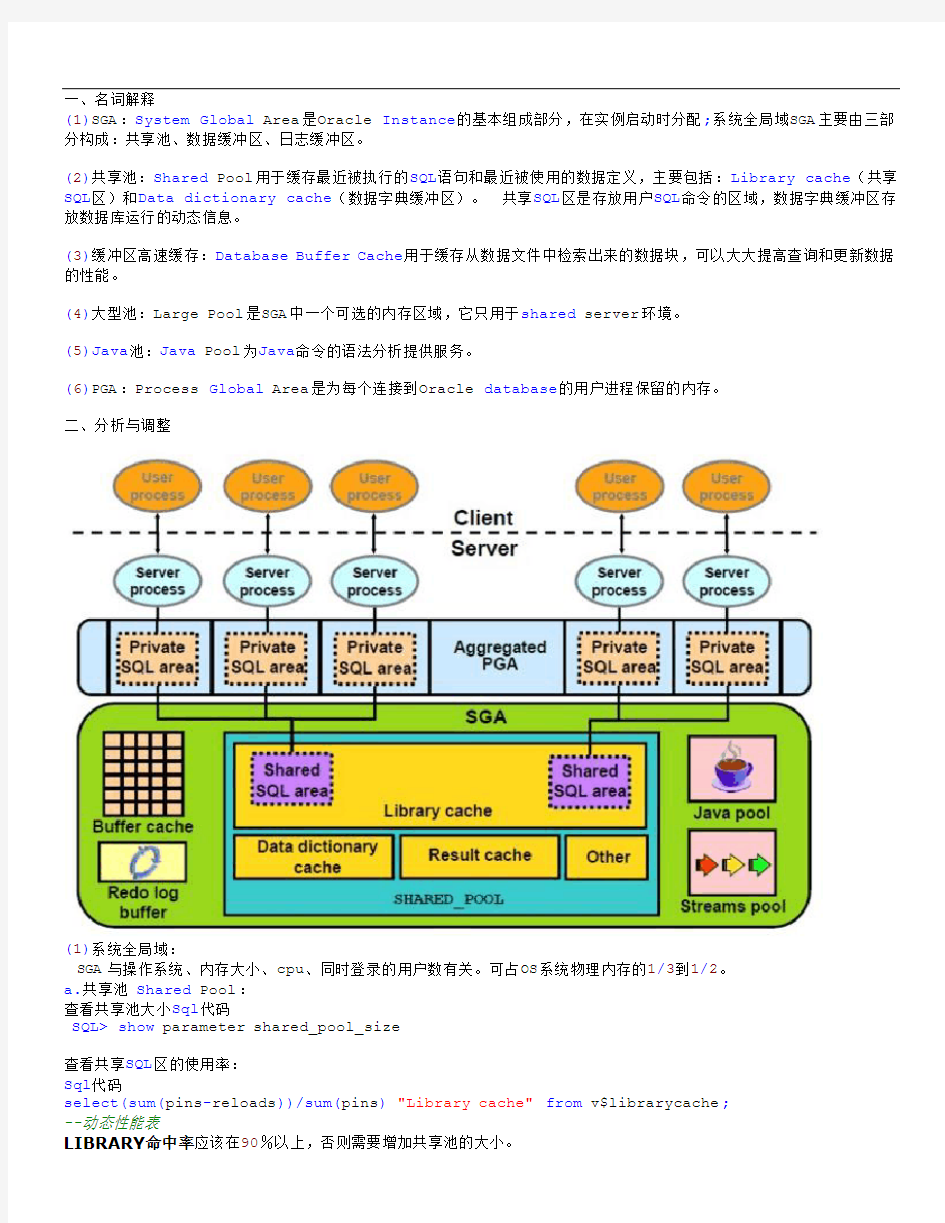

一、名词解释
(1)SGA:System Global Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。
(2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Library cache(共享SQL区)和Data dictionary cache(数据字典缓冲区)。共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。
(3)缓冲区高速缓存:Database Buffer Cache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。
(4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。
(5)Java池:Java Pool为Java命令的语法分析提供服务。
(6)PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。
二、分析与调整
(1)系统全局域:
SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/3到1/2。
a.共享池Shared Pool:
查看共享池大小Sql代码
SQL>show parameter shared_pool_size
查看共享SQL区的使用率:
Sql代码
select(sum(pins-reloads))/sum(pins)"Library cache"from v$librarycache;
--动态性能表
LIBRARY命中率应该在90%以上,否则需要增加共享池的大小。
查看数据字典缓冲区的使用率:
Sql代码
select(sum(gets-getmisses-usage-fixed))/sum(gets)"Data dictionary cache"from v$rowcache; --动态性能表
这个使用率也应该在90%以上,否则需要增加共享池的大小。
修改共享池的大小:
Sql代码
ALTER SYSTEM SET SHARED_POOL_SIZE =64M;
b.缓冲区高速缓存Database Buffer Cache:
查看共享池大小Sql代码
SQL>show parameter db_cache_size
查看数据库数据缓冲区的使用情况:
Sql代码
SELECT name,value FROM v$sysstat order by name WHERE name IN(''DB BLOCK GETS'',''CONSISTENT GETS'',''PHYSICAL READS'');
SELECT * FROM V$SYSSTAT WHERE NAME IN('parse_time_cpu','parse_time_elapsed','parse_count_ hard');
计算出来数据缓冲区的使用命中率=1-(physical reads/(db block gets+consistent gets)),这个命中率应该在90%以上,否则需要增加数据缓冲区的大小。
c.日志缓冲区
查看日志缓冲区的使用情况:
Sql代码
SELECT name,value FROM v$sysstat WHERE name IN('redo entries','redo log space requests')
查询出的结果可以计算出日志缓冲区的申请失败率:
申请失败率=requests/entries,申请失败率应该接近于0,否则说明日志缓冲区开设太小,需要增加ORACLE数据库的日志缓冲区。
d.大型池:
可以减轻共享池的负担,可以为备份、恢复等操作来使用,不使用LRU算法来管理。其大小由数据库的'共享模式/db模式'如果是共享模式的话,要分配的大一些。
指定Large Pool的大小:
Sql代码
ALTER SYSTEM SET LARGE_POOL_SIZE=64M
e.Java池:
在安装和使用Java的情况下使用。
(2)PGA调整
a.PGA_AGGREGATE_TARGET初始化设置
PGA_AGGREGATE_TARGET的值应该基于Oracle实例可利用内存的总量来设置,这个参数可以被动态的修改。假设Oracle实例可分配4GB的物理内存,剩下的内存分配给操作系统和其它应用程序。你也许会分配80%的可用内存给Oracle 实例,即3.2G。现在必须在内存中划分SGA和PGA区域。
在OLTP(联机事务处理)系统中,典型PGA内存设置应该是总内存的较小部分(例如20%),剩下80%分配给SGA。OLTP:PGA_AGGREGATE_TARGET =(total_mem * 80%) * 20% = 2.5G
在DSS(数据集)系统中,由于会运行一些很大的查询,典型的PGA内存最多分配70%的内存。
DSS:PGA_AGGREGATE_TARGET =(total_mem * 80%) * 50%
在这个例子中,总内存4GB,DSS系统,你可以设置PGA_AGGREGATE_TARGET为1600MB,OLTP则为655MB。
b.配置PGA自动管理
不用重启DB,直接在线修改。
SQL>alter system set workarea_size_policy=auto scope=both;
System altered.
SQL>alter system set pga_aggregate_target=512m scope=both;
System altered.
SQL>show parameter workarea
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
workarea_size_policy string AUTO--这个设置成AUTO
SQL>show parameter pga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_target big integer536870912
SQL>
c.监控自动PGA内存管理的性能
V$PGASTAT:这个视图给出了一个实例级别的PGA内存使用和自动分配的统计。
SQL>set lines 256
SQL>set pages 42
SQL>SELECT * FROM V$PGASTAT;
NAME VALUE UNIT
---------------------------------------------------------------- ---------- ------------ aggregate PGA target parameter 536870912 bytes
--当前PGA_AGGREGATE_TARGET的值
aggregate PGA auto target 477379584 bytes
--当前可用于自动分配了的PGA大小,应该比PGA_AGGREGATE_TARGET 小
global memory bound26843136 bytes
--自动模式下工作区域的最大大小,Oracle根据工作负载自动调整。
total PGA inuse 6448128 bytes
total PGA allocated 11598848 bytes
--PGA的最大分配
maximum PGA allocated 166175744 bytes
total freeable PGA memory393216 bytes
--PGA的最大空闲大小
PGA memory freed back to OS 69074944 bytes
total PGA used for auto workareas 0 bytes
--PGA分配给auto workareas的大小
maximum PGA used for auto workareas 1049600 bytes
total PGA used for manual workareas 0 bytes
maximum PGA used for manual workareas 530432 bytes
over allocation count1118
--实例启动后,发生的分配次数,如果这个值大于0,就要考虑增加pga的值
bytes processed 114895872 bytes
extra bytes read/written 4608000 bytes
cache hit percentage 96.14percent
--命中率
16rows selected.
--V$PGA_TARGET_ADVICE
SQL>SELECT round(PGA_TARGET_FOR_ESTIMATE/1024/1024) target_mb,
ESTD_PGA_CACHE_HIT_PERCENTAGE cache_hit_perc,
ESTD_OVERALLOC_COUNT
FROM v$pga_target_advice;
The output of this query might look like the following:
TARGET_MB CACHE_HIT_PERC ESTD_OVERALLOC_COUNT
---------- -------------- --------------------
6323367
1252430
250303
375390
500580
600590
700590
800600
900600
1000610
1500670
2000760
3000830
4000850
可以看出当TARGET_MB 为375M是ESTD_OVERALLOC_COUNT=0,所以可以将PGA_AGGREGATE_TARGET设置成375M。
附:oracle SGA与PGA区别:
SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写。
PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反,PGA 是只被一个进程使用的区域,PGA 在创建进程时分配,在终止进程时回收。
另一篇文章中也这样写了相关的调整记录
如何估算PGA,SGA的大小,配置数据库服务器的内存
ORACLE给的建议是: OLTP系统 PGA=(Total Memory)*80%*20%。
DSS系统PGA=(Total Memory)*80%*50%。
ORACLE建议一个数据库服务器,分80%的内存给数据库,20%的内存给操作系统,那怎么给一个数据库服务器配内存呢?SQL>select * from v$pgastat;
NAME VALUE UNIT
---------------------------------------------------------------- ---------- ------------aggregate PGA target parameter 104857600 bytes
-----这个值等于参数PGA_AGGREGATE_TARGET的值,如果此值为0,表示禁用了PGA自动管理。
aggregate PGA auto target 75220992 bytes
-----表示PGA还能提供多少内存给自动运行模式,通常这个值接近pga_aggregate_target-total pga inuse. global memory bound20971520 bytes
-----工作区执行的最大值,如果这个值小于1M,马上增加PGA大小
total PGA inuse 30167040 bytes
-----当前分配PGA的总大小,这个值有可能大于PGA,如果PGA设置太小.这个值接近select sum(pga_used_mem) from v$process.
total PGA allocated 52124672 bytes
-----工作区花费的总大小
maximum PGA allocated 67066880 bytes
total freeable PGA memory0 bytes ----没有了空闲的PGA
process count23----当前一个有23个process
max processes count25
PGA memory freed back to OS 0 bytes
total PGA used for auto workareas 8891392 bytes
maximum PGA used for auto workareas 22263808 bytes
total PGA used for manual workareas 0bytes ---为0自动管理
maximum PGA used for manual workareas 0 bytes ---为0自动管理
over allocation count0
--如果PGA设置太小,导致PGA有时大于PGA_AGGREGATE_TARGET的值,此处为0,说明PGA没有扩展大于TARGET的值,如果此值出现过,那么增加PGA大小。
bytes processed 124434432 bytes
extra bytes read/written 0 bytes
cache hit percentage 100percent
---命中率为100%,如果太小增加PGA
recompute count(total)6651
19rows selected
SQL>select max(pga_used_mem)/1024/1024M from v$process;
----当前一个process消耗最大的内存
M
----------
9.12815189
SQL>select min(pga_used_mem)/1024/1024M from v$process where pga_used_mem>0;---process
消耗最少内存
M
----------
0.19186878
SQL>select max(pga_used_mem)/1024/1024M from v$process ;
----process曾经消耗的最大内存
M
----------
9.12815189
SQL>select sum(pga_used_mem)/1024/1024from v$process;----当前process一共消耗的PGA
SUM(PGA_USED_MEM)/1024/1024
---------------------------
28.8192501068115
如何设置PGA呢?我们可以在压力测试阶段,模拟一下系统的运行,然后运行
select(select sum(pga_used_mem)/1024/1024from v$process)/(select count(*)from v$process) from dual;
得到一个process大约占用了多少的内存,然后估算系统一共会有多少连接,比如一共有500个连接,
那么sessions=1.1*process +5=500,那么processes=450,
再乘以一个process需要消耗的内存,就能大约估算出PGA需要设置多大。
EG = 1.1 * 450 = 495M 估算的大一点 550M就OK乐
最好将PGA设置的值比计算出的值大一点,PGA值设定好后,就可以根据系统的性质,如果系统为OLTOP,那么总的内存可以设置为 PGA/0.16,最后也能估算出SGA的大小,建议还是多配点内存,反正便宜。
下面摘抄eygle的关于一个process能够分配的最大内存(串行操作)的规则:
10gR1之前,对于串行操作(非并行)一个process能够分配的最大的内存为min(5%pga_aggregate_target,100m) 10gR2之后,对于串行操作(非并行)一个process能够分配的最大内存有如下规则:
如果pga_aggregate_target<=500m,那么最大的内存为20%*pga_aggregate_target.
如果500m 如果1000m 如果pga_aggregate_target>2.5G,那么最大内存为2.5G. SQL>SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ FROM SYS.x$ksppi x, SYS.x$ksppcv y WHERE x.inst_id =USERENV('Instance') AND y.inst_id =USERENV('Instance')AND x.indx = y.indx AND x.ksppinm LIKE'%&par%' NAME VALUE DESCRIB -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- _smm_max_size 20480 maximum work area size in auto mode(serial) SQL>show parameter pga NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ pga_aggregate_target big integer100M 此处我的一个process能够分配的最大内存为20M,因为我的PGA=100M,符合上面的规则。 隐含参数_smm_max_size表示一个process能够分配最大的memory. 买了piner的《oracle高可用环境》一书,正好趁这段时间学习一下。 把看到的东西总结一下发表于此,今天先发第一章关于SGA与PGA的内容。 以后会陆续将总结在此发表,与大家共享。 SGA与PGA的结构如下图: SGA: 查看SGA: Sqlp>show sga 或select * from v$sga; Total System Global Area 289406976 bytes Fixed Size1248600 bytes Variable Size176161448 bytes Database Buffers 109051904 bytes Redo Buffers 2945024 bytes Fixed Size:包括了数据库与实例的控制信息、状态信息、字典信息等,启动时就被固定在SGA中,不会改变。Variable Size:包括了shard pool、large pool、java pool、stream pool、游标区和其他结构 Database Buffers:数据库中数据块缓冲的地方,是SGA中最大的地方,决定数据库性能 Redo Buffers:提供REDO缓冲的地方,在OLAP中不需要太大 V$sgastat记录了SGA的一些统计信息 V$sga_dynamic_components 保存SGA中可以手动调整的区域的一些调整记录 Shard pool: Shard_pool_size决定其大小,10g以后自动管理 Shard_pool中数据字典和控制区结构用户无法直接控制,与用户有关的只有sql缓冲区(library cache)。 将经常访问的过程或包用DBMS_SHARED_POOL.KEEP存储过程将该包pin在共享池中。 手工清除共享池的内容:alter system flush shard_pool; 共享池相关的几个常用的视图: V$sqlarea 记录了所有sql的统计信息,包括执行次数、物理读、逻辑读、耗费时间等 V$sqltext_with_newline 完全显示sql语句,通过hash_value来标示语句,piece排序 V$sql_plan保存了sql的执行计划,通过工具查看 V$shared_pool_advice 对共享池的预测,可以做调整SGA的参考 Data buffer: 在OLTP系统中要求data buffer的命中率在95%以上 select sum(pins)"execution",sum(pinhits)"hits", ((sum(pinhits)/sum(pins))*100)"pinhitration", sum(reloads)"misses",((sum(pins)/(sum(pins) +sum(reloads)))*100)"relhitratio" from V$librarycache 计算命中率的语句 select round((1- (physical.value - direct.value - lobs.value)/logical.value)*100,2) "Buffer Cache Hit Ratio" from v$sysstat physical,v$sysstat direct,v$sysstat lobs,v$sysstat logical where https://www.doczj.com/doc/086773975.html, ='physical reads' and https://www.doczj.com/doc/086773975.html, ='physical reads direct' and https://www.doczj.com/doc/086773975.html, ='physical reads direct (lob)' and https://www.doczj.com/doc/086773975.html, ='session logical reads'; PINS NUMBER Number of times a PIN was requested for objects of this namespace PINHITS NUMBER Number of times all of the metadata pieces of the library object were found in memory RELOADS NUMBER Any PIN of an object that is not the first PIN performed since the object handle was created,and which requires loading the object from disk Oracle把从data buffer中获得的数据库叫cache hit,把从磁盘获得的脚cache miss 数据缓冲区中的数据块通过脏列表(dirty list)和LRU列表(LRU list)来管理。 Data buffer可细分为:default pool、keep pool、recycle pool对应的参数为db_cache_size、 db_keep_cache_size 、db_recycle_size分别表示缓冲区大小 从9i开始oracle支持不同块大小的表空间,相应的可以为不同块大小的表空间指定不同块大小的数据缓冲区,不同块大小的数据缓冲区可以用相应的db_nk_cache_size来指定,其中 n可以是2、4、6、16或32 V$db_cache_advice 对数据缓冲区的预测,可以做调整data buffer的参考 V$bh、 x$bh记录了数据块在data buffer中缓冲的情况,通过这个视图可以找系统中的热点块。 通过下面语句找系统中top 10热点快所在的热点对象: Select/*+ rule*/ owner,object_name from dba_objects Where data_object_id in (select obj from (select obj from x$bh order by tch desc) Where rownum<11); PGA: 用来保存于用户进程相关的内存段。 从9i开始使用PGA自动管理,pga_aggregate_target参数指定session一共使用的最大PGA内存的上限。 Workarea_size_policy参数用于开关PGA内存自动管理功能,auto/manual 在OLTP环境中,自动PGA 管理只要设置到一定的值,如2G左右就能满足系统的要求。 自动内存管理: 从9i开始,sga_max_size参数设置SGA 的内存大小,不能动态修改 从10g开始,指定了sga_target参数后,所有的SGA组件如:shared pool、data buffer、 large pool都不用手工指定了,Oracle会自动管理。这一特性就是自动共享内存管理ASMM。如果设置了sga_target=0,就自动关闭自动共享内存管理功能。Sga_target大小不能超过sga_max_size的大小。 手动管理SGA: Alter system set sga_target=2000m; Alter system set db_cache_size=1000m; Alter system set shared_pool=200m; Alter system set sga_target=0---------关闭自动共享内存管理ASMM 11G以后sga+pga整个内存可以自动管理AMM,相关参数memory_max_target memory_target.设置好这两个参数后就不用关心SGA和PGA了 11g手动内存管理: Alter system set memory_target=3000m; Alter system set sga_target=2000m; Alter system set pga_aggregate_target=1000m; Alter system set memory_target=0;---------关闭自动内存管理AMM SGA+PGA最好不要超过总内存的70% 一、名词解释 (1)SGA:System Global Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。 (2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Library cache(共享SQL区)和Data dictionary cache(数据字典缓冲区)。共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。 (3)缓冲区高速缓存:Database Buffer Cache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。 (4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。 (5)Java池:Java Pool为Java命令的语法分析提供服务。 (6)PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。 二、分析与调整 (1)系统全局域: SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/3到1/2。 a.共享池Shared Pool: 查看共享池大小Sql代码 SQL>show parameter shared_pool_size 查看共享SQL区的使用率: Sql代码 select(sum(pins-reloads))/sum(pins)"Library cache"from v$librarycache; --动态性能表 LIBRARY命中率应该在90%以上,否则需要增加共享池的大小。 Oracle数据库实例及其相关概念2010-11-24 00:00 出处:中国IT实验室作者:佚名 完整的Oracle数据库通常由两部分组成:Oracle数据库实例和数据库。 用数据库安全策略防止权限升级攻击 C++虚函数的显式声明 完整的Oracle数据库通常由两部分组成:Oracle数据库实例和数据库。 1)数据库是一系列物理文件的集合(数据文件,控制文件,联机日志,参数文件等); 2)Oracle数据库实例则是一组Oracle后台进程/线程以及在服务器分配的共享内存区。 在启动Oracle数据库服务器时,实际上是在服务器的内存中创建一个Oracle实例(即在服务器内存中分配共享内存并创建相关的后台内存),然后由这个Oracle数据库实例来访问和控制磁盘中的数据文件。Oracle有一个很大的内存快,成为全局区(SGA)。 一、数据库、表空间、数据文件 1.数据库 数据库是数据集合。Oracle是一种数据库管理系统,是一种关系型的数据库管理系统。 通常情况了我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据、数据库管理系统。也即物理数据、内存、操作系统进程的组合体。 数据库的数据存储在表中。数据的关系由列来定义,即通常我们讲的字段,每个列都有一个列名。数据以行(我们通常称为记录)的方式存储在表中。表之间可以相互关联。以上就是关系模型数据库的一个最简单的描述。 当然,Oracle也是提供对面象对象型的结构数据库的最强大支持,对象既可以与其它对象建立关系,也可以包含其它对象。关于OO型数据库,以后利用专门的篇幅来讨论。一般情况下我们的讨论都基于关系模型。 2.表空间、文件 无论关系结构还是OO结构,Oracle数据库都将其数据存储在文件中。数据库结构提供对数据文件的逻辑映射,允许不同类型的数据分开存储。这些逻辑划分称作表空间。 表空间(tablespace)是数据库的逻辑划分,每个数据库至少有一个表空间(称作SYSTEM表空间)。为了便于管理和提高运行效率,可以使用一些附加表空间来划分用户和应用程序。例如:USER表空间供一般用户使用,RBS表空间供回滚段使用。一个表空间只能属于一个数据库。 每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。在Oracle7.2以后,数据文件创建可以改变大小。创建新的表空间需要创建新的数据文件。数据文件一旦加入到表空间中,就不能从这个表空间中移走,也不能与其它表空间发生联系。 如果数据库存储在多个表空间中,可以将它们各自的数据文件存放在不同磁盘上来对其进行物理分割。在规划和协调数据库I/O请求的方法中,上述的数据分割是一种很重要的方法。 3.Oracle数据库的存储结构分为逻辑存储结构和物理存储结构: 1)逻辑存储结构:用于描述Oracle内部组织和管理数据的方式; 2)物理存储结构:用于描述Oracle外部即操作系统中组织和管理数据的方式。 二、Oracle数据库实例 实验6 进程及进程间的通信 ●实验目的: 1、理解进程的概念 2、掌握进程复制函数fork的用法 3、掌握替换进程映像exec函数族 4、掌握进程间的通信机制,包括:有名管道、无名管道、信 号、共享内存、信号量和消息队列 ●实验要求: 熟练使用该节所介绍fork函数、exec函数族、以及进程间通信的相关函数。 ●实验器材: 软件: 1.安装了Ubunt的vmware虚拟机 硬件:PC机一台 ●实验步骤: 1、用进程相关API 函数编程一个程序,使之产生一个进程 扇:父进程产生一系列子进程,每个子进程打印自己的PID 然后退出。要求父进程最后打印PID。 进程扇process_fan.c参考代码如下: 2、用进程相关API 函数编写一个程序,使之产生一个进程 链:父进程派生一个子进程后,然后打印出自己的PID,然后退出,该子进程继续派生子进程,然后打印PID,然后退出,以此类推。 要求:1) 实现一个父进程要比子进程先打印PID 的版本。(即 打印的PID 一般是递增的) 2 )实现一个子进程要比父进程先打印PID 的版本。(即打印的PID 一般是递减的) 进程链1,process_chain1.c的参考代码如下: 进程链2,process_chain2.c的参考代码如下: 3、编写程序execl.c,实现父进程打印自己的pid号,子进程调用 execl函数,用可执行程序file_creat替换本进程。注意命令行参数。 参考代码如下: /*execl.c*/ #include CP1H可编程控制器 您将学会什么? 第二章 CP1H内存分配 第二章 CP1H内存分配 第二章 CP1H内存分配 Oracle 内存内存全面全面全面分析分析 作者作者::fuyuncat 来源来源::https://www.doczj.com/doc/086773975.html, 作者简介 黄玮,男,99年开始从事DBA 工作,有多年的水利、军工、电信及航 运行业大型数据库Oracle 开发、设计和维护经验。 曾供职于南方某著名电信设备制造商——H 公司。期间,作为DB 组 长,负责设计、开发和维护彩铃业务的数据库系统。目前,H 公司的彩铃系 统是世界上终端用户最多的彩铃系统。最终用户数过亿。 目前供职于某世界著名物流公司,负责公司的电子物流系统的数据库开 发、维护工作。 msn: fuyuncat@https://www.doczj.com/doc/086773975.html, Email :fuyuncat@https://www.doczj.com/doc/086773975.html, Oracle 的内存配置与oracle 性能息息相关。而且关于内存的错误(如4030、4031错 误)都是十分令人头疼的问题。可以说,关于内存的配置,是最影响Oracle 性能的配 置。内存还直接影响到其他两个重要资源的消耗:CPU 和IO。 首先,看看Oracle 内存存储的主要内容是什么: ? 程序代码(PLSQL、Java); ? 关于已经连接的会话的信息,包括当前所有活动和非活动会话; ? 程序运行时必须的相关信息,例如查询计划; ? Oracle 进程之间共享的信息和相互交流的信息,例如锁; ? 那些被永久存储在外围存储介质上,被cache 在内存中的数据(如redo log 条 目,数据块)。 此外,需要记住的一点是,Oracle 的内存是与实例对应的。也就是说,一个实例就有 一个独立的内存结构。 先从Oracle 内存的组成架构介绍。 1. Oracle 的内存架构组成 Oracle 的内存,从总体上讲,可以分为两大块:共享部分(主要是SGA)和进程独享 部分(主要是PGA 和UGA)。而这两部分内存里面,根据功能不同,还分为不同内存池 (Pool)和内存区(Area)。下面就是Oracle 内存构成框架图: 本文由我司收集整编,推荐下载,如有疑问,请与我司联系 Java 内存区域划分、内存分配原理 2014/11/16 2448 运行时数据区域 Java 虚拟机在执行Java 的过程中会把管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程 的启动而存在,而有的区域则依赖线程的启动和结束而创建和销毁。 Java 虚拟机包括下面几个运行时数据区域: 程序计数器 程序计数器是一块较小的区域,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的模型里,字节码指示器就是通过改变程序计数器的值 来指定下一条需要执行的指令。分支,循环等基础功能就是依赖程序计数器来完成的。 由于java 虚拟机的多线程是通过轮流切换并分配处理器执行时间来完成,一个处理器同一时间只会执行一条线程中的指令。为了线程恢复后能够恢复正确的 执行位置,每条线程都需要一个独立的程序计数器,以确保线程之间互不影响。因 此程序计数器是“线程私有”的内存。 如果虚拟机正在执行的是一个Java 方法,则计数器指定的是字节码指令对应的地址,如果正在执行的是一个本地方法,则计数器指定问空undefined。程序计数器区域是Java 虚拟机中唯一没有定义OutOfMemory 异常的区域。 Java 虚拟机栈 和程序计数器一样也是线程私有的,生命周期与线程相同。虚拟机栈描述的是Java 方法执行的内存模型:每个方法被执行的时候都会创建一个栈帧用于存储局部变量表,操作栈,动态链接,方法出口等信息。每一个方法被调用的过程就对应 一个栈帧在虚拟机栈中从入栈到出栈的过程。 实例变量和类变量内存分配 Java向程序员许下一个承诺:无需关心内存回收,java提供了优秀的垃圾回收机制来回收已经分配的内存。大部分开发者肆无忌惮的挥霍着java程序的内存分配,从而造成java程序的运行效率低下! java内存管理分为两方面: 1,内存的分配:指创建java对象时,jvm为该对象在堆内存中所分配的内存空间。 2,内存的回收:指当该java对象失去引用,变成垃圾时,jvm的垃圾回收机制自动清理该对象,并回收该对象占用的内存。 jvm的垃圾回收机制由一条后台线程完成。不断分配内存使得系统中内存减少,从而降低程序运行性能。大量分配内存的回收使得垃圾回收负担加重,降低程序运行性能。 一,实例变量和类变量(静态变量) java程序的变量大体可分为成员变量和局部变量。 其中局部变量有3类:形参、方法内的局部变量、代码块内的局部变量。 局部变量被存储在方法的栈内存中,生存周期随方法或代码块的结束而消亡。 在类内定义的变量被称为成员变量。没使用static修饰的称为成员变量,用static修饰的称为静态变量或类变量。 1.1实例变量和类变量的属性 在同一个jvm中,每个类只对应一个Class对象,但每个类可以创建多个java对象。 【其实类也是一个对象,所有类都是Class实例,每个类初始化后,系统都会为该类创建一个对应的Class实例,程序可以通过反射来获取某个类所对应的Class实例(Person.class 或Class.forName(“Person”))】 因此同一个jvm中的一个类的类变量只需要一块内存空间;但对实例变量而言,该类每创建一次实例,就需要为该实例变量分配一块内存空间。 非静态函数需要通过对象调用,静态函数既可以通过类名调用,也可以通过对象调用,其实用对象调用静态函数,底层还是用类名调用来实现的! 1.2实例变量的初始化时机 对实例变量而言,它属于java对象本身,每次创建java对象时都需要为实例变量分配内存空间,并执行初始化。 一、名词解释 (1)SGA:SystemGlobal Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。 (2)共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Librarycache(共享SQL区)和Datadictionarycache(数据字典缓冲区)。共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。 (3)缓冲区高速缓存:DatabaseBufferCache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。 (4)大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。 (5)Java池:Java Pool为Java命令的语法分析提供服务。 (6)PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。 二、分析与调整 (1)系统全局域: SGA与操作系统、内存大小、cpu、同时登录的用户数有关。可占OS系统物理内存的1/3到1/2。 a.共享池Shared Pool: 查看共享池大小Sql代码 SQL>show parameter shared_pool_size 查看共享SQL区的使用率: Sql代码 select(sum(pins-reloads))/sum(pins)"Library cache"from v$librarycache; --动态性能表 LIBRARY命中率应该在90%以上,否则需要增加共享池的大小。 查看数据字典缓冲区的使用率: 本文背景: 在编程中,很多Windows或C++的内存函数不知道有什么区别,更别谈有效使用;根本的原因是,没有清楚的理解操作系统的内存管理机制,本文企图通过简单的总结描述,结合实例来阐明这个机制。 本文目的: 对Windows内存管理机制了解清楚,有效的利用C++内存函数管理和使用内存。 本文内容: 3. 内存管理机制--虚拟内存 (VM) · 虚拟内存使用场合 虚拟内存最适合用来管理大型对象或数据结构。比如说,电子表格程序,有很多单元格,但是也许大多数的单元格是没有数据的,用不着分配空间。也许,你会想到用动态链表,但是访问又没有数组快。定义二维数组,就会浪费很多空间。 它的优点是同时具有数组的快速和链表的小空间的优点。 · 分配虚拟内存 如果你程序需要大块内存,你可以先保留内存,需要的时候再提交物理存储器。在需要的时候再提交才能有效的利用内存。一般来说,如果需要内存大于1M,用虚拟内存比较好。 · 保留 用以下Windows 函数保留内存块 VirtualAlloc (PVOID 开始地址,SIZE_T 大小,DWORD 类型,DWORD 保护 属性) 一般情况下,你不需要指定“开始地址”,因为你不知道进程的那段空间 是不是已经被占用了;所以你可以用NULL。“大小”是你需要的内存字 节;“类型”有MEM_RESERVE(保留)、MEM_RELEASE(释放)和 MEM_COMMIT(提交)。“保护属性”在前面章节有详细介绍,只能用前 六种属性。 如果你要保留的是长久不会释放的内存区,就保留在较高的空间区域, 这样不会产生碎片。用这个类型标志可以达到: MEM_RESERVE|MEM_TOP_DOWN。 C++程序:保留1G的空间 LPVOID pV=VirtualAlloc(NULL,1000*1024*1024,MEM_RESERVE|MEM_TOP_DOWN,PAGE_READW if(pV==NULL) cout<<"没有那么多虚拟空间!"< ABC公司Oracle数据库参数调整建议 1.Oracle参数initdb.ora (修改建议) 目前系统现在分析: (1)Windows 2003可以显示50G内存,但操作系统是32位,最多默认支持4G,用户进程支持2G,Oracle可能支持1.7G内存; (2)不清楚是否对操作系统做过支持大内存的调整;从下表的参数分析,可能没有修改; (3)不清楚此系统Windows是否允许在虚拟环境(Virtual Machine),故保守起见,我们的建议是:把内存往小里调整。 根据我们的经验,对Oracle数据库调整如下: 总内存控制在1.5G SGA控制在800M PGA使用700M testdb.__db_cache_size=469762048 testdb.__java_pool_size=8388608 testdb.__large_pool_size=8388608 testdb.__oracle_base='D:\app\Administrator'#ORACLE_BASE set from environment testdb.__pga_aggregate_target= 734003200 #700M #671088640 testdb.__sga_target=838860800 #800M #1249902592 testdb.__shared_io_pool_size=0 testdb.__shared_pool_size= 335544320 #320M #738197504 testdb.__streams_pool_size=8388608 *.audit_file_dest='D:\app\Administrator\admin\xbrldb\adump' *.audit_trail='db' *.compatible='11.2.0.0.0' *.control_files='E:\data\xbrldb\control01.ctl','D:\app\Administrator\flash_recovery_ area\xbrldb\control02.ctl' *.db_block_size=8192 *.db_domain='' *.db_name='xbrldb' *.db_recovery_file_dest='D:\app\Administrator\flash_recovery_area' *.db_recovery_file_dest_size=21474836480 *.diagnostic_dest='D:\app\Administrator' *.dispatchers='(PROTOCOL=TCP) (SERVICE=xbrldbXDB)' *.fast_start_mttr_target=30 *.job_queue_processes=1000 testdb.local_listener='(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(H OST=10.24.58.100)(PORT=1531))))' *.log_archive_format='ARC%S_%R.%T' *.memory_target= 1610612736 #1.5G#1916796928 《动态分配内存与数据结构》习题 学号姓名 一、选择题 1、是一种限制存取位置的线性表,元素的存取必须服从先进先出的规则。 A.顺序表B.链表C.栈D.队列 2、是一种限制存取位置的线性表,元素的存取必须服从先进后出的规则。 A.顺序表B.链表C.栈D.队列 3、与顺序表相比,链表不具有的特点是。 A.能够分散存储数据,无需连续内存空间 B.插入和删除无需移动数据 C.能够根据下标随机访问 D.只要内存足够,没有最大长度的限制 4、如果通过new运算符动态分配失败,返回结果是。 A.-1 B.0 C.1D.不确定 5、实现深复制中,不是必须自定义的。 A.构造函数B.复制构造函数 C.析构函数D.复制赋值操作符函数 6、分析下列代码是否存在问题,选择合适的选项:。 int main(void) { int *p = new int [10]; p = new int [10]; delete [] p; p = NULL; return 0; } A.没有问题 B.有内存泄漏 C.存在空悬指针 D.存在重复释放同一空间 7、通过new运算符动态分配的对象,存储于内存中的。 A.全局变量与静态变量区 B.代码区 C.栈区 D.堆区 8、下列函数中,可以是虚函数。 A.构造函数 B.析构函数 C.静态成员函数 D.友元函数 9、关于通过new运算符动态创建的对象数组,下列判断中是错误的。 A. 动态创建的对象数组只能调用默认构造函数 B. 动态创建的对象数组必须调用delete []动态撤销 C. 动态创建的对象数组的大小必须是常数或常变量 D. 动态创建的对象数组没有数组名 10、顺序表不具有的特点是 A. 元素的存储地址连续 B. 存储空间根据需要动态开辟,不会溢出 C. 可以直接随机访问元素 D. 插入和删除元素的时间开销与位置有关 11、假设一个对象Ob1的数据成员是指向动态对象的指针,如果采用浅复制的方式复制该对象得到对象Ob2,那么在析构对象Ob1和对象Ob2时会的问题。 A. 有重复释放 B. 没有 C. 内存泄漏 D. 动态分配失败 12、假设对5个元素A、B、C、D、E进行压栈或出栈的操作,压栈的先后顺序是ABCDE,则出栈的先后顺序不可能是。 A. ABCDE B. EDCBA C. EDBCA D. BCADE 13、假设对4个元素A、B、C、D、E进行压栈或出栈的操作,压栈的先后顺序是ABCD,则出栈的先后顺序不可能是。 A. ABCD B. DCBA C. BCAD D. DCAB 14、通过new运算符动态创建的对象的存放在中。 A. 代码区 B. 栈区 C. 自由存储区 D. 全局数据区 15、链表不具有的特点是。 A. 元素的存储地址可以不连续 B. 存储空间根据需要动态开辟,不会溢出 C. 可以直接随机访问元素 D. 插入和删除元素的时间开销与位置无关 16、有关内存分配和释放的说法,下面当中错误的是 A.new运算符的结果只能赋值给指针变量 B.动态创建的对象数组必须调用delete []动态撤销 C.用new分配的空间位置是在内存的栈区 D.动态创建的对象数组没有数组名 17、关于栈,下列哪项不是基本操作 A.删除栈顶元素 B.删除栈底元素 C.判断栈是否为空 D.把栈置空 18、关于链表,说法错误的是 一分钟查一个案例带你看看Oracle数据库到底有多牛逼 性能难题 问题来了 电话响了,是一位证券客户 DBA 的来电,看来,问题没过两天,又出现了。 接起电话,果不其然。 “小y,前天那个问题又重现了。重启后恢复正常,这次抓到了hangAnalyze,不过领导在身后一直催,所以没来得及抓取 systemstate dump 就重启了。你尽快帮忙分析下吧,hanganalyze 的 trace 文件 已经转到你邮箱了。” 就在 2 天前,该客户找到小 y, 他们有一套比较重要的系统出现了数据库无法登陆的情况,导致业务中断,重启后业务恢复,但原因未明,搞的他们压力很大。 可惜的是,他们是事后找过来,由于客户现场保护意识不足,最后也只能是巧妇难为无米之炊了… 总的来说,小 y 还算是比较熟悉证券行业的。 毕竟,小 y 多年来一直在银行、证券、航空等客户提供数据库专家支持服务,这其中就包括了北京 排名前 6 的所有证券公司。 简而言之,证券行业的要求就是快速恢复,快速恢复业务大于一切。 原因很简单,股价瞬息万变,作为股民,如果当时无法出售或者购买股票,甚至可能引发官司。所以,证券核心交易系统如果中断时间超过 5 分钟,则可以算得上是严重故障了,一旦被投诉,则可能会 被证监会通报,届时业务可能被降级,影响到证券公司的经营和收益。 结合这个特点,小 y 为客户制定了应急预案,看来收集 systemstate dump 是来不及了,只能先 收集 hangAnalyze, 时间来得及的话则可以继续收集 systemstate dump。收集 hangAnalyze 的命令 很简单,照敲就是了,没什么技术含量。 $sqlplus –prelim “/as sysdba” SQL>oradebug setmypid SQL>oradebug hanganalyze 3 .. 此处等上一会 .. SQL>oradebug hanganalyze 3 SQL>oradebug tracefile_name 共享内存 不同进程共享内存示意图 共享内存指在多处理器的计算机系统中,可以被不同中央处理器(CPU)访问的大容量内存。由于多个CPU需要快速访问存储器,这样就要对存储器进行缓存(Cache)。任何一个缓存的数据被更新后,由于其他处理器也可能要存取,共享内存就需要立即更新,否则不同的处理器可能用到不同的数据。共享内存(shared memory)是 Unix下的多进程之间的通信方法 ,这种方法通常用于一个程序的多进程间通信,实际上多个程序间也可以通过共享内存来传递信息。 目录 共享内存的创建 共享内存是存在于内核级别的一种资源,在shell中可以使用ipcs命令来查看当前系统IPC中的状态,在文件系统/proc目录下有对其描述的相应文件。函数shmget可以创建或打开一块共享内存区。函数原型如下:#include 函数中参数key用来变换成一个标识符,而且每一个IPC对象与一个key相对应。当新建一个共享内存段时,size参数为要请求的内存长度(以字节为单位)。 注意:内核是以页为单位分配内存,当size参数的值不是系统内存页长的整数倍时,系统会分配给进程最小的可以满足size长的页数,但是最后一页的剩余部分内存是不可用的。 当打开一个内存段时,参数size的值为0。参数flag中的相应权限位初始化ipc_perm结构体中的mode域。同时参数flag是函数行为参数,它指定一些当函数遇到阻塞或其他情况时应做出的反应。shmid_ds结构初始化如表14-4所示。 初始化 Oracle数据库实例的内存和进程结构 更新: 2010-04-27来源: 互联网字体:【大中小】 内存结构 在Oracle数据库系统中内存结构主要分为系统全局区(SGA)和程序全局区(PGA)。 SGA随着数据库实例的启动向操作系统申请分配一块内存结构,随着数据库实例的关闭释放,每一个Oracle数据库实例有且只有一个SGA。 PGA随着Oracle服务进程启动的时候申请分配的一块内存结构。如果在共享服务结构中PGA存在SGA 中。 下图展示Oracle的内存结构,在后面我们将用文字详细的表述各个部件。 系统全局区(SGA) 重要提示,提高SGA的大小可以在一定程度上提高Oracle数据库系统的性能,但你设置SGA的值如果不能锁定在内存物理页上,有些部分可能被交换到系统的交换文件中。这样你的Oracle数据库系统将变慢。 系统全局区是一组包含数据和控制信息的共享内存结构,允许Oracle服务的众多后台进程同时访问或修改其中的数据,所以有些时候也被称为―全局共享区‖,参数文件中的SGA_MAX_SIZE指定SGA动态大小。※共享池SharedPool ※数据高速缓存DatabaseBufferCache ※重做日志缓存RedoLogBufferCache ※ Java池(可选)JavaPool ※大缓冲池(可选)LagerPool 共享池 共享池存储了最近多数使用的执行SQL语句和最近使用的数据定义。它包含库高速缓存器和数据字典缓存器这两个与性能相关的内存结构。共享池的大小可以通过初始化参数文件(通常为init.ora)中的SHARED_POOL_SIZE决定。共享池是活动非常频繁的内存结构,会产生大量的内存碎片,所以你要确保它尽可能足够大。 库高速缓存器,他又包含共享SQL区和共享PL/SQL区两个组件区。为了提高SQL语句的性能,在提交SQL语句或PL/SQL程序块时Oracle服务器将先利用最近最少使用(LRU)算法检查库高速缓存中是否存在相同的SQL语句或PL/SQL程序块,若有则使用原有的分析树和执行路径。 数据字典缓存器,它收集最近使用的数据库中的数据定义信息。它包含数据文件、表、索引、列、用户、访问权限、其他数据库对象等信息。在分析阶段决定数据库对象的可访问信息。利用数据字典缓存器有效的改善了响应时间。它的大小由共享池的大小决定。 数据高速缓存 它存储数据文件中数据块的拷贝。利用这种结构使数据的更新操作性能大大的提高。数据高速缓存中的数据交换同样采用最近最少使用算法(LRU)。它的大小主要受到DB_BLOCK_SIZE决定。数据高速缓存它由DB_CACHE_SIZE、DB_KEEP_CACHE_SIZE、 DB_RECYCLE_CACHE_SIZE这些独立的子缓存器构成,同时它能动态的增长或收缩。 重做日志缓存 在任何程序设计环境及语言中,内存管理都十分重要。在目前的计算机系统或嵌入式系统中,内存资源仍然是有限的。因此在程序设计中,有效地管理内存资源是程序员首先考虑的问题。 第1节主要介绍内存管理基本概念,重点介绍C程序中内存的分配,以及C语言编译后的可执行程序的存储结构和运行结构,同时还介绍了堆空间和栈空间的用途及区别。 第2节主要介绍C语言中内存分配及释放函数、函数的功能,以及如何调用这些函数申请/释放内存空间及其注意事项。 3.1 内存管理基本概念 3.1.1C程序内存分配 1.C程序结构 下面列出C语言可执行程序的基本情况(Linux 2.6环境/GCC4.0)。 可以看出,此可执行程序在存储时(没有调入到内存)分为代码区(text)、数据区(data)和未初始化数据区(bss)3个部分。 (1)代码区(text segment)。存放CPU执行的机器指令(machine instructions)。通常,代码区是可共享的(即另外的执行程序可以调用它),因为对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。另外,代码区还规划了局部变量的相关信息。 (2)全局初始化数据区/静态数据区(initialized data segment/data segment)。该区包含了在程序中明确被初始化的全局变量、静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。例如,一个不在任何函数内的声明(全局数据): 使得变量maxcount根据其初始值被存储到初始化数据区中。 这声明了一个静态数据,如果是在任何函数体外声明,则表示其为一个全局静态变量,如果在函数体内(局部),则表示其为一个局部静态变量。另外,如果在函数名前加上static,则表示此函数只能在当前文件中被调用。 (3)未初始化数据区。亦称BSS区(uninitialized data segment),存入的是全局未初始化变量。BSS这个叫法是根据一个早期的汇编运算符而来,这个汇编运算符标志着一个块的开始。BSS区的数据在程序开始执行之前被内核初始化为0或者空指针(NULL)。例如一个不在任何函数内的声明: 将变量sum存储到未初始化数据区。 图3-1所示为可执行代码存储时结构和运行时结构的对照图。一个正在运行着的C编译程序占用的内存分为代码区、初始化数据区、未初始化数据区、堆区和栈区5个部分。 (1)代码区(text segment)。代码区指令根据程序设计流程依次执行,对于顺序指令,则只会执行一次(每个进程),如果反复,则需要使用跳转指令,如果进行递归,则需要借助栈来实现。 代码区的指令中包括操作码和要操作的对象(或对象地址引用)。如果是立即数(即具体的数值,如5),将直接包含在代码中;如果是局部数据,将在栈区分配空间,然后引用该数据地址;如果是BSS区和数据区,在代码中同样将引用该数据地址。 (2)全局初始化数据区/静态数据区(Data Segment)。只初始化一次。 (3)未初始化数据区(BSS)。在运行时改变其值。oracle实例内存解析
Oracle数据库实例及其相关概念
实验6 进程及进程间的通信之共享内存
CP1H系列PLC内存分配培训教程
Max作品 Max作品 2015.9
CP1H系列PLC选型配置
CP1H系列PLC内存分配
CP1H系列PLC功能使用
CP1H内存结构
①程序或设置参数变更时 RAM 闪存自动传送 接通电源时 闪存 RAM自动传送 ②通过特定操作 进行RAM 闪存的传送 通过PLC设置,在接通电源时 进行闪存 RAM的传送
用户程序
RAM
I/O存储器
闪存
③ 通过软件操作 进行RAM 存储盒的传送,或 闪存 存储盒的传送 通过DIP开关设置,在接通电源 时或通过软件操作 进行存储盒 RAM的传送,或 存储盒 闪存的传送
系统参数
CP1H的I/O存储器
CIO W
用户程序
存储器区 输入输出继电器区 内部辅助继电器区 特殊辅助继电器区 保持继电器区 数据存储器区 定时器区 计数器区 变址寄存器区 数据寄存器区 任务标志区
CP1H 0~6143CH 0~511CH 0~959CH 0~511CH 0~32767CH 0~4095CH 0~4095CH 0~15CH 0~15CH 0~31CH
A H D
I/O存储器
T C
系统参数
IR DR TK
I/O存储器地址表示
字(通道)地址:数据 W 100
W区 字编号
D 100
D区 字编号
100
字编号(CIO省略)
字地址、位地址的 表示用十进制 字地址可看成位地 址的集合 一个字(通道)16位
位地址:状态(字编号和位编号由“. .”隔开) W 100 . 02
W区 字编号 位编号 (00~15)
0 . 07
字编号 位编号(CIO省略) (00~15)Oracle内存全面分析
Java内存区域划分、内存分配原理
4.实例变量和类变量内存分配
oracle实例内存详解
Windows内存管理机制及C++内存分配实例(三):虚拟内存
ORACLE内存调整建议
《动态分配内存与数据结构》课后习题
一分钟查一个案例带你看看Oracle数据库到底有多牛逼性能难题
共享内存的原理
Oracle数据库实例的内存和进程结构
C语言的内存分配
相关主题
文本预览