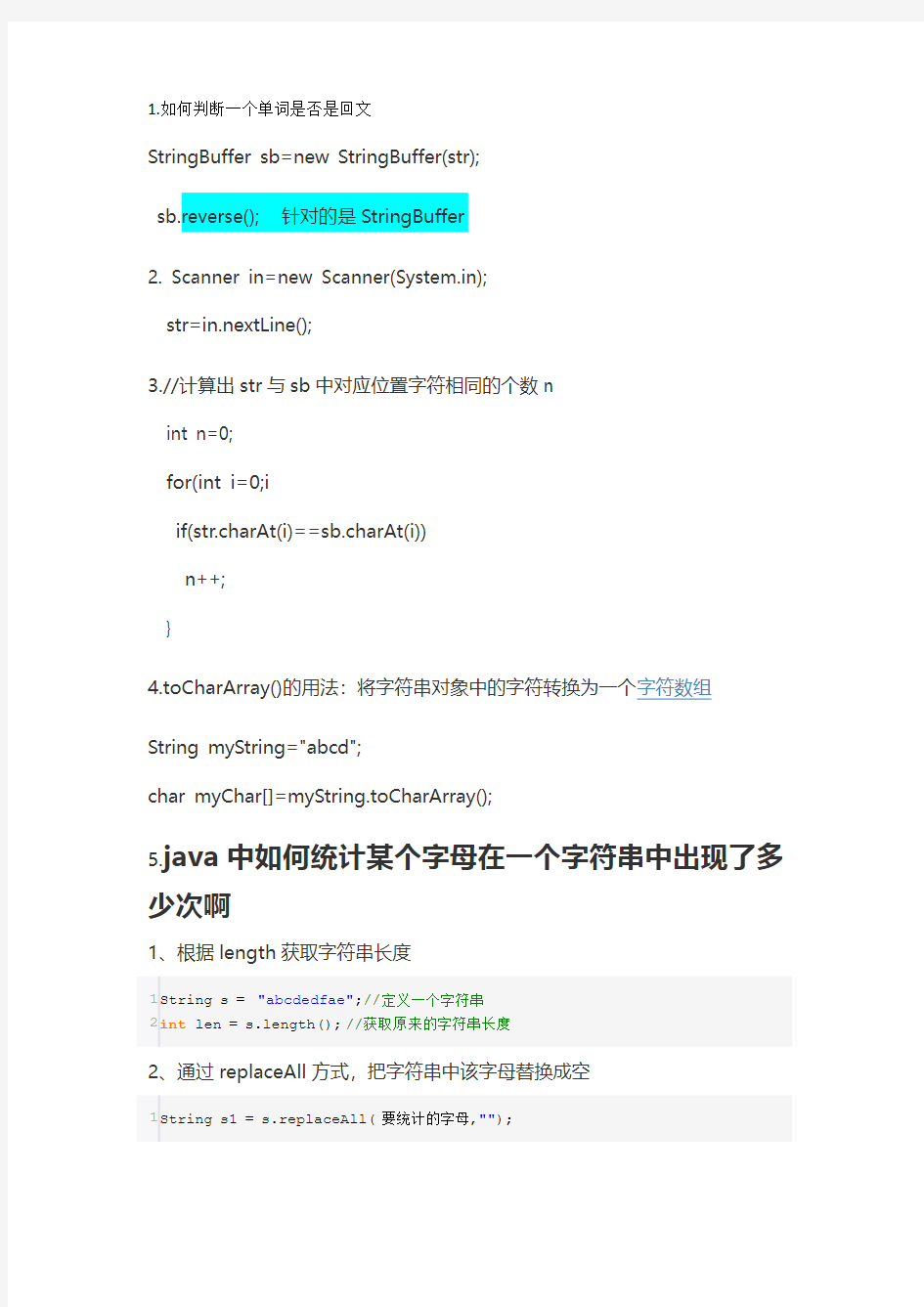

1.如何判断一个单词是否是回文 StringBuffer sb=new StringBuffer(str);
sb.reverse(); 针对的是StringBuffer
2. Scanner in=new Scanner(System.in);
str=in.nextLine();
3.//计算出str 与sb 中对应位置字符相同的个数n
int n=0;
for(int i=0;i if(str.charAt(i)==sb.charAt(i)) n++; } 4.toCharArray()的用法:将字符串对象中的字符转换为一个字符数组 String myString="abcd"; char myChar[]=myString.toCharArray(); 5.java 中如何统计某个字母在一个字符串中出现了多少次啊 1、根据length 获取字符串长度 1 2 String s = "abcdedfae";//定义一个字符串 int len = s.length();//获取原来的字符串长度 2、通过replaceAll 方式,把字符串中该字母替换成空 1 S tring s1 = s.replaceAll(要统计的字母,""); 3、获取替换后的字符串长度 1 i nt len 2 = s1.length(); 4、原来的字符串长度减去替换后的字符串长度就是该字母出现的次数 1 i nt lenTimes = len1-len2;//出现的次数 6.用java编写一个函数,统计一个字符串中每个字母出现的次数 String str ="2342asfghgyu56asdasda"; Map for(int i=0;i String key = String.valueOf((str.charAt(i))); if(!maps.containsKey(key)) maps.put(key, 1); else{ int val =maps.get(key); maps.put(key, val+1); } } for(Map.Entry i : maps.entrySet()){ System.out.println(i.getKey()+ "=="+i.getValue()); } String str = "jdsalfjaslnzdfuawoejlljafd"; int max = 0; Map for(char chr : str.toCharArray()) { Integer i = map.get(chr); int value = (i == null) ? 0: i; // 获取,没有则0,有则叠加 map.put(chr, ++value); max = value > max ? value : max; // 更新max } System.out.println(max); String s = "adfoweyirlkbasgxalueralsdhg"; // 待统计字符串 int max = 0; // 记录最大出现次数 int[] cnt = new int[127]; // 临时计数用的数组 for(int i = 0; i < s.length(); i++) { // 循环字符以做统计 char c = s.charAt(i); // 取出单个字母 max = (++cnt[c] > max) ? cnt[c] : max; // 计数并检测最大出现次数 } System.out.println (max); 7.toString()和String.valueOf()区别: String.valueOf()做了非空的判断可以避免空指针的出现 public static String valueOf(Object obj) { return(obj == null) ? "null": obj.toString(); } 8.排序算法: 9.不利用临时变量,进行两个整数的交换 A=2,b=4 输出a=4,b=2 A=a+b-a; B=b+a-b; 10.随机生成制定长度的字符串 11. 算法初步与框图 一、知识网络 二、考纲要求 1.算法的含义、程序框图 (1)了解算法的含义,了解算法的思想. (2)理解程序框图的三种基本逻辑结构:顺序、条件分支、循环. 2.基本算法语句 理解几种基本算法语句――输入语句、输出语句、赋值语句、条件语句、循环语句的含义. 三、复习指南 本章是新增内容,多以选择题或填空题形式考查,常与数列、函数等知识联系密切.考查的重点是算法语句与程序框图,以基础知识为主,如给出程序框图或算法语句,求输出结果或说明算法的功能;或写出程序框图的算法语句,判断框内的填空等考查题型.难度层次属中偏低. 第一节 算法与程序框图 ※知识回顾 1 2.. 3. 4. 5.算法的基本特征:①明确性:算法的每一步执行什么是明确的;②顺序性:算法的“前一步”是“后一步”的前提,“后一步”是“前一步”的继续;③有限性:算法必须在有限步内完成任务,不能无限制的持续进行;④通用性:算法应能解决某一类问题. ※典例精析 例1.如图所示是一个算法的程序框图,则该程序框图所表示的功能是 解析:首先要理解各程序框的含义,输入a,b,c三个数之后,接着判断a,b的大小,若b小,则把b赋给a,否则执行下一步,即判断a与c的大小,若c小,则把c赋给a, 否则执行下一步,这样输出的a是a,b,c三个数中的最小值.所以该程序框图所表示的功能是求a,b,c三个数中的最小值. 评注: 求a,b,c三个数中的最小值的算法设计也可以用下面程序框图来表示. 例2.下列程序框图表示的算法功能是() (1)计算小于100的奇数的连乘积 (2)计算从1开始的连续奇数的连乘积 (3)计算从1开始的连续奇数的连乘积, 当乘积大于100时,计算奇数的个数 (4)计算L≥ 1×3×5××n100成立时n的最小值 解析:为了正确地理解程序框图表示的算法,可以将执行过程分解,分析每一步执行的结果.可以看出程序框图中含有当型的循环结构,故分析每一次循环的情况,列表如下: 第一次:13,5 =?=; S i 第二次:135,7 =??=; S i 第三次:1357,9 S<不成立,输出结果是7,程序框图表示的算法功能是求使=???=,此时100 S i 前端思维导图 42 npm模块安装机制 npm 是 Node 的模块管理器,功能极其强大;它是 Node 获得成功的重要原因之一;正因为有了npm,我们只要一行命令,就能安装别人写好的模块 参考 1参考 2 41 js检测数据类型 Javascript 有两种数据类型,分别是基本数据类型(6种)和引用数据类型 参考 1 40 SPA 靳肖健 单页面应用 39 sass 世界上最成熟、最稳定、最强大的专业级CSS扩展语言! 参考 1参考 2 38 使用键的集合对象 Map/Set/WeakMap/WeakSet 均为js标准内置对象;用于储存特别结构数据这些集合对象在存储数据时会使用到键,支持按照插入顺序来迭代元素 靳肖健 参考 1参考 2 37 前端优先遍历 JavaScript深度优先遍历和广度优先遍历 参考 1参考 2 36 NUXT Nuxt.js 是一个基于 Vue.js 的通用应用框架;他预设了利用 Vue.js 开发服务端渲染的应用所需要的各种配置 参考 1参考 2 35 vuex Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式;它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化靳肖健 参考 1 34 严格模式 es5的严格模式是采用具有限制性JavaScript变体的一种方式 参考 1 33 模型与视图 设计模式是对在某种环境中反复出现的问题以及解决该问题的方案的描述;mv*设计模式被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中 各种排序算法的总结和比较 1 快速排序(QuickSort) 快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序可以由下面四步组成。 (1)如果不多于1个数据,直接返回。 (2)一般选择序列最左边的值作为支点数据。(3)将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。 (4)对两边利用递归排序数列。 快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。 2 归并排序(MergeSort) 归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。 3 堆排序(HeapSort) 堆排序适合于数据量非常大的场合(百万数据)。 堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。 堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。 Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。 Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。 5 插入排序(InsertSort) 插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。 数学建模常用的十种解题方法 摘要 当需要从定量的角度分析和研究一个实际问题时,人们就要在深入调查研究、了解对象信息、作出简化假设、分析内在规律等工作的基础上,用数学的符号和语言,把它表述为数学式子,也就是数学模型,然后用通过计算得到的模型结果来解释实际问题,并接受实际的检验。这个建立数学模型的全过程就称为数学建模。数学建模的十种常用方法有蒙特卡罗算法;数据拟合、参数估计、插值等数据处理算法;解决线性规划、整数规划、多元规划、二次规划等规划类问题的数学规划算法;图论算法;动态规划、回溯搜索、分治算法、分支定界等计算机算法;最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法;网格算法和穷举法;一些连续离散化方法;数值分析算法;图象处理算法。 关键词:数学建模;蒙特卡罗算法;数据处理算法;数学规划算法;图论算法 一、蒙特卡罗算法 蒙特卡罗算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必用的方法。在工程、通讯、金融等技术问题中, 实验数据很难获取, 或实验数据的获取需耗费很多的人力、物力, 对此, 用计算机随机模拟就是最简单、经济、实用的方法; 此外, 对一些复杂的计算问题, 如非线性议程组求解、最优化、积分微分方程及一些偏微分方程的解⑿, 蒙特卡罗方法也是非常有效的。 一般情况下, 蒙特卜罗算法在二重积分中用均匀随机数计算积分比较简单, 但精度不太理想。通过方差分析, 论证了利用有利随机数, 可以使积分计算的精度达到最优。本文给出算例, 并用MA TA LA B 实现。 1蒙特卡罗计算重积分的最简算法-------均匀随机数法 二重积分的蒙特卡罗方法(均匀随机数) 实际计算中常常要遇到如()dxdy y x f D ??,的二重积分, 也常常发现许多时候被积函数的原函数很难求出, 或者原函数根本就不是初等函数, 对于这样的重积分, 可以设计一种蒙特卡罗的方法计算。 定理 1 )1( 设式()y x f ,区域 D 上的有界函数, 用均匀随机数计算()??D dxdy y x f ,的方法: (l) 取一个包含D 的矩形区域Ω,a ≦x ≦b, c ≦y ≦d , 其面积A =(b 一a) (d 一c) ; ()j i y x ,,i=1,…,n 在Ω上的均匀分布随机数列,不妨设()j i y x ,, j=1,…k 为落在D 中的k 个随机数, 则n 充分大时, 有 数学建模10种常用算法 1、蒙特卡罗算法(该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必用的方法) 2、数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具) 3、线性规划、整数规划、多元规划、二次规划等规划类问 题(建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现) 4、图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备) 5、动态规划、回溯搜索、分治算法、分支定界等计算机算法(这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中) 6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用) 7、网格算法和穷举法(网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具) 8、一些连续离散化方法(很多问题都是实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的) 9、数值分析算法(如果在比赛中采用高级语言进行 编程的话,那一些数值分析中常用的算法比如方程组 求解、矩阵运算、函数积分等算法就需要额外编写库 函数进行调用) 10、图象处理算法(赛题中有一类问题与图形有关, 即使与图形无关,论文中也应该要不乏图片的,这些 图形如何展示以及如何处理就是需要解决的问题,通 常使用Matlab进行处 参数估计 C.F. 20世纪60年代,随着电子计算机的 。参数估计有多种方法,有最小二乘法、极大似然法、极大验后法、最小风险法和极小化极大熵法等。在一定条件下,后面三个方法都与极大似然法相同。最基本的方法是最小二乘法和极大似然法. 基本介绍 参数估计(parameter 尽可能接近的参数 误差 平方和 θ,使已知数据Y 最大,这里P(Y│θ)是数据Y P(Y│θ)。在实践中这是困难的,一般可假设P(Y│θ 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MA TLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的插值计算,还有吵的沸沸扬扬可能会考的“非典”问题也要用到数据拟合算法,观察数据的 将整个网站安排频道或者分类进行拆分,比如 首页,内容页,文字列表页,图片列表页,频道1页面,频道2页面,分类1页面,分类2页面,后台管理页面,等等 3. 每个网站作为一个模块。比如 商城站,支付站,论坛,三个站独立为三个大模块。 模块化实现 1. 高度耦合提取为一个模块,将模块代码作用域进行控制 代码1.非继承模块,通过后代选择符方式控制作用域 .mod {} .mod .title {} .mod .con {} .mod .more {} .note {} .note .title {} .note .con {} .note .more {} 算法初步比较经典的教案
前端思维导图
各种排序算法的总结和比较
数学建模常用的十种解题方法
数学建模10种常用算法
数学建模中常见的十大模型
前端模块化设计思路
常见内部排序算法比较 排序算法是数据结构学科经典的内容,其中内部排序现有的算法有很多种,究竟各有什么特点呢?本文力图设计实现常用内部排序算法并进行比较。分别为起泡排序,直接插入排序,简单选择排序,快速排序,堆排序,针对关键字的比较次数和移动次数进行测试比较。 问题分析和总体设计 ADT OrderableList { 数据对象:D={ai| ai∈IntegerSet,i=1,2,…,n,n≥0} 数据关系:R1={〈ai-1,ai〉|ai-1, ai∈D, i=1,2,…,n} 基本操作: InitList(n) 操作结果:构造一个长度为n,元素值依次为1,2,…,n的有序表。Randomizel(d,isInverseOrser) 操作结果:随机打乱 BubbleSort( ) 操作结果:进行起泡排序 InserSort( ) 操作结果:进行插入排序 SelectSort( ) 操作结果:进行选择排序 QuickSort( ) 操作结果:进行快速排序 HeapSort( ) 操作结果:进行堆排序 ListTraverse(visit( )) 操作结果:依次对L种的每个元素调用函数visit( ) }ADT OrderableList 待排序表的元素的关键字为整数.用正序,逆序和不同乱序程度的不同数据做测试比较,对关键字的比较次数和移动次数(关键字交换计为3次移动)进行测试比较.要求显示提示信息,用户由键盘输入待排序表的表长(100-1000)和不同测试数据的组数(8-18).每次测试完毕,要求列表现是比较结果. 要求对结果进行分析.
详细设计 1、起泡排序 算法:核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。当找到这两个项目后,交换项目的位置然后继续扫描。重复上面的操作直到所有的项目都按顺序排好。 bubblesort(struct rec r[],int n) { int i,j; struct rec w; unsigned long int compare=0,move=0; for(i=1;i<=n-1;i++) for(j=n;j>=i+1;j--) { if(r[j].key C语言经典算法大全 老掉牙 河内塔 费式数列 巴斯卡三角形 三色棋 老鼠走迷官(一) 老鼠走迷官(二) 骑士走棋盘 八个皇后 八枚银币 生命游戏 字串核对 双色、三色河内塔 背包问题(Knapsack Problem) 数、运算 蒙地卡罗法求PI Eratosthenes筛选求质数 超长整数运算(大数运算) 长PI 最大公因数、最小公倍数、因式分解 完美数 阿姆斯壮数 最大访客数 中序式转后序式(前序式) 后序式的运算 关于赌博 洗扑克牌(乱数排列) Craps赌博游戏 约瑟夫问题(Josephus Problem) 集合问题 排列组合 格雷码(Gray Code) 产生可能的集合 m元素集合的n个元素子集 数字拆解 排序 得分排行 选择、插入、气泡排序 Shell 排序法- 改良的插入排序Shaker 排序法- 改良的气泡排序Heap 排序法- 改良的选择排序快速排序法(一) 快速排序法(二) 快速排序法(三) 合并排序法 基数排序法 搜寻 循序搜寻法(使用卫兵) 二分搜寻法(搜寻原则的代表)插补搜寻法 费氏搜寻法 矩阵 稀疏矩阵 多维矩阵转一维矩阵 上三角、下三角、对称矩阵 奇数魔方阵 4N 魔方阵 2(2N+1) 魔方阵 1.河内之塔 说明河内之塔(Towers of Hanoi)是法国人M.Claus(Lucas)于1883年从泰国带至法国的,河内为越 战时北越的首都,即现在的胡志明市;1883年法国数学家Edouard Lucas曾提及这个故事,据说创世纪时Benares有一座波罗教塔,是由三支钻石棒(Pag)所支撑,开始时神在第一根棒上放置64个由上至下依由小至大排列的金盘(Disc),并命令僧侣将所有的金盘从第一根石棒移至第三根石棒,且搬运过程中遵守大盘子在小盘子之下的原则,若每日仅搬一个盘子,则当盘子全数搬运完毕之时,此塔将毁损,而也就是世界末日来临之时。 解法如果柱子标为ABC,要由A搬至C,在只有一个盘子时,就将它直接搬至C,当有两个盘 子,就将B当作辅助柱。如果盘数超过2个,将第三个以下的盘子遮起来,就很简单了,每次处理两个盘子,也就是:A->B、A ->C、B->C这三个步骤,而被遮住的部份,其实就是进入程式的递回处理。事实上,若有n个盘子,则移动完毕所需之次数为2^n - 1,所以当盘数为64时,则所需次数为:264- 1 = 18446744073709551615为5.05390248594782e+16年,也就是约5000世纪,如果对这数字没什幺概念,就假设每秒钟搬一个盘子好了,也要约5850亿年左右。 #include 常见经典排序算法(C语言) 1.希尔排序 2.二分插入法 3.直接插入法 4.带哨兵的直接排序法 5.冒泡排序 6.选择排序 7.快速排序 8.堆排序 一.希尔(Shell)排序法(又称宿小增量排序,是1959年由D.L.Shell提出来的) /* Shell 排序法*/ #include } } 二.二分插入法 /* 二分插入法*/ void HalfInsertSort(int a[], int len) { int i, j,temp; int low, high, mid; for (i=1; i 60.题目:古典问题:有一对兔子,从出生后第3个月 起每个月都生一对兔子,小兔 子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总 数 为多少? _________________________________________________________________ _ 程序分析:兔子的规律为数列1,1,2,3,5,8,13,21.... _________________________________________________________________ __ 程序源代码: main() { long f1,f2; int i; f1=f2=1; for(i=1;i<=20;i++) { printf("%12ld %12ld",f1,f2); if(i%2==0) printf("\n");/*控制输出,每行四个*/ f1=f1+f2;/*前两个月加起来赋值给第三个月*/ f2=f1+f2;/*前两个月加起来赋值给第三个月*/ } } 上题还可用一维数组处理,you try! 61.题目:判断101-200之间有多少个素数,并输出所有素数。 _________________________________________________________________ _ 1 程序分析:判断素数的方法:用一个数分别去除2到sqrt(这个数),如果能被 整 除,则表明此数不是素数,反之是素数。 _________________________________________________________________ __ 程序源代码: #include "math.h" main() { int m,i,k,h=0,leap=1; 数学建模有下面十种常用算法, 可供参考: 1.蒙特卡罗算法(该算法又称随机性模拟算法,是通过计算机仿真来解决问 题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必用的方法) 2.数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数 据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具) 3.线性规划、整数规划、多元规划、二次规划等规划类问题(建模竞赛大多 数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现) 4.图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算 法,涉及到图论的问题可以用这些方法解决,需要认真准备) 5.动态规划、回溯搜索、分治算法、分支定界等计算机算法(这些算法是算 法设计中比较常用的方法,很多场合可以用到竞赛中) 6.最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些 问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用) 7.网格算法和穷举法(网格算法和穷举法都是暴力搜索最优点的算法,在很 多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具) 8.一些连续离散化方法(很多问题都是实际来的,数据可以是连续的,而计 算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的) 9.数值分析算法(如果在比赛中采用高级语言进行编程的话,那一些数值分 析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用) 10.图象处理算法(赛题中有一类问题与图形有关,即使与图形无关,论文中 也应该要不乏图片的,这些图形如何展示以及如何处理就是需要解决的问题,通常使用Matlab 进行处理) C#实现所有经典排序算法 //选择排序 class SelectionSorter { private int min; public void Sort(int[] arr) { for (int i = 0; i < arr.Length - 1; ++i) { min = i; for (int j = i + 1; j < arr.Length; ++j) { if (arr[j] < arr[min]) min = j; } int t = arr[min]; arr[min] = arr[i]; arr[i] = t; } } static void Main(string[] args) { int[] array = new int[] { 1, 5, 3, 6, 10, 55, 9, 2, 87, 12, 34, 75, 33, 47 }; SelectionSorter s = new SelectionSorter(); s.Sort(array); foreach (int m in array) Console.WriteLine("{0}", m); } } //冒泡排序 class EbullitionSorter { public void Sort(int[] arr) { int i, j, temp; bool done = false; j = 1; while ((j < arr.Length) && (!done))//判断长度 { done = true; for (i = 0; i < arr.Length - j; i++) { if (arr[i] > arr[i + 1]) { C常用经典算法及其实 现 集团企业公司编码:(LL3698-KKI1269-TM2483-LUI12689-ITT289- 常用算法经典代码(C++版) 一、快速排序 voidqsort(intx,inty)//待排序的数据存放在a[1]..a[n]数组中 {inth=x,r=y; intm=a[(x+y)>>1];//取中间的那个位置的值 while(h if(h 数学建模中常见的十 大模型 精品文档 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的 收集于网络,如有侵权请联系管理员删除 C常用经典算法及其实 现 公司标准化编码 [QQX96QT-XQQB89Q8-NQQJ6Q8-MQM9N] 常用算法经典代码(C++版) 一、快速排序 void qsort(int x,int y) a[n]数组中 {int h=x,r=y; int m=a[(x+y)>>1]; a[n]数组中 {for(int i=1;i 数学建模方法详解--三种最常用算法 一、层次分析法 层次分析法[1] (analytic hierarchy process,AHP)是美国著名的运筹学家T.L.Saaty教授于20世纪70年代初首先提出的一种定性与定量分析相结合的多准则决策方法[2,3,4].该方法是社会、经济系统决策的有效工具,目前在工程计划、资源分配、方案 排序、政策制定、冲突问题、性能评价等方面都有广泛的应用. (一) 层次分析法的基本原理 层次分析法的核心问题是排序,包括递阶层次结构原理、测度原理和排序原理[5].下面分别予以介绍. 1.递阶层次结构原理 一个复杂的结构问题可以分解为它的组成部分或因素,即目标、准则、方案等.每一个因素称为元素.按照属性的不同把这 些元素分组形成互不相交的层次,上一层的元素对相邻的下一层的全部或部分元素起支配作用,形成按层次自上而下的逐层支配 关系.具有这种性质的层次称为递阶层次. 2.测度原理 决策就是要从一组已知的方案中选择理想方案,而理想方案一般是在一定的准则下通过使效用函数极大化而产生的.然而对 于社会、经济系统的决策模型来说,常常难以定量测度.因此,层次分析法的核心是决策模型中各因素的测度化.3.排序原理 层次分析法的排序问题,实质上是一组元素两两比较其重要性,计算元素相对重要性的测度问题.(二) 层次分析法的基本步骤 层次分析法的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一致的[1] . 1.成对比较矩阵和权向量 为了能够尽可能地减少性质不同的诸因素相互比较的困难,提高结果的准确度.T .L .Saaty 等人的作法,一是不把所有因 素放在一起比较,而是两两相互对比,二是对比时采用相对尺度. 假设要比较某一层n 个因素n C C ,,1对上层一个因素O 的影响,每次取两个因素i C 和j C ,用ij a 表示i C 和j C 对O 的影响之比, 全部比较 结 果 可 用 成 对 比 较 阵 1 ,0,ij ij ji n n ij A a a a a 表示,A 称为正互反矩阵.一般地,如果一个正互反阵 A 满足: , ij jk ik a a a ,,1,2,,i j k n (1) 则A 称为一致性矩阵,简称一致阵.容易证明n 阶一致阵A 有下列性质: ①A 的秩为1,A 的唯一非零特征根为n ;②A 的任一列向量都是对应于特征根 n 的特征向量. 如果得到的成对比较阵是一致阵,自然应取对应于特征根n 的、归一化的特征向量(即分量之和为1)表示诸因素n C C ,, 1对 上层因素O 的权重,这个向量称为权向量.如果成对比较阵A 不是一致阵,但在不一致的容许范围内,用对应于A 最大特征根(记 国家安全生产监管总局办公楼视频监控系统改造工程 深化设计方案说明 一、系统概述: 1国家安全生产监督管理总局基本地理情况: 国家安全生产监督管理总局大院位于北京市东城区和平里北 街21号,北邻青年沟路,东邻和平里西街,南邻和平里北街,西 邻兴化路。周边情况如右图所示。 2当地社会治安状况可能对大院的影响: 国家安全生产监督管理总局大院地处首都北京,位于和平里北 街21号,大院外部分布着友邻单位和驻地居民,受首都总体社会 环境影响,院外周边地区治安状况良好,又由于大院内部有着相对 严格的军事化管理制度和严谨的治安保卫管理体系,内部社会风气 治安状况良好,所以,拟建中的安防系统在点位分布上,应以预防 突发事件、暴力上访、恶意上访和发现制止实时犯罪为主、治安监 控为辅,同时为各种事后的证据查询提供可靠依据。 3被防护对象的物防设施能力与人防组织管理概况: 根据对现场的考察,我们发现院内人防力量较强,大院各大小 门都有武警执勤,除此之外还有流动巡逻哨的巡视。这些警卫力量 有统一管理,所以大院内部警卫力量较强,防范严密。 大院采用半开放式围墙,并且临街,物防力量稍显薄弱,所以 在防翻越和不法分子进入院内后的监控较为重要。在本方案中,我 们重点考虑了大院内部的技防监控覆盖率。 4气候环境对本项目设备的影响: 1-2月3-4月5-6月7-8月9-10月11-12月 由于北京地处地理阶梯地带,依山近海,地形多样,又是冷空气南下和暖空气北移必经之路,冷暖空气活动频繁,致使北京地区常有旱涝、暴雨、冰雹、大风、寒潮、雾害、雷电等多种气象灾害发生,尤以雷电灾害对安防设备影响及破坏最为严重,应该引起高度重视,所选设备注意防雷、 防潮、防尘、耐高低温等。同时安装 防雷器,以避免直击雷对于设备的损伤。 环境数据图表 数据来源:北京市气象台 5 监控点位的确定: 国家安全生产监督管理总局办公楼原有一套模拟视频监控系统,共有模拟摄像机78台,监控室在首层,面积为42平方米,显示设备为4x2模拟电视墙,由于当时技术的局限性和设备的老化,原有的系统已经不能满足实际监控的需要。 根据重点目标、重点区域重点防护同时兼顾一般场所的原则,摄像机在监控布点时,尽量做到无盲区、无死角并注重设备使用的经济性合理性。 本次采用基于IP 技术的全数字监控系统,将原有摄像机全部换成百万像素IP 摄像机,并根据视频监控区域的要求新增部分百万像素IP 摄像机,弥补原有视频监控系统的监控死角,原有的监控室设备亦更换成数字系统。经过反复勘查对比,最终确定在整个大院内部,安装红外室内半球摄像机86台,室内快球摄像机1台,室内枪式摄像机22台,室外云台摄像机2台,电梯专用摄像机4台。 二、 系统设计原则: 结合当前技术发展状况及趋势,考虑项目建设和日后运行的成本以及使用单位、部门工作的特殊性,系统必须严格遵循以下原则: 1 经济性 充分利用成熟的先进技术,采用性能/价格比较高的产品; 避免盲目性追求最新技术,避免选择新技术后在系统中其它设备和技术成为“瓶颈”,避免某些新技术欠成熟和欠稳定性;同时又要防止系统处理能力不够;软件符合管理需要,界面友好、易维护,整个系统易用、实用。 2 可靠性 (1). 系统硬件上全部选用主流产品,保证了系统的高质量和高稳定性,能够适应野外恶劣环境工作,同时采取有效的防雷、接地、稳压等措施; 平均温度 -2.2 10.0 22.15 25.5 16.5 1.5 平均湿度 44 46 57 76 65 53 平均降水量 3.8 14.8 56.2 172.5 33.7 5.1 雷电 无 有 有 多发 有 有C语言经典算法大全
常见经典排序算法(C语言)1希尔排序 二分插入法 直接插入法 带哨兵的直接排序法 冒泡排序 选择排序 快速排
c语言经典算法100例
数学建模十种常用算法
C#实现所有经典排序算法
C常用经典算法及其实现
数学建模中常见的十大模型讲课稿
C常用经典算法及其实现修订稿
数学建模方法详解种最常用算法
1.深化设计方案说明
相关主题
文本预览