列:各个回归系数的p值(双侧) 第六列:a和b 95%的置信区间的上下限。 (二)使用指数函数LOGEST和增长函数GROWTH进行非线性预测 在Excel中,有一个专用于指数曲线回归分析的LOGEST函数,其线性化的全部计算过程都是自动完成的。如果因变量随自变量的增加而相应增加,且增加的幅度逐渐加大;或者因变量随自变量的增加而相应减少,且减少的幅度逐渐缩小,就可以断定其为指数曲线类型。 具体操作过程: 1.使用LOGEST函数计算回归统计量 ①打开“第3章时间数列分析与预测.xls”工作簿,选择“增长曲线”工作表如下图所示。 ②选择E2:F6区域,单击工具栏中的“粘贴函数”快捷键,弹出“粘贴函数”对话框,在“函数分类”中选择 “统计”,在“函数名”中选择“LOGEST”函数,则打开LOGEST对话框,如下图11.20所示。
2016年第二学期时间序列分析及应用R 语言课后作业 第三章 趋势 3.4(a) data(hours);plot(hours,ylab='Monthly Hours',type='o') 画出时间序列图 Time M o n t h l y H o u r s 19831984198519861987 39.039.540.040.541.041. 5 (b) data(hours);plot(hours,ylab='Monthly Hours',type='l') Time M o n t h l y H o u r s 19831984198519861987 39.039.540.040.541.041. 5 type='o' 表示每个数据点都叠加在曲线上;type='b' 表示在曲线上叠加数据点,但是该数据点附近是断开的;type='l' 表示只显示各数据点之间的连接线段;type='p' 只想显示数据点。 points(y=hours,x=time(hours),pch=as.vector(season(hours))) Time M o n t h l y H o u r s 19831984 198519861987 39.039.5 40.0 40.5 41.041.5 J A S O N D J F M A M J J A S O N D J F M A M J J A S O N D J F M A M J J A S O N D J F M A M J J A S O N D J F M A M J 3.10(a) data(hours);hours.lm=lm(hours~time(hours)+I(time(hours)^2));summary(hours.lm)
实验五用EXCEL进行时间序列分析 一、实验目的 利用Excel进行时间序列分析 二、实验内容 1.测定发展水平和平均发展水平 2. 测定增长量和平均增长量 3. 测定发展速度、增长速度和平均发展速度 4. 计算长期趋势 5. 计算季节变动 三、实验指导 时间序列分析常用的方法有两种:指标分析法和构成因素分析法。 指标分析法,通过计算一系列时间序列分析指标,包含发展水平、平均发展水平、增长量、平均增长量、发展速度、平均发展速度等来揭示现象的发展状况和发展变化程度。 构成因素分析法,是将时间序列看做由长期趋势、季节变动、循环变动、不规则变动四种因素构成,将各影响因素分别从时间序列中分离出去并加以测定、对未来发展做出预测的过程。 发展水平:发展水平是指某一经济现象在各个时期达到的实际水平。 在时间序列中,各指标数值就是该指标所反映的社会经济现象在所属时间的发展 y(t=0,1,2,3,…,n)水平。在时间序列中,我们用y表示指标值,t表示时间,则 t 表示各个时期的指标值。 平均发展水平:平均发展水平又称“序时平均数”、“动态平均数”,是时间序列中各项发展水平的平均数,反映现象在一段时期中发展的一般水平。 增长量:增长量是指某一经济现象在一定时期增长或减少的绝对量。它是报告期发展水平减基期发展水平之差。 平均增长量:平均增长量是时间序列中的逐期增长量的序时平均数,它表明现象在一定时段内平均每期增加(减少)的数量。公式表示如下: 发展速度:发展速度是说明事物发展快慢程度的动态相对数。它等于报告期水平对基期水平之比。发展速度有两种:分为环比发展速度和定基发展速度。 1.环比发展速度:也称逐期发展速度,是报告期发展水平与前一期发展水平之比。2.定基发展速度:是报告期水平与固定基期水平之比。 平均发展速度:平均发展速度是动态数列中各期环比发展速度或各期定基发展速度中的环比发展速度的序时平均数。它说明在一定时期内发展速度的一般水平。平均发展速度的计算方法有几何法和方程法。
案例4 某专卖店销售额数量规律研究 资料 某专卖店为加强管理的科学化,采集了过去五年的销售量资料如下: 讨论大纲 1. 用哪些简单的描述性指标,可大致找到该专卖店销售额的一般规律? 答:在不考虑不规则变化的情况下,用长期趋势、季节变动和周期波动这些描述性指标可以找到专卖店销售额的一般规律。 2. 能否以一个近似的函数式描述出销售额的长期趋势?能否进行预测? 答:可以用一个近似的函数式描述销售额的长期趋势,计算过程如下表所示 函数式为24.870.298Y X Λ =+,可以进行预测,如预测2009年冬季的销售额,即将序号21作为自变量X 的值代入上述函数式中求解相应的预测值。
3.该数列是否存在明显的季节性变化,如何测定? 4.该数列是否存在周期波动,如何测定? 答:将3、4步合并进行分析,过程如下: 第一步:计算上述时间序列的季节指数,利用移动平均比率法,计算过程如下表所示
从季节指数的计算过程可以看出数列存在明显的季节性变化,用季节指数测定,春夏秋冬季节的季节指数分别为119.64%,75.99%,108.13%,96.23% 第二步:根据季节指数,可以得到消除季节影响的序列,然后根据这一无季节影响的时间序列拟合趋势线,计算过程如下表
所得趋势线为24.800.31Y X Λ =+ 第三步:测定周期波动,将1-20这20个时间的序号分别代入第二步求解出的趋势线24.800.31Y X Λ=+中,得到下表中的(3)列,然后用消除的季节影响的序列除以(3)列即可得到周期波动的成分,计算过程如下表所示:
5.上述规律如何帮助该专卖店的经营决策? 答:利用上述规律可以帮助专卖店预测下一年四个季度的销售额情况,如下表: 其中趋势值是将21,22,23,24分别作为X 值代入24.800.31Y X Λ =+中得到。 预测值为趋势值与季节指数相乘得到 通过预测值及前面求解出的季节指数,商家可以更好的掌握季节的影响,趋势的影响及周期的波动,可以更好的做出经营决策。
用Excel做时间序列预测法实例分析 4.3.1时间序列预测法概述 1.时间序列预测法的概念 ,时间序列是指把历史统计资料按时间顺序排列起来得到的一组数据序列。例如,按月份排列的某种商品的销售量。 时间序列预测法是将预测目标的历史数据按时间顺序排列成为时间序列,然后分析它随时间变化的发展趋势,外推预测目标的未来值。因此,时间序列预测法主要用于分析影响事物的主要因素比较困难或相关变量资料难以得到的情况,预测时先要进行时间序列的模式分析。时间序列预测法通常又分为移动平均法、指数平滑法、趋势外推法、季节分析法和生命周期法等。 2.时间序列模式 不同的时间序列预测方法只适用于一定的数据时间序列模式。时间序列的模式,是指历史时间序列所反映的某种可以识别的事物变动趋势形态。时间序列的基本模式,可以归纳为水平型、趋势型、周期变动型和随机型四种类型,它们大体反映了市场供求变动的基本形态。(1)水平型。水平型时间序列模式是指时间序列各个观察值呈现出围绕着某个定值上下波动的变动形态。如某些非季节性的生活必需品的逐月销售量等。水平型的时间序列模式一般采用平均法进行预测。 (2)趋势型。趋势型时间序列模式是指时间序列在一定时期内虽出现小范围的上下 波动,但总体上呈现出持续上升或下降趋势的变动形态。如高档耐用消费品的经济寿命 曲线等。趋势型时间序列模式依其特征不同又可分为线性和非线性趋势模式。一般采用趋势外推预测法。 (3)周期变动型。周期变动型时间序列模式是指随着时间的推移,时间序列呈现出有规则的上升与下降循环变动的形态。按时间序列循环波动的周期不同,可分为季节变动型模式和循环变动型模式两类。常见的是季节变动型模式,这种模式往往以年为变动周期,按月或按季度编制时间序列,如许多季节性消费品的按月、按季销售量等一般采用季节指数法进行预测。 (4)随机型。随机型时间序列模式是指时间序列呈现出的变化趋势走向升降不定、没有一定规律可循的变动势态。这种现象往往是由于某些偶然因素引起的,如经济现象中的不规则变动、政治变动以及自然气候的突变等。对于这类时间序列模式,很难运用时间序列预测方法作出预测,但有时也可通过某种统计处理,消除不规则因素的影响,找出事物固定的变化规律,从而进行分析预测。 4.3.2移动平均预测法实例分析 例2,某家电产品2009年1~12月份实际市场销售额如表4-2所示。试运用移动平均法和二次移动平均法,采用近4期数据预测2010年1月份的市场需求量。 表4-2某产品2009年市场销售额(单位;万元) 1.移动平均法概述 移动平均法的计算过程是对一组近期实际值取平均值,将这个平均值作为下期预测值,逐项移动,形成一个序列平均数的时间序列。它是根据时间序列资料、逐项推移,依次计算包含一定项数的序时平均值,以反映长期变动趋势的方法。当时间序列的数值由于受到周期变动
第四章 预 测 在本章当中我们讨论预测的一般概念和方法,然后分析利用),(q p ARMA 模型进行预测的问题。 §4.1 预期原理 利用各种条件对某个变量下一个时点或者时间阶段内取值的判断是预测的重要情形。为此,需要了解如何确定预测值和度量预测的精度。 4.1.1 基于条件预期的预测 假设我们可以观察到一组随机变量t X 的样本值,然后利用这些数据预测随机变量1+t Y 的值。特别地,一个最为简单的情形就是利用t Y 的前m 个样本值预测1+t Y ,此时t X 可以描述为: 假设*|1t t Y +表示根据t X 对于1+t Y 做出的预测。那么如何度量预测效果呢?通常情况下,我们利用损失函数来度量预测效果的优劣。假设预测值与真实值之间的偏离作为损失,则简单的二次损失函数可以表示为(该度量也称为预测的均方误差): 定理4.1 使得预测均方误差达到最小的预测是给定t X 时,对1 +t Y 的条件数学期望,即: 证明:假设基于t X 对1+t Y 的任意预测值为: 则此预测的均方误差为: 对上式均方误差进行分解,可以得到: 其中交叉项的数学期望为(利用数学期望的叠代法则): 因此均方误差为: 为了使得均方误差达到最小,则有: 此时最优预测的均方误差为: 211*|1)]|([)(t t t t t X Y E Y E Y MSE +++-= End 我们以后经常使用条件数学期望作为随机变量的预测值。 4.1.2 基于线性投影的预测 由于上述条件数学期望比较难以确定,因此将预测函数的范围限制在线性函数当中,我们考虑下述线性预测: 如此预测的选取是所有预测变量的线性组合,预测的优劣则体现在系数向量的选择上。 定义4.1 如果我们可以求出一个系数向量值α,使得预测误差)(1t t X Y α'-+与t X 不相关: 则称预测t X α'为1+t Y 基于t X 的线性投影。 定理4.2 在所有线性预测当中,线性投影预测具有最小的均方误差。
1、(1)判断序列的平稳性 该序列时序图如图1所示: 时序图显示该序列有显著的变化趋势,为典型的非平稳序列。 (2)对原序列进行差分运算: 对原序列进行1阶差分运算,运算后序列时序图如图2所示: 时序图显示差分后序列在均值附近比较平稳的波动。为了进一步确定平稳性,考察差分后序列的自相关图,如图三所示:
自相关图显示差分后序列不存在自相关,所以可以认为1阶差分后序列平稳,从图中我们还可以判断差分后序列可以视为白噪声序列。 (3)对白噪声平稳差分序列拟合AR 模型 原序列的自相关图和偏自相关图如图4: 图中显示序列自相关系数拖尾,偏自相关系数1阶截尾,实际上我们用ARIMA (1,0,0)模型拟合原序列。在最小二乘估计原理下,拟合结果为: 10.88831.489t t t x x ε-=++
(4)对残差序列进行检验: 残差白噪声检验: 参数显著性检验: 图中显示:延迟6阶和12阶的P 值均大于0.05,可以认为该残差序列即为白噪声序列,系数显著性检验显示两参数均显著。这说明ARIMA (1,0,0)模型对该序列建模成功。 (5)模型的预测: 估计下一盘的收盘价为:(1)0.88828931.489288.121t x ∧ =?+= 2、(1)绘制时序图: 时序图显示该序列具有长期递增趋势和以年为周期的季节效应。
(2)差分平稳化 对原序列作1阶差分,希望提取原序列的趋势效应,差分后序列时序图: 3、模型定阶 考察差分后序列相关图和偏自相关图的性质,进一步确认平稳性判断,并估计拟合模型的阶数。 自相关图和偏自相关图显示延迟12阶自相关系数和偏自相关系数大于2倍标准差范围,说明差分后序列中仍有非常显著的季节效应。延迟1阶的自相关系数和偏自相关系数也大于2倍的标准差,这说明差分后序列还具有短期相关性。根据差分后序列自相关图和偏自相关图的性质,尝试拟合ARMA模型,但拟合效果均不理想,拟合残差均通不过白噪声检验。所以我们可以考虑建立乘积模型:
时间序列数据平稳性检验实验 指导(总6页) -CAL-FENGHAI.-(YICAI)-Company One1 -CAL-本页仅作为文档封面,使用请直接删除
实验一时间序列数据平稳性检验实验指导 一、实验目的: 理解经济时间序列存在的不平稳性,掌握对时间序列平稳性检验的步骤和各种方法,认识利用不平稳的序列进行建模所造成的影响。 二、基本概念: 如果一个随机过程的均值和方差在时间过程上都是常数,并且在任何两时期的协方差值仅依赖于该两个时期间的间隔,而不依赖于计算这个协方差的实际时间,就称它是宽平稳的。 时序图 ADF检验 PP检验 三、实验内容及要求: 1、实验内容: 用来分析1964年到1999年中国纱产量的时间序列,主要内容: (1)、通过时序图看时间序列的平稳性,这个方法很直观,但比较粗糙;(2)、通过计算序列的自相关和偏自相关系数,根据平稳时间序列的性质观察其平稳性; (3)、进行纯随机性检验; (4)、平稳性的ADF检验; (5)、平稳性的pp检验。 2、实验要求: (1)理解不平稳的含义和影响; (2)熟悉对序列平稳化处理的各种方法; (2)对相应过程会熟练软件操作,对软件分析结果进行分析。 四、实验指导 (1)、绘制时间序列图 时序图可以大致看出序列的平稳性,平稳序列的时序图应该显示出序列始终围绕一个常数值波动,且波动的范围不大。如果观察序列的时序图显示出该序列有明显的趋势或周期,那它通常不是平稳序列,现以1964-1999年中国纱年产量序列(单位:万吨)来说明。 在EVIEWS中建立工作文件,在“Workfile structure type”栏中选择“Dated-regular frequency”,在右边的“Date specification”中输入起始年1964,终止年1999,点击ok则建立了工作文件。找到中国纱年产量序列的excel文件并导入命名该序列为sha,见图1-2。
实验六用EXCEL进行时间序列分析 实验目的:了解基于EXCEL的时间序列分析过程 实验内容:季节指数的计算; 分离季节因素; 建立预测模型并进行预测 1. 用EXCEL计算季节指数 下表是一家啤酒生产企业2000-2005年各季度的啤酒销售量数据。试计算各季的季节指数. 试测定该数列的季节指数。 计算步骤: 第一步:计算移动平均值(季度数据采用4项移动平均),并将其结果进行“中心化”处理,得出“中心化移动平均值” 第二步:将序列的各观察值除以相应的中心化移动平均值,然后再计算出各比值的季度平均值,即季节指数 第三步:调整:各季节指数的平均数应等于1或100%,若根据第2步计算的季节比率的平均值不等于1时,则需要进行调整。具体方法是:将第2步计算的每个季节比率的平均值除以它们的总平均值 2、分离季节因素 续上题。 步骤:将原时间序列除以相应的季节指数即可得分离季节效应后的序列。 年/季啤酒销售量 (Y) Y/S 2000/1 25 31.55651 2 32 30.69943 3 37 29.01494 4 26 29.2069 2001/1 30 37.86781 2 38 36.45558 3 42 32.93588 4 30 33.70027 2002/1 29 36.60555 2 39 37.41493 3 50 39.20938 4 3 5 39.31698 2003/1 30 37.86781
2 39 37.41493 3 51 39.99356 4 37 41.56366 2004/1 29 36.60555 2 42 40.29301 3 55 43.13031 4 38 42.687 2005/1 31 39.13007 2 4 3 41.25236 3 5 4 42.34613 4 41 46.05703 3、建立预测模型并进行预测 续上题。 步骤一:根据分离季节性因素的序列确定线性趋势方程; 步骤二:根据趋势方程进行趋势预测。该预测值不含季节性因素,即在没有季节因素影响情况下的预测值。 步骤三:计算最终的预测值。将回归预测值乘以相应的季节指数。 步骤四:计算预测误差。 实验报告: 完成教材上的习题13.11 文件选项加载项选择分析数据库 1:计算移动平均值(季度数据采用4项移动平均), 并将其结果进行“中心化”处理,得出“中心化移动平均值”
时间序列分析第四次作业 ——房青 B0712094 1071209153 1. ARMA-GARCH modeling of SSE Composite Index. Use the recent 1000 obervations on the log return of the SSECI. (1) Use PACF to identify an ARCH model of the series. In terms of correlations, is this model adequate for the modeling of the conditional heteroskedasicity? And what about the conditional mean? Lag P a r t i a l A C F 0 510 15202530 -0.05 0.0 0.05 0.1 0 Series : difflogsh 通过PACF 图,可以确定ARCH 模型的阶数为24。 Ljung-Box test for standardized residuals: Statistic P-value Chi^2-d.f. 28.83 0.004172 12 Ljung-Box test for squared standardized residuals: Statistic P-value Chi^2-d.f. 3.974 0.9839 12 根据上述检验结果可以看出,在5%显著性水平下模型残差具有显著自相关性,说明ARCH (24)对条件异方差的拟合能力并不好。