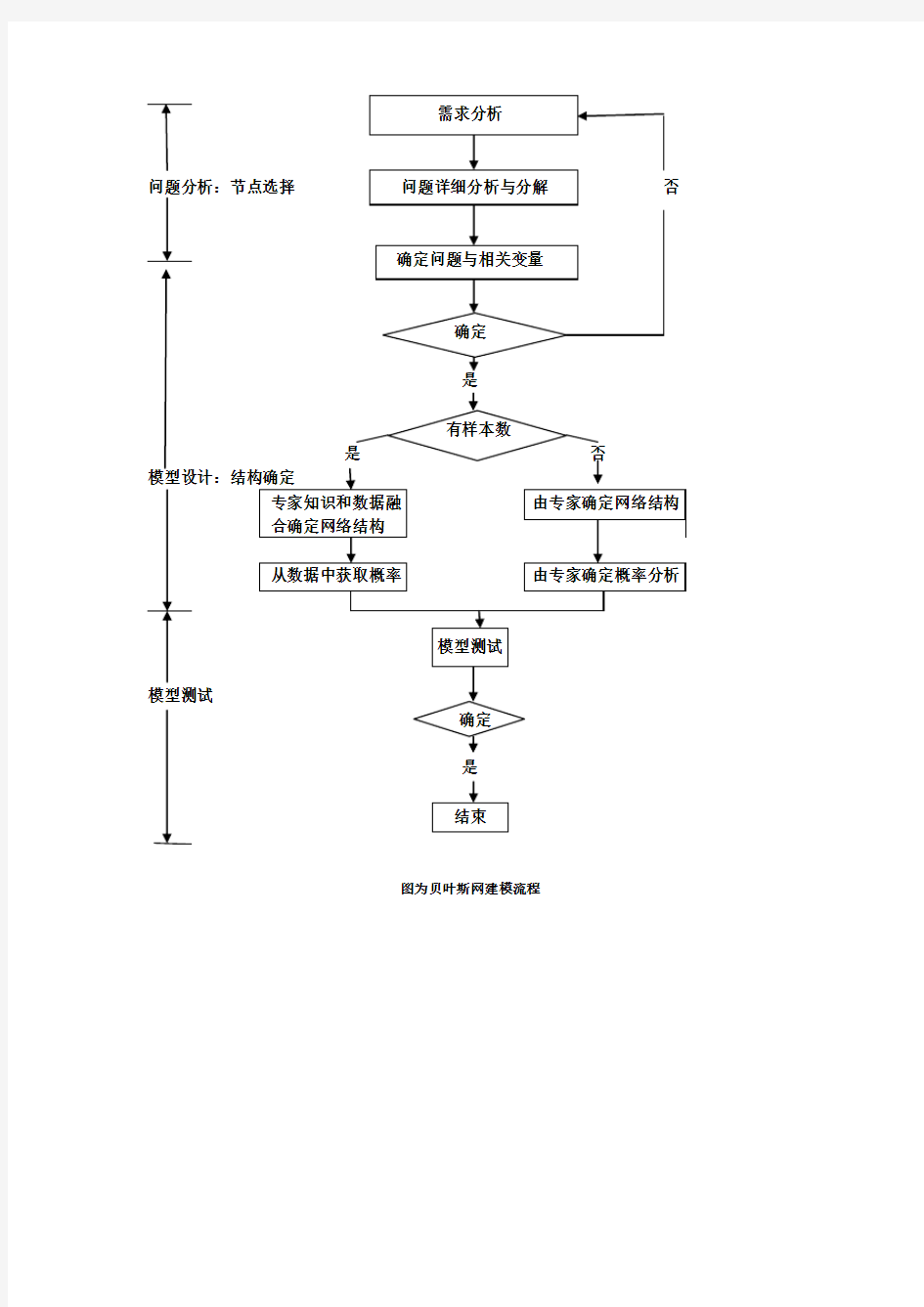
模型设计:结构确定
模型测试
是
图为贝叶斯网建模流程
目录 一、贝叶斯概率基础 (2) 1先验概率、后验概率和条件概率 (2) 2条件概率公式 (2) 3全概率公式 (2) 4贝叶斯公式 (2) 二、贝叶斯网络概述 (3) 三、Sql server 2008中的贝叶斯网络应用 (4) 1在SQL Server 2005中建一个新的数据库BayesDatabase,如图所示。 (4) 2创建新的商业智能项目BayesProject (5) 3建立BayesA中的数据连接,连接到数据库BayesDatabase (6) 4建立BayesA中的数据源视图,在建立视图的过程中选择数据库中的表格Table_2 . 7 5创建挖掘结构 (8) 6数据挖掘向导 (9) 7挖掘模型 (10) 8部署 (11) 9贝叶斯网络结构图 (11) 10数据挖掘预测 (12) 11第一次挖掘模型预测 (13) 12第二次挖掘模型预测 (13) 13第三次挖掘模型预测 (14)
贝叶斯网络 一、贝叶斯概率基础 1先验概率、后验概率和条件概率 先验概率:根据历史的资料或主观判断所确定的各种时间发生的概率后验概率:通过贝叶斯公式,结合调查等方式获取了新的附加信息,对先验概率修正后得到的更符合实际的概率 条件概率:某事件发生后该事件的发生概率 2条件概率公式 条件概率公式: 3全概率公式 4贝叶斯公式
独立互斥且完备的先验事件概率可以由后验事件的概率和相应条件概率决定 二、贝叶斯网络概述 贝叶斯网络是一种概率网络,它是基于概率推理的图形化网络,而贝叶斯公式则是这个概率网络的基础。贝叶斯网络是基于概率推理的数学模型,所谓概率推理就是通过一些变量的信息来获取其他的概率信息的过程,基于概率推理的贝叶斯网络(Bayesian network)是为了解决不定性和不完整性问题而提出的,它对于解决复杂设备不确定性和关联性引起的故障有很的优势,在多个领域中获得广泛应用。 贝叶斯网络是一种概率网络,它是基于概率推理的图形化网络,而贝叶斯公式则是这个概率网络的基础。贝叶斯网络是基于概率推理的数学模型,所谓概率推理就是通过一些变量的信息来获取其他的概率信息的过程,基于概率推理的贝叶斯网络(Bayesian network)是为了解决不定性和不完整性问题而提出的,它对于解决复杂设备不确定性和关联性引起的故障有很的优势,在多个领域中获得广泛应用。
贝叶斯网络 一.简介 贝叶斯网络又称信度网络,是Bayes方法的扩展,目前不确定知识表达和推理领域最有效的理论模型之一。从1988年由Pearl提出后,已知成为近几年来研究的热点.。一个贝叶斯网络是一个有向无环图(Directed Acyclic Graph,DAG),由代表变量节点及连接这些节点有向边构成。节点代表随机变量,节点间的有向边代表了节点间的互相关系(由父节点指向其后代节点),用条件概率进行表达关系强度,没有父节点的用先验概率进行信息表达。节点变量可以是任何问题的抽象,如:测试值,观测现象,意见征询等。适用于表达和分析不确定性和概率性的事件,应用于有条件地依赖多种控制因素的决策,可以从不完全、不精确或不确定的知识或信息中做出推理。 二. 贝叶斯网络建造 贝叶斯网络的建造是一个复杂的任务,需要知识工程师和领域专家的参与。在实际中可能是反复交叉进行而不断完善的。面向设备故障诊断应用的贝叶斯网络的建造所需要的信息来自多种渠道,如设备手册,生产过程,测试过程,维修资料以及专家经验等。首先将设备故障分为各个相互独立且完全包含的类别(各故障类别至少应该具有可以区分的界限),然后对各个故障类别分别建造贝叶斯网络模型,需要注意的是诊断模型只在发生故障时启动,因此无需对设备正常状态建模。通常设备故障由一个或几个原因造成的,这些原因又可能由一个或几个更低层次的原因造成。建立起网络的节点关系后,还需要进行概率估计。具体方法是假设在某故障原
因出现的情况下,估计该故障原因的各个节点的条件概率,这种局部化概率估计的方法可以大大提高效率。 三. 贝叶斯网络有如下特性 1. 贝叶斯网络本身是一种不定性因果关联模型。贝叶斯网络与其他决策模型不同,它本身是将多元知识图解可视化的一种概率知识表达与推理模型,更为贴切地蕴含了网络节点变量之间的因果关系及条件相关关系。 2. 贝叶斯网络具有强大的不确定性问题处理能力。贝叶斯网络用条件概率表达各个信息要素之间的相关关系,能在有限的,不完整的,不确定的信息条件下进行学习和推理。 3. 贝叶斯网络能有效地进行多源信息表达与融合。贝叶斯网络可将故障诊断与维修决策相关的各种信息纳入网络结构中,按节点的方式统一进行处理,能有效地按信息的相关关系进行融合。 目前对于贝叶斯网络推理研究中提出了多种近似推理算法,主要分为两大类:基于仿真方法和基于搜索的方法。在故障诊断领域里就我们水电仿真而言,往往故障概率很小,所以一般采用搜索推理算法较适合。就一个实例而言,首先要分析使用那种算法模型: a.)如果该实例节点信度网络是简单的有向图结构,它的节点数目少的情况下,采用贝叶斯网络的精确推理,它包含多树传播算法,团树传播算法,图约减算法,针对实例事件进行选择恰当的算法; b.)如果是该实例所画出节点图形结构复杂且节点数目多,我们可采用近似推理算法去研究,具体实施起来最好能把复杂庞大的网络进行化简,然后在与精确推理相结合来考虑。
贝叶斯网络 贝叶斯网络是一系列变量的联合概率分布的图形表示。 一般包含两个部分,一个就是贝叶斯网络结构图,这是一个有向无环图(DAG),其中图中的每个节点代表相应的变量,节点之间的连接关系代表了贝叶斯网络的条件独立语义。另一部分,就是节点和节点之间的条件概率表(CPT),也就是一系列的概率值。如果一个贝叶斯网络提供了足够的条件概率值,足以计算任何给定的联合概率,我们就称,它是可计算的,即可推理的。 3.5.1 贝叶斯网络基础 首先从一个具体的实例(医疗诊断的例子)来说明贝叶斯网络的构造。 假设: 命题S(moker):该患者是一个吸烟者 命题C(oal Miner):该患者是一个煤矿矿井工人 命题L(ung Cancer):他患了肺癌 命题E(mphysema):他患了肺气肿 命题S对命题L和命题E有因果影响,而C对E也有因果影响。 命题之间的关系可以描绘成如右图所示的因果关系网。 因此,贝叶斯网有时也叫因果网,因为可以将连接结点的弧认为是表达了直接的因果关系。 图3-5 贝叶斯网络的实例 图中表达了贝叶斯网的两个要素:其一为贝叶斯网的结构,也就是各节点的继承关系,其二就是条件概率表CPT。若一个贝叶斯网可计算,则这两个条件缺一不可。 贝叶斯网由一个有向无环图(DAG)及描述顶点之间的概率表组成。其中每个顶点对应一个随机变量。这个图表达了分布的一系列有条件独立属性:在给定了父亲节点的状态后,每个变量与它在图中的非继承节点在概率上是独立的。该图抓住了概率分布的定性结构,并被开发来做高效推理和决策。 贝叶斯网络能表示任意概率分布的同时,它们为这些能用简单结构表示的分布提供了可计算优势。 假设对于顶点xi,其双亲节点集为Pai,每个变量xi的条件概率P(xi|Pai)。则顶点集合X={x1,x2,…,xn}的联合概率分布可如下计算: 。 双亲结点。该结点得上一代结点。
第四章贝叶斯分析 Bayesean Analysis §4.0引言 一、决策问题的表格表示——损失矩阵 对无观察(No-data)问题a=δ 可用表格(损失矩阵)替代决策树来描述决策问题的后果(损失): 或 损失矩阵直观、运算方便 二、决策原则 通常,要根据某种原则来选择决策规则δ,使结果最优(或满意),这种原则就叫决策原则,贝叶斯分析的决策原则是使期望效用极大。本章在介绍贝叶斯分
析以前先介绍芙他决策原则。 三、决策问题的分类: 1.不确定型(非确定型) 自然状态不确定,且各种状态的概率无法估计. 2.风险型 自然状态不确定,但各种状态的概率可以估计. 四、按状态优于: l ij ≤l ik ?I, 且至少对某个i严格不等式成立, 则称行动a j 按状态优于a k §4.1 不确定型决策问题 一、极小化极大(wald)原则(法则、准则) a 1a 2 a 4 min j max i l (θ i , a j ) 或max j min i u ij 例: 各行动最大损失: 13 16 12 14 其中损失最小的损失对应于行动a 3 . 采用该原则者极端保守, 是悲观主义者, 认为老天总跟自己作对. 二、极小化极小 min j min i l (θ i , a j ) 或max j max i u ij 例:
各行动最小损失: 4 1 7 2 其中损失最小的是行动a 2 . 采用该原则者极端冒险,是乐观主义者,认为总能撞大运。 三、Hurwitz准则 上两法的折衷,取乐观系数入 min j [λmin i l (θ i , a j )+(1-λ〕max i l (θ i , a j )] 例如λ=0.5时 λmin i l ij : 2 0.5 3.5 1 (1-λ〕max i l ij : 6.5 8 6 7 两者之和:8.5 8.5 9.5 8 其中损失最小的是:行动a 4 四、等概率准则(Laplace) 用 i ∑l ij来评价行动a j的优劣 选min j i ∑l ij 上例: i ∑l ij: 33 34 36 35 其中行动a1的损失最小五、后梅值极小化极大准则(svage-Niehans) 定义后梅值s ij =l ij -min k l ik 其中min k l ik 为自然状态为θ i 时采取不同行动时的最小损失.
matlab贝叶斯网络工具箱使用 2010-12-18 02:16:44| 分类:默认分类| 标签:bnet 节点叶斯matlab cpd |字号大中小订阅 生成上面的简单贝叶斯网络,需要设定以下几个指标:节点,有向边和CPT表。 给定节点序,则只需给定无向边,节点序自然给出方向。 以下是matlab命令: N = 4; %给出节点数 dag = false(N,N); %初始化邻接矩阵为全假,表示无边图C = 1; S = 2; R = 3; W = 4; %给出节点序 dag(C,[R,S])=true; %给出有向边C-R,C-S dag([R,S],W)=true; %给出有向边R-W,S-W discrete_nodes = 1:N; %给各节点标号 node_sizes = 2*ones(1,N); %设定每个节点只有两个值 bnet = mk_bnet(dag, node_sizes); %定义贝叶斯网络bnet %bnet结构定义之后,接下来需要设定其参数。 bnet.CPD{C} = tabular_CPD(bnet, C, [0.5 0.5]); bnet.CPD{R} = tabular_CPD(bnet, R, [0.8 0.2 0.2 0.8]); bnet.CPD{S} = tabular_CPD(bnet, S, [0.5 0.9 0.5 0.1]); bnet.CPD{W} = tabular_CPD(bnet, W, [1 0.1 0.1 0.01 0 0.9 0.9 0.99]); 至此完成了手工输入一个简单的贝叶斯网络的全过程。 要画结构图的话可以输入如下命令: G=bnet.dag; draw_graph(G); 得到:
第21卷第2期V ol 121N o 12 三明高等专科学校学报JOURNA L OF S ANMI NG C O LLEGE 2004年6月 Jun 12004 收稿日期:2004204226 作者简介:陈秀琼(1969-),女,福建尤溪人,三明高等专科学校计算机科学系讲师。 基于贝叶斯网络的数据挖掘技术 陈秀琼 (三明高等专科学校计算机科学系,福建三明 365004) 摘 要:从海量数据中挖掘有用的信息为高层的决策支持和分析预测服务,已成为网络时代人们对信息系统提出的新的需求,但我们发现数据处理和数据的提炼技术是匮乏的。起源于贝叶斯统计学的贝叶斯网络以其独特的不确定性知识表达形式、丰富的概率表达能力、综合先验知识的增量学习方法等特性表示了客体的概率分布和因果联系,成为当前数据挖掘众多方法中最为引人注目的焦点之一。本文首先对贝叶斯网络、贝叶斯网络推理和贝叶斯网络学习进行综合性的阐述,然后讨论其在数据挖掘中的应用和优势。 关键词:贝叶斯网络;贝叶斯推理;贝叶斯学习;数据挖掘 中图分类号:O211 文献标识码:A 文章编号:1671-1343(2004)02-0047-06 随着计算机网络和存储技术的迅猛发展,数据传播和积累的速度不断提高,我们迫切需要强有力的数据挖掘工具从海量数据中挖掘有用的信息,为高层的决策支持和分析预测服务。起源于贝叶斯统计学的贝叶斯网络以其独特的不确定性知识表达形式、丰富的概率表达能力、综合先验知识的增量学习方法等特性表示了客体的概率分布和因果联系,利用其模型进行数据挖掘能从数据库中挖掘出多层、多点的因果概念联系,推理出客观世界客体间存在的普遍联系,因此成为当前数据挖掘众多方法中最引人注目的焦点之一[1]。 1 贝叶斯网络 图1 贝叶斯网络结构示例 贝叶斯网络(Bayesian netw ork ),又叫概率因果网络、信任网络、知识图等,是一种有向无环图[2]。一个贝叶斯网络由两个部分构成: (1)具有k 个节点的有向无环图G (如图1)。图中的节点代表随机变量,节点间的有向边代表了节点间的相互关联关系。节点变量可以是任何问题的抽象,如测试值、观测现象、意见征询等。通常认为有向边表达了一种因果关系,故贝叶斯网络有时叫做因果网络(causal netw ork )。重要的是,有向图蕴涵了条件独立性假设,贝叶斯网络规 定图中的每个节点V i 条件独立于由V i 的父节点给定的非V i 后代节点构成的任何节点子 集,即如果用A (V i )表示非V i 后代节点构成的任何节点子集,用∏(V i )表示V i 的直接双
贝叶斯网络(基础知识) 1基本概率公理 1)命题 我们已经学过用命题逻辑和一阶谓词逻辑表达命题。在概率论中我们采用另外一种新的表达能力强于命题逻辑的命题表达方式,其基本元素是随机变量。 如:Weather=snow; Temperature=high, etc。 在概率论中,每个命题赋予一个信度,即概率 2)在随机现象中,表示事件发生可能性大小的一个实数称为事件的概率用P(A)表示。 如P(硬币=正面)=0.5。 3)在抛硬币这个随机现象中,落地后硬币的所有可能结果的集合构成样本空间。 4)P(A)具有以下性质: 0 ≤P(A) ≤1, P(A)+P(-A)=1 P(true) = 1 and P(false) = 0 P(A∨B) = P(A) + P(B) - P(A∧B) (or, P(A∨B)=P(A)+P(B), if A∩B=Φ,即A,B互斥) 2随机变量 随机变量是构成语言的基本元素:如本书提到的天气、骰子、花粉量、产品、Mary,公共汽车,火车等等。 1)典型情况下,随机变量根据定义域的类型分成3类: 布尔随机变量:如:牙洞Cavity的定义域是
1.选题:本课题国内外研究现状述评,提出选题的背景及意义。 2.目标与内容: 本课题研究拟完成的研究目标和主要研究内容,研究内容要对?拟解决的问题进行具体化。3、研究思路与方法:本课题研究的技术路线、方法和计划。4.预期价值:本课题理论创新程度和实践应用价值。(课题设计论证限3000字以内) 一直以来如何有效的提高学生的学习效率和教师的教学效率不断的得到大量的研究,近二十年以来,随着计算机信息技术和互联网应用的飞速发展,在教育心理学中正在发生着一场革命,应用建构主义的学习理论(Slavin, 1994)来指导改革教学成为一大趋势。建构主义学习理论从“学习的含义”(即关于“什么是学习”)与“学习的方法”(即关于“如何进行学习”)这两个角度说明学习的影响因素及提高学习效率的方法,建构主义学习理论认为学习是在一定的基础知识之上,在一定的情境即社会文化背景下,借助其他人的帮助即通过人际间的协作活动而实现的意义建构过程。“情境”、“协作”、“会话”和“意义建构”是学习环境中的四大要素或四大属性。所谓“情境”即是学习的综合环境;“协作”: 指学习中与他人的沟通与合作;“会话”:学习小组成员之间通过会话商讨如何完成规定的学习任务的计划;“意义建构”:建构事物的性质、规律以及事物之间的内在联系,是整个学习过程的最终目标。建构主义的学生观、教师观和知识观和以往的学习理论有了很大的变化,应用建构主义学习理论来提高教学效率正成为当前的研究热点,但目前的研究多从学习的方法论和学习技术本身入手,考虑学生的具体群体的学习特点较少,不能很好的有的放矢,在分析学生的学习影响因素时多直接用常规的数理统计理论进行分析与讨论,而实际上影响学生的学习因素是相当复杂与繁多的,而且学习因素之间W能存在相互的因果关系,而这种因果关系有时往往不知道,因素之间的影响到底多大,定量的关系不明确,甚至可能有很多隐藏的因素在起作用,发现学习的各种影响因素及其因果关系与比重,以及它们的变化分布规律对我们找出主要因素从而正确指导教学以及设计调查问卷摸查学生的学习基础与学习特点对教师的教学设计和提高教学效率具有重要意义,目前对此的研究还比较少。 贝叶斯网络又称信度网络,是Bayes方法的扩展,是目前不确定知识表达和推理领域最有效的理论模型之一。自1988年由Pearl提出后,己知成为近几年来研究的热点一般的贝叶斯网络结构是一个有向无环图(Directed Acyclic Graph,DAG),如图1所示,由代表变量节点及连接这些节点有向边构成。节点代表随机变量,节点间的有向边代表了节点间的互相关系(由父节点指向其后代节点),用条件概率进行表达关系强度,没有父节点的用先验概率进行信息表达, 节点变量可以是任何问题的抽象(如知识表达),适用于表达和分析不确定性和概率性的事件,可以从不完全、不精确或不确定的知识或信息中做出推理。贝叶斯网络本身是一种不确定性因果关联模型,贝叶斯网络与其他决策模型不同,它本身是将多元知识图解可视化为一种概率知识表近与推理模型,更为贴切地蕴含了网络节点,变量之间的因果关系及条件相关关系,如果节点表达为学习因素,
贝叶斯网络 2007-12-27 15:13 贝叶斯网络 贝叶斯网络亦称信念网络(Belief Network),于1985 年由Judea Pearl 首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。它的节点用随机变量或命题来标识,认为有直接关系的命题或变量则用弧来连接。例如,假设结点E 直接影响到结点H,即E→H,则建立结点E 到结点H 的有向弧(E,H),权值(即连接强度)用条件概率P(H/E)来表示,如图所示: 一般来说,有 n 个命题 x1,x2,,xn 之间相互关系的一般知识可用联合概率分布来描述。但是,这样处理使得问题过于复杂。Pearl 认为人类在推理过程中,知识并不是以联合概率分布形表现的,而是以变量之间的相关性和条件相关性表现的,即可以用条件概率表示。如 例如,对如图所示的 6 个节点的贝叶斯网络,有 一旦命题之间的相关性由有向弧表示,条件概率由弧的权值来表示,则命题之间静态结构关系的有关知识就表示出来了。当获取某个新的证据事实时,要对每个命题的可能取值加以综合考查,进而对每个结点定义一个信任度,记作 Bel(x)。可规定 Bel(x) = P(x=xi / D) 来表示当前所具有的所有事实和证据 D 条件下,命题 x 取值为 xi 的可信任程度,然后再基于 Bel 计算的证据和事实下各命题
的可信任程度。 团队作战目标选择 在 Robocode 中,特别在团队作战中。战场上同时存在很多机器人,在你附近的机器人有可能是队友,也有可能是敌人。如何从这些复杂的信息中选择目标机器人,是团队作战的一大问题,当然我们可以人工做一些简单的判断,但是战场的信息是变化的,人工假定的条件并不是都能成立,所以让机器人能自我选择,自我推理出最优目标才是可行之首。而贝叶斯网络在处理概率问题上面有很大的优势。首先,贝叶斯网络在联合概率方面有一个紧凑的表示法,这样比较容易根据一些事例搜索到可能的目标。另一方面,目标选择很容易通过贝叶斯网络建立起模型,而这种模型能依据每个输入变量直接影响到目标选择。 贝叶斯网络是一个具有概率分布的有向弧段(DAG)。它是由节点和有向弧段组成的。节点代表事件或变量,弧段代表节点之间的因果关系或概率关系,而弧段是有向的,不构成回路。下图所示为一个简单的贝叶斯网络模型。它有 5 个节 点和 5 个弧段组成。图中没有输入的 A1 节 点称为根节点,一段弧的起始节点称为其末节点的母节点,而后者称为前者的子节点。 简单的贝叶斯网络模型 贝叶斯网络能够利用简明的图形方式定性地表示事件之间复杂的因果关系或概率关系,在给定某些先验信息后,还可以定量地表示这些关系。网络的拓扑结构通常是根据具体的研究对象和问题来确定的。目前贝叶斯网络的研究热点之一就是如何通过学习自动确定和优化网络的拓扑结构。 变量 由上面贝叶斯网络模型要想得到理想的目标机器人,我们就必须知道需要哪些输入变量。如果想得到最好的结果,就要求我们在 Robocode 中每一个可知的数据块都要模拟为变量。但是如果这样做,在贝叶斯网络结束计算时,我们会得到一个很庞大的完整概率表,而维护如此庞大的概率表将会花费我们很多的系统资源和计算时间。所以在开始之前我们必须要选择最重要的变量输入。这样从比赛中得到的关于敌人的一些有用信息有可能不会出现在贝叶斯网络之内,比如速
Software Engineering and Applications 软件工程与应用, 2019, 8(2), 65-71 Published Online April 2019 in Hans. https://www.doczj.com/doc/b61386662.html,/journal/sea https://https://www.doczj.com/doc/b61386662.html,/10.12677/sea.2019.82008 Research on Users Behavior Similarity Based on Bayesian Network Jiamei Ye Mathematics and Statistical Institute of Jiangxi University of Finance and Economics, Nanchang Jiangxi Received: Mar. 24th, 2019; accepted: Apr. 8th, 2019; published: Apr. 15th, 2019 Abstract With the rapid development of mobile devices and mobile services, mobile social networks are integrated into people’s daily lives, and people are also generating a large amount of data here. The research on this huge data source is very meaningful and necessary. User similarity in social networks is an important research field in social media data analysis. It also plays a very impor-tant role in the research of product recommendation and social network user relationship evolu-tion. The similarity between users depends not only on the network topology, but also on the de-gree of dependence between users. In order to achieve the similarity measure between users in social network data, this paper proposes a basis based on topology and probabilistic reasoning. The user similarity measurement method of social network is adopted, and Bayesian network is used as the framework of this uncertain knowledge discovery. A user similarity discovery method based on Bayesian network is proposed. Keywords User Behavior Similarity, Bayesian Network, DBLP Dataset 基于贝叶斯网络的用户行为相似性研究 叶佳美 江西财经大学统计学院,江西南昌 收稿日期:2019年3月24日;录用日期:2019年4月8日;发布日期:2019年4月15日 摘要 随着移动设备和移动服务的高速发展,移动社交网络融入了人们的日常生活。每时每刻人们都在这里生
收稿日期:2004-01-23。 项目来源:国家自然科学基金资助项目(60175022)。 第29卷第4期2004年4月武汉大学学报#信息科学版 Geomatics and Information Science of Wuhan U niversity V ol.29No.4Apr.2004 文章编号:1671-8860(2004)04-0315-04文献标识码:A 贝叶斯网络结构学习及其应用研究 黄解军1 万幼川1 潘和平 1 (1 武汉大学遥感信息工程学院,武汉市珞喻路129号,430079) 摘 要:阐述了贝叶斯网络结构学习的内容与方法,提出一种基于条件独立性(CI)测试的启发式算法。从完全潜在图出发,融入专家知识和先验常识,有效地减少网络结构的搜索空间,通过变量之间的CI 测试,将全连接无向图修剪成最优的潜在图,近似于有向无环图的无向版。通过汽车故障诊断实例,验证了该算法的可行性与有效性。 关键词:贝叶斯网络;结构学习;条件独立性;概率推理;图论中图法分类号:T P18;T P311 贝叶斯网络学习是贝叶斯网络的重要研究内容,也是贝叶斯网络构建中的关键环节,大体分为结构学习和参数学习两个部分。由于网络结构的空间分布随着变量的数目和每个变量的状态数量呈指数级增长,因此,结构学习是一个NP 难题。为了克服在构建网络结构中计算和搜索的复杂性,许多学者进行了大量的探索性工作[1~5]。至今虽然出现了许多成熟的学习算法,但由于网络结构空间的不连续性、结构搜索和参数学习的复杂性、数据的不完备性等特点,每种算法都存在一定的局限性。本文提出了一种新算法,不仅可以有效地减少网络结构的搜索空间,提高结构学习的效率,而且可避免收敛到次优网络模型的问题。 1 贝叶斯网络结构学习的基本理论 1.1 贝叶斯网络结构学习的内容 贝叶斯网络又称为信念网络、概率网络或因果网络[6] 。它主要由两部分构成:1有向无环图(directed acyclic graph,DAG),即网络结构,包括节点集和节点之间的有向边,每个节点代表一个变量,有向边代表变量之间的依赖关系;o反映变量之间关联性的局部概率分布集,即概率参数,通常称为条件概率表(conditional probability table,CPT),概率值表示变量之间的关联强度或置信度。贝叶斯网络结构是对变量之间的关系描 述,在具体问题领域,内部的变量关系形成相对稳定的结构和状态。这种结构的固有属性确保了结构学习的可行性,也为结构学习提供了基本思路。贝叶斯网络结构学习是一个网络优化的过程,其目标是寻找一种最简约的网络结构来表达数据集中变量之间的关系。对于一个给定问题,学习贝叶斯网络结构首先要定义变量及其构成,确定变量所有可能存在的状态或权植。同时,要考虑先验知识的融合、评估函数的选择和不完备数据的影响等因素。 1.2 贝叶斯网络结构学习的方法 近10年来,贝叶斯网络的学习理论和应用取得了较大的进展。目前,贝叶斯网络结构学习的方法通常分为两大类:1基于搜索与评分的方法,运用评分函数对网络模型进行评价。通常是给定一个初始结构(或空结构),逐步增加或删减连接边,改进网络模型,从而搜索和选择出一个与样本数据拟合得最好的结构。根据不同的评分准则,学习算法可分为基于贝叶斯方法的算法[3,7]、基于最大熵的算法[8]和基于最小描述长度的算法[1,2]。o基于依赖关系分析的方法,节点之间依赖关系的判断通过条件独立性(CI )测试来实现,文献[9,10]描述的算法属于该类算法。前者在DAG 复杂的情况下,学习效率更高,但不能得到一个最优的模型;后者在数据集的概率分布与DAG 同构的条件下,通常获得近似最优的模型[11],
Computer Science and Application 计算机科学与应用, 2020, 10(3), 493-504 Published Online March 2020 in Hans. https://www.doczj.com/doc/b61386662.html,/journal/csa https://https://www.doczj.com/doc/b61386662.html,/10.12677/csa.2020.103052 The Bibliometric Analysis of Current Studies and Developing Trends on Bayesian Network Research Zhongzheng Xiao1, Nurbol2, Hongyang Liu3 1College of Information Science and Engineering, Xinjiang University, Urumqi Xinjiang 2Network Center, Xinjiang University, Urumqi Xinjiang 3Xichang Satellite Launch Center, Xichang Sichuan Received: Feb. 26th, 2020; accepted: Mar. 12th, 2020; published: Mar. 19th, 2020 Abstract In this paper, 2,930 literatures related to Bayesian network in the recent 10 years in the web of science were taken as the research object. Based on the literature metrological content analysis method, the focus, development rules of research context, existing commonalities and differences, and research status at home and abroad were systematically reviewed. The study found that, as of now, especially in the prevalence of neural networks, Bayesian networks can be deepened and have great potential because of their strong mathematical interpretability. The analysis results are helpful to provide reference for the research status and progress of scholars in the field of Bayesian network research in China. Keywords Bayesian Network, Map Analysis, Citespace, Research Context 贝叶斯网络研究现状与发展趋势的文献计量 分析 肖中正1,努尔布力2,刘宏阳3 1新疆大学信息科学与工程学院,新疆乌鲁木齐 2新疆大学网络中心,新疆乌鲁木齐 3西昌卫星发射中心,四川西昌 收稿日期:2020年2月26日;录用日期:2020年3月12日;发布日期:2020年3月19日
论贝叶斯分类、决策树分类、感知器分类挖掘算法的优势与劣势 摘要本文介绍了在数据挖掘中数据分类的几个主要分类方法,包括:贝叶斯分类、决策树分类、感知器分类,及其各自的优势与劣势。并对于分类问题中出现的高维效应,介绍了两种通用的解决办法。 关键词数据分类贝叶斯分类决策树分类感知器分类 引言 数据分类是指按照分析对象的属性、特征,建立不同的组类来描述事物。数据分类是数据挖掘的主要内容之一,主要是通过分析训练数据样本,产生关于类别的精确描述。这种类别通常由分类规则组成,可以用来对未来的数据进行分类和预测。分类技术解决问题的关键是构造分类器。 一.数据分类 数据分类一般是两个步骤的过程: 第1步:建立一个模型,描述给定的数据类集或概念集(简称训练集)。通过分析由属性描述的数据库元组来构造模型。每个元组属于一个预定义的类,由类标号属性确定。用于建立模型的元组集称为训练数据集,其中每个元组称为训练样本。由于给出了类标号属性,因此该步骤又称为有指导的学习。如果训练样本的类标号是未知的,则称为无指导的学习(聚类)。学习模型可用分类规则、决策树和数学公式的形式给出。 第2步:使用模型对数据进行分类。包括评估模型的分类准确性以及对类标号未知的元组按模型进行分类。 常用的分类规则挖掘方法 分类规则挖掘有着广泛的应用前景。对于分类规则的挖掘通常有以下几种方法,不同的方法适用于不同特点的数据:1.贝叶斯方法 2.决策树方法 3.人工神经网络方法 4.约略集方法 5.遗传算法 分类方法的评估标准: 准确率:模型正确预测新数据类标号的能力。 速度:产生和使用模型花费的时间。 健壮性:有噪声数据或空缺值数据时模型正确分类或预测的能力。 伸缩性:对于给定的大量数据,有效地构造模型的能力。 可解释性:学习模型提供的理解和观察的层次。 影响一个分类器错误率的因素 (1) 训练集的记录数量。生成器要利用训练集进行学习,因而训练集越大,分类器也就越可靠。然而,训练集越大,生成器构造分类器的时间也就越长。错误率改善情况随训练集规模的增大而降低。 (2) 属性的数目。更多的属性数目对于生成器而言意味着要计算更多的组合,使得生成器难度增大,需要的时间也更长。有时随机的关系会将生成器引入歧途,结果可能构造出不够准确的分类器(这在技术上被称为过分拟合)。因此,如果我们通过常识可以确认某个属性与目标无关,则将它从训练集中移走。 (3) 属性中的信息。有时生成器不能从属性中获取足够的信息来正确、低错误率地预测标签(如试图根据某人眼睛的颜色来决定他的收入)。加入其他的属性(如职业、每周工作小时数和年龄),可以降低错误率。 (4) 待预测记录的分布。如果待预测记录来自不同于训练集中记录的分布,那么错误率有可能很高。比如如果你从包含家用轿车数据的训练集中构造出分类器,那么试图用它来对包含许多运动用车辆的记录进行分类可能没多大用途,因为数据属性值的分布可能是有很大差别的。 评估方法 有两种方法可以用于对分类器的错误率进行评估,它们都假定待预测记录和训练集取自同样的样本分布。 (1) 保留方法(Holdout):记录集中的一部分(通常是2/3)作为训练集,保留剩余的部分用作测试集。生成器使用2/3 的数据来构造分类器,然后使用这个分类器来对测试集进行分类,得出的错误率就是评估错误率。 虽然这种方法速度快,但由于仅使用2/3 的数据来构造分类器,因此它没有充分利用所有的数据来进行学习。如果使用所有的数据,那么可能构造出更精确的分类器。 (2) 交叉纠错方法(Cross validation):数据集被分成k 个没有交叉数据的子集,所有子集的大小大致相同。生成器训练和测试共k 次;每一次,生成器使用去除一个子集的剩余数据作为训练集,然后在被去除的子集上进行测试。把所有
带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、 决策树 【导读】众所周知,Scikit-learn(以前称为scikits.learn)是一个用于Python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度增强,k-means和DBSCAN,旨在与Python数值和科学库NumPy和SciPy 互操作。本文将带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树。 逻辑回归(Logistic regression) 逻辑回归,尽管他的名字包含"回归",却是一个分类而不是回归的线性模型。逻辑回归在文献中也称为logit回归,最大熵分类或者对数线性分类器。下面将先介绍一下sklearn中逻辑回归的接口: class sklearn.linear_model.LogisticRegression(penalty=l2, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=warn, max_iter=100, multi_class=warn, verbose=0, warm_start=False, n_jobs=None) 常用参数讲解: penalty:惩罚项。一般都是"l1"或者"l2"。 dual:这个参数仅适用于使用liblinear求解器的"l2"惩罚项。一般当样本数大于特征数时,这个参数置为False。 C:正则化强度(较小的值表示更强的正则化),必须是正的浮点数。 solver:参数求解器。一般的有{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}。multi_class:多分类问题转化,如果使用"ovr",则是将多分类问题转换成多个二分类为题看待;如果使用"multinomial",损失函数则会是整个概率分布的多项式拟合损失。 不常用的参数这里就不再介绍,想要了解细节介绍,可以sklearn的官网查看。 案例: 这里我使用sklearn内置的数据集——iris数据集,这是一个三分类的问题,下面我就使用
摘要: 本文主要介绍了贝叶斯网的基本概念以及重要性抽样方法的基本理论和概率推理, 重点介绍了两种重要的抽样方法, 即逻辑抽样方法和似然加权法, 并且比较了它们的优缺点 关键词: 贝叶斯网 抽样法 无偏估计 1.引言 英国学者T.贝叶斯1763年在《论有关机遇问题的求解》中提出一种归纳推理的理论, 后被一些统计学者发展为一种系统的统计推断方法, 称为贝叶斯方法.采用这种方法作统计推断所得的全部结果, 构成贝叶斯统计的内容.认为贝叶斯方法是唯一合理的统计推断方法的统计学者, 组成数理统计学中的贝叶斯学派, 其形成可追溯到 20世纪 30 年代.到50~60年代, 已发展为一个有影响的学派.Zhang 和Poole 首先提出了变量消元法, 其原理自关于不定序动态规划的研究(Bertele and Brioschi,1972).相近的工作包括D`Ambrosio (1991)、Shachter (1994)、Shenoy (1992)等人的研究.近期关于变量消元法的研究可参见有关文献【1】由于变量消元法不考虑步骤共享, 故引进了团树传播法, 如Hugin 方法.在实际应用中, 网络节点往往是众多的, 精确推理算法是不适用的, 因而近似推理有了进一步的发展. 重要性抽样法(Rubinstein, 1981)是蒙特尔洛积分中降低方差的一种手段, Henrion (1988)提出了逻辑抽样, 它是最简单也是最先被用于贝叶斯网近似推理的重要性抽样算法. Fung 和Chang (1989)、Shachter 和Peot (1989)同时提出了似然加权算法. Shachter 和Peot (1989)还提出了自重要性抽样和启发式重要性抽样算法. Fung 和Favero (1994)提出了逆序抽样(backward sam-pling ), 它也是重要性抽样的一个特例. Cheng 和Druzdzel (2000)提出了自适应重要性抽样算法, 同时也给出了重要性抽样算法的通用框架, 这就是各种抽样方法的发展状况. 本文就近似推理阐述了两种重要的抽样方法即逻辑抽样方法和似然加权法, 并比较了它们的优缺点. 2. 基本概念 2.1 贝叶斯网络的基本概念 贝叶斯网络是一种概率网络, 用来表示变量之间的依赖关系, 是带有概率分布标注的有向无环图, 能够图形化地表示一组变量间的联合概率分布函数. 贝叶斯网络模型结构由随机变量(可以是离散或连续)集组成的网络节点, 具有因果关系的网络节点对的有向边集合和用条件概率分布表示节点之间的影响等组成.其中节点表示了随机变量, 是对过程、事件、状态等实体的某些特征的描述; 边则表示变量间的概率依赖关系.起因的假设和结果的数据均用节点表示, 各变量之间的因果关系由节点之间的有向边表示, 一个变量影响到另一个变量的程度用数字编码形式描述.因此贝叶斯网络可以将现实世界的各种状态或变量画成各种比例, 进行建模. 2.2重要性抽样法基本理论 设()f X 是一组变量X 在其定义域n X R Ω?上的可积函数.考虑积分 ()()X I f X d X Ω= ? (2.2.1)