数据分析期末试题及答案
一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分)
解:
1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系
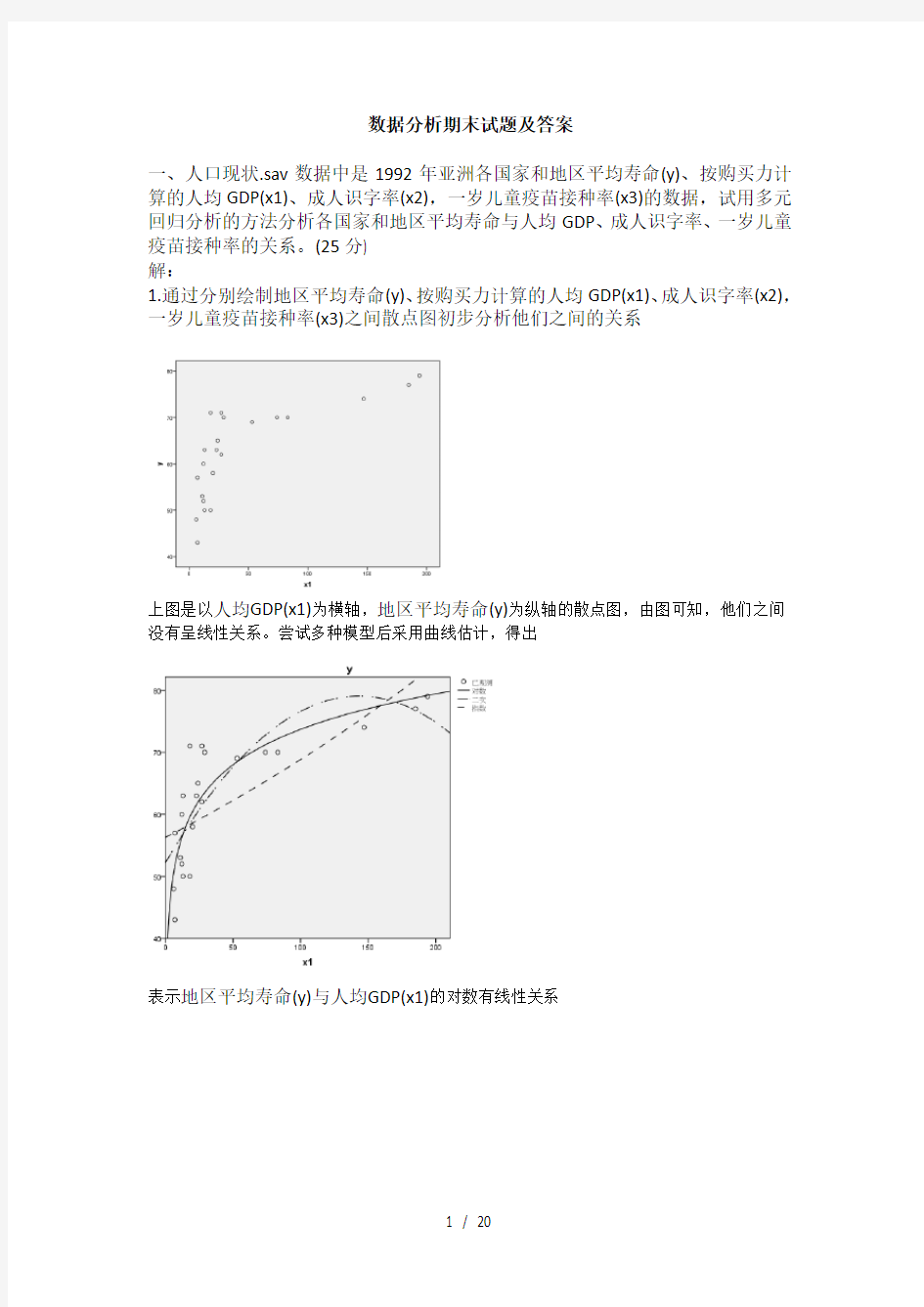
上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出
表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
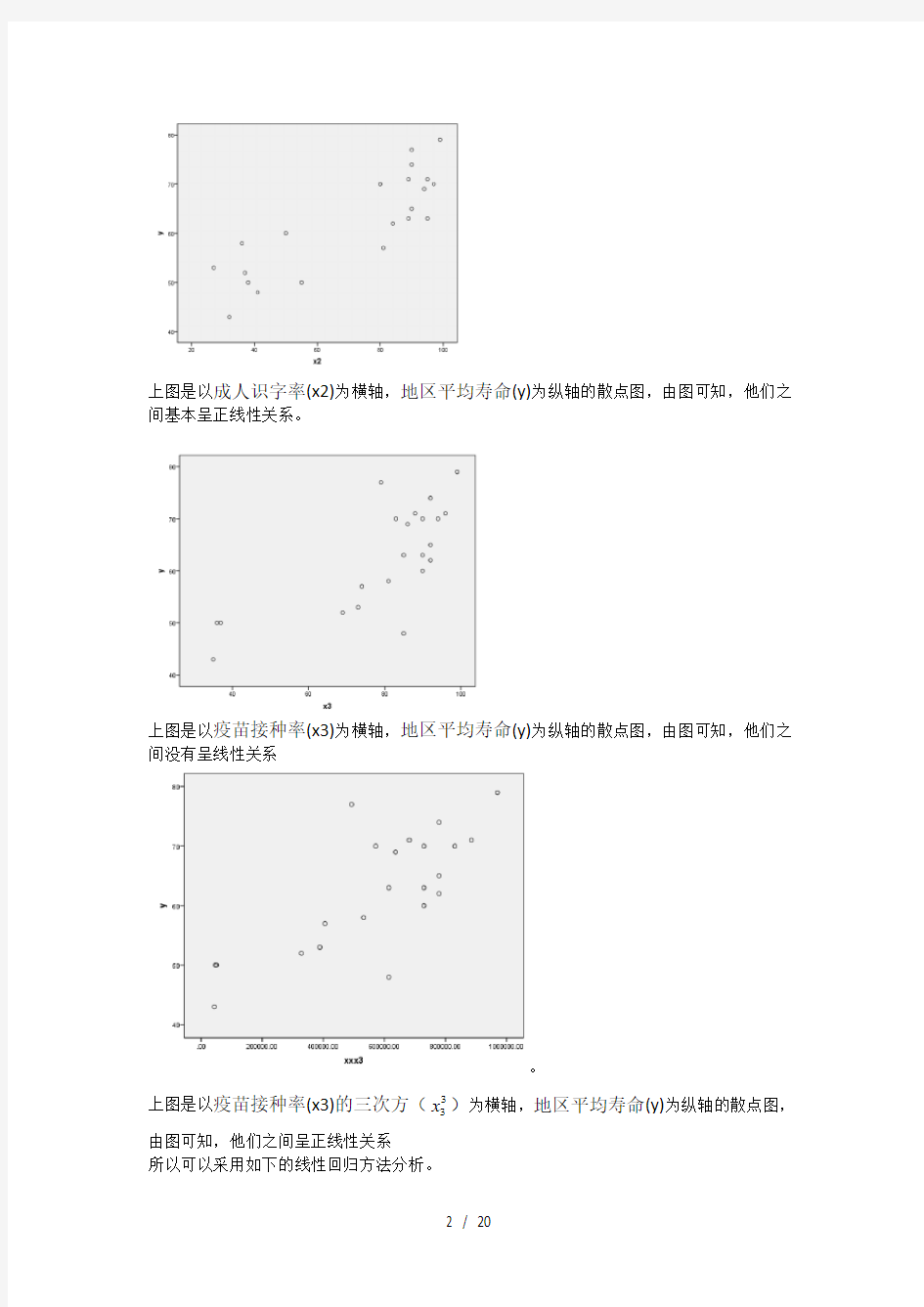
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。
上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系
。
x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3
3
由图可知,他们之间呈正线性关系
所以可以采用如下的线性回归方法分析。
2.线性回归
先用强行进入的方式建立如下线性方程
设Y=β0+β1*(Xi1)+β2*Xi2+β3*
X+εi i=1.2 (24)
3i
其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差
R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。
建立总体性的假设检验
提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零
得如下方差分析表
上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
做独立性的假设检验得出参数估计表
2=β3=0:H1:β1、β2、β3不全为零
由表知,
β1=33.014,β1=0.072,β2=0.169,β3=0.178,以β1=0.072为例,表示当成人
识字率(x2),一岁儿童疫苗接种率(x3)不变时,,人均GDP(x1)每增加一个单位,平
均寿命(y)就增加0.072个单位。
基于以上结果得出年平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗
接种率(x3)之间有显著性的线性关系有回归方程
Y=33.014+0.072*X1+ 0.169*X2+ 0.178*X3
β1、β2、β3对应得p值分别为0.000,0.000,0.002,对应的概率p值都小于0.05,
表示它们的单独性的假设检验没通过,即该模型是最优的,所以不用采用逐步回
归的方式分析。
对原始数据进行残差分析
未标准化的残差RES_1
-7.53964
-3.57019
-3.42221
-2.89835
-2.30455
-2.17263
-2.05862
-1.37142
-1.17048
-.43890
-.17260
-.03190
.94655
1.42896
1.61252
1.61590
2.10139
3.01856
3.02571
3.49808
4.60737
5.29645
以X1为横轴,RES_1为纵轴画出如下散点图
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
同理可以得出RES_1与X2、X3的散点图,
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
误差项的正态性检验
数据(RES_1)标准化残差ZRES_1
由图可以看出,散点图近似的在一条直线附近,则可以认为数据来自正太分布总体
二、诊断发现运营不良的金融企业是审计核查的一项重要功能,审计核查的分类失败会导致灾难性的后果。下表列出了66家公司的部分运营财务比率,其中33家在2年后破产Y=0,另外33家在同期保持偿付能力(Y=1)。请用变量X1(未分配利润/总资产),X2(税前利润/总资产)和X3(销售额/总资产)拟合一个Logistic 回归模型,并根据模型给出实际意义的分析,数据见财务比率.sav(25分)。 解:
整体性的假设检验 提出假设性检验
H0:回归系数i β=0(i=1,2,3),H1:不都为0 建立logistic 模型:
)}
0{1}
0{ln(
=-=Y p Y p =3
213210X X X ββββ+++
分类表a,b
已观测 已预测
Y
百分比校正
1
步骤 0
Y
0 0 33 .0 1
0 33
100.0
上表显示了logistic分析的初始阶段方程中只有常数项时的错判矩阵,其中33家在2年后破产(y=0),但模型均预测为错误,正确率为0%,另外33家在同期保持偿付能力(Y=1),正确率为100%,所以模型总的预测正确率为50%。
由上表得知,如果变量X1(未分配利润/总资产),X2(税前利润/总资产)进入方程,概率p值都为0.000,小于显著性水平0.05,本应该是拒绝原假设,X1,X2是可以进入方程的。而X3(销售额/总资产)进入方程,概率p值为0.094,大于显著性水平0.05,本应该是接受原假设,X3(销售额/总资产)是不能进入方程的,但这里的解释变量的筛选策略为enter,是强行进入方程的。
用强行全部进入
-2倍的对数似然函数值越小表示模型的拟合优度越高,这里的值是5.791,比较小,表示模型的拟合优度还可以,而且Nagelkerke R 方为0.969,与0相比还是比较大的,所以拟合度比较高
上表显示了logistic 分析的初始阶段方程中只有常数项时的错判矩阵,其中33家在2年后破产(y=0),但模型预测出了32家,正确率为97%,另外33家在同期保持偿付能力(Y=1),模型预测出了32家,正确率为97%,所以模型总的预测正确率为97%,较之前的有很大的提高。
上表给出了方程中变量的系数。由表得出
160
.5,180.0,336.0,334.10,3210===-=ββββ
以
1β为例,表示控制变量X2(税前利润/总资产)和X3(销售额/总资产)不变,X1(未分
配利润/总资产)每增加一个单位,)}
0{1}
0{ln(
=-=Y p Y p 增加0.336分单位
模型方程:
)}
0{1}
0{ln(
=-=Y p Y p = 4.160X3X2180.00.336X1-10.334-++
Logistic 回归方程: P{Y=0}=
)4.160X3X2180.00.336X1--10.334ex p(1)4.160X3X2180.00.336X1--10.334ex p(+++++
由表得知,X1到X3对应的概率p 值都大于0.05,接受原假设,表示X1到X3对Y 都没有显著性影响。所以用下述方法改进。
用向前步进(wald )
-2倍的对数似然函数值越小表示模型的拟合优度越高,这里的值是9.472,比之前的5.791要大,表示拟合优度降低,表示用向前的方法并没有比进入的方法好
而且从上表知道总的预测百分比为97%,没有变化,所以这一步较之前的强行进入的方法没什么优化,也就是没什么必要用向前的方法做。
所以有最优的一个Logistic 回归模型为 模型方程:
)}
0{1}
0{ln(
=-=Y p Y p = 4.160X3X2180.00.336X1-10.334-++
Logistic 回归方程: P{Y=0}=
)4.160X3X2180.00.336X1--10.334ex p(1)4.160X3X2180.00.336X1--10.334ex p(+++++
三、为了研究几个省市的科技创新力问题,现在取了2005年8个省得15个科技指标数据,试用因子分析方法来分析一个省得科技创新能力主要受到哪些潜在因素的影响。数据见8个省市的科技指标数据.sav ,其中各个指标的解释如下:(25分)
X1:每百万人科技活动人员数(人/万人)
X2: 从事科技活动人员中科学技术、工程师所占比重(%) X3 :R&D 人员占科技胡哦哦的呢人员的比重(%) X4:大专以上学历人口数占总人口数的比例(%) X5 :地方财政科技拨款占地方财政支出的比重(%) X6:R&D 经费占GDP 比重(%)
X7:R&D 经费中挤出研究所占比例(%) X8:人均GDP(元/人)
X9:高科技产品出口额占商品出口额的比重(%) X10: 规模以上产业增加值中高技术产业份额(%)
X11 :万名科技人员被国际三大检索工具收录的论文数(篇/百万人) X12 :每百万人口发明专利的授权量(件/百万人)
X13:发明专利申请授权量占专利申请授权量的比重(%)X14 :万人技术市场成交合同金额(万元/万人)
X15 :财政性教育经费支出占GDP比重(%)
解:
丁璐璐-英雄联盟网络游戏的营销策略分析
沈阳工学院 学年论文 题目:英雄联盟网络游戏的营销策略分析 学院:经济与管理学院 专业:市场营销 学号: 1520110537 学生姓名:丁璐璐 指导教师:董乃群 2017年1月6日
摘要 随着中国互联网络游戏产业的出现和发展,游戏行业这些年来也不断的变化更新中。网络游戏这个产业从初步发展到现在的蓬勃发展,这都归结于网络游戏行业资金得到迅速聚集,高利润使得许多竞争者大量研发新型、大型网络游戏,以及用户的成倍增长这些因素共同促进而成。 《英雄联盟》(简称LOL)是由美国拳头游戏(Riot Games)开发、中国大陆游戏代理运营的英雄对战MOBA竞技网游。游戏里拥有数百个个性英雄,并拥有排位系统、天赋系统、符文系统等特色养成系统。《英雄联盟》还致力于推动全球电子竞技的发展,除了联动各赛区发展职业联赛,每年还会举办“季中冠军赛”“全球总决赛”“All Star全明星赛”三大世界级赛事,获得了亿万玩家的喜爱,形成了自己独有的电子竞技文化。 本文主要分为六个部分。第一部写了研究的背景以及意义;第二部分主要写了英雄联盟的游戏规模、营销策略和存在问题;第三部分写了英雄联盟的竞争环境和SWOT分析;第四部分为英雄联盟的优化策略;第五部分为英雄联盟的 4P策略;第六部分是结论。 关键词:英雄联盟;营销策略;LOL
目录 摘要............................................................Ⅰ 目录............................................................Ⅱ 绪论............................................................1 1英雄联盟营销现状...............................................3 1.1英雄联盟的游戏规模.........................................3 1.2英雄联盟的营销策略.........................................4 1.3英雄联盟营销存在问题.......................................7 2英雄联盟竞争分析...............................................7 2.1英雄联盟的竞争环境.........................................7 2.2英雄联盟的SWOT分析....................................16
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
数据分析期末试题及答案 一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分) 解: 1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系 上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出 表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。 上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系 。 x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3 3 由图可知,他们之间呈正线性关系 所以可以采用如下的线性回归方法分析。
2.线性回归 先用强行进入的方式建立如下线性方程 设Y=β0+β1*(Xi1)+β2*Xi2+β3* X+εi i=1.2 (24) 3i 其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差 R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。 建立总体性的假设检验 提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零 得如下方差分析表 上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
电子商务公司网站分析几大模块 电子商务火热,客观上也让网站分析的需求激增,无论是出于何种目的,例如希望获得更多潜在客户,或是希望压缩成本,又或是希望提升用户体验,业务需求 一.业务需求: 1. 市场推广方式是否有效,以及能否进一步提效; 2. 访问网站的用户是否是目标用户,哪种渠道获取的用户更有价值(跟第一个需求有交集也有不同); 3. 用户对网站的感觉是好还是不好,除了商品本身之外的哪些因素影响用户的感觉; 4. 除了撒谎外,什么样的商业手段能够帮助说服客户购买; 5. 从什么地方能够进一步节约成本; 6. 新的市场机会在哪里,哪些未上架的商品能够带来新的收入增长。2.网站分析实施 1. 网站URL的结构和格式 2. 流量来源的标记 3. 端到端的ROI监测实施 4. 每个页面都正确置入了监测代码吗 三. 在线营销 1. SEO的效果衡量 2. SEM和硬广的效果衡量 3. EDM营销效果衡量 4. 所有营销方式的综合分析 4.网站上的影响、说服和转化 预置的影响点和说服点的评估 2. 识别潜在的影响点和说服点 3. 购物车和支付环节仍然是重中之重
五.访问者与网站的互动参与 访问者互动行为研究包括: (1)内部搜索分析; (2)新访问者所占的比例、数量趋势和来源; (3)旧访问者的访问数量趋势、比例和来源; (4)访问频次和访问间隔时间; (5)访问路径模式 商品研究包括: (1)关注和购买模型; (2)询价和购买模型;访问者来询价,还是来购买,在具体行为上是有区别的。 (3)内部搜索分析 其他重要的关联因素: 狭义的网站分析领域: 地域细分的销售额、访问者和商品关注情况; 客户端情况;例如操作系统,浏览器软件,带宽,访问网站的速度等等; 广义的网站分析领域: 网站分析测试:A/B测试和多变量测试 用户可用性测试; 调研; 用户人群属性研究; 站内IWOM分析; 站外IWOM分析 1. 市场推广方式是否有效,以及能否进一步提效; 网站分析能够全面衡量效果,并据此提效 2. 访问网站的用户是否是目标用户,哪种渠道获取的用户更有价值 3. 用户对网站的感觉是好还是不好,除了商品本身之外的哪些因素影响
大数据分析的六大工具介绍 2016年12月 一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分学在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设il?的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式, 相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二.第一种工具:Hadoop Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是 以一种可黑、高效、可伸缩的方式进行处理的。Hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。此外,Hadoop依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地 在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下儿个优点: ,高可黑性。Hadoop按位存储和处理数据的能力值得人们信赖。,高扩展性。Hadoop是 在可用的计?算机集簇间分配数据并完成讣算任务 的,这些集簇可以方便地扩展到数以千计的节点中。 ,高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动 态平衡,因此处理速度非常快。 ,高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败 的任务重新分配。 ,Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非 常理想的。Hadoop上的应用程序也可以使用其他语言编写,比如C++。 第二种工具:HPCC HPCC, High Performance Computing and Communications(高性能计?算与通信)的缩写° 1993年,山美国科学、工程、技术联邦协调理事会向国会提交了“重大挑战项 U:高性能计算与通信”的报告,也就是被称为HPCC计划的报告,即美国总统科学战略项U ,其U的是通过加强研究与开发解决一批重要的科学与技术挑战 问题。HPCC是美国实施信息高速公路而上实施的计?划,该计划的实施将耗资百亿 美元,其主要U标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络 传输性能,开发千兆比特网络技术,扩展研究和教育机构及网络连接能力。
2018年度全平台直播行业白皮书 致力于服务主播 小葫芦
2017年小葫芦通过海量的主播数据对直播行业做了详细的总结,2018年 小葫芦数据的覆盖量已扩展到了全平台3600万以上的直播间,在各直播平台争相上市,短视频风生水起的一年,小葫芦2018年直播行业白皮书对直播行业有哪些总结? PS:数据全覆盖虎牙、斗鱼、YY、快手、B站、企鹅电竞、熊猫等28家主流平台。 序言
01 OPTION 02 OPTION 03 OPTION 04 OPTION 年度总体数据 2018年度全平台直播行业浅析 主播礼物数据 2018年主播礼物收入究竟如何 主播弹幕数据 2018年主播弹幕文化究竟如何 主播特征数据 2018年主播有意思的特征数据 目 录 页
01.年度总体数据 总体数据对比送礼月度数据弹幕月度数据直播时长数据直播分类情况直播开播频次
总体数据对比 10 20 30 40 50 60 70 80 90 10010 20 30 40 50 60 70 80 90100 1,453,192人87,424,650人21,006,937,229条 35,524年209,725,063人 2,172,030人143,227,648人45,247,211,652条58,937年337,812,960人 新增主播送礼人数弹幕数量直播时长互动人数 2017年 此为2017年全年的直播行业相关数据,整体对比2018年略逊一筹。2018年 此为2018年全年直播行业相关数据,对比2017年占比均有提升。
送礼人数月度数据 2018年送礼总人数 2018年全平台送礼总人数达到惊人的143,227,648,相比2017年87,424,650增幅63%。 后半年送礼人数增加 从7月份开始,2018年后半年参与直播送礼的人数有所增加。 8月,9月送礼人数最多 8月和9月送礼人数居多,寒暑假,依旧是直播的高峰期,学生群体人数众 多。
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
数据分析练习题 第 小组 姓名: 练习一: 1、老师在计算学期总平均分的时候按如下标准:作业占100%、测验占30%、期中占35%、期末考试占35% x 小关 = . x 小兵 = . 2、结果如下表:(单位:小时) 求这些灯泡的平均使用寿命? . x = .小时 3、在一个样本中,2出现了x 1次,3出现了x 2次,4出现了x 3次,5出现了x 4次,则这个样本的平均数为 . 4、某人打靶,有a 次打中x 环,b 次打中y 环,则这个人平均每次中靶 环。 5、某校为了了解学生作课外作业所用时间的情况,对学生作课外作业所用时间进行调查,下表是该校初二某班50名学生某一天做数学课外作业所用时间的情况统计表 (1)、第二组数据的组中值是多少? (2)、求该班学生平均每天做数学作业所用时间 答:(1)组中值为: . (2)解: 6、某公司有15名员工,他们所在的部门及相应每人所创的年利润如下表该公司每人所创年利润的平均数是多少万元?
7、为调查居民生活环境质量,环保局对所辖的50个居民区进行了噪音(单位:分贝)水平的调查,结果如下图,求每个小区噪音的平均分贝数。 8、某公司销售部有营销人员15人,销售部为了制定某种商品的销售金额,统计了这15个人的销售量如下(单位:件) 1800、510、250、250、210、250、210、210、150、210、150、120、120、210、150 求这15个销售员该月销量的中位数和众数。 假设销售部负责人把每位营销员的月销售定额定为320件,你认为合理吗?如果不合理,请你制定一个合理的销售定额并说明理由。 练习二: 1. 数据8、9、9、8、10、8、99、8、10、7、9、9、8的中位数是 ,众数是 2. 一组数据23、27、20、18、X 、12,它的中位数是21,则X 的值是 . 3. 数据92、96、98、100、X 的众数是96,则其中位数和平均数分别是( ) A.97、96 B.96、96.4 C.96、97 D.98、97 4. 如果在一组数据中,23、25、28、22出现的次数依次为2、5、3、4次,并且没有其他的数据, 则这组数据的众数和中位数分别是( ) A.24、25 B.23、24 C.25、25 D.23、25 请你根据上述数据回答问题: (1).该组数据的中位数是什么? (2).若当气温在18℃~25℃为市民“满意温度”,则我市一年中达到市民“满意温度”的大约有多少天? 60 噪音/分贝 80 70 50 40 90
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
数据分析系统 操作手册 目录 一、前言 (2) 1.1、编写目的 (2) 1.2、读者对象 (2) 二、系统综述 (3) 2.1、系统架构 (3) 2.1.1系统浏览器兼容 (3) 三、功能说明 (4) 3.1、登录退出 (4) 3.1.1、登录 (4) 3.1.2、退出 (4) 3.1.3、用户信息 (5) 3.2、仪表盘 (5) 3.2.1、报表选择 (6) 3.2.2、布局方式 (7) 3.2.3、仪表盘管理 (8) 3.2.4、单个报表 (10) 3.3、应用中心 (13) 3.3.1、数据搜索 (13) 3.4、策略配置 (39)
3.4.1、数据采集 (39) 3.4.2、报表 (46) 3.4.3、数据类型 (53) 3.4.4、预设搜索 (58) 3.5、系统管理 (61) 3.5.1、代理注册设置 (61) 3.5.2、用户角色 (62) 3.5.3、系统用户 (65) 四、附件 (67) 一、前言 1.1、编写目的 本文档主要介绍日志分析系统的具体操作方法。通过阅读本文档,用户可以熟练的操作本系统,包括对服务器的监控、系统的设置、各类设备日志源的配置及采集,熟练使用日志查询、日志搜索功能,并掌握告警功能并能通过告警功能对及日志进行定位及分析。 1.2、读者对象 系统管理员:最终用户
项目负责人:即所有负责项目的管理人员 测试人员:测试相关人员 二、系统综述 2.1、系统架构 系统主界面为所有功能点的入口点,通过主菜单可快速定位操作项。系统主要分为四大模块,分别为 1):仪表盘 2):应用中心 3):策略配置 4):系统管理 2.1.1系统浏览器兼容 支持的浏览器 IE版本IE8至IE11等版本 Chrome 36及以上版本 Google chrome(谷歌 浏览器) Firefox 30及以以上版本 Mozilla Firefox (火 狐浏览器)
还不会选英雄阵容?python来帮你carry全场 欢迎来到召唤术峡谷~”英雄联盟作为一款长青游戏,风靡了这么多年,2018全球总决赛的IG冠军一出更是引发了众多撸迷又将游戏重新拾起。 今天我们就来分析一下战队的阵容选择会对胜率带来什么样的影响。 1.载入必要的包 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from pyecharts import Radar 2.读取并观察数据情况 dat_hero=pd.read_csv('TeamHero_index.csv') dat_hero.head()
3.数据分析 (1)红蓝方因素对胜负的影响 众所周知,在英雄联盟中,由于蓝方会先手ban英雄及pick英雄,因此通常蓝方的胜率更高一些。让我们来看看数据是否能够印证这一点。 取出红方获胜的数据: red_win1=dat_hero[dat_hero['是否红方'].isin(['1'])] red_win1=red_win1[red_win1['是否获胜'].isin(['1'])] red_win2=dat_hero[dat_hero['是否红方'].isin(['0'])] red_win2=red_win2[red_win2['是否获胜'].isin(['0'])] red_win=pd.concat([red_win1,red_win2]) red_win.shape (208,8) 取出蓝方获胜的数据 blue_win1=dat_hero[dat_hero['是否红方'].isin(['1'])] blue_win1=blue_win1[blue_win1['是否获胜'].isin(['0'])] blue_win2=dat_hero[dat_hero['是否红方'].isin(['0'])] blue_win2=blue_win2[blue_win2['是否获胜'].isin(['1'])] blue_win=pd.concat([blue_win1,blue_win2]) blue_win.shape (316,8) 画出红蓝方胜场直方图
数据分析方法课程设计
题目概述: 3、调查美国50个州7种犯罪率,得结果列于表1,其中给出的是美国50个州每100 000 个人中七种犯罪的比率数据。这七种犯罪是:murder(杀人罪),rape(强奸罪),robbery(抢劫罪),assault(斗殴罪),burglary(夜盗罪),larceny(偷盗罪),auto(汽车犯罪)。
1)基于变量()的观测值,求样本协 方差矩阵S和样本相关系数矩阵R; 2)分别从S和R。出发做主成分分析: (1)求样本主成分的贡献率、累计贡献率和各个样本主成分; (2)在两种情况下,你认为应该保留几个主成分,其意义如何解释?(提示:要求累计贡献率达到80%以上)就此题而言,你认为基于S和R的分析结果哪个更 合理? (3)按第一主成分得分将美国50个州排序,结果如何? (4)作以第一主成分得分为横坐标,第二主成分得分为纵坐标的散点图。 L快速聚类和类平均距离谱系聚3)对表1的美国50个州七种犯罪的比率数据,分别试用 2.5 类法将美国50个州分4类,并对聚类结果进行分析和比较。从聚类结果看,你认为哪种分类方法好? 问题一 采用sas得到样本协方差矩阵S:
样本相关系数矩阵R: 问题二 1、从R进行主成分分析: (1)、求样本主成分的贡献率、累计贡献率和各个样本主成分。 贡献率: (2)累计贡献率到达80%以上,需保留三个主成分,前三个成分的累计贡献率已达到86.9%。
由此三个主成分: PRIN1=0.300279murder+ 0.431759 rape+0.396875 robbery+0.396652assault+ 0.440157 burglary +0.357360arceny +0.295177auto PRIN2=-0.629174muder-0.169435rape+0.042247robbery-0.343528asault+0.203341bur glary+ 0.402319larceny+0.502421auto PRIN3=0.178245muder-0.2442rape+0.495861robbery-0.06951asault- 0.2099burglary- 0.5392larceny+0.568auto 从S进行主成分分析: 贡献率: 特征向量: 累计贡献率:第一个成分贡献率已达到87.36%。主成分表达式: PRIN1=0.000864muder+0.008773rape+0.056993robbery+0.059196asault+ 0.465346burglary+0.872863larceny+0.121384auto 分析: 由于第一主成分对所有变量都有近似相等的载荷,因此可认为第一主成分是对所有犯罪率的总度量。第二主成分在变量auto和larceny上有高的正载荷,而在变量murder和assault上有高的负载荷;在burglary上存在小的正载荷,而在rape上存在小的负载荷。可以认为,这个主成分是用于度量暴力犯罪在犯罪性质上占的比重。第三主成分很难给出明显的解释。在依PRIN1排序的结果表中,排在前面的PRIN1值较小的州犯罪率较低,即北达科他NORTH DAKOTA(PRIN1= -3.96408)州犯罪率最低,PRIN1值较大的州,犯罪率较高,即内华达NEV ADA(PRIN1= 5.26699)州犯罪率最高。在依PRIN2排序的结果表35.4中,排在前面的PRIN2值较小州的暴力犯罪性质比重较大。
第一课SAS 系统简介 一.SAS 系统 1什么是SAS 系统 SAS 系统是一个模块化的集成软件系统。所谓软件系统就是一组在一起作业的计算机程序。 SAS 系统是一种组合软件系统。基本部分是Base SAS 软件 2 SAS 系统的功能 SAS 系统是大型集成应用软件系统,具有完备的以下四大功能: ●数据访问 ●数据管理 ●数据分析 ●数据显示 它是美国软件研究所(SAS Institute Inc.)经多年的研制于1976年推出。目前已被许多 国家和地区的机构所采用。SAS 系统广泛应用于金融、医疗卫生、生产、运输、通信、政府、科研和教育等领域。它运用统计分析、时间序列分析、运筹决策等科学方法进行质量管理、财务管理、生产优化、风险管理、市场调查和预测等等业务,并可将各种数据以灵活多样的各种报表、图形和三维透视的形式直观地表现出来。在数据处理和统计分析领域,SAS 系统一直被誉为国际上的标准软件系统。 3 SAS 系统的主要模块 SAS 系统包含了众多的不同的模块,可完成不同的任务,主要模块有: ●●●●●●●● ●●●SAS/BASE(基础)——初步的统计分析 SAS/STAT(统计)——广泛的统计分析 SAS/QC(质量控制)——质量管理方面的专门分析计算 SAS/OR(规划)——运筹决策方面的专门分析计算 SAS/ETS(预测)——计量经济的时间序列方面的专门分析计算 SAS/IML(距阵运算)——提供了交互矩阵语言 SAS/GRAPH(图形)——提供了许多产生图形的过程并支持众多的图形设备 SAS/ACCESS(外部数据库接口)——提供了与大多数流行数据库管理系统的方便接口并自身也能进行数据管理 SAS/ASSIST(面向任务的通用菜单驱动界面)——方便用户以菜单方式进行操作SAS/FSP(数据处理交互式菜单系统) SAS/AF(面向对象编程的应用开发工具) 另外SAS系统还将许多常用的统计方法分别集成为两个模块LAB和INSIGHT,供用户
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
命题方式:单独命题 佛山科学技术学院2008—2009学年第一学期 《数据分析》课程期末考试试题A卷专业、班级:姓名:学号:
共 3 页第 2 页
共 3 页第3 页
一(1)SAS界面包括 输出框,日志框,编辑器 (2)在非数值变量后面家上”$”符号. (3) 自由格式输入数据应加上”@@”标记. (4) 三均值的计算公式 ^ M=1/4Q1+1/2M+1/4Q3 二 程序: data t1; input x@@; cards; 100.00 107.57 112.42 96.21 121.58 107.21 117.16 116.19 101.37 109.78 112.83 104.37 105.40 109.50 111.60 112.10 113.50 112.40 proc univariate plot normal; run; proc capability graphics normal; histogram x/normal; qqplot x/normal(….); run; (1)由上图可知道 均值:109.510556 方差:40.5703938 变异系数:5.81632451 峰度:0.05978054 偏度:-0.3324812 (2) 中位数: 上四分位数: 下四分位数: 四分位极差: (3)做出直方图、QQ图、茎叶图、箱线图 直方图:
QQ图 茎叶图:
箱线图: (4)进行正态性W 检验(取05.0=α). 由上图可以知道Wo=0.978265,P=0.9304>05.0=α; 故不能拒绝原假设Ho,所以是高度显著的。 三 data t2; input x1-x4; cards ; 16.7 26.7 6.4 35.0 18.2 28.0 3.2 29.7 16.7 26.7 2.1 34.9 18.1 26.7 4.3 31.5 16.7 26.0 3.0 32.7 18.1 30.2 7.0 34.9 20.2 30.5 4.8 34.4 20.2 29.5 5.5 36.2 21.5 31.5 5.8 36.5 18.8 30.6 5.4 35.4 21.6 27.8 5.4 34.1 21.3 29.5 5.8 35.8 proc corr cov pearson ; run ; (1)计算协方差矩阵,Pearson 相关矩阵; 协方差矩阵:
毕业论文声明 本人郑重声明: 1.此毕业论文是本人在指导教师指导下独立进行研究取得的成果。除了特别加以标注地方外,本文不包含他人或其它机构已经发表或撰写过的研究成果。对本文研究做出重要贡献的个人与集体均已在文中作了明确标明。本人完全意识到本声明的法律结果由本人承担。 2.本人完全了解学校、学院有关保留、使用学位论文的规定,同意学校与学院保留并向国家有关部门或机构送交此论文的复印件和电子版,允许此文被查阅和借阅。本人授权大学学院可以将此文的全部或部分内容编入有关数据库进行检索,可以采用影印、缩印或扫描等复制手段保存和汇编本文。 3.若在大学学院毕业论文审查小组复审中,发现本文有抄袭,一切后果均由本人承担,与毕业论文指导老师无关。 4.本人所呈交的毕业论文,是在指导老师的指导下独立进行研究所取得的成果。论文中凡引用他人已经发布或未发表的成果、数据、观点等,均已明确注明出处。论文中已经注明引用的内容外,不包含任何其他个人或集体已经发表或撰写过的研究成果。对本文的研究成果做出重要贡献的个人和集体,均已在论文中已明确的方式标明。 学位论文作者(签名): 年月
关于毕业论文使用授权的声明 本人在指导老师的指导下所完成的论文及相关的资料(包括图纸、实验记录、原始数据、实物照片、图片、录音带、设计手稿等),知识产权归属华北电力大学。本人完全了解大学有关保存,使用毕业论文的规定。同意学校保存或向国家有关部门或机构送交论文的纸质版或电子版,允许论文被查阅或借阅。本人授权大学可以将本毕业论文的全部或部分内容编入有关数据库进行检索,可以采用任何复制手段保存或编汇本毕业论文。如果发表相关成果,一定征得指导教师同意,且第一署名单位为大学。本人毕业后使用毕业论文或与该论文直接相关的学术论文或成果时,第一署名单位仍然为大学。本人完全了解大学关于收集、保存、使用学位论文的规定,同意如下各项内容: 按照学校要求提交学位论文的印刷本和电子版本;学校有权保存学位论文的印刷本和电子版,并采用影印、缩印、扫描、数字化或其它手段保存或汇编本学位论文;学校有权提供目录检索以及提供本学位论文全文或者部分的阅览服务;学校有权按有关规定向国家有关部门或者机构送交论文的复印件和电子版,允许论文被查阅和借阅。本人授权大学可以将本学位论文的全部或部分内容编入学校有关数据库和收录到《中国学位论文全文数据库》进行信息服务。在不以赢利为目的的前提下,学校可以适当复制论文的部分或全部内容用于学术活动。 论文作者签名:日期: 指导教师签名:日期: