
用于孤立词识别的语音识别系统实验报告
语音是人际交流的最习惯、最自然的方式,它将成为让计算机智能化地与人通信,人机自然地交互的理想选择。让说话代替键盘输入汉字,其技术基础是语音识别和理解。语音识别将人发出的声音、音节、或短语转换成文字和符号,或给出响应执行控制,作出回答。
该系统用于数字0~9的识别,系统主要包括训练和识别两个阶段。实现过程包括对原始语音进行预加重、分帧、加窗等处理,提取语音对应的特征参数。在得到了特征参数的基础上,采用模式识别理论的模板匹配技术进行相似度度量,来进行训练和识别。在进行相似度度量时,采用DTW 算法对特征参数序列重新进行时间的对准。
一、 特征提取
1、端点检测
利用短时平均幅度和短时过零率进行端点检测,以确定语音有效范围
的开始和结束位置。
首先利用短时平均幅度定位语音的大致位置。做法为:(1)确定一个
较高的阈值MH,短时平均幅度大于MH 的部分一定是语音段。(2)分别沿这一语音段向两端搜索,大于某个阈值ML 的部分还是语音段,这样能较为准确地确定语音的起始点,将清音与无声段分开。因为清音的过零率远远高于无声段,确定一个过零率的阈值Z min , 从ML 确定的语音段向前搜
索不超过一帧的长度,短时过零率突然低于Z
min 三倍的点被认为是语音的
起始点。
2、预加重
对输入的原始语音进行预加重,其目的是为了对语音的高频部分进行加重,增加语音的高频分辨率。假设在n 时刻的语音采样值为x(n),则经过预加重处理后的结果为:
y(n)=x(n)+αx(n-1) α=0.98
3、分帧及加窗
语音具有短时平稳的特点,通过对语音进行分帧操作,可以提取其短时特性,便于模型的建立。帧长取为30ms ,帧移取为10ms ,然后将每帧信号用Hamming 窗相乘,以减小帧起始和结束处的信号不连续性。Hamming 窗函数为: w(n)=0.54-0.46cos(1
2-N n π) (0≤n ≤N-1) 该系统中,hamming 窗的窗长N 取为240。
设原始信号为s(n),加窗后为:
s w (n)=
∑∞
-∞=-m m n w m s )()( 4、特征参数的计算
人耳对不同频率的语音具有不同的感知能力,试验发现,在1000Hz 以下,感知能力与频率成线性关系,而在1000Hz 以上,感知能力则与频率成对数关系。为了模拟人耳对不同频率语音的感知特性,人们提出了Mel 频率概念,其意义为:1Mel 为1000Hz 的音调感知程度的1/1000。频率f
与Mel 频率的转换关系为:)10log()7001log(2595f B +?=
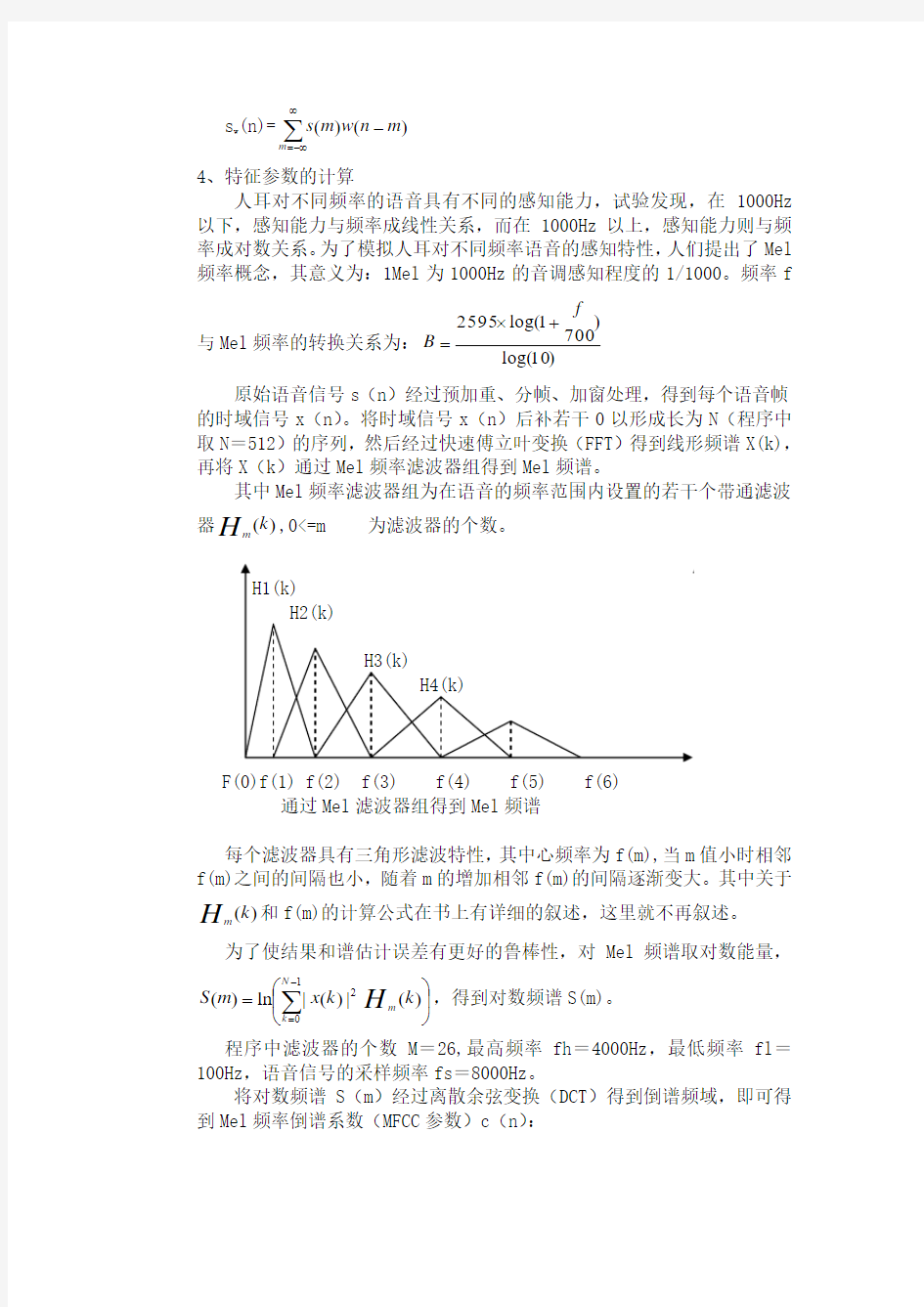
原始语音信号s (n )经过预加重、分帧、加窗处理,得到每个语音帧的时域信号x (n )。将时域信号x (n )后补若干0以形成长为N (程序中取N =512)的序列,然后经过快速傅立叶变换(FFT )得到线形频谱X(k),再将X (k )通过Mel 频率滤波器组得到Mel 频谱。
其中Mel 频率滤波器组为在语音的频率范围内设置的若干个带通滤波器)(k H m ,0<=m F(0)f(1) f(2) f(3) f(4) f(5) f(6) 通过Mel 滤波器组得到Mel 频谱 每个滤波器具有三角形滤波特性,其中心频率为f(m),当m 值小时相邻f(m)之间的间隔也小,随着m 的增加相邻f(m)的间隔逐渐变大。其中关于)(k H m 和f(m)的计算公式在书上有详细的叙述,这里就不再叙述。 为了使结果和谱估计误差有更好的鲁棒性,对Mel 频谱取对数能量, ?? ? ??=∑-=1 02 )(|)(|ln )(N k m k k x m S H ,得到对数频谱S(m)。 程序中滤波器的个数M =26,最高频率fh =4000Hz ,最低频率fl =100Hz ,语音信号的采样频率fs =8000Hz 。 将对数频谱S (m )经过离散余弦变换(DCT )得到倒谱频域,即可得到Mel 频率倒谱系数(MFCC 参数)c (n ): C(n)= ∑-=1 0M m S (m )cos(M m n )2/1(+π) (0≤m ≤M ) 在实际的语音识别应用中,并不是取全部维数的MFCC 系数,试验表 明,通常取前12维的MFCC 系数即可。 二、 训练和识别 训练。用户输入若干次训练语音,然后用上面所述的方法提取各个数 字的特征参数,用模板匹配技术训练模板,得到每个数字的特征模板,放入特征模板库中。 识别。为了进行相似度度量,将特征模板库中的各个模板称为参考模 板,将待识别的输入语音经过预处理以及特征提取以后得到的特征矢量序列称之为测试模板。计算测试模板和参考模板之间的相似度,可以计算它们之间的失真,失真越小相似度越高。对于特征矢量之间的失真度,有多种度量的方法,为了简单和便于处理,使用欧氏距离来进行度量。 在语音识别的过程中,进行相似度度量时,对用户语音进行训练或识 别时,即使每次尽量以同样的方式说同一个词汇,其持续时间的长度也会随机改变,而且每个词内部各个部分的相对时长也是随机变化的,因此,如果直接用特征矢量序列的模式来进行相似度的比较,其效果不可能是最佳的。需要用DTW 算法对特征参数序列模式重新进行时间的对准来进行相似性的比较。 DTW 算法通过寻找一条通过测试模板和参考模板各个交叉点的帧失真度总和最小的路径,再向前回溯,即可得最佳路径。识别过程中,将待识别数字的特征参数与每个参考模板进行比较,帧失真度最小的模板即识别为该模板中的数字。 三、 界面 界面分识别和训练两个模块,训练时先选择所要训练的数字,再录音加入训练集。识别时录入任意数字,即可进行识别。通过录音按钮和暂停按钮控制录音,录音时均可显示波形。使用Waveform 函数waveInOpen 、waveInPrepareHeader 、waveInAddBuffer 、waveOutOpen 、waveOutReset 等显示声音波形。 四、 实验小结 在该系统中,采用了频域分析方法对语音信号进行分析,提取了可靠、量化、突出的特征。对数字0~9的识别率可达80%以上。对于语音波形相似的2和8、1和7较难识别,但是增加训练样本后,问题可得到改善。 语音识别系统实验报告 专业班级:信息安全 学号: 姓名: 目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6) 3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12) 一、设计任务及要求 实现语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中, IBM语音识别输入系统(ViaVioce) V9.1 简体中文光盘版| 用嘴巴控制电脑... sjyhsyj 2009-8-28 12:13:271# 软件大小:276.08MB 软件语言:多国语言 软件类别:国外软件 / 汉字输入 运行环境:Win9x/NT/2000/XP/ 软件介绍: 该系统可用于声控打字和语音导航。只要对着微机讲话,不用敲键盘即可打汉字,每分钟可输入150个汉字,是键盘输入的两倍,是普通手写输入的六倍。该系统识别率可达95%以上。并配备了高性能的麦克风,使用便利,特别适合于起草文稿、撰写文章、和准备教案,是文职人员、作家和教育工作者的良好助手。 IBM潜心研究26年,他领导了世界的语音识别技术,其语音识别产品在全球销售已达一百万套以上。使用语音输入方式,您的工作空间更加自由舒畅: *即使您不会打字,也可迅速准备好文稿; *只要集中精力思考问题,无须琢磨怎样拼音,怎样拆字; *当您疲劳时,闭上眼、伸伸腰,双手方在脑后,然后轻松地说:开始听写吧... ... 注:价值超数千元的IBM的中文语音录入工具,有耳麦的朋友可以试一试,也可以当作学习普通话的工具,没有理由不下载使用它。 IBM ViaVoice语音输入系统详解 作者: 艾寒出处: 天极网 目前汉字输入的方式主要有四种:键盘输入,手写输入,扫描输入和我们现在要谈到的语音输入。让我们先来了解一下这四种输入方式。 键盘输入:键盘输入基本上是基于各种输入法,主要又分为字形输入法和拼音输入法。实际上字形输入法是不符合人的写作思维习惯,因为人们在措辞时,头脑中首先反映出的是即将这个词语的语音,所以字形输入法更适合专业录入人员使用。拼音输入法也分两种,一种以词语为输入单位,另一种以语句为输入单位,而后者不符合写作的思维习惯,因为人们在写作时是以词为思考单位。键盘输入法在输入速度有要求的情况下对于键盘操作、指法要求比较高; 手写输入:手写输入是最容易上手的输入方法,但是同样由于手写输入的先天不足,很难达到较高的输入速度; 扫描输入:扫描输入对于硬件要求比较高,主要是适用于资料的整理; 语音输入:语音输入对输入人员的键盘操作能力、指法要求很低,几乎可以说你只要会说汉语,就可以进行语音输入。 语音输入尤其是汉字语音输入经历了很长时间的研究和应用,到目前已经达到了一个相 本科学生毕业论文(设计) 题目(中 文): 特定人孤立词语音识别的研究 (英文): Research Of Speaker-dependent Isolated-word Speech recognition 姓名学号院(系)专业、年级指导教师 毕业设计(论文)原创性声明和使用授权说明 原创性声明 本人重承诺:所呈交的毕业设计(论文),是我个人在指导教师的指导下进行的研究工作及取得的成果。尽我所知,除文中特别加以标注和致谢的地方外,不包含其他人或组织已经发表或公布过的研究成果,也不包含我为获得及其它教育机构的学位或学历而使用过的材料。对本研究提供过帮助和做出过贡献的个人或集体,均已在文中作了明确的说明并表示了谢意。 作者签名:日期: 指导教师签名:日期: 使用授权说明 本人完全了解大学关于收集、保存、使用毕业设计(论文)的规定,即:按照学校要求提交毕业设计(论文)的印刷本和电子版本;学校有权保存毕业设计(论文)的印刷本和电子版,并提供目录检索与阅览服务;学校可以采用影印、缩印、数字化或其它复制手段保存论文;在不以赢利为目的前提下,学校可以公布论文的部分或全部容。 作者签名:日期: 科技学院本科毕业论文(设计)诚信声明 本人重声明:所呈交的本科毕业论文(设计),是本人在指导老师的指导下,独立进行研究工作所取得的成果,成果不存在知识产权争议,除文中已经注明引用的容外,本论文不含任何其他个人或集体已经发表或撰写过的作品成果。对本文的研究做出重要贡献的个人和集体均已在文中以明确方式标明。本人完全意识到本声明的法律结果由本人承担。 本科毕业论文(设计)作者签名: 二○○八年月日 matlab语音识别系统(源代码)最新版 目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6) 3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12) 一、设计任务及要求 用MATLAB实现简单的语音识别功能; 具体设计要求如下: 用MATLAB实现简单的数字1~9的语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。 一种汉语语音输入系统及其方法,用以将任意文句的汉语语音直接转换成相应的中文文字,该系统及其方法包括声音处理过程及语言解码过程两大部分。其特征在于声音处理过程利用“段落统计模型” 计算输入汉语语音的各单音节及声调的机率,进而辨识之;语言解码过程针对声音处理过程送来的一连串音节利用“词类双连中文语言模型”找出对应的中文字。一种包含“智慧型学习技术”的汉语听写机,用本方法将语音输入转换成文字显示。 技术要求 1、一种汉语语音输入方法,用以将任意文句的汉语语音直接转换成相对应的中文文字,该方法包括声音处理过程以及语言解码过程两大部分,其特征在于,该声音处理过程利用“段落统计模型”计算输入汉语语音的每一音节以及声调的机率,进而辨识之;该语言解码过程针对该声音处理过程送来的一连串音节,以“马可夫中文语言模型”找出所对应的中文字。 2、根据权利要求1的方法,其特征在于,其中该“马可夫中文语言模型”是以“词”为基础,但以“字”来计算机率的“马可夫中文语言模型”。 3、根据权利要求1的方法,其特征在于,其中该以“词”为基础,以“字”来计算机率的“马可夫中文语言模型”系将输入的音节串所对应的同音字一一分割为若干个词,但根据两两相连的词之间相连的词头字及词尾字相连出现的机率,并比较每一个词出现的频率及前后文关系判断该音节的字。 4、根据权利要求1的方法,其特征在于,其中该“段落统计模型”的训练方式包含下列步骤: (1)若某一单音节α的总长度为T个音框,则将该单音节分为N段,每一段含有T/N个音框; (2)使用者重覆念该单音节数次,长度虽不尽相同,但同样等分成N段; (3)将所有上述单音节的第一段音框的特征向量合在一起,训练成第一段的状态; (4)将所有上述单音节的第二段音框的特征向量混合在一起,训练成第二段的状态,依此类推,训练出N个状态; (5)上述每个状态以M个高斯机率混合来描述,以上述音框的特征向量训练各个高斯机率的参数;和 (6)上述M个状态即构成该音节α的“段落统计模型”。 孤立词语音识别程序 信息处理仿真实验语音处理部分 一、实验目的 按所学相关语音处理的知识,自己设计一个孤立词语音识别程序,分析所设计系统的特性。熟悉不同模块间如何进行有效的组合,以及模 块内的设计,重点掌握特征参数的提取和模式识别方法,并对不同的特 征参数提取方法和模式匹配方法有大概的了解,知道其不同的优缺点。 二、实验内容 1、熟悉预处理、特征参数提取、模式匹配三个模块的原理,并设计 这三个模块的matlab子程序。 2、设计主程序,将上述3个模块合理组合构成一个系统,训练模板并 测试。 三、实验原理及设计步骤 1、孤立词语音识别系统:先用端点检测将语音中有用的语音部分提取出来(即 将头部和尾部的静音部分除掉),然后提取语音信号的Mel尺度倒谱参数(MFCC),进行动态归整(DTW算法)后与模板库里面的标准语音作比较,具体流程如下: 图3.1孤立词语音识别系统 2、各模块解析 ⑴预处理:包括反混叠失真滤波器、预加重器、端点检测和噪声滤波器。这里 将预加重器和噪声滤波器放在下一个模块里,所以预处理主要进行端点检测以捕捉到数据中的语音信息。 端点检测采用双门限法来检测端点。同时,利用过零率检测清音,用短时能量检测浊音,两者配合。整个语音信号的端点检测可以分为四段:静音、过渡段、语音段、结束。程序中使用一个变量status来表示当前 所处的状态。 在静音段,如果能量或过零率超越了低门限,就应该开始标记起始点,进入过渡段。 在过渡段中,由于参数的数值比较小,不能确信是否处于真正的语音段,因此只要 两个参数的数值都回落到低门限以下,就将当前状态恢复到静音状态。 而如果在过渡段中两个参数中任意一个超过了高门限,就可以确信 进入语音段了。 一些突发性的噪声可以引发短时能量或过零率的数值很高,但是往往不 能维持足够长的时间,这些可以通过设定最短时间门限来判别。当 前状态处于语音段时,如果两个参数的数值降低到低门限以下,而 且总的计时长度小于最短时间门限,则认为这是一段噪音,继续扫 描以后的语音数据。否则就标记好结束端点,并返回 ⑵特征参数提取:常用的语音识别参数有线性预测参数(LPC),线性预测倒谱 参数(LPCC)和Mel 尺度倒谱参数(MFCC)等。这里提取语音信号的Mel 尺度倒谱参数(MFCC),步骤如下: 预 加 重汉明窗傅立叶变 换取模三角滤波函数组取对数离散余弦变换语音 信号MFCC 归一化导谱提升计算差分系数并合 并特征参数 图3.2特征参数提取 分析: ①预加重 ()()-0.97(1)y n x n x n =- ②加汉明窗 ()()()w x n y n w n =? ③ FFT 1 2/0()()N j nk N w w n X k x n e π--==∑ 这里直接采用现成的FFT 快速算法。 ④对频谱进行三角滤波 程序采用归一化mel 滤波器组系数 ⑤计算每个滤波器的输出能量 120()ln ()()0N w m k S m X k H k m M -=??=≤< ??? ∑ ⑥离散余弦变换(DCT)得到MFCC ()1()()cos (0.5)/1,2,...,M m C n S m n m M n p π==-=∑ 通常协方差矩阵一般取对角阵,三角滤波器组的对数能量输出之间 语音识别系统调研报告 姓名:罗小嘉学号:2801305018 1、摘要:本文简要的介绍了语音识别系统的原理,发展和在各个方面的应用前景。 2、关键词:语音识别;应用 3、引言:语音识别主要是指用机器在各种情况下,根据信息执行人的各种意图,有效地了解、识别语音和其它声音。它是近十几年来发展起来的具有理论价值和实用价值的新兴学科:从计算机大学科角度看,可视为智能计算机的智能接口;从信息处理学科来看,可视为信息识别的一个重要分支;从自动控制学科来看,又可视为模式识别的一个重要组成部分. 早在18 世纪,人们就对语音学进行了科学研究,但由于各种条件的限制,语音识别仅在计算机技术迅速发展之后,才成为一个非常活跃的研究领域. 60 年代末期,面对语音识别的种种困难,人们开始研究特定人、孤立词、小词汇量的识别,从而使语音识别的问题能够在当时的条件下得以开展;70年代后期,特定人、孤立词、小词汇量的语音识别取得较为满意的效果,语音识别的研究则沿着特定人向非特定人、孤立词向连续词、小词汇量向大词汇量方向扩展研究领域和目标;80 年代中期以来,计算机技术、信息技术及模式识别等技术的迅猛发展,极大地促进了语音识别技术的发展. 4、正文:语音识别系统要求能够实现实时语音识别。该语音识别系统的关键技术主要是语言实时识别技术、语音端点检测与声韵分割。如图: 对于语音端点检测与声韵分割的问题,从背景噪声中找出语音的开始和终止,这在语音处理中是很基本的问题,因为准确的端点检测,不仅可以提高识别精度,还可以避免计算噪声,减少计算量. 大多数语音处理系统采用过零率和能量两参数作端点检测. 但过零率受噪声影响较大,采用多门限过零率作语音起点检测,将能量信息直接反应在门限中,同时将分析窗长取小,使起点检测比较准确,效果较好. 语音识别技术的应用可以分为两个发展方向:一个方向是大词汇 开放实验项目报告 项目名称:语音识别机器人 专业 学生姓名 班级学号 指导教师 指导单位 2012/2013学年第一学期 一.设计背景 在科学日新月异的今天,电子设备的便捷化,人性化,智能化已成为不可逆转的潮流,而语音控制智能,更是其中研究发展的热点。凌阳SPCE061以其便捷的操作,可靠的性能,成为了各位电子爱好者的首选。本实验采用凌阳61板和运动小车(迷你型)模组设计的语音控制小车。凌阳板嵌入小车模型顶部。语音处理技术不仅包括语音的录制和播放,还涉及语音的压缩编码和解码、语音的识别等各种处理技术。本设计的语音控制小车,借助于SPCE061A在语音处理方面的特色,不仅具有前进、后退、左转、右转、停止等基本程序控制功能,而且还具备语音控制功能。 二.总流程图 三.主要模块 1、凌阳SPCE061是继μ’nSP?系列产品SPCE500A等之后凌阳科技推出的又一款16 位结构的微控制器。与SPCE500A不同的是,在存储器资源方面考虑到用户的较少资源的需求以及便于程序调试等功能,SPCE061A里只内嵌32K字的闪存(FLASH )。较高的处理速度使μ’nSP?能够非常容易地、快速地处理复杂的数字信号。因此,与SPCE500A相比,以μ’nSP?为核心的SPCE061A 微控制器是适用于数字语音识别应用领域产品的一种最经济的选择。 其性能如下: A、16 位μ’nSP?微处理器; B、工作电压(CPU) VDD 为2.4~3.6V (I/O) VDDH 为2.4~5.5V C、CPU 时钟:0.32MHz~49.152MHz ; D、内置2K 字SRAM; E、内置32K FLASH; F、可编程音频处理; G、晶体振荡器; H、系统处于备用状态下(时钟处于停止状态),耗电仅为2μA@3.6V ; I、2 个16 位可编程定时器/计数器(可自动预置初始计数值); J、2 个10 位DAC(数-模转换)输出通道; K、32 位通用可编程输入/输出端口; L、14 个中断源可来自定时器A / B ,时基,2 个外部时钟源输入,键唤醒; 用于孤立词识别的语音识别系统实验报告 语音是人际交流的最习惯、最自然的方式,它将成为让计算机智能化地与人通信,人机自然地交互的理想选择。让说话代替键盘输入汉字,其技术基础是语音识别和理解。语音识别将人发出的声音、音节、或短语转换成文字和符号,或给出响应执行控制,作出回答。 该系统用于数字0~9的识别,系统主要包括训练和识别两个阶段。实现过程包括对原始语音进行预加重、分帧、加窗等处理,提取语音对应的特征参数。在得到了特征参数的基础上,采用模式识别理论的模板匹配技术进行相似度度量,来进行训练和识别。在进行相似度度量时,采用DTW 算法对特征参数序列重新进行时间的对准。 一、 特征提取 1、端点检测 利用短时平均幅度和短时过零率进行端点检测,以确定语音有效范围 的开始和结束位置。 首先利用短时平均幅度定位语音的大致位置。做法为:(1)确定一个 较高的阈值MH,短时平均幅度大于MH 的部分一定是语音段。(2)分别沿这一语音段向两端搜索,大于某个阈值ML 的部分还是语音段,这样能较为准确地确定语音的起始点,将清音与无声段分开。因为清音的过零率远远高于无声段,确定一个过零率的阈值Z min , 从ML 确定的语音段向前搜 索不超过一帧的长度,短时过零率突然低于Z min 三倍的点被认为是语音的 起始点。 2、预加重 对输入的原始语音进行预加重,其目的是为了对语音的高频部分进行加重,增加语音的高频分辨率。假设在n 时刻的语音采样值为x(n),则经过预加重处理后的结果为: y(n)=x(n)+αx(n-1) α=0.98 3、分帧及加窗 语音具有短时平稳的特点,通过对语音进行分帧操作,可以提取其短时特性,便于模型的建立。帧长取为30ms ,帧移取为10ms ,然后将每帧信号用Hamming 窗相乘,以减小帧起始和结束处的信号不连续性。Hamming 窗函数为: w(n)=0.54-0.46cos(1 2-N n π) (0≤n ≤N-1) 该系统中,hamming 窗的窗长N 取为240。 设原始信号为s(n),加窗后为: 实验一 语音信号的时域分析 一、 实验目的、要求 (1)掌握语音信号采集的方法 (2)掌握一种语音信号基音周期提取方法 (3)掌握语音信号短时能量和短时过零率计算方法 (4)了解Matlab 的编程方法 二、 实验原理 语音是一时变的、非平稳的随机过程,但由于一段时间内(10-30ms)人的声带和声道形状的相对稳定性,可认为其特征是不变的,因而语音的短时谱具有相对稳定性。在语音分析中可以利用短时谱的这种平稳性,将语音信号分帧。 10~30ms 相对平稳,分析帧长一般为20ms 。 语音信号的分帧是通过可移动的有限长度窗口进行加权的方法来实现的。几种典型的窗函数有:矩形窗、汉明窗、哈宁窗、布莱克曼窗。 语音信号的能量分析是基于语音信号能量随时间有相当大的变化,特别是清音段的能量一般比浊音段的小得多。定义短时平均能量 [][]∑∑+-=∞-∞=-=-= n N n m m n m n w m x m n w m x E 122)()()()( 下图说明了短时能量序列的计算方法,其中窗口采用的是直角窗。 过零就是信号通过零值。对于连续语音信号,可以考察其时域波形通过时间轴的情况。而对于离散时间信号,如果相邻的取样值改变符号则称为过零。由此可以计算过零数,过零数就是样本改变符号的次数。单位时间内的过零数称为平 均过零数。 语音信号x (n )的短时平均过零数定义为 ()[]()[]()()[]()[]() n w n x n x m n w m x m x Z m n *--=---= ∑∞ -∞=1sgn sgn 1sgn sgn 式中,[]?sgn 是符号函数,即 ()[]()()()()???<-≥=01 01sgn n x n x n x 短时平均过零数可应用于语音信号分析中。发浊音时,尽管声道有若干个共振峰,但由于声门波引起了谱的高频跌落,所以其语音能量约集中干3kHz 以下。而发清音时.多数能量出现在较高频率上。既然高频率意味着高的平均过零数,低频率意味着低的平均过零数,那么可以认为浊音时具有较低的平均过零数,而清音时具有较高的平均过零数。然而这种高低仅是相对而言,没有精确的数值关系。 短时平均过零的作用 1.区分清/浊音: 浊音平均过零率低,集中在低频端; 清音平均过零率高,集中在高频端。 2.从背景噪声中找出是否有语音,以及语音的起点。 基音是发浊音时声带震动所引起的周期性,而基音周期是指声带震动频率的倒数。基音周期是语音信号的重要的参数之一,它描述语音激励源的一个重要特征,基音周期信息在多个领域有着广泛的应用,如语音识别、说话人识别、语音分析与综合以及低码率语音编码,发音系统疾病诊断、听觉残障者的语音指导等。因为汉语是一种有调语言,基音的变化模式称为声调,它携带着非常重要的具有辨意作用的信息,有区别意义的功能,所以,基音的提取和估计对汉语更是一个十分重要的问题。 由于人的声道的易变性及其声道持征的因人而异,而基音周期的范围又很宽,而同—个人在不同情态下发音的基音周期也不同,加之基音周期还受到单词发音音调的影响,因而基音周期的精确检测实际上是一件比较困难的事情。基音提取的主要困难反映在:①声门激励信号并不是一个完全周期的序列,在语音的 第24卷 第2期 2007年6月 河 北 省 科 学 院 学 报Journal of the Hebei Academy of Sciences Vol .24No .2June 2007 文章编号:1001-9383(2007)02-0008-04 基于离散隐马尔科夫模型的语音识别技术 高清伦,谭月辉,王嘉祯 (军械工程学院计算机工程系,河北石家庄 050003) 摘要:概述语音识别技术的基本原理,对当前三种主要识别技术———动态时间规整技术、隐含马尔科夫模型 技术及人工神经网络技术进行比较,重点介绍基于离散隐马尔科夫模型(DH MM )的语音识别系统的实现。关键词:语音识别;隐马尔科夫模型;动态时间规整;人工神经网络中图分类号:T N912.34 文献标识码:A Speech recogn iti on technology ba sed on d iscrete H MM GAO Q ing 2l un,TAN Yue 2hu i,WAN G J i a 2zhen (D epart m ent of Co m puter Engineering,O rdnance Engineering College,Shijiazhuang Hebei 050003,China ) Abstract:The conditi on and the basic p rinci p le of s peech recogniti on technol ogy are intr oduced,three differ 2ent kinds of s peech recogniti on syste m s such as DT W ,H MM ,ASR are compared,and p lace e mphasis on how t o realize DH MM in s peech recogniti on syste m is p resented e mphatically . Keywords:Speech recogniti on;H idden Markov Model (H MM );Dyna m ic Ti m e W ar p ing (DT W );A rtificial Neural Net w ork (ANN ) 语音识别技术是语音信号处理技术一个重要的研究方向,是让机器通过识别和理解过程把人 类的语音信号转变为相应的文本或命令的技术,它属于多维模式识别和智能计算机接口的范畴,涉及到声学、语音学、语言学、计算机科学、信号与信息处理和人工智能等诸多学科,是21世纪衡量一个国家信息科学技术发展水平的重要标准之一。 1语音识别技术概述 语音识别系统本质上是一种模式识别系统, 目前有很多语音识别算法,但其基本原理和基本 技术相似。一个完整的语音识别系统一般都包括有特征提取、模式匹配和参考模式库3个基本单元,它的基本结构如图1所示。 (1)特征提取 所谓特征提取就是从语音信号中提取用于语 音识别的有用信息,其基本思想是将预处理过的信号通过一次变换,去掉冗余部分,而把代表语音本质特征的参数抽取出来,如平均能量、平均跨零率、共振峰、LPC 系数、MFCC 系数等。 图1语音识别系统基本结构 (2)模式匹配 这是整个语音识别系统的核心,它是根据一定规则(如H MM )以及专家知识(如构词规则、语法规则、语义规则等),计算输入特征与参考模式 3收稿日期:2007-01-26 作者简介:高清伦(1976-),男,河北沧州人,硕士,主要从事信息工程理论应用方面的研究. 通信工程学院12级1班罗恒2012101032 实验一语音信号的低通滤波和短时分析综合实验 一、实验要求 1、根据已有语音信号,设计一个低通滤波器,带宽为采样频率的四分之一,求输出信号; 2、辨别原始语音信号与滤波器输出信号有何区别,说明原因; 3、改变滤波器带宽,重复滤波实验,辨别语音信号的变化,说明原因; 4、利用矩形窗和汉明窗对语音信号进行短时傅立叶分析,绘制语谱图并估计基音周期,分析两种窗函数对基音估计的影响; 5、改变窗口长度,重复上一步,说明窗口长度对基音估计的影响。 二、实验目的 1.在理论学习的基础上,进一步地理解和掌握语音信号低通滤波的意义,低通滤波分析的基本方法。 2.进一步理解和掌握语音信号不同的窗函数傅里叶变化对基音估计的影响。 三、实验设备 1.PC机; 2.MATLAB软件环境; 四、实验内容 1.上机前用Matlab语言完成程序编写工作。 2.程序应具有加窗(分帧)、绘制曲线等功能。 3.上机实验时先调试程序,通过后进行信号处理。 4.对录入的语音数据进行处理,并显示运行结果。 5. 改变滤波带宽,辨别与原始信号的区别。 6.依据曲线对该语音段进行所需要的分析,并且作出结论。 7.改变窗的宽度(帧长),重复上面的分析内容。 五、实验原理及方法 利用双线性变换设计IIR滤波器(巴特沃斯数字低通滤波器的设计),首先要设计出满足指标要求的模拟滤波器的传递函数Ha(s),然后由Ha(s)通过双线性变换可得所要设计的IIR滤波器的系统函数H(z)。如果给定的指标为数字滤波器的指标,则首先要转换成模拟滤波器的技术指标,这里主要是边界频率Wp和Ws 的转换,对ap和as指标不作变化。边界频率的转换关系为∩=2/T tan(w/2)。接着,按照模拟低通滤波器的技术指标根据相应设计公式求出滤波器的阶数N和3dB截止频率∩c ;根据阶数N查巴特沃斯归一化低通滤波器参数表,得到归一化传输函数Ha(p);最后,将p=s/ ∩c 代入Ha(p)去归一,得到实际的模拟滤波器传输函数Ha(s)。之后,通过双线性变换法转换公式s=2/T((1-1/z)/(1+1/z))得到所要设计的IIR滤波器的系统函数H(z)。 信息处理仿真实验语音处理部分 一、实验目的 按所学相关语音处理的知识,自己设计一个孤立词语音识别程序,分析所设计系统的特性。熟悉不同模块间如何进行有效的组合,以及模块的设计,重点掌握特征参数的提取和模式识别方法,并对不同的特征参数提取方法和模式匹配方法有大概的了解,知道其不同的优缺点。 二、实验容 1、熟悉预处理、特征参数提取、模式匹配三个模块的原理,并设计这三个模块的matlab子程序。 2、设计主程序,将上述3个模块合理组合构成一个系统,训练模板并测试。 三、实验原理及设计步骤 1、孤立词语音识别系统:先用端点检测将语音中有用的语音部分提取出来 (即将头部和尾部的静音部分除掉),然后提取语音信号的Mel尺度倒谱参数(MFCC),进行动态归整(DTW算法)后与模板库里面的标准语音作比较,具体流程如下: 图3.1孤立词语音识别系统 2、各模块解析 ⑴预处理:包括反混叠失真滤波器、预加重器、端点检测和噪声滤波器。 这里将预加重器和噪声滤波器放在下一个模块里,所以预处理主要进行端点检测以捕捉到数据中的语音信息。 端点检测采用双门限法来检测端点。同时,利用过零率检测清音,用短时能量检测浊音,两者配合。整个语音信号的端点检测可以分为四段:静音、过渡段、语音段、结束。程序中使用一个变量status来表示当前所处的状态。 在静音段,如果能量或过零率超越了低门限,就应该开始标记起始点,进 入过渡段。 在过渡段中,由于参数的数值比较小,不能确信是否处于真正的语音段,因此只要 两个参数的数值都回落到低门限以下,就将当前状态恢复到静音状态。 而如果在过渡段中两个参数中任意一个超过了高门限,就可以确信进入语 音段了。 语音控制小车实验报告 专业: 学号: 姓名: 2014年01月12日 一、实验目的 语音控制小车以SPCE061A单片机为核心,采用语音识别技术,可通过语音命令对其行驶状态进行控制。本次实验的主要目的: 1.通过简单的I/O 操作实现小车的前进、后退、左转、右转功能; 2.配合SPCE061A 的语音特色,利用系统的语音播放和语音识别资源,实现语音控制的功能; 3.在行走过程中声控改变小车运动状态; 4.在超出语音控制范围时使小车停车。 二、实验内容 1、SPCE061A简介 SPCE061A是一款性价比很高的十六位单片机,使用它可以非常方便灵活的实现语音的录放,该芯片拥有8路10位精度的ADC,其中一路为音频转换通道,并且内置有自动增益电路。这为实现语音录入提供了方便的硬件条件。两路10位精度的DAC,只需要外接功放(SPY0030A)即可完成语音的播放。该单片机具有一套易学易用的指令系统和集成开发环境,在此环境中,它支持标准 C 语言编程,也支持 C 语言与汇编语言的互相调用。另外还提供了语音录放的库函数,只要了解库函数的使用,就可以很容易的完成语音的录放、识别等功能,这些都为软件开发提供了方便的条件。 SPCE061A特性: 16位μ’nSP微处理器; 工作电压:内核工作电压VDD为 3.0V~3.6V(CPU),I/O口工作电压VDDH为VDD~5.5V(I/O); CPU时钟:0.32MHz~49.152MHz; 内置2K 字 SRAM; 内置32K 闪存 ROM; 可编程音频处理; 晶体振荡器; 系统处于备用状态下(时钟处于停止状态),耗电小于 2μA@3.6V; 2 个 16 位可编程定时器/计数器(可自动预置初始计数值); 2 个 10 位 DAC(数-模转换)输出通道; 32 位通用可编程输入/输出端口; 基于Microsoft Speech SDK实现用户孤立词识别的过程如下: 1、初始化COM端口:在CWinApp的子类中,调用CoInitializeEx函数进行COM 初始化:::CoInitializeEx(NULL,COINIT_APARTMENTTHREADED); 2、创建识别引擎:微软Speech SDK 5.1 支持两种模式的:共享(Share)和独享(InProc)。一般情况下可以使用共享型,大的服务型程序使用InProc。如下:hr = m_cpRecognizer.CoCreateInstance(CLSID_SpSharedRecognizer);//Share hr = m_cpRecognizer.CoCreateInstance(CLSID_SpInprocRecognizer);//InProc 如果是Share型,直接到步骤3;如果是InProc型,必须使用ISpRecognizer::SetInput 设置输入:CComPtr 《语音识别输入软件》(Dragon NaturallySpeaking 10 SP1、10.1)[光盘镜像] Dragon NaturallySpeaking 10 Dragon Naturally Speaking 10 Preferred gives small business and advanced PC users the power to create documents, reports and emails three times faster than most people type —with up to 99% accuracy. Surf the Web by voice or dictate and edit in Microsoft Word and Excel, Corel WordPerfect, and most other Windows-based applications. Create voice commands to quickly insert blocks of texts or images —such as your name, title, and signature. Dictate into a handheld device when you're away from your PC, or use a Bluetooth microphone for the same great dictation results without the wires. A high-quality headset is included. 请大家看清自己的操作系统选择合适自己的对应版本!该版本软件不支持中文语音输入《语音识别输入软件》软件售价:249.99美元 专业工作人员每天都在为完成创建文档、编写邮件、完成表格以及流线型工作任务而忙碌着,现在,拥有了Dragon NaturallySpeaking Professional 9,您只需开口说话就可以完成以上任务!Dragon Naturally Speaking 速度为动手输入字符速度的三倍,而且准确率高达99%。对着您的电脑讲话,您说的话会立即在office文件、IE浏览器、Corel WordPerfect软件、Lotus Notes 系统或其他基于Windows操作系统的应用程序上显示。您还可以创建语音命令,同时进行多种计算机任务,由此而知,您将节约多少时间!Dragon Naturally Speaking Professional 9经Section 508检验完全合格,并为身有残疾的使用者创造了完全脱离手工操作使用个人计算机的机会。Dragon Naturally Speaking Professional 9 同时也含有多种可供选择的网络部署的工具,如支持Citrix瘦客户机必需设施的配置。 您想象不到的准确率 Dragon Naturally Speaking Professional 9实现了前所未有的准确率,甚至比打字都要准确。Dragon Naturally Speaking 从来没有出现过拼写错误,而且,事实上,使用次数越多,Dragon NaturallySpeaking 就越灵活,其准确率越高。 快于打字的速度! 大多数人说话的速度为每分钟120个字,而打字的速度每分钟少于40个字,Dragon Naturally Speaking 的速度将近手工输入字符速度的三倍! 使用简易 您马上就可以通过声音来进行信笺、邮件的完成以及进行网上冲浪,不再需要从输入可读字符来开始这一切了。随软件我们附赠事业能够指南和Nuance认可的完全隔离噪音的麦克风。 语音识别技术在物流中的应用 语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产业。 1、语音识别的基本原理 语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示: 未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。 2、语音识别技术的发展历史及现状 1952年,AT&TBell实验室的Davis等人研制了第一个可十个英文数字的特定人语音增强系统一Audry系统1956年,美国普林斯顿大学RCA实验室的Olson和Belar等人研制出能10个单音节词的系统,该系统采用带通滤波器组获得的频谱参数作为语音增强特征。1959年,Fry和Denes等人尝试构建音素器来4个元音和9个辅音,并采用频谱分析和模式匹配进行决策。这就大大提高了语音识别的效率和准确度。从此计算机语音识别的受到了各国科研人员的重视并开始进入语音识别的研究。60年代,苏联的Matin等提出了语音结束点的端点检测,使语音识别水平明显上升;Vintsyuk提出了动态编程,这一提法在以后的识别中不可或缺。60年代末、70年代初的重要成果是提出了信号线性预测编码(LPC)技术和动态时间规整(DTW)技术,有效地解决了语音信号的特征提取和不等长语音匹配问题;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。语音识别技术与语音合成技术结合使人们能够摆脱键盘的束缚,取而代之的是以语音输入这样便于使用的、自然的、人性化的输入方式,它正逐步成为信息技术中人机接口的关键技术。 3、语音识别的方法 模拟电子技术课程设计 语 音 放 大 器 姓名:伍慧兰 学号:2015550828 班级:15通信工程1班 指导老师:罗光明 目录 一、设计目的 (2) 二、知识点和设计内容 (2) 三、设计方案 (3) 四、实验原理与参考电路 (4) (一)实验原理图如图1-2 (4) (二)实验原理 (5) 1) 前置放大器 (5) 2) 有源带通滤波器 (5) 3) 功率放大器 (6) 五、实验的主要元器件 (7) (一)元器件清单 (7) (二)部分器件的使用介绍 (8) 1) LM324芯片 (8) 2) TDA2030引脚图与应用电路参数 (12) 六、实验步骤 (13) (一)电路仿真实验 (13) (二)硬件实物实验 (19) 1) 前置放大器的焊接与调试 (19) 2) 有源带通滤波器 (20) 七、实验中的问题提出与解决方法 (24) 八、注意事项 (25) 九、实验感想 (26) 参考资料 (27) 语音放大器设计 一、设计目的 1、了解语音识别知识; 2、掌握集成运算放大器的工作原理及其应用; 3、掌握低频小信号放大电路、带通滤波器和功放电路的设计方法; 4、培养应用现代工具对模拟电子系统进行仿真测试、制作调试、故障检查及分析的能力; 5、培养市场素质、工艺素质、自主学习能力、分析问题解决问题的能力以及团队精神; 6、培养文献查阅与综述和撰写课程设计报告的能力。 二、知识点和设计内容 本实验的知识点为分立元件放大器或集成运放、有源滤波器、集 成功率放大器;涉及电子电路各个模块之间的联合调试技术。 三、设计方案 语音放大器设计的基本设计思路 分析可知本语音放大器应包括输入电路、前置放大器、有源带通滤波器、功率放大器、扬声器等几部分组成,如图1-1所示。 前置放大器可采用集成运算放大器,有源带通滤波器可采用LPF 和HPF 串联构成,功率放大电路选用集成功放。 设计的性能指标 通常语音信号非常微弱,需要经过放大、滤波、功率放大后才能驱动扬声器发声。假设语音信号为峰峰值不大于10mV 频率范围100Hz~3kHz 的正弦波,要求驱动8Ω1W 的扬声器。具体性能指标如下: 1、前置放大器:输入信号Uid ≤10mV ;输入阻抗Ri ≥100k Ω 2、有源带通滤波器:通带100Hz~3kHz ;增益Au=1 3、功放:最大不失真输出功率Pomax ≥1W ;负载阻抗R L =8Ω 4、输出功率连续可调;直流输出电压≤50mV ;静态电源电流≤100mA 输入 电路 前置 放大 带通 滤波 功率 放大 图1-1 语音放大电路原理框图语音识别系统实验报告材料
语音识别输入系统
特定人孤立词语音识别的研究毕业论文
matlab语音识别系统(源代码)最新版
中文电脑的汉语语音输入系统及其方法与制作流程
孤立词语音识别程序
语音识别系统调研报告
语音识别机器人实验报告
用于孤立词识别的语音识别系统实验报告
语音信号处理实验报告11
基于离散隐马尔科夫模型的语音识别技术
语音信号处理实验报告实验一
孤立词语音识别程序文件
语音控制小车实验报告
Microsoft Speech SDK孤立词语音识别
语音识别输入软件
语音识别技术在物流中的应用
语音放大器设计实验报告
相关主题
文本预览