
第十一章线性相关分析与线性回归分析
11.1 两个变量之间的线性相关分析
相关分析是在分析两个变量之间关系的密切程度时常用的统计分析方法。最简单的相关分析是线性相关分析,即两个变量之间是一种直线相关的关系。相关分析的方法有很多,根据变量的测量层次不同,可以选择不同的相关分析方法。总的来说,变量之间的线性相关关系分为三种。一是正相关,即两个变量的变化方向一致。二是负相关,即两个变量的变化方向相反。三是无相关,即两个变量的变化趋势没有明显的依存关系。两个变量之间的相关程度一般用相关系数r 来表示。r 的取值范围是:-1≤r≤1。∣r∣越接近1,说明两个变量之间的相关性越强。∣r∣越接近0,说明两个变量之间的相关性越弱。相关分析可以通过下述过程来实现:
11.1.1 两个变量之间的线性相关分析过程
1.打开双变量相关分析对话框
执行下述操作:
Analyze→Correlate(相关)→Bivariate(双变量)打开双变量相关分析对话框,如图11-1 所示。
图11-1 双变量相关分析对话框
2.选择进行相关分析的变量
从左侧的源变量窗口中选择两个要进行相关分析的变量进入Variable 窗口。
3.选择相关系数。
Correlation Coefficient 是相关系数的选项栏。栏中提供了三个相关系数的选项:(1)Pearson:皮尔逊相关,即积差相关系数。适用于两个变量都为定距以上变量,且两个
变量都服从正态分布的情况。这是系统默认的选项。
(2)Kendall:肯德尔相关系数。它表示的是等级相关,适用于两个变量都为定序变量的情况。
(3)Spearman:斯皮尔曼等级相关。它表示的也是等级相关,也适用于两个变量都为定序变量的情况。
4.确定显著性检验的类型。
Test of Significance 是显著性检验类型的选项栏,栏中包括两个选项:
(1)Two-tailed:双尾检验。这是系统默认的选项。
(2)One-tailed:单尾检验。
5.确定是否输出相关系数的显著性水平
Flag significant Correlations:是标出相关系数的显著性选项。如果选中此项,系统在输出结果时,在相关系数的右上方使用“*”表示显著性水平为0.05;用“**”表示显著性水平为0.01。
6. 选择输出的统计量
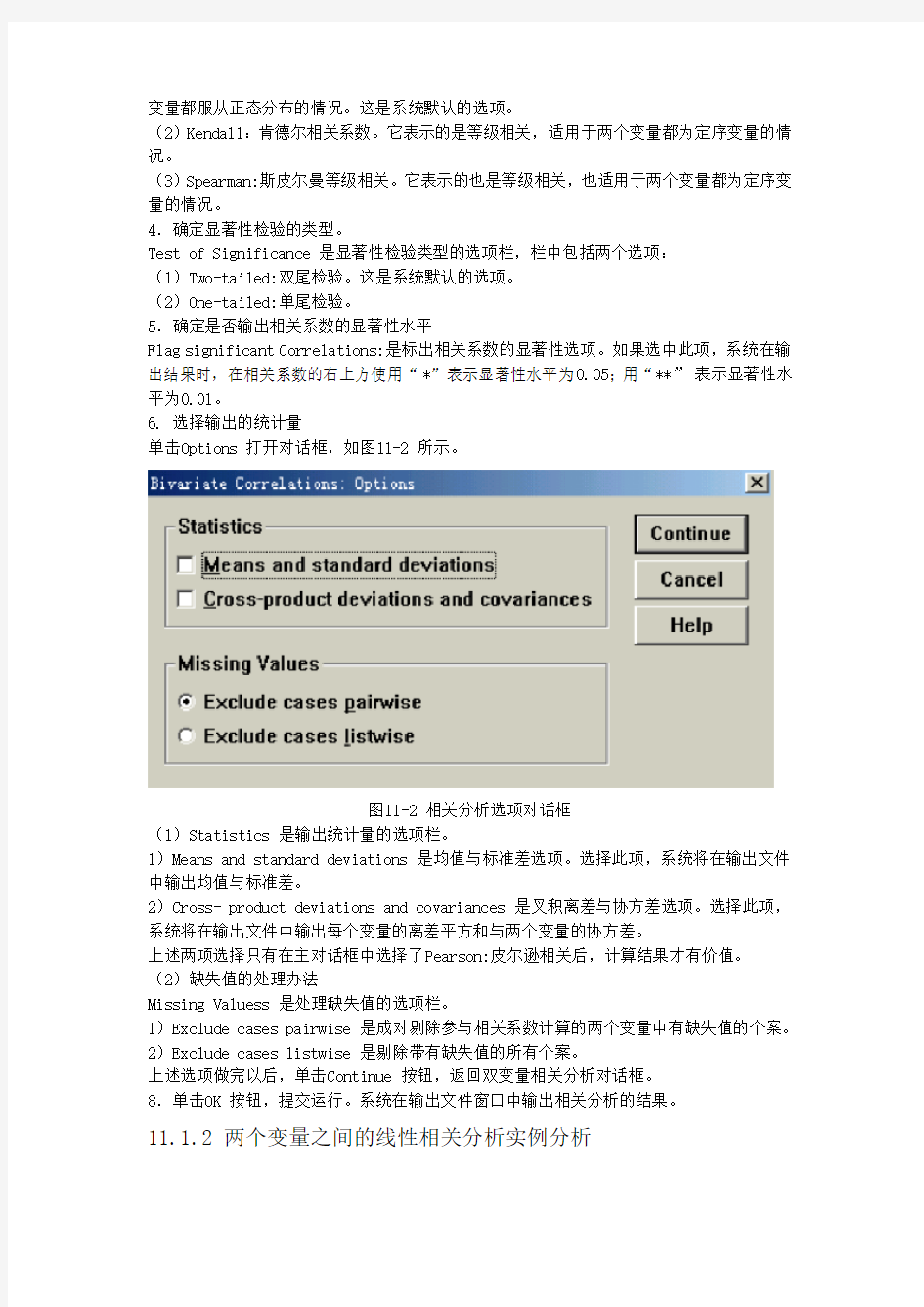
单击Options 打开对话框,如图11-2 所示。
图11-2 相关分析选项对话框
(1)Statistics 是输出统计量的选项栏。
1)Means and standard deviations 是均值与标准差选项。选择此项,系统将在输出文件中输出均值与标准差。
2)Cross- product deviations and covariances 是叉积离差与协方差选项。选择此项,系统将在输出文件中输出每个变量的离差平方和与两个变量的协方差。
上述两项选择只有在主对话框中选择了Pearson:皮尔逊相关后,计算结果才有价值。
(2)缺失值的处理办法
Missing Valuess 是处理缺失值的选项栏。
1)Exclude cases pairwise 是成对剔除参与相关系数计算的两个变量中有缺失值的个案。2)Exclude cases listwise 是剔除带有缺失值的所有个案。
上述选项做完以后,单击Continue 按钮,返回双变量相关分析对话框。
8.单击OK 按钮,提交运行。系统在输出文件窗口中输出相关分析的结果。
11.1.2 两个变量之间的线性相关分析实例分析
实例:在“休闲调查1”中,对被调查者的“住房面积”和“家月收入”作相关分析
打开数据文件“休闲调查1”后,执行下述操作:
1.Analyze→Correlate→Bivariate 打开双变量相关分析对话框。
2.从左侧的源变量中选择“住房面积”和“家月收入”进入Variable 窗口。其它选项采用系统默认状态。
3.单击Options 按钮,打开对话框。
选择Means and standard deviations 选项和Cross- product deviations and covariances 选项。
单击Continue 按钮,返回双变量相关分析对话框。
4.单击OK 按钮,提交运行。可以在输出文件中看到相关分析的结果如表11-1、表11-2 所示
表11-1 变量的描述统计
表11-2相关分析表
由于在选项中选择了Means and standard deviations选项。所以在输出文件中出现了表11-1,表中的内容就是两个变量的平均值、标准差和个案数。
表11-2是以交叉表的形式表现的相关分析的结果。下面将表的内容作如下解释:Pearson Correlation是皮尔逊相关系数。在它右侧“住房使用面积”一列中对应的数据为1.000,这是“住房使用面积”与“住房使用面积”的相关系数。由于使用同一个变量计算相关,数据完全一一对应,所以计算的相关系数为1。在“家月收入”下面对应的数据为0.393,这是“住房使用面积”与“家月收入”的皮尔逊相关系数。
Sig. (2-tailed)是双端检验的显著性水平。可以看出,相关系数0.393 的显著性水平为0.000,表明总体中两个变量的相关是显著的。0.393 的“**”和表下面的英文说明Correlation is significant at the 0.05 level (2-tailed) (相关系数在0.01 的水平
上显著)即说明了这一点。Sum of Squares and Cross-products 是离差平方和与叉积和。如果以“家月收入”为X 变量,“住房使用面积”为Y 变量的话,离差平方和是指
()2∑-X X 或()2∑-Y Y 。差积和是指Σ(x ? x )(y ? y )。表11-2 中“家月收入”一列下面所对应的94462797 是“家月收入”变量的离差平方和。而879447.51 则是差积和。Covariance 是协方差。表11-2 中“家月收入”一列下面所对应的3118.608 是“家月收入”的方差。“住房使用面积”一列下面所对应的187.904 是“家月收入”变量与“住房使用面积”变量的协方差。从输出的情况来看,“住房面积”和“家月收入”呈正相关,其相关系数为0.393,在总体中这个相关系数在0.01 的水平上是显著的。
11.2 线性回归分析
回归分析是用确定性的方法来研究变量之间的非确定性关系的最重要的方法之一。非确定性关系是指变量在变化过程中表现出来的数量上具有一定的依存性,但并非象函数关系那样一一对应的关系。如果把其中的一个或几个变量作为自变量,把另一个随着自变量的变化而变化的变量作为因变量,通过建立线性关系的数学模型来研究它们之间的非确定性的关系的方法就是回归分析的方法。由于回归分析中表现的是自变量和因变量之间的关系,所以这种方法也多用于研究因果关系的数量表现。在SPSS 中的回归分析方法有七种,本节只介绍最简单、最常用的线性回归分析。
回归分析在Analyze 的下拉菜单中,如图11-3 所示。
图11-3 回归分析的指令菜单
图中的主菜单中Regression 是回归,二级菜单中的Linear 是线性。
11.2.1 一元线性回归
11.2.1.1 一元线性回归的原理
1.一元线性回归方程
一元线性回归也就是直线回归。适用于对两个定距以上变量之间关系的分析。是通过给一定
数量的样本观测值拟合一条直线 bx a y
+=?,来研究变量之间关系的方法。这条直线也叫回归直线或回归方程。求回归方程的过程就是利用观测值求出方程中的回归直线中的a 、b 两个系数。一般采用最小二乘法。a 是回归直线的截距,b 是回归直线的斜率,也称为回归系数。
2.回归方程的假定条件
有了回归直线,每一个样本观测值都可以表示为 y i = a + bx i +εi 。(i=1,2…n )εi 称为随机误差项。用回归方程来表示变量之间的关系需要满足一定的假定条件。这些假定条件是:(1) 正态性假定。即随机误差项εi 服从正态分布。
(2) 零均值假定。εi 的均值为零,即E(εi )=0。
(3) 同方差假定。εi 分布的方差相等。
(4) 独立性假定。εi 是相互独立的随机变量。
(5) 无系列相关假定。εi 的变化与x i 的变化无相关
上述的假定条件中有一个不满足,回归方程都是没有价值的。由于上述的假定都是对总体而言的,而总体的情况又属于未知。因此在建立回归方程后应该用样本观测值对上述假定进行检验。
3.回归方程的显著性检验
由于回归方程是用样本观测值建立的,用它来描述总体情况时,需要进行假设检验。
(1)回归系数的显著性检验
1)对回归系数b 的检验:检验的原假设是b=0,检验的方法是T 检验。
2)对截距a 的检验:检验的原假设是a=0,检验的方法是T 检验。
(2)对回归直线拟合优度的检验
采用最小二乘法可以给任何一组数据配合一条直线。但只有两个变量之间的相关较强时,用
回归直线来描述它们之间的关系才有意义。回归直线拟合优度检验的指标是判定系数R 2。
R 2=r 2,即相关系数的平方。它说明因变量的变化中有多少是由自变量的变化引起的。如R 2=0.65,则说明,因变量的变化中的65%是由自变量的变化引起的。R 2越接近1,说明拟合优
度越好。R 2=0,说明自变量与因变量没有任何关系,配合回归直线没有价值。
(3)对回归直线意义的检验
对一组数据配合回归直线是否有意义,可以通过方差分析和F 检验的方法来确定。把某一样本观测值到回归直线的距离的平方和定义为残差平方和。它反映了除自变量以外的其它因素对因变量的影响。把回归直线到总平均值之间的距离的平方和定义为回归平方和。它反映了自变量对因变量的影响。如果回归平方和很大而残差平方和很小,说明自变量对因变量的解释能力很大,则配合回归直线有意义。反之则说明配合回归直线没有意义。将两个平方和分别除以各自的自由度,就得到了平均回归平方和及平均残差平方和。统计量F=平均回归平方和/平均残差平方和。F 值过小,达不到显著性水平,说明自变量对因变量的解释力度很差,配合回归直线没有意义。
(4)残差的独立性检验
残差的独立性检验也称系列相关检验。如果随机误差项不独立,那么对回归模型的任何估计与假设所做出的结论都是不可靠的。残差的独立性检验是通过Durbin-Watson 检验来完成
的。Durbin-Watson 检验的参数用D 表示。D 的取值范围是0<D<4。当残差与自变量相互独立时,D≈2。当相邻两点的残差正相关时,D<2。当相邻两点的残差负相关时,D>2。其它如随机误差项的零均值,同方差,独立性的检验可根据残差散点图来进行。将在后面的输出文件中介绍。
11.2.1.2 一元线性回归的分析过程
1.打开回归分析对话框
执行下述操作:
Analyze→Regression→Linear 打开对话框,如图11-4所示。由于回归分析的选项很多,本节只介绍与一元线性回归模型的建立及各种检验有关的选项。
图11-4 回归分析对话框
2.选择回归分析的因变量与自变量
从左侧源变量窗口中选择一个变量作为因变量进入Dependent(s)窗口。再选择一个变量作为自变量进入Independent窗口。
3.确定回归分析结果的输出内容
单击Statistics按钮,打开对话框,如图11-5所示。
图11-5 回归分析统计量输出对话框
该对话框包括三部分。
(1)Regression Coefficients是回归系数选项栏。该栏中包括三项内容。与一元回归有关的选项是:
1)Estimates是输出估计值的选项。若选择此项,则在输出文件中输出回归系数B、B的标准误、标准化回归系数beta、B的T检验值以及T值的双侧检验的显著性水平Sig。这是系统默认选项。
2)Confidence intervals是输出回归系数置信区间的选项。选择此项后,系统将在输出文件中输出回归系数95%的置信区间。
(2)在对话框中右上方的五个选项中。与一元回归有关的选项是:
1)Model fit是模型的配置选项。选择此项后,系统将在输出文件中输出引入模型或从模型中剔除的变量,提供复相关系数R、及调整的R2,估计值的标准误,方差分析表。这是系统的默认选项。
2)Descriptives是输出描述统计结果的选项。选择此项后,系统将输出所有变量的个案数、均值、标准差和相关系数矩阵及单侧检验的显著性水平矩阵。
(3)Residuals是残差选项栏。该栏包括两项内容。
1)Durbin-Watson是系列相关检验选项,选择该项后系统将在模型概要中输出Durbin-Watson 的值。
2)Casewise diagnostics是输出个案诊断表的选项。
上述选项作完以后,单击Continue 按钮,返回回归分析对话框。
4.选择输出的图形
单击Plots按钮,打开图形选择对话框,如图11-6所示。
系统默认状态是不输出图形的。但图形对检验残差的正态性,等方差性,奇异值等是非常有帮助的。做图过程为:
图11-6 图形选择对话框
(1)选择坐标轴变量
可以从左侧的源变量窗口中选择两个变量分别进入右侧的X窗口和Y窗口。做了这项选择以后,系统将输出以这两个变量为坐标的散点图。如果要输出多个散点图,可单击Next按钮,在Y和X窗口中再输入另外两个变量。原变量窗口中的七个变量分别为:
1)DEPENDNT是因变量。
2)ZPRED是标准化预测值。
3)ZRESID 标准化残差。
4)DRESID 是剔除残差。
5)ADJPRED调整的预测值。
6)SRESID学生化残差。
7)SDRESID是学生化剔除残差。
(2)确定图形类别
Standardized Residual Plots(标准化残差图)图形类别的选项栏。其中包括两个选项。1)Histogram是输出带有正态曲线的标准化残差的直方图。
2)Normal probability plot输出残差的正态概率图。
上述选项作完以后,单击Continue 按钮,返回回归分析对话框。
5.确定保存变量
单击Save按钮,打开保存变量对话框,如图11-7所示。
图11-7保存变量对话框
该对话框中有较多的选项,系统将把被选择的分析结果作为新变量保存到数据窗口中。
下面只介绍最常用的两个:
(1)Unstandardized是保存非标准化预测值。
(2)Standardized是保存标准化预测值。
上述选项作完以后,单击Continue 按钮,返回回归分析对话框。
6.单击OK按钮,提交运行。系统在输出文件窗口中输出回归分析的结果
11. 2. 1.3 一元线性回归的实例分析
实例:在“休闲调查”中以“住房面积”为因变量,以“家月收入”为自变量进行回归分析。
打开数据文件“休闲调查”后,执行下述操作:
1.Analyze→Regression→Linear 打开图11-4 所示的回归分析对话框。
2.从左侧源变量窗口中选择“住房面积”作为因变量进入Dependent(s)窗口。再选择“家月收入”作为自变量进入Independent窗口。
3.单击Statistics按钮,打开如图11-5所示的统计量输出对话框。选择Durbin-Watson选项。
单击Continue 按钮,返回回归分析对话框。
4.单击Plots按钮,打开如图11-6所示的图形选择对话框。
从左侧的源变量窗口中选择ZPRED(标准化预测值)进入X窗口,选择ZRESID(标准化残差)进入Y窗口。选择Histogram选项。单击Continue 按钮,返回回归分析对话框。
5.单击Save按钮,打开如图11-5所示的保存变量对话框。
选择Unstandardized选项。单击Continue 按钮,返回回归分析对话框。
a) 单击OK 按钮,提交运行。可以在输出文件中看到一元回归分析的结果如表11-3、表11-4、表11-5、表11-6、表11-7 和图11-8、图11-9所示
表11-3 进入或剔除模型的变量
Variables Entered/Removed b
a. All requested variables entered.
b. Dependent Variable: 住房使用面积
表11-3表明。只有一个自变量“家月收入”进入了模型。这个输出结果对多元回归分析是非常有价值的。
表11-4 回归模型的概要表
Model Summary b
a. Predictors: (Constant), 家月收入
b. Dependent Variable: 住房使用面积
表11-4的内容是回归模型的概要。“家月收入”与“住房面积”的相关系数R为0.393,模型的判定系数R Square即R2为0.155,由于R2受个案数的影响较大,根据个案数对其进行调整以后的值为Adjusted R Square,它能更好地说明模型的拟合优度。该模型中的Adjusted R Square为0.152,说明自变量对因变量的影响不是太大,因变量的变差中只有15.2%是由自变量引起的。Durbin-Watson的值是1.5,因为比较接近2,所以认为随机误差项基本上相互独立的,不存在序列相关的问题。
表11-5 方差分析表
表11-5的内容是对模型的方差分析与F检验的结果。从表中可以看出,平均的回归平方和(Regression Mean Square)为8187.646,平均的剩余平方和(Residual Mean Square)为159.435。F值为51.354,显著性水平为0.000。由于显著性已经达到0.001的水平,说明配合
回归直线是有意义的。
表11-6 回归系数
表11-6的内容是回归方程的参数及检验结果。从表中可以看出,回归方程的常数项即截距为28.438,截距的标准误差为1.582。T检验值为17.976,显著性水平为0.000。回归方程的斜率即回归系数为0.009,回归系数的标准误差为0.001,标准化回归系数为0.393,T检验值为7.166,显著性水平为0.000。可以在0.001的水平上说明这个斜率对总体是有意义的。
表11-7 残差统计表
表11-7中的Predicted Values是预测值,Residual是残差。Std. Predicted Values是标准化预测值。Std. Residual是标准化残差。从表中可以看出,残差的平均值为0。标准化残差的平均值为0。说明残差的分布满足均值为零的假设。
图11-8标准化残差的直方图
从图11-8中可以看出,残差的分布基本呈正态。
图11-9残差分布的散点图
图11-9是以标准化预测值为横轴,以标准化残差为纵轴绘制的散点图。可以用于检验等方差性和奇异值的情况。如果残差分布具有等方差性,则图中的散点应该在由原点发出的横线上下的确定的范围内分布。从图中可以看出,残差的分布基本满足等方差性的要求。还可以在“休闲调查1”的数据窗口中看到在数据文件中又增加了一个变量Pre_1,如图11-10所示。这个Pre_1便是由回归方程计算出的预测值。
图11-10 以标准化预测值为新变量的统计结果
11.2.2 多元线性回归
11.2.2.1 多元线性回归的过程
多元线性回归是研究多个变量之间因果关系的最常用的的方法之一。在多个变量中有一个是因变量。因变量应该是定距以上的变量。其它的变量是自变量。自变量的个数应在两个或两个以上,但每个自变量与因变量之间的关系都是线性的。由于任何一个社会现象的变化都可能是由多个因素引起的,因此多元回归在解释一果多因的变量之间的关系时显得特别有效。
由于回归分析的选项较多,而且适用于一元回归的选项均适用于多元回归。在一元回归的输出文件中的内容在多元回归中也都输出。所以在介绍多元线性回归的实现过程及输出结果的解释中重复的部分不再介绍。多元线性回归的实现过程如下:
1.打开回归分析对话框
执行下述操作:
Analyze→Regression→Linear 打开如图11-11所示的对话框。这是一个与图11-4完全相同的对话框。
图11-11 回归分析对话框
2.选择回归分析的因变量与自变量
从左侧源变量窗口中选择一个变量作为因变量进入Dependent(s)窗口。再选择多个自变量进入Independent 窗口。
3.确定自变量的挑选方法
Method 是回归分析中自变量的挑选方法的选择窗口。由于人为选定的自变量未必是对因变量有较大影响的变量。系统要根据自变量对因变量作用的大小,从选定的自变量中筛选出一部分自变量作为回归模型中的自变量。最终保留在模型中的自变量应该是对因变量的变化贡献较大的变量。在Method 窗口中有五个选项。本节只介绍Enter、Backward 和Stepwise三个较常用的选项。
(1)Enter 是强行进入法选项。即所有选择的自变量全部进入回归模型。这是系统默认的
选项。可根据各个自变量的回归数T 检验的值是否达到了显著性水平来确定那些自变量应进入模型。
(2)Backward 向后剔除法选项。先将全部所选变量进入模型,每次剔除一个使方差分析的F 值最小且T 检验达不到显著性水平的变量,直到回归某型中不再含有达不到显著性水平的自变量为止。
(3)Stepwise 逐步进入法选项。首先根据方差分析的结果选择对因变量贡献最大的自变量进入方程。每加入一个自变量进行一次方差分析,如果有自变量使F 值最小且T 检验达不到显著性水平,则予以剔除。这样重复进行,直到回归方程中所有的自变量均符合进入模型的要求,而模型外的变量均不符合进入模型的要求为止。
4.确定输出的统计量
单击Statistics 按钮,打开如图11-5所示的对话框。下面对该对话框中与多元回归分析有关的选项作如下介绍。
图11-5 回归分析统计量输出对话框
(1)Regression Coefficients 是回归系数选项栏。前两项在一元回归中均有介绍。Covariance matrix 是输出回归系数的协方差矩阵、各变量的相关系数矩阵。
(2)在模型及拟合效果的选项中:
1)R squared change是R2的变化。选择此项后,系统将输出回归方程引入或剔除一个自变量后R2的变化量。R2的变化量用R ch表示。R ch较大说明引入或剔除的自变量是一个对因变量影响较大的自变量。
2)Part and patial correlation是相关系数选项。选择此项后,系统将输出回归方程的部分相关系数(表明当一个自变量进入方程后R2增加了多少)、偏相关系数(表明排出了其它的自变量对Y的影响后,某个自变量与Y的相关程度)和零阶相关系数(表明变量之间的简单相关系数)。
3)Collinearity diagnostics 是共线性诊断选项。选择此项后,系统将输出各变量的容限度、方差膨胀因子和共线性诊断表。
上述选项作完以后,单击Continue 按钮,返回回归分析对话框。
5.确定自变量引入模型或从模型中剔除的的标准及缺失值的处理方法
单击Option按钮,打开选项对话框,如图11-12所示。
图11-12选项对话框
(1)确定判断标准
Stepping Method Criteria是设置变量引入模型或从模型中剔除的判断标准栏。
1)Use probability of F是以F的概率作为变量引入模型或从模型中剔除的判断标准。系统默认状态是,当一个变量的F值的显著性水平T Sig.≤0.05时,该变量被引入回归方程。当一个变量的F值的显著性水平T Sig.≥0.1时,该变量被从模型中剔除。也可以根据需要通过在Entry窗口和Removal窗口输入数值的方法,自己设定这两个数值。
2)Use F values是以F值作为变量引入模型或从模型中剔除的判断标准。系统默认状态是,当一个变量的F值≥3.84,该变量被引入回归方程。当一个变量的F值≤2.71时,该变量被从模型中剔除。也可以通过选择Use F values 选项,并在被激活的Entry窗口和Removeal窗口输入数值的方法,根据需要自己设定这两个数值。
(2)Include constant in equation是在方程中包含常数项的选项。这是系统默认选项。(3)Missing Valuess是缺失值的处理方法。
1)Exclude cases listwise 剔除参与回归分析的任何变量中的缺失值。也就是分析中使用的个案在所有变量上都具有合法值。
2) Exclude cases pairwise 是成对删除缺失值。
3) Replace with mean 是用平均值代替缺失值。
上述选项作完以后,单击Continue 按钮,返回回归分析对话框。
6.单击OK按钮,提交运行。系统在输出文件窗口中输出回归分析的结果
11.2.2.2多元线性回归的实例分析
实例:在“贫困调查”中以“月支出”为因变量,以“满意度2”、“年龄”、“住房面积”、“月平均低保金”、“教育水平”为自变量进行多元回归分析。
打开数据文件“贫困调查”后,执行下述操作:
1.Analyze→Regression→Linear 打开图11-11 所示的回归分析对话框。
2.从左侧源变量窗口中选择“月支出”作为因变量进入Dependent(s)窗口。再选择“年龄”、“住房面积”、“低保金”、“教育水平”“满意度2”作为自变量进入Independent窗口。3.在Method窗口中选择Backward选项。
4.单击Statistics按钮,打开如图11-5所示的统计量输出对话框。选择Durbin-Watson选项。选择Collinearity diagnostics选项。单击Continue 按钮,返回回归分析对话框。
5.单击Plots按钮,打开如图11-6所示的图形选择对话框。
从左侧的源变量窗口中选择ZPRED(标准化预测值)进入X窗口,选择ZRESID(标准化残差)进入Y窗口。选择Histogram选项。单击Continue 按钮,返回回归分析对话框。
6.单击Save按钮,打开如图11-5所示的保存变量对话框。选择Unstandardized选项。单击Continue 按钮,返回回归分析对话框。
7.单击OK 提交运行。可以在输出文件中看到多元回归分析的结果。下面主要介绍在一元回归分析结果中没有出现过的表格和图形。
表11-9 变量的进入与剔除表
由于在回归模型的建立方法中选择了向后剔除法(Backward)。表11-6的内容说明系统一共建立了四个模型,第一个模型中包括了全部选定的自变量。在第二个模型中剔除了“满意度2”这个变量。在第三的模型中剔除了“低保金”这个变量。在第四个的模型中剔除了“教育水平”。原因是这三个变量F值的概率均大于0.1。
表11-10 多元回归模型的统计概要
从表11-10中可以看出,包含了“年龄”、“住房面积”、“低保金”、“教育水平”、“满意度2”五个自变量的第一个模型的调整的判定系数Adjusted R Square为0.246。剔除了“满意度2”这个变量后,包含了“年龄”、“住房面积”、“低保金”、“教育水平”四个自变量的第二个模型的调整的判定系数Adjusted R Square为0.255。剔除了“满意度2”和“低保金”两个变量后,包含了“年龄”、“住房面积”和“教育水平”三个自变量的第三个模
型的调整的判定系数Adjusted R Square为0.263。剔除了“满意度2”和“低保金”和“教育水平”三个变量后,包含了“年龄”和“住房面积””两个自变量的第四个模型的调整的判定系数Adjusted R Square为0.251。由于剔除了“教育水平”以后,判定系数略微减小了,说明“教育水平”对因变量还多少有一点影响。但由于达不到显著性水平被从模型中剔除。
表11-11 多元回归模型的方差分析表
从表11-11中可以看出,每个模型都达到了0.00的显著性水平。说明配合回归模型是有意义的。但随着无效变量被逐步剔除,F值愈来愈大。这说明只包含“年龄”和“住房面积”两个变量的模型的拟合优度是最好的。
表11-12 多元回归模型的回归系数表
表11-12中根据三个包含自变量数不同的模型,分别给出了回归系数、回归系数的标准误、标准化回归系数、T检验值、T检验值的显著性水平。从第一个包含了五个变量的模型的T检验值和显著性水平可以看出,“满意度2”、“低保金”和“教育水平”三个变量T检验值均达不到0.1的水平。根据向后剔除法,先剔除了显著性水平最差的“满意度2”这个变量。但从包含了四个变量的第二个模型中可以看出,剔除了“满意度2”后,“年龄”的显著性有所增加。但“低保金”和“教育水平”的显著性仍然达不到0.1的水平。因此它们也被从模型中逐步剔除了。随着无效变量被剔除,“年龄”变量的显著性水平越来越高。最后保留在模型中的两个有效变量是“年龄”和“住房面积”。
第七章 相关与回归分析 一、本章学习要点 (一)相关分析就是研究两个或两个以上变量之间相关程度大小以及用一定函数来表达现象相互关系的方法。现象之间的相互关系可以分为两种,一种是函数关系,一种是相关关系。函数关系是一种完全确定性的依存关系,相关关系是一种不完全确定的依存关系。相关关系是相关分析的研究对象,而函数关系则是相关分析的工具。 相关按其程度不同,可分为完全相关、不完全相关和不相关。其中不完全相关关系是相关分析的主要对象;相关按方向不同,可分为正相关和负相关;相关按其形式不同,可分为线性相关和非线性相关;相关按影响因素多少不同,可分为单相关和复相关。 (二)判断现象之间是否存在相关关系及其程度,可以根据对客观现象的定性认识作出,也可以通过编制相关表、绘制相关图的方式来作出,而最精确的方式是计算相关系数。 相关系数是测定变量之间相关密切程度和相关方向的代表性指标。相关系数用符号“γ”表示,其特点表现在:参与相关分析的两个变量是对等的,不分自变量和因变量,因此相关系数只有一个;相关系数有正负号反映相关系数的方向,正号反映正相关,负号反映负相关;计算相关系数的两个变量都是随机变量。 相关系数的取值区间是[-1,+1],不同取值有不同的含义。当1||=γ时,x 与y 的变量为完全相关,即函数关系;当1||0<<γ时,表示x 与y 存在一定的线性相关,||γ的数值越大,越接近于1,表示相关程度越高;反之,越接近于0,相关程度越低,通常判别标准是:3.0||<γ称为微弱相关,5.0||3.0<<γ称为低度相关,8.0||5.0<<γ称为显著相关,1||8.0<<γ称为高度相关;当0||=γ时,表示y 的变化与x 无关,即不相关;当0>γ时,表示x 与y 为线性正相关,当0<γ时,表示x 与y 为线性负相关。 皮尔逊积距相关系数计算的基本公式是: ∑∑∑∑∑∑∑---= =] )(][)([22222y y n x x n y x xy n y x xy σσσγ 斯皮尔曼等级相关系数和肯特尔等级相关系数是测量两个等级变量(定序测度)之间相 关密切程度的常用指标。 (三)回归分析是对具有相关关系的两个或两个以上变量之间数量变化的一般关系进行测定,确定一个相应的数学表达式,以便从一个已知量来推测另一个未知量,为估计预测提供一个重要的方法。回归分析按自变量的个数分,有一元回归和多元回归,按回归线的形状分,有线性回归和非线性回归。与相关分析相比,回归分析的特点是:两个变量是不对等的,必须区分自变量和因变量;因变量是随机的,自变量是可以控制的量;对于一个没有因果关系的两变量,可以求得两个回归方程,一个是y 倚x 的回归方程,一个是x 倚y 的回归方程。 简单线性回归方程式为:bx a y c +=,式中c y 是y 的估计值,a 代表直线在y 轴上的截距,b 表示直线的斜率,又称为回归系数。回归系数的涵义是,当自变量x 每增加一个单位时,因变量y 的平均增加值。当b 的符号为正时,表示两个变量是正相关,当b 的符号为负时,表示两个变量是负相关。a 、b 都是待定参数,可以用最小平方法求得。求解a 、b 的公式为: ∑∑∑∑∑--= 2 2)(x x n y x xy n b ; n x b n y a ∑∑-= 回归估计标准误差是衡量因变量的估计值与观测值之间的平均误差大小的指标。利用此 指标可以说明回归方程的代表性。其计算公式为: 2 ) (2 --= ∑n y y S c yx 或2 2 ---= ∑∑∑n xy b y a y S yx 回归估计标准误和相关系数之间具有以下关系:
案例分析报告(2014——2015学年第一学期) 课程名称:预测与决策 专业班级:电子商务1202 学号:2204120202 学生姓名:陈维维 2014 年11月
案例分析(一元线性回归模型) 我国城镇居民家庭人均消费支出预测 一、研究目的与要求 居民消费在社会经济的持续发展中有着重要的作用,居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。从理论角度讲,消费需求的具体内容主要体现在消费结构上,要增加居民消费,就要从研究居民消费结构入手,只有了解居民消费结构变化的趋势和规律,掌握消费需求的热点和发展方向,才能为消费者提供良好的政策环境,引导消费者合理扩大消费,才能促进产业结构调整与消费结构优化升级相协调,才能推动国民经济平稳、健康发展。例如,2008年全国城镇居民家庭平均每人每年消费支出为11242.85元,最低的青海省仅为人均8192.56元,最高的上海市达人均19397.89元,上海是黑龙江的2.37倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我研究的对象是各地区居民消费的差异。居民消费可分为城镇居民消费和农村居民消费,由于各地区的城镇与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城镇居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。 所以模型的被解释变量Y选定为“城镇居民每人每年的平均消费支出”。 因为研究的目的是各地区城镇居民消费的差异,并不是城镇居民消费在不同时间的变动,所以应选择同一时期各地区城镇居民的消费支出来建立模型。因此建立的是2008年截面数据模型。影响各地区城镇居民人均消费支
第10章 简单线性回归分析 思考与练习参考答案 一、最佳选择题 1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。 A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错 2.如果相关系数r =1,则一定有( C )。 A .总SS =残差SS B .残差SS =回归 SS C .总SS =回归SS D .总SS >回归SS E. 回归MS =残差MS 3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。 A .ρ=0时,r =0 B .|r |>0时,b >0 C .r >0时,b <0 D .r <0时,b <0 E. |r |=1时,b =1 4.如果相关系数r =0,则一定有( D )。 A .简单线性回归的截距等于0 B .简单线性回归的截距等于Y 或X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总 E .简单线性回归的总SS 等于0 5.用最小二乘法确定直线回归方程的含义是( B )。 A .各观测点距直线的纵向距离相等 B .各观测点距直线的纵向距离平方和最小 C .各观测点距直线的垂直距离相等 D .各观测点距直线的垂直距离平方和最小
E .各观测点距直线的纵向距离等于零 二、思考题 1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。 答:区别: (1)资料要求上,进行直线回归分析的两变量,若X 为可精确测量和严格控制的变量,则对应于每个X 的Y 值要求服从正态分布;若X 、Y 都是随机变量,则要求X 、Y 服从双变量正态分布。直线相关分析只适用于双变量正态分布资料。 (2)应用上,说明两变量线性依存的数量关系用回归(定量分析),说明两变量的相关关系用相关(定性分析)。 (3)两个系数的意义不同。r 说明具有直线关系的两变量间相互关系的方向与密切程度,b 表示X 每变化一个单位所导致Y 的平均变化量。 (4)两个系数的取值范围不同:-1≤r ≤1,∞<<∞-b 。 (5)两个系数的单位不同:r 没有单位,b 有单位。 联系: (1)对同一双变量资料,回归系数b 与相关系数r 的正负号一致。b >0时,r >0,均表示两变量X 、Y 同向变化;b <0时,r <0,均表示两变量X 、Y 反向变化。 (2)回归系数b 与相关系数r 的假设检验等价,即对同一双变量资料,r b t t =。由于相关系数r 的假设检验较回归系数b 的假设检验简单,故在实际应用中常以r 的假设检验代替b 的假设检验。 (3)用回归解释相关:由于决定系数2 R =SS 回 /SS 总 ,当总平方和固定时,回归平方 和的大小决定了相关的密切程度。回归平方和越接近总平方和,则2 R 越接近1,说明引入相关的效果越好。例如当r =0.20,n =100时,可按检验水准0.05拒绝H 0,接受H 1,认为两变量有相关关系。但2 R =(0.20)2=0.04,表示回归平方和在总平方和中仅占4%,说明
第一章 回归分析 第一节 概述 1、常见的变量间的关系 一类称为确定性关系; 一类称为非确定性关系或相关关系。 2、变量的分类 自变量:可以在某一范围内取确定数值的。 因变量或随机变量:取值可观测,但不可控制的变量。 3、回归分析及线性回归分析 研究一个(或几个)自变量于一个随机变量之间的相关关系时所建立的数学模型及所作的统计分析称为回归分析。 如果所建立的模型是线性的,就叫线性回归分析。 4、回归方程 一元回归方程: 多元回归方程: 第二节 一元线性回归分析 一、一元线性回归参数的最小二乘估计 考虑因变量y 与自变量x 的一元线性回归方程 (1) 其一元线性回归模型为: (2) 为论述方便,令: y=[y 1,y 2,……y n ]T ε=[ε1 ,ε 2……εn ]T x=[x 1,x 2, ……x n ]T 则由(2)式可构成y=A β+ε, ε~N(0,I σ2) (3) 一般采用最小二乘估计法求定β0, β1的最佳估值 ,即在 的要求下求定 利用最小二乘法求得其结果为: x y ββ+=0m m x x x y ββββ++++= 22110i i i x y εββ++=10x y ββ+= 0????????????=n x x x A 11121 ??????=10βββ10?,?ββ最小=--=)?()?(??ββεεA y A y T T 10?,?ββ
可得到一元线性回归方程为: 二、估值的性质 三、一元回归的方差分析和线性关系的显著性检验 所谓回归方程的显著性检验,就是检验假设:所有回归系数都等于零,也即检验H :β1=0 为此,我们首先把变量y 的观测值y i 与其平均值 之间的总偏离平方和Q y 分解为回 βββ????10A x y =+=)12(2?7)11(6)10(0?)9(?:?,?5)8(0)?,?(,0)?,?(:?,??.4)7())(()?(:?3)6()1()?()5(1)?(:?,?2)4(0)?(,)?(:1222221 11 21222 02110 -=?-=?==?==-=?+==?==?∑∑∑===-n Q s s s Q y y y y D y D y A A A A I D s x n D s D E E x xy y n i i n i i n i i i i i T T x x εεσσεε βεεβε σεεσββββεββ的无偏估值方差残差平方和的总和等于零而残差的总和的总和等于观测值估计值不相关与残差的方差为残差的方差估值无偏性y
(一) 填空题 1、 现象之间的相关关系按相关的程度分有________相关、________相关和_______ 相关;按相关的方向分有________相关和________相关;按相关的形式分有-________相关和________相关;按影响因素的多少分有________相关和-________相关。 2、 对现象之间变量关系的研究中,对于变量之间相互关系密切程度的研究,称为 _______;研究变量之间关系的方程式,根据给定的变量数值以推断另一变量的可能值,则称为_______。 3、 完全相关即是________关系,其相关系数为________。 4、 在相关分析中,要求两个变量都是_______;在回归分析中,要求自变量是 _______,因变量是_______。 5、 person 相关系数是在________相关条件下用来说明两个变量相关________的统 计分析指标。 6、 相关系数的变动范围介于_______与_______之间,其绝对值愈接近于_______, 两个变量之间线性相关程度愈高;愈接近于_______,两个变量之间线性相关程度愈低。当_______时表示两变量正相关;_______时表示两变量负相关。 7、 当变量x 值增加,变量y 值也增加,这是________相关关系;当变量x 值减少, 变量y 值也减少,这是________相关关系。 8、 在判断现象之间的相关关系紧密程度时,主要用_______进行一般性判断,用_______进行数量上的说明。 9、 在回归分析中,两变量不是对等的关系,其中因变量是_______变量,自变量是 _______量。 10、 已知13600))((=----∑y y x x ,14400)(2=--∑x x ,14900)(2=-∑-y y ,那么,x 和y 的相关系数r 是_______。 11、 用来说明回归方程代表性大小的统计分析指标是________指标。 12、 已知1502=xy σ,18=x σ,11=y σ,那么变量x 和y 的相关系数r 是_______。 13、 回归方程bx a y c +=中的参数b 是________,估计特定参数常用的方法是 _________。 14、 若商品销售额和零售价格的相关系数为-0.95,商品销售额和居民人均收入的相关系数为0.85,据此可以认为,销售额对零售价格具有_______相关关系,销售额与人均收入具有_______相关关系,且前者的相关程度_______后者的相关程度。 15、 当变量x 按一定数额变动时,变量y 也按一定数额变动,这时变量x 与y 之间存在着_________关系。 16、 在直线回归分析中,因变量y 的总变差可以分解为_______和_______,用公式表示,即_____________________。 17、 一个回归方程只能作一种推算,即给出_________的数值,估计_________的可能值。 18、 如估计标准误差愈小,则根据回归直线方程计算的估计值就_______ 19、 已知直线回归方程bx a y c +=中,5.17=b ;又知30=n ,∑=13500y ,
所属章节: 第五章相关分析与回归分析 1■在线性相关中,若两个变量的变动方向相反,一个变量的数值增加,另一个变量数值随之减少,或一个变量的数值减少,另一个变量的数值随之增加,则称为()。 答案: 负相关。干扰项: 正相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答: 本题的正确答案为: 负相关。 2■在线性相关中,若两个变量的变动方向相同,一个变量的数值增加,另一个变量数值随之增加,或一个变量的数值减少,另一个变量的数值随之减少,则称为()。 答案: 正相关。干扰项: 负相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答:
本题的正确答案为: 正相关。 3■下面的xx中哪一个是错误的()。 答案: 相关系数不会取负值。干扰项: 相关系数是度量两个变量之间线性关系强度的统计量。干扰项: 相关系数是一个随机变量。干扰项: 相关系数的绝对值不会大于1。 提示与解答: 本题的正确答案为: 相关系数不会取负值。 4■下面的xx中哪一个是错误的()。 答案: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 干扰项: 相关系数显著性检验的原假设是: 总体中两个变量不存在相关关系。 干扰项: 回归分析中回归系数的显著性检验的原假设是:
所检验的回归系数的真值为0。 干扰项: 回归分析中多元线性回归方程的整体显著性检验的原假设是: 自变量前的偏回归系数的真值同时为0。 提示与解答: 本题的正确答案为: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 5■根据你的判断,下面的相关系数值哪一个是错误的()。 答案: 1.25。干扰项:-0.86。干扰项: 0.78。干扰项:0。 提示与解答: 本题的正确答案为: 1.25。 6■下面关于相关系数的陈述中哪一个是错误的()。 答案: 数值越大说明两个变量之间的关系越强,数值越小说明两个变量之间的关系越弱。 干扰项:
第九章 线性回归和相关分析 9.1 什么叫做回归分析?直线回归方程和回归截距、回归系数的统计意义是什么,如何计算?如何对直线回归进行假设测验和区间估计? 9.2 a s 、b s 、x y s /、y s 、y s ?各具什么意义?如何计算(思考各计算式的异同)? 9.3 什么叫做相关分析?相关系数、决定系数各有什么具体意义?如何计算?如何对相关系数作假设测验? 9.4 什么叫做协方差分析?为什么要进行协方差分析?如何进行协方差分析(分几个步骤)?为什么有时要将i y 矫正到x 相同时的值?如何矫正? 9.5 测得不同浓度的葡萄糖溶液(x ,mg /l )在某光电比色计上的消光度(y )如下表,试计算: (1)直线回归方程y ?=a +bx ,并作图;(2)对该回归方程作假设测验;(3)测得某样品的消光度为0.60,试估算该样品的葡萄糖浓度。 x 0 5 10 15 20 25 30 y 0.00 0.11 0.23 0.34 0.46 0.57 0.71 [答案:(1)y ? =-0.005727+0.023429x ,(2)H0被否定,(3)25.85mg/l] 9.6 测得广东阳江≤25oC 的始日(x)与粘虫幼虫暴食高峰期(y)的关系如下表(x 和y 皆以8月31日为0)。试分析:(1)≤25oC 的始日可否用于预测粘虫幼虫的暴食期;(2)回归方程及其估计标准误;(3)若某年9月5日是≤25oC 的始日,则有95%可靠度的粘虫暴食期在何期间? 年份 54 55 56 57 58 59 60 x 13 25 27 23 26 1 15 y 50 55 50 47 51 29 48 [答案:(1)r=0.8424;(2)y ? =33.2960+0.7456x , x y s /=4.96;(3)9月22日~10月23日] 9.7 研究水稻每一单茎蘖的饱粒重(y ,g)和单茎蘖重(包括谷粒)(x ,g)的关系,测定52个早熟桂花黄单茎蘖,得:SSx=234.4183,SSy=65.8386,SP=123.1724,b=0.5254,r=0.99;测定49个金林引单茎蘖,得SSx=65.7950,SSy=18.6334,SP=33.5905,b=0.5105,r=0.96。试对两回归系数和相关系数的差异作假设测验,并解释所得结果的意义。 [答案: 2 1b b s -=0.0229,t <1; 2 1z z s -=0.2053,t=3.413] 9.8 下表为1963、1964、1965三年越冬代棉红铃虫在江苏东台的化蛹进度的部分资料,试作协方差分析。 x 日 期 (以6月10日为0) y 化 蛹 进 度(%) 1963年 1964年 1965年
残差分析的相关概念辨析及应用 在研究两个变量间的关系时,首先要根据散点图来粗略判断它们是否线性相关,是否可以用线性回归模型来拟合数据.然后,可以通过残差^ ^ 2^ 1,,,n e e e 来判断模型拟合的效果,判断原始数据中是否存在可疑数据.这方面的分析工作称为残差分析.残差分析一般有两种 方法:(1)作残差图;(2)利用相关指数R 2 来刻画回归效果. .,,2,1,^^^^n i a x b y y y e i i i i i =--=-= ^ i e 称为相应于点(x i ,y i )的残差.类比样本 方差估计总体方差的思想,可以用)2)(,(2 1 21^^1^2^2 >-=-=∑=n b a Q n e n n i i σ 作为σ2的估计量,其中^a 和^b 由公式x b y a ^^-=, ∑∑==---= n i i n i i i x x y y x x b 1 2 1 ^ )() )((给出,Q(^a ,^ b )称为残差 平方和.可以用^2 σ衡量回归方程的预报精度.通常,^2 σ越小,预报精度越高. 例1.设变量x,y 具有线性相关关系,试验采集了5组数据,下列几个点对应数据的采集可能有错误的是 ( ) A 点A B.点 B C.点 C D.点E 思路与技巧 由散点图判断出,点A,B,C,D,F 呈线性分布,E 点远离这个区域,说明点E 数据有问题. 解答D 评析 可以用Excel 画散点图,样本的散点图可以形象的展示两个变量的关系,画散点图的目的是用来确定回归模型的形式,若散点图呈条状分布,则x 与y 有较好的线性相关关系,散点图除了条状分布,还有其他形状的分布. 例2.为研究重量x(单位:克)对弹簧长度y(单位:厘米)的影响,对不同重量的6根弹簧进行测量,得如下数据: (1)画出散点图. (2)如果散点图中的各点大致分布在一条直线的附近,求y 与x 之间的回归直线方程. (3)求出残差,进行残差分析. 思路与技巧 可以用Excel 画散点图,由散点图发现x 与y 是否呈线性分布,由此判断x 与y 之间是否有较好的线性相关关系,若有,求出线性回归方程,再画出残差图,进行残
在此处利用两个简单的回归分析案例让初学者学会使用STATA进行回归分析。STATA版本:11.0 案例1: 某实验得到如下数据 x12345 y4 5.5 6.27.78.5 对x y 进行回归分析。 第一步:输入数据(原始方法) 1.在命令窗口输入input x y /有空格 2.回车
得到: 3.再输入: 1 4 2 5.5 3 6.2 4 7.7 5 8.5 end 4.输入list 得到 5.输入reg y x 得到回归结果 回归结果: =+ y x 3.02 1.12 T= (15.15) (12.32) R2=0.98 解释一下: SS是平方和,它所在列的三个数值分别为回归误差平方和(SSE)、残差平方和
(SSR)及总体平方和(SST),即分别为Model、Residual和Total相对应的数值。df(degree of freedom)为自由度。 MS为SS与df的比值,与SS对应,SS是平方和,MS是均方,是指单位自由度的平方和。 coef.表明系数的,因为该因素t检验的P值是0.001,所以表明有很强的正效应,认为所检验的变量对模型是有显著影响的。_cons表示常数项 6.作图可以通过Graphics——>twoway—twoway graphs——>plots——>Create 案例2:加大一点难度 1. 首先将excel另存为CSV格式文件
2. 将csv文件导入STATA, File——>import——>选第一个 3.输入list
4.进行回归 reg inc emp inv pow 5.回归结果 =-+++ 395741.718.18 4.3530.22 inc emp inv pow
一般线性回归分析案例 1、案例 为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康地影响,随机抽取了30个观测数据,基于多员线性回归分析地理论方法,对儿童体内几种必需元素与血红蛋白浓度地关系进行分析研究.这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu). 表一血红蛋白与钙、铁、铜必需元素含量 (血红蛋白单位为g;钙、铁、铜元素单位为ug) case 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30y(g) 7.00 7.25 7.75 8.00 8.25 8.25 8.50 8.75 8.75 9.25 9.50 9.75 10.00 10.25 10.50 10.75 11.00 11.25 11.50 11.75 12.00 12.25 12.50 12.75 13.00 13.25 13.50 13.75 14.00 14.25 ca 76.90 73.99 66.50 55.99 65.49 50.40 53.76 60.99 50.00 52.34 52.30 49.15 63.43 70.16 55.33 72.46 69.76 60.34 61.45 55.10 61.42 87.35 55.08 45.02 73.52 63.43 55.21 54.16 65.00 65.00 fe 295.30 313.00 350.40 284.00 313.00 293.00 293.10 260.00 331.21 388.60 326.40 343.00 384.48 410.00 446.00 440.01 420.06 383.31 449.01 406.02 395.68 454.26 450.06 410.63 470.12 446.58 451.02 453.00 471.12 458.00 cu 0.840 1.154 0.700 1.400 1.034 1.044 1.322 1.197 0.900 1.023 0.823 0.926 0.869 1.190 1.192 1.210 1.361 0.915 1.380 1.300 1.142 1.771 1.012 0.899 1.652 1.230 1.018 1.220 1.218 1.000
第十章 直线相关与回归 一、教学大纲要求 (一) 掌握内容 ⒈ 直线相关与回归的基本概念。 ⒉ 相关系数与回归系数的意义及计算。 ⒊ 相关系数与回归系数相互的区别与联系。 (二)熟悉内容 ⒈ 相关系数与回归系数的假设检验。 ⒉ 直线回归方程的应用。 ⒊ 秩相关与秩回归的意义。 (三)了解内容 曲线直线化。 二、 学内容精要 (一) 直线回归 1. 基本概念 直线回归(linear regression)建立一个描述应变量依自变量变化而变化的直线方程,并要求各点与该直线纵向距离的平方和为最小。直线回归是回归分析中最基本、最简单的一种,故又称简单回归(simple regression )。 直线回归方程bX a Y +=?中,a 、b 是决定直线的两个系数,见表10-1。 表10-1 直线回归方程a 、b 两系数对比 a b 含义 回归直线在Y 轴上的截距(intercept )。 表示X 为零时,Y 的平均水平的估计值。 回归系数(regression coefficient ),即直线的斜率。表示X 每变化一个单位时,Y 的平均变化量的估计值。 系数>0 a >0表示直线与纵轴的交点在原点的上方 b >0,表示直线从左下方走向右上方,即Y 随X 增大而增大 系数<0 a <0表示直线与纵轴的交点在原点的下方 b <0,表示直线从左上方走向右下方,即Y 随X 增大而减小 系数=0 a =0表示回归直线通过原点 b =0,表示直线与X 轴平行,即Y 不随X 的变化而变化 计算公式 X b Y a -= XX XY l l X X Y Y X X b =---= ∑∑2 )())(( 2. 样本回归系数b 的假设检验 (1)方差分析; (2)t 检验。
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: 2010年中国各地区城市居民人均年消费支出和可支配收入
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 表3 相关性 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
表4 系数a 3、结果分析 表2模型汇总:相关系数为0.965,判定系数为0.932,调整判定系数为0.930,估计值的标准误877.29128 表3是相关分析结果。消费性支出Y与可支配收入X相关系数为0.965,相关性很高。 表4是回归分析中的系数:常数项b=704.824,可支配收入X的回归系数a=0.668。a的标准误差为0.034,回归系数t的检验值为19.921,P值为0,满足95%的置信区间,可认为回归系数有显著意义。得线性回归方程Y=0.668X+704.824. 【实验结论】 (1)结果显示,变量之间具有如下关系式:Y=0.668X+704.824.也就是说消费与收入之间存在稳定的函数关系。随着收入的增加,消费将增加,但消费的增长低于收入的增长。这与凯尔斯的绝对收入消费理论刚好吻合。但为了研究方便,这里假设边际消费倾向为常数。由公式知X每增长1个单位,Y增加0.668个单位。
第七章 相关分析与回归分析 例1、有10个同类企业的固定资产和总产值资料如下: 根据以上资料计算(1)协方差和相关系数;(2)建立以总产值为因变量的一元线性回归方程;(3)当固定资产改变200万元时,总产值平均改变多少?(4)当固定资产为1300万元时,总产值为多少? 解:计算表如下: (1)协方差——用以说明两指标之间的相关方向。 2 2) )((n y x xy n n y y x x xy ∑∑∑∑- = - -= σ
35.126400100 9801 6525765915610>=?-?= 计算得到的协方差为正数,说明固定资产和总产值之间存在正相关关系。 (2)相关系数用以说明两指标之间的相关方向和相关的密切程度。 ∑∑∑ ∑∑∑∑--- = ] )(][) ([2 2 2 2 y y n x x n y x xy n r 95 .0) 980110866577 10()6525566853910(9801 65257659156102 2 =-??-??-?= 计算得到的相关系数为0.95,表示两指标为高度正相关。 (3) 2 2 26525 56685391098016525765915610) (-??-?= --= ∑∑∑∑∑x x n y x xy n b 90 .014109765 126400354257562556685390 6395152576591560== --= 85 .39210 65259.010 9801=? -= -=x b y a 回归直线方程为: x y 9.085.392?+= (4)当固定资产改变200万元时,总产值平均改变多少? x y ?=?9.0,180 2009.0|200=?=?=?x y 万元 当固定资产改变200万元时,总产值平均增加180万元。 (5)当固定资产为1300万元时,总产值为多少? 85 .156213009.085.392|1300=?+==x y 万元 当固定资产为1300万元时,总产值为1562.85万元。 例2、试根据下列资产总值和平均每昼夜原料加工量资料计算相关系数。
线性回归方程中的相关系数r r=∑(Xi-X的平均数)(Yi-Y平均数)/根号下[∑(Xi-X平均数)^2*∑(Yi-Y平均数)^2]
R2就是相关系数的平方, R在一元线性方程就直接是因变量自变量的相关系数,多元则是复相关系数 判定系数R^2 也叫拟合优度、可决系数。表达式是: R^2=ESS/TSS=1-RSS/TSS 该统计量越接近于1,模型的拟合优度越高。 问题:在应用过程中发现,如果在模型中增加一个解释变量,R2往往增大 这就给人一个错觉:要使得模型拟合得好,只要增加解释变量即可。 ——但是,现实情况往往是,由增加解释变量个数引起的R2的增大与拟合好坏无关,R2需调整。 这就有了调整的拟合优度: R1^2=1-(RSS/(n-k-1))/(TSS/(n-1)) 在样本容量一定的情况下,增加解释变量必定使得自由度减少,所以调整的思路是:将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响: 其中:n-k-1为残差平方和的自由度,n-1为总体平方和的自由度。 总是来说,调整的判定系数比起判定系数,除去了因为变量个数增加对判定结果的影响。R = R接近于1表明Y与X1,X2 ,…,Xk之间的线性关系程度密切; R接近于0表明Y与X1,X2 ,…,Xk之间的线性关系程度不密切 相关系数就是线性相关度的大小,1为(100%)绝对正相关,0为0%,-1为(100%)绝对负相关 相关系数绝对值越靠近1,线性相关性质越好,根据数据描点画出来的函数-自变量图线越趋近于一条平直线,拟合的直线与描点所得图线也更相近。 如果其绝对值越靠近0,那么就说明线性相关性越差,根据数据点描出的图线和拟合曲线相差越远(当相关系数太小时,本来拟合就已经没有意义,如果强行拟合一条直线,再把数据点在同一坐标纸上画出来,可以发现大部分的点偏离这条直线很远,所以用这个直线来拟合是会出现很大误差的或者说是根本错误的)。 分为一元线性回归和多元线性回归 线性回归方程中,回归系数的含义 一元: Y^=bX+a b表示X每变动(增加或减少)1个单位,Y平均变动(增加或减少)b各单位多元: Y^=b1X1+b2X2+b3X3+a 在其他变量不变的情况下,某变量变动1单位,引起y平均变动量 以b2为例:b2表示在X1、X3(在其他变量不变的情况下)不变得情况下,X2每变动1单位,y平均变动b2单位
S T A T A第一章回归 分析
在此处利用两个简单的回归分析案例让初学者学会使用STATA进行回归分析。STATA版本:11.0 案例1: 某实验得到如下数据 x 1 2 3 4 5 y 4 5.5 6.2 7.7 8.5 对x y 进行回归分析。 第一步:输入数据(原始方法) 1.在命令窗口输入 input x y /有空格 2.回车
得到: 3.再输入: 1 4 2 5.5 3 6.2 4 7.7 5 8.5 end 4.输入list 得到 5.输入 reg y x 得到回归结果 回归结果: =+ 3.02 1.12 y x
T= (15.15) (12.32) R2=0.98 解释一下: SS是平方和,它所在列的三个数值分别为回归误差平方和(SSE)、残差平方和(SSR)及总体平方和(SST),即分别为Model、Residual和Total相对应的数值。 df(degree of freedom)为自由度。 MS为SS与df的比值,与SS对应,SS是平方和,MS是均方,是指单位自由度的平方和。 coef.表明系数的,因为该因素t检验的P值是0.001,所以表明有很强的正效应,认为所检验的变量对模型是有显著影响的。_cons表示常数项 6.作图可以通过Graphics——>twoway—twoway graphs——>plots——>Create 案例2:加大一点难度 1. 首先将excel另存为CSV格式文件
2. 将csv文件导入STATA, File——>import——>选第一个
3.输入 list 4.进行回归 reg inc emp inv pow 5.回归结果 =-+++ 395741.718.18 4.3530.22 inc emp inv pow
回归分析与相关分析联系、区别?? 简单线性回归分析是对两个具有线性关系的变量,研究其相关性,配合线性回归方程,并根据自变量的变动来推算和预测因变量平均发展趋势的方法。 回归分析(Regression analysis)通过一个变量或一些变量的变化解释另一变量的变化。 主要内容和步骤:首先依据经济学理论并且通过对问题的分析判断,将变量分为自变量和因变量,一般情况下,自变量表示原因,因变量表示结果;其次,设法找出合适的数学方程式(即回归模型)描述变量间的关系;接着要估计模型的参数,得出样本回归方程;由于涉及到的变量具有不确定性,接着还要对回归模型进行统计检验,计量经济学检验、预测检验;当所有检验通过后,就可以应用回归模型了。 回归的种类 回归按照自变量的个数划分为一元回归和多元回归。只有一个自变量的回归叫一元回归,有两个或两个以上自变量的回归叫多元回归。 按照回归曲线的形态划分,有线性(直线)回归和非线性(曲线)回归。 相关分析与回归分析的关系 (一)相关分析与回归分析的联系 相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。 (二)相关分析与回归分析的区别 1.相关分析中涉及的变量不存在自变量和因变量的划分问题,变量之间的关系是对等的;而在回归分析中,则必须根据研究对象的性质和研究分析的目的,对变量进行自变量和因变量的划分。因此,在回归分析中,变量之间的关系是不对等的。 2.在相关分析中所有的变量都必须是随机变量;而在回归分析中,自变量是确定的,因变量才是随机的,即将自变量的给定值代入回归方程后,所得到的因变量的估计值不是唯一确定的,而会表现出一定的随机波动性。 3.相关分析主要是通过一个指标即相关系数来反映变量之间相关程度的大小,由于变量之间是对等的,因此相关系数是唯一确定的。而在回归分析中,对于互为因果的两个变量(如人的身高与体重,商品的价格与需求量),则有可能存在多个回归方程。 需要指出的是,变量之间是否存在“真实相关”,是由变量之间的内在联系所决定的。相关分析和回归分析只是定量分析的手段,通过相关分析和回归分析,虽然可以从数量上反映变量之间的联系形式及其密切程度,但是无法准确判断变量之间内在联系的存在与否,也无法判断变量之间的因果关系。因此,在具体应用过程中,一定要注意把定性分析和定量分析结合起来,在定性分析的基础上展开定量分析。
1、 变量间统计关系和函数关系的区别是什么 答:函数关系是一种确定性的关系,一个变量的变化能完全决定另一个变量的变化;统计关系是非确定的,尽管变量间的关系密切,但是变量不能由另一个或另一些变量唯一确定。 2、 回归分析与相关分析的区别和联系是什么 答:联系:刻画变量间的密切联系; 区别:一、回归分析中,变量y 称为因变量,处在被解释的地位,而在相关分析中,变量y 与x 处于平等地位;二、相关分析中y 与x 都是随机变量,而回归分析中y 是随机的,x 是非随机变量。三、回归分析不仅可以刻画线性关系的密切程度,还可以由回归方程进行预测和控制。 3、 回归模型中随机误差项ε的意义是什么主要包括哪些因素 答:随机误差项ε的引入,才能将变量间的关系描述为一个随机方程。主要包括:时间、费用、数据质量等的制约;数据采集过程中变量观测值的观测误差;理论模型设定的误差;其他随机误差。 4、 线性回归模型的基本假设是什么 答:1、解释变量非随机;2、样本量个数要多于解释变量(自变量)个数;3、高斯-马尔科夫条件;4、随机误差项相互独立,同分布于2(0,)N σ。 5、 回归变量设置的理论根据在设置回归变量时应注意哪些问题 答:因变量与自变量之间的因果关系。需注意问题:一、对所研究的问题背景要有足够了解;二、解释变量之间要求不相关;三、若某个重要的变量在实际中没有相应的统计数据,应考虑用相近的变量代替,或者由其他几个指标复合成一个新的指标;四、解释变量并非越多越好。 6、 收集、整理数据包括哪些内容 答:一、收集数据的类型(时间序列、截面数据);二、数据应注意可比性和数据统计口径问题(统计范围);三、整理数据时要注意出现“序列相关”和“异
第八章相关与回归分析 一、本章重点 1.相关系数的概念及相关系数的种类。事物之间的依存关系,可以分为函数关系和相关关系。相关关系又有单向因果关系和互为因果关系;单相关和复相关;线性相关和非线性相关;不相关、不完全相关和完全相关;正相关和负相关等类型。 2.相关分析,着重掌握如何画相关表、相关图,如何测定相关系数、测定系数以及进行相关系数的推断。相关表和相关图是变量间相关关系的生动表示,对于未分组资料和分组资料计算相关系数的方法是不同的,一元线性回归中相关系数和测定系数有着密切的关系,得到样本相关系数后还要对总体相关系数进行科学推断。 3.回归分析,着重掌握一元回归的基本原理方法,一元回归是线性回归的基础,多元线性回归和非线性回归都是以此为基础的。用最小平方法估计回归参数,回归参数的性质和显著性检验,随机项方差的估计,回归方程的显著性检验,利用回归方程进行预测是回归分析的主要内容。 4.应用相关与回归分析应注意的问题。相关与回归分析都有它们的应用范围,必须知道在什么情况下能用,什么情况下不能用。相关分析和回归分析必须以定性分析为前提,否则可能会闹出笑话,在进行预测时选取的样本要尽量分散,以减少预测误差,在进行预测时只有在现有条件不变的情况下才能进行,如果条件发生了变化,原来的方程也就失去了效用。 二、难点释疑 本章难点在于计算公式多,不容易记忆,所以更要注重计算的练习。为了掌握基本计算的内容,起码应认真理解书上的例题,做完本指导书上的全部计算题。初学者可能会感到本章公式多且复杂,难于记忆,其实只要抓住Lxx、Lxy、Lyy 这三个记号,记住它们的展开式,几个主要的公式就不难记忆了。如果能自己把这些公式推证一下,搞清其关系,那就更容易记住了。 三、练习题 (一)填空题 1事物之间的依存关系,根据其相互依存和制约的程度不同,可以分为()和()两种。 2.相关关系按相关关系的情况可分为()和();按自变量的多少分()和();按相关的表现形式分()和();按相关关系的